
“天底下沒有完美的資料庫,也許Oracle是個例外”,前陣子幾個DBA在討論國產化替代時,有人就這么說,確實是的,Oracle算是比較完美的資料庫產品了,不過現在很多用戶都在面臨從Oracle資料庫向其他資料庫遷移的問題,中國電信已經宣布了今年年底前全線下架Oracle資料庫,全部用國產或者開源資料庫替代,本周和中國電信的朋友交流的時候,他們說已經完成了數百套系統從Oracle資料庫的遷移,最晚到8月份,這個任務就能夠完成了,
還有些企業怕遇到坑,因此還在不斷地研究、認證、測驗、分析中,事實上,在做出決策之前多一分小心還是十分必要的,10年前電信提出用開源資料庫替代Oracle的時候,針對MYSQL和PG做了一番分析,我也參與了其中的一些作業,通過對當時的MYSQL和PG進行對比,我們最終的分析結果是:如果要遷移計費、賬務系統,MYSQL優于PG,當然這個分析并不是說MYSQL就全面碾壓PG,而只是針對計費、賬務這樣的系統場景,PG的膨脹與VACUUM會對系統穩定運行造成較大的影響,相對而言風險更大,
其實我們也沒辦法看得太遠,哪怕是選擇好的資料庫,在遷移程序中,甚至遷移完成后的長期運行程序中,還是會遇到很多坑,有些問題可能是資料庫基礎架構從娘胎里帶來的,無法馬上解決的問題,如果你的應用對這樣的問題十分敏感,不解決會引發大問題,那樣就十分悲慘了,
昨天剛剛上班就有一個客戶遇到國產資料庫的問題,他們有一條SQL執行十分頻繁,總體開銷很大,希望通過index only scan來降低開銷,不過創建了索引之后,執行計劃依然不走index only scan,還是要走需要回表的執行計劃,我以前也沒有遇到過這類的問題,正好這個國產資料庫是基于opengauss 2.0的,我們的測驗環境中有opengauss 2.0和3.0的環境,于是我就先在opengauss 2.0的環境中做了一個測驗,實際上openGauss是不支持Covering index的,在openGauss 2.0上,我們創建Covering index的時候會報錯:

openGauss2.0是不支持這個語法的,openGauss3.0也類似,只不過錯誤資訊有所變化:

在openGauss3.0中,針對ustore的表是支持covering index的,而針對默認的和PG兼容的ASTORE是不支持的,于是我們做了些變更,創建了一個測驗用例,
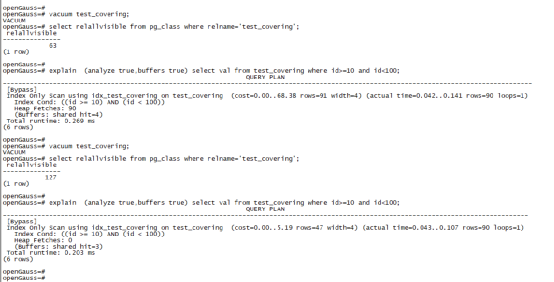
drop table test_covering ; create table test_covering (id serial,name text,val int); create index idx_test_covering on test_covering(id,val); insert into test_covering(name,val) select 'test'||generate_series(1,10000),(random()*100)::int%100; analyze test_covering; update test_covering set val=val+1; select relallvisible from pg_class where relname='test_covering'; explain (analyze true,buffers true) select val from test_covering where id>=10 and id<100; vacuum test_covering; select relallvisible from pg_class where relname='test_covering'; explain (analyze true,buffers true) select val from test_covering where id>=10 and id<100;
從執行計劃上看,確實沒有采用Index Only Scan的執行計劃,openGauss是基于PG 9.2.4開發的,難道這是PG早期的BUG嗎?按理說PG的COVERING INDEX就是為了讓SQL可以使用Index only scan的,于是我立即在openGauss 3.0上測驗了一下,
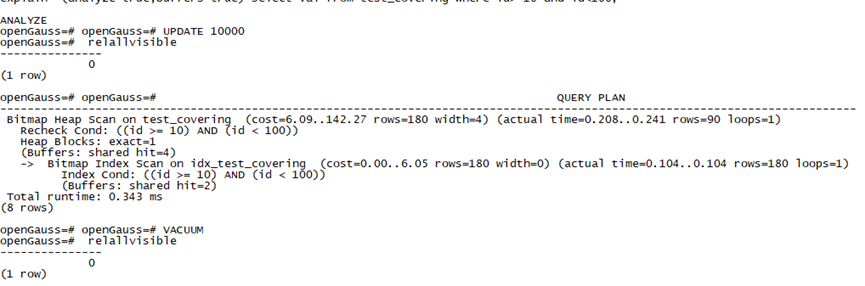
在openGauss 3.0上,我并沒有看到預期的Index Only Scan的執行計劃,于是我在網上和一個朋友交流了這個問題,他正好對此有過研究,立即就指出了這是一個visibility map的問題,PG 8.4為了支持MVCC,引入了visibility map,不過VM檔案并不是實時更新的,因此如果PAGE在VM中是不可見狀態時,就必須做回表操作,因為索引中并不存在資料行可見性的標識資料,因此不能使用Index Only Scan,為了進一步確認這個問題,我在一個社區版的PG 11上做了一個測驗,
drop table test_covering ; create table test_covering (id serial,name text,val int); create index idx_test_covering on test_covering(id) include(val); insert into test_covering(name,val) select 'test'||generate_series(1,10000),(random()*100)::int%100; analyze test_covering; update test_covering set val=val+1; select relallvisible from pg_class where relname='test_covering'; select relallvisible from pg_class where relname='test_covering'; explain (analyze true,buffers true) select val from test_covering where id>=10 and id<100; vacuum test_covering; select relallvisible from pg_class where relname='test_covering'; explain (analyze true,buffers true) select val from test_covering where id>=10 and id<100;

我們在PG 11上看到了預期的執行計劃,因為PG的資料行的可視性資訊僅僅存盤于表資料中,而索引中沒有這個資訊,因此在做Index Only Scan的時候,如果VM沒有及時更新,就必須回表才能獲得準確的資訊了,在VACUUM前執行的查詢中,HEAP FETCHES是180,說明雖然執行計劃是Index Only Scan,不過有180條資料是回表操作了,
當VM里已經更新了PAGE的資訊,那么這些PAGE上的記錄就不需要“回表操作”了,因此VACUUM后VM得到了更新,此時HEAP FETCHES變成0了,說明沒有任何回表操作,因為VM檔案的大小遠遠小于資料表的檔案,因此不回表會降低執行成本,從上面的例子我們也可以看出,不回表執行0.037毫秒,回表執行0.203毫秒,差異還是挺大的,
在PG 11上只要做了表分析,那么起碼執行計劃是Index Only Scan的,為什么openGauss上執行計劃也不選擇Index Only Scan呢?剛才我們測驗openGauss的時候因為不支持Covering Index的問題,對SQL做了改寫,改寫后的SQL在PG 11上是什么樣的呢?
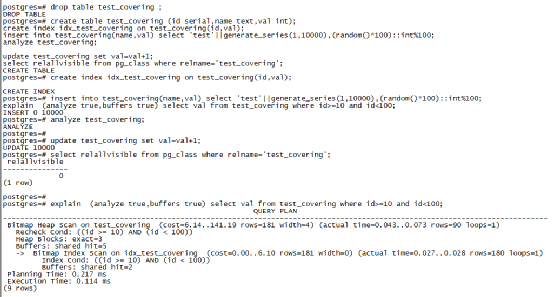
我們發現,如果索引變成了普通的索引之后,在PG上的執行計劃也和openGauss一樣了,
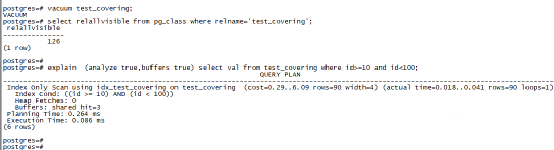
不過如果我們做一個vacuum,執行計劃就變得正確了,而且也不存在“回表”的問題了,從這個測驗我們再聯想一下openGauss,openGauss資料庫的CBO優化器是不是認為因為VM比較舊,這個查詢需要回表,所以不選擇Index Only Scan的執行計劃呢?
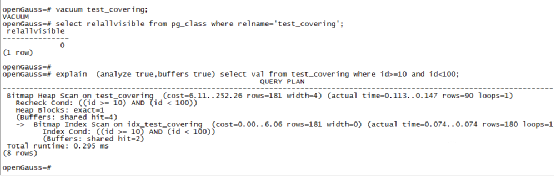
于是我們也在openGauss上做了VACUUM,不過VACUUM完成后,可視的PAGE數量還是0,執行計劃也還是沒有發生改變,過了一段時間后,發現可見頁的數量不為零了,于是再次分析執行計劃,發現執行計劃已經變成了Index Only Scan,
openGauss的檔案上對于VM檔案更新的問題并未做出說明,因為我們也只能猜測openGauss的vacuum命令并不更新VM檔案,VM檔案的更新可能是由其他機制來完成的,因為這個問題的存在,因此openGauss在ASTORE上不支持Covering Index,以防止創建了這樣的索引,大部分情況下,Index Only Scan的執行計劃也不可用,不過我們在openGauss的相關檔案上并未找到這方面的說明,
我們利用openGauss 3.0的USTORE功能,做了最后一個實驗,因為剛才我們看到openGauss在USTORE上是支持covering index的,是不是用Ustore可以解決這個問題呢?
rop table test_covering ; create table test_covering (id serial,name text,val int) with (STORAGE_TYPE=USTORE) ; create index idx_test_covering on test_covering using ubtree(id) include(val) ; insert into test_covering(name,val) select 'test'||generate_series(1,10000),(random()*100)::int%100; explain (analyze true,buffers true) select val from test_covering where id>=10 and id<100; analyze test_covering; update test_covering set val=val+1; explain (analyze true,buffers true) select val from test_covering where id>=10 and id<100;
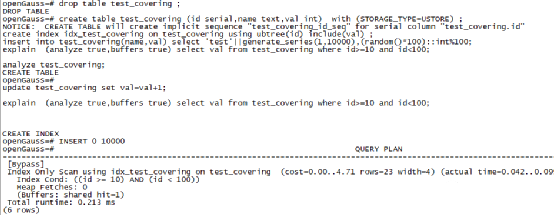
和我們預想的一樣,在USTORE上不需要VM的情況下,優化器正確地選擇了Index Only Scan,似乎在opengauss上使用USTORE可以完美解決這個問題,不過目前USTORE還不夠成熟,在USTORE上也存在不少坑,比如說官方檔案中沒有提及的USTORE表不支持回收站的問題,以及USTORE上以前我們遇到的一些性能問題,從openGauss僅在USTORE上支持covering index上,我們也可以看出華為openGauss在VM方面可能存在一些問題,就像我們測驗中發現,哪怕做vacuum,也不能馬上更新VM資料,不能及時更新VM,會導致SQL陳述句的回表操作增加,導致covering index的初衷無法實作,
資料庫使用程序中難免會遇到坑,在使用“完美的資料庫”-Oracle的時候我們不也經常遇到BUG嗎,遇到坑并不怕,怕的是遇到坑之后我們無法找到解決方案,也不知道這個坑到底是怎么回事,國產資料庫并不只是在功能與性能上存在差距的問題,更大的問題可能是在今后的長期維護上,運維知識、運維專家、運維工具的缺失可能會更大地影響國產資料庫的發展,
不過不管如何,走出第一步就沒有后退的道理了,遇到坑就退回去也是不大可能的,企業在走出第一步之前,就應該未雨綢繆,安排好填坑的隊伍,這樣才能有備無患,
作者丨白鱔
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/After-the-localization-and-substitution-of-databases-the-road-to-patching-up-pits-has-never-stopped.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/539902.html
標籤:其他