摘要:openGemini的設計和優化都是根據時序資料特點而來,在面對海量運維監控資料處理需求時,openGemini顯然更加有針對性,
IT運維誕生于最早的資訊化時代,在資訊化時代,企業的資訊化系統,主要為了滿足企業內部管理的需求,通常是集中、可控和固化的煙囪式架構,傳統IT運維,以人力運維為主,在單點式和煙囪式的架構中,的確起到了非常重要的作用,
我們知道,傳統運維模式關注的是單臺IT設備的故障率或單套應用系統的可用性,系統與系統之間,設備與設備之間,是彼此孤立的,因此產生的資料量也相對有限,
但進入到云計算時代之后,IT的邊界被完全打開,更多的聯接、更多的設備、更多的服務,使得系統規模開始變得越來越大,隨著監控粒度越來越細,監控資料呈現出爆炸式增長的態勢,每天將產生上百TB的資料,如何對如此海量的資料進行處理成為華為云SRE面臨的一大難題
業務背景
華為云SRE基礎設施監控系統是一個先進的平臺,用于監控和管理華為云在全球各個region的基礎設施,該系統需要實時監測各種資源,包括網路、存盤、計算、安全和各個云服務,
現狀
業務誕生之初,適逢“大資料”時代,Hadoop作為批量離線計算系統已經得到了業界的普遍認可,并經過了工業上的驗證,所以HBase具備“站在巨人肩膀之上”的優勢,其發展勢頭非常迅猛,HBase還是一種NoSQL資料庫,支持水平擴展和大規模資料的存盤能力,故選型HBase,當然內部也基于HBase做過很多優化,比如縮短row key,減少Key-Value數,按照時間維度分表,將單行多列變為單行單列,
痛點
隨著華為云業務擴展,特別是近些年,華為云在全球布局的速度也突飛猛進,所要監控的設備也越來越多,顆粒度越來越細,查詢場景也逐漸豐富,HBase明顯已經無法滿足當前業務需要,問題主要體現在以下幾點:
- HBase不支持高階聚合查詢,時間范圍太大的查詢性能比較差,無法渲染圖表
- HBase沒有特定的壓縮演算法,應對每天上百TB資料,存盤成本長期居高不下
- HBase部署需要依賴第三方組件HDFS和Zookeeper,運維成本高
技術選型
為了解決這些痛點,我們將目光投向時下流行的時序資料庫(Time-Series Database),首先在DBEngines排名前20的開源時序資料庫中甄別,排除商業品類、開源協議不友好的,初步擬選了InfluxDB、Druid、Prometheus、OpenTSDB幾款,經過技術對比,InfluxDB只有單機版,功能和性能受限大,故排除,OpenTSDB底層存盤仍然是HBase,存盤成本問題仍然存在,故排除,Prometheus不適合在大規模資料場景下使用,Druid是一個實時分析型的資料庫,用于大規模實時資料匯入、快速查詢分析的場景,基本滿足需求,但在時空聚合查詢場景時延相對較大,徘徊之際,了解到華為云開源的openGemini,經過測驗對比,openGemini在資料壓縮效率、讀寫性能方面優勢明顯,經過和openGemini社區團隊交流后,最后選擇了openGemini存盤全網華為云SRE基礎設施監控資料,
性能測驗
寫性能
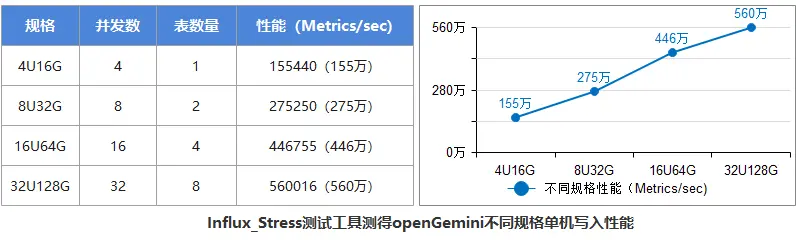
上述測驗結果顯示了openGemini 從4U擴展到32U的性能表現,可以看出:
- 從4U到32U,openGemini寫入性能可以線性擴展(擴展比為0.8)
- 從4U的155萬Metrics/s平穩增長到32U的560萬Metrics/s
查詢性能
查詢性能是我們重點考慮的方面,測驗工具Jmeter,測驗場景從業務中挑選了使用頻率較高的三種型別查詢陳述句,在此基礎上變化查詢并發數、查詢時間范圍、聚合算子等進行測驗,
測驗陳述句舉例:

測驗規格與集群部署

測驗結果(20并發6h 表示查詢并發為20,時間范圍為6小時)
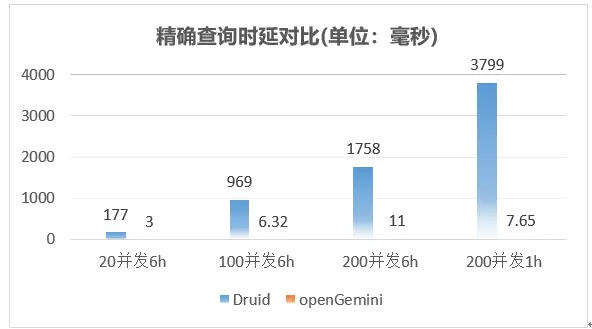
精確查詢整體性能表現如下:
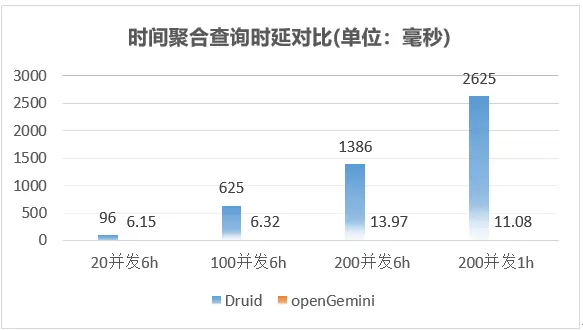
時間聚合查詢整體性能表現如下
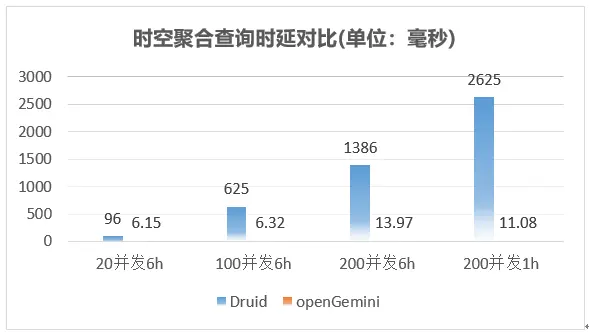
時空聚合查詢整體性能表現如下
測驗結論
整體上,openGemini在上述三種查詢場景下,相比Druid性能大幅領先,openGemini寫入性能滿足目前同樣流量大小的HBase集群,而且使用的規模要小不少,此外,openGemini不依賴任何第三方組件或應用,同時還有非常豐富的監控指標,更好的觀察系統的運行狀況,快速定位和解決問題,
遷移方案
資料雙寫
采用openGemini后,并沒有立即拆除已有系統,主要考慮兩方面:
- 如果openGemini出現問題可以迅速把流量切回去,保證現網業務運行平穩,
- HBase的資料不能直接遷移到openGemini,如果開發遷移工具成本又很高,故HBase和openGemini雙寫,在此過渡期間是個好的辦法,
查詢切流
我們給openGemini和HBase配置了不同的DNS,切換DNS就可以非常方便地查詢不同資料庫的資料,對現網可靠性也不會產生影響,
實際效果
截止目前,已實作全網流量切入openGemini,系統平穩運行超過半年,
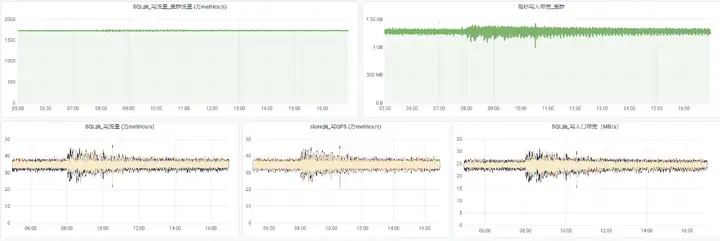
和之前的HBase對比:
- 單region下,HBase集群規模從數百計算節點降至數十節點,規模縮減60%以上
- 截止目前,上線集群平均每秒寫入達到1.81億條指標資料,存盤空間節約超90%,CPU資源上可以節省68%,記憶體資源可以節省50%
- 查詢性能大幅提升
總結
openGemini的設計和優化都是根據時序資料特點而來,在面對海量運維監控資料處理需求時,openGemini顯然更加有針對性,而以上的事實證明,在運維監控場景中,openGemini的應用能夠提升運維效率,降低運維成本,真正幫助企業實作降本增效,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/540419.html
標籤:大數據
上一篇:關系型資料庫設計三大范式