
本文從 5W1H 角度介紹了分庫分表手段,其在解決如 IO 瓶頸、讀寫性能、物理存盤瓶頸、記憶體瓶頸、單機故障影響面等問題的同時也帶來如事務性、主鍵沖突、跨庫 join、跨庫聚合查詢等問題,anyway,在綜合業務場景考慮,正如快取的使用一樣,本著非必須勿使用原則,如資料庫確實成為性能瓶頸時,在設計分庫分表方案時也應充分考慮方案的擴展性,或者考慮采用成熟熱門的分布式資料庫解決方案,如 TiDB,
閱讀此文你將了解:
- 什么是分庫分表以及為什么分庫分表
- 如何分庫分表
- 分庫分表常見幾種方式以及優缺點
- 如何選擇分庫分表的方式
資料庫常見優化方案
對于后端程式員來說,繞不開資料庫的使用與方案選型,那么隨著業務規模的逐漸擴大,其對于存盤的使用上也需要隨之進行升級和優化,
隨著規模的擴大,資料庫面臨如下問題:
- 讀壓力:并發 QPS、索引不合理、SQL 陳述句不合理、鎖粒度
- 寫壓力:并發 QPS、事務、鎖粒度
- 物理性能:磁盤瓶頸、CPU 瓶頸、記憶體瓶頸、IO 瓶頸
- 其他:宕機、網路例外
面對上述問題,常見的優化手段有:
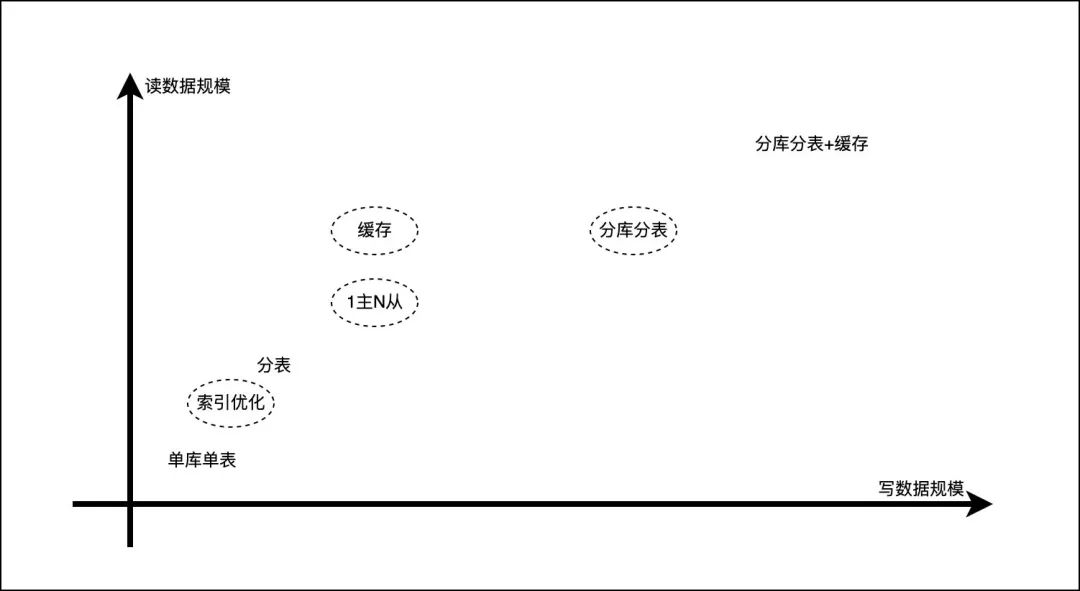
索引優化、主從同步、快取、分庫分表每個技術手段都可以作為一個專題進行講解,本文主要介紹分庫分表的技術方案實作,
什么是分庫分表?
對于閱讀本文的讀者來說,分庫分表概念應該并不會陌生,其拆開來講是分庫和分表兩個手段:
- 分表:將一個表中的資料按照某種規則分拆到多張表中,降低鎖粒度以及索引樹,提升資料查詢效率,
- 分庫:將一個資料庫中的資料按照某種規則分拆到多個資料庫中,以緩解單服務器的壓力(CPU、記憶體、磁盤、IO),
為什么分庫分表?
-
性能角度:CPU、記憶體、磁盤、IO 瓶頸
- 隨著業務體量擴大,資料規模達到百萬行,資料庫索引樹龐大,查詢性能出現瓶頸,
- 用戶并發流量規模擴大,由于單庫(單服務器)物理性能限制也無法承載大流量,
-
可用性角度:單機故障率影響面
-
如果是單庫,資料庫宕機會導致 100%服務不可用,N 庫則可以將影響面降低 N 倍,
分庫分表帶來的問題?
-
事務性問題
- 方案一:在進行分庫分表方案設計程序中,從業務角度出發,盡可能保證一個事務所操作的表分布在一個庫中,從而實作資料庫層面的事務保證,
- 方案二:方式一無法實作的情況下,業務層引入分布式事務組件保證事務性,如事務性訊息、TCC、Seata 等分布式事務方式實作資料最終一致性,
-
分庫可能導致執行一次事務所需的資料分布在不同服務器上,資料庫層面無法實作事務性操作,需要更上層業務引入分布式事務操作,難免會給業務帶來一定復雜性,那么要想解決事務性問題一般有兩種手段:
-
主鍵(自增 ID)唯一性問題
- 在資料庫表設計時,經常會使用自增 ID 作為資料主鍵,這就導致后續在遷庫遷表、或者分庫分表操作時,會因為主鍵的變化或者主鍵不唯一產生沖突,要解決主鍵不唯一問題,有如下方案:
- 方案一:自增 ID 做主鍵時,設定自增步長,采用等引數列遞增,避免各個庫表的主鍵沖突,但是這個方案仍然無法解決遷庫遷表、以及分庫分表擴容導致主鍵 ID 變化問題
- 方案二:主鍵采用全域統一 ID 生成機制:如 UUID、雪花演算法、資料庫號段等方式,
-
跨庫多表 join 問題
- 首先來自大廠 DBA 的建議是,線上服務盡可能不要有表的 join 操作,join 操作往往會給后續的分庫分表操作帶來各種問題,可能導致資料的死鎖,可以采用多次查詢業務層進行資料組裝(需要考慮業務上多次查詢的事務性的容忍度)
-
跨庫聚合查詢問題
分庫分表會導致常規聚合查詢操作,如 group by,order by 等變的例外復雜,需要復雜的業務代碼才能實作上述業務邏輯,其常見操作方式有:
§ 方案一:賽道賽馬機制,每次從 N 個庫表中查詢出 TOP N 資料,然后在業務層代碼中進行聚合合并操作,
§ 假設: 以2庫1表為例,每次分頁查詢N條資料, § § 第一次查詢: § ① 每個表中分別查詢出N條資料: § SELECT * FROM db1_table1 where $col > 0 order by $col LIMITT 0,N § SELECT * FROM db2_table1 where $col > 0 order by $col LIMITT 0,N § ② 業務層代碼對上述兩者做歸并排序,假設最終取db1資料K1條,取db2資料K2條,則K1+K2 = N § 此時的DB1 可以計算出OffSet為K1 ,DB2計算出Offset為K2 § 將獲取的N條資料以及相應的Offset K1/K2回傳給 端上, § § 第二次查詢: § ① 端上將上一次查詢對應的資料庫的Offset K1/K2 傳到后端 § ② 后端根據Offset構造查詢陳述句查詢分別查詢出N條陳述句 § SELECT * FROM db1_table1 where $col > 0 order by $col LIMITT $K1,N § SELECT * FROM db2_table1 where $col > 0 order by $col LIMITT $K2,N § ③ 再次使用歸并排序,獲取TOP N資料,將獲取的N條資料以及相應的Offset K1/K2回傳給 端上, § § 第三次查詢: 依次類推.......
§ 方案二:可以將經常使用到 groupby,orderby 欄位存盤到一個單一庫表(可以是 REDIS、ES、MYSQL)中,業務代碼中先到單一表中根據查詢條件查詢出相應資料,然后根據查詢到的主鍵 ID,到分庫分表中查詢詳情進行回傳,2 次查詢操作難點會帶來介面耗時的增加,以及極端情況下的資料不一致問題,
什么是好的分庫分表方案?
-
滿足業務場景需要:根據業務場景的不同選擇不同分庫分表方案:比如按照時間劃分、按照用戶 ID 劃分、按照業務能力劃分等
-
方案可持續性:
- 何為可持續性?其實就是:業務資料量級和流量量級未來進一步達到新的量級的時候,我們的分庫分表方案可以持續靈活擴容處理,
-
最小化資料遷移:擴容時一般涉及到歷史資料遷移,其擴容后需要遷移的資料量越小其可持續性越強,理想的遷移前后的狀態是(同庫同表>同表不同庫>同庫不同表>不同庫不同表)
-
資料偏斜:資料在庫表中分配的均衡性,盡可能保證資料流量在各個庫表中保持等量分配,避免熱點資料對于單庫造成壓力,
- 最大資料偏斜率:(資料量最大樣本 - 資料量最小樣本)/ 資料量最小樣本,一般來說,如果我們的最大資料偏斜率在 5%以內是可以接受的,
如何分庫分表
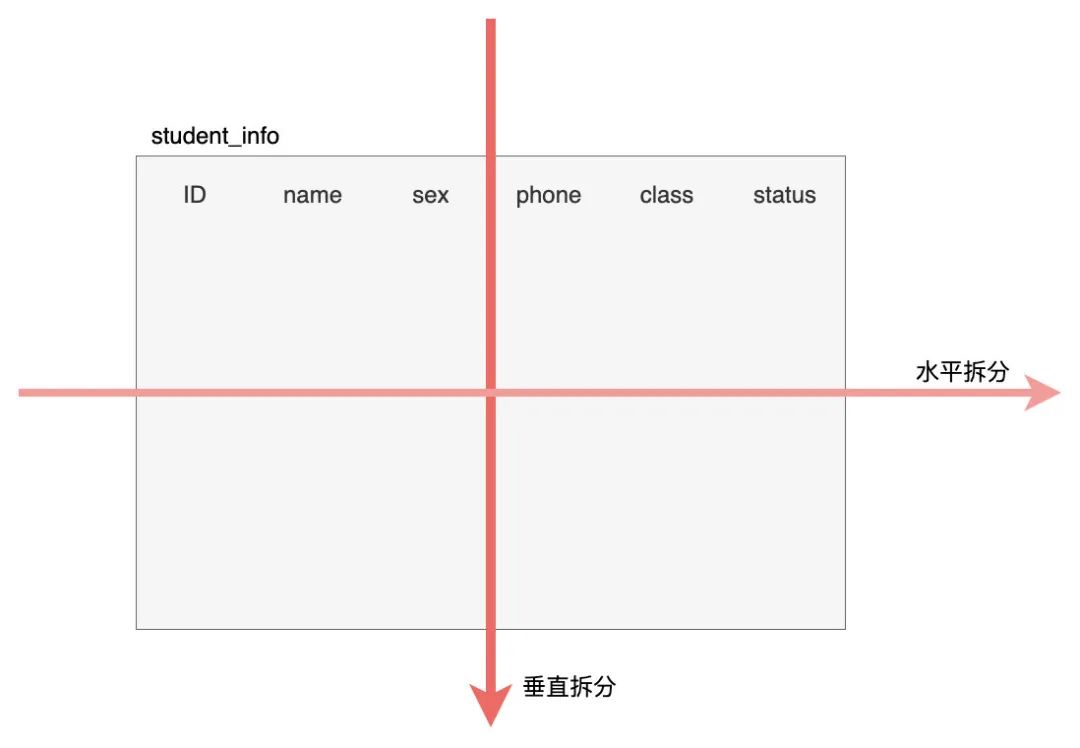
垂直拆分:
-
垂直拆表
- 即大表拆小表,將一張表中資料不同”欄位“分拆到多張表中,比如商品庫將商品基本資訊、商品庫存、賣家資訊等分拆到不同庫表中,
- 考慮因素有將不常用的,資料較大,長度較長(比如 text 型別欄位)的拆分到“擴展表“,表和表之間通過”主鍵外鍵“進行關聯,
- 好處:降低表資料規模,提升查詢效率,也避免查詢時資料量太大造成的“跨頁”問題,
-
垂直拆庫
- 垂直拆庫則在垂直拆表的基礎上,將一個系統中的不同業務場景進行拆分,比如訂單表、用戶表、商品表,
- 好處:降低單資料庫服務的壓力(物理存盤、記憶體、IO 等)、降低單機故障的影響面
水平拆分:
-
操作:將總體資料按照某種維度(時間、用戶)等分拆到多個庫中或者表中,典型特征不同的庫和表結構完全一下,如訂單按照(日期、用戶 ID、區域)分庫分表,
-
水平拆表
- 將資料按照某種維度拆分為多張表,但是由于多張表還是從屬于一個庫,其降低鎖粒度,一定程度提升查詢性能,但是仍然會有 IO 性能瓶頸,
-
水平拆庫
- 將資料按照某種維度分拆到多個庫中,降低單機單庫的壓力,提升讀寫性能,
常見水平拆分手段
range 分庫分表
顧名思義,該方案根據資料范圍劃分資料的存放位置,
思路一:時間范圍分庫分表
舉個最簡單例子,我們可以把訂單表按照年份為單位,每年的資料存放在單獨的庫(或者表)中,
時下非常流行的分布式資料庫:TiDB 資料庫,針對 TiKV 中資料的打散,也是基于 Range 的方式進行,將不同范圍內的[StartKey,EndKey)分配到不同的 Region 上,
缺點:
- 需要提前建庫或表,
- 資料熱點問題:當前時間的資料會集中落在某個庫表,
- 分頁查詢問題:涉及到庫表中間分界線查詢較復雜,
例子:交易系統流水表則是按照天級別分表,
hash 分庫分表
hash 分表是使用最普遍的使用方式,其根據“主鍵”進行 hash 計算資料存盤的庫表索引,原理可能大家都懂,但有時拍腦袋決定的分庫分表方案可能會導致嚴重問題,
思路一:獨立 hash
對于分庫分表,最常規的一種思路是通過主鍵計算 hash 值,然后 hash 值分別對庫數和表數進行取余操作獲取到庫索引和表索引,比如:電商訂單表,按照用戶 ID 分配到 10 庫 100 表中,
const ( // DbCnt 庫數量 DbCnt = 10 // TableCnt 表數量 TableCnt = 100 ) // GetTableIdx 根據用戶 ID 獲取分庫分表索引 func GetTableIdx(userID int64) (int64, int64) { hash := hashCode(userID) return hash % DbCnt, hash % TableCnt }
上述是偽代碼實作,大家可以先思考一下上述代碼可能會產生什么問題?
比如 1000? 1010?,1020 庫表索引是多少?
思考一下........
思考一下........
思考一下........
思考一下........
思考一下........
思考一下........
答:資料偏斜問題,
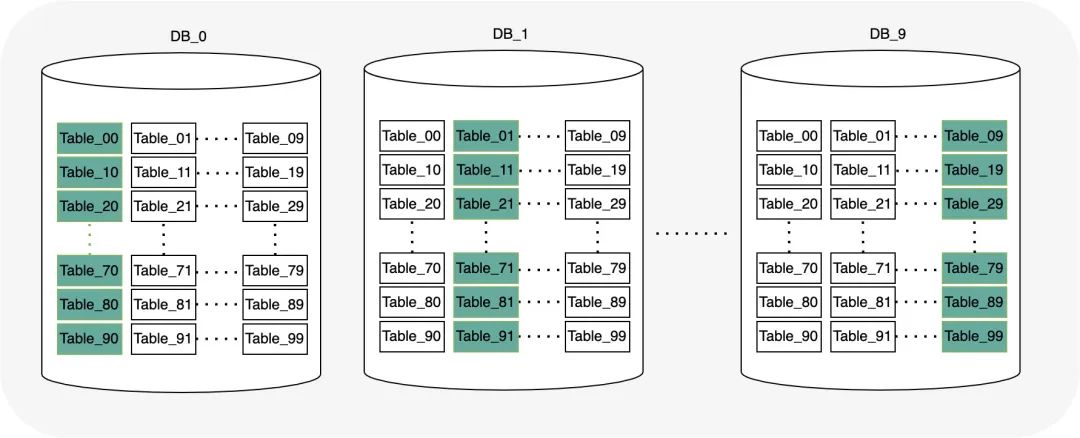
非互質關系導致的資料偏斜問題證明:
假設分庫數分表數最大公約數為a,則分庫數表示為 m*a , 分表數為 n*a (m,n為正整數) 某條資料的hash規則計算的值為H, 若某條資料在庫D中,則H mod (m*a) == D 等價與 H=M*m*a+D (M為整數) 則表序號為 T = H % (n*a) = (M*m*a+D)%(n*a) 如果D==0 則T= [(M*m)%n]*a
思路二:統一 hash
思路一中,由于庫和表的 hash 計算中存在公共因子,導致資料偏斜問題,那么換種思考方式:10 個庫 100 張表,一共 1000 張表,那么從 0 到 999 排序,根據 hash 值對 1000 取余,得到[0,999]的索引,似乎就可以解決資料偏斜問題:
// GetTableIdx 根據用戶 ID 獲取分庫分表索引 // 例子:1123011 -> 1,1 func GetTableIdx(userID int64) (int64, int64) { hash := hashCode(userID) slot := DbCnt * TableCnt return hash % slot % DbCnt, hash % slot / DbCnt }
上面會帶來的問題?
比如 1123011 號用戶,擴容前是 1 庫 1 表,擴容后是 0 庫 11 表
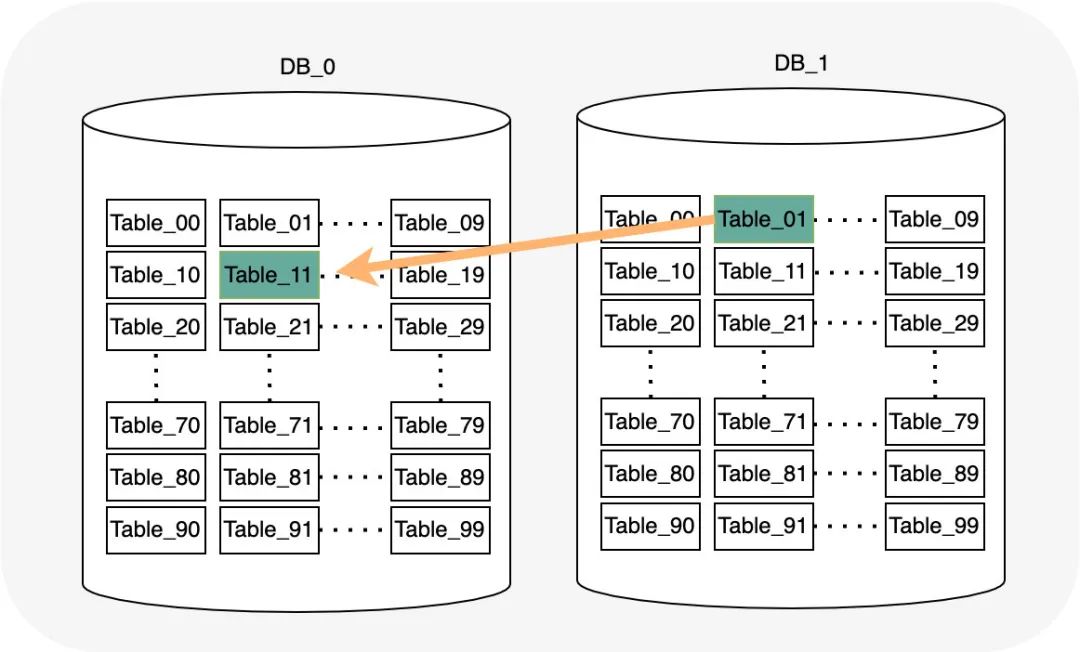
擴展性問題證明,
某條資料的hash規則計算的值為H,分庫數為D,分表數為T 擴容前: 分片序號K1 = H % (D*T),則H = M*DT + K1 ,且K1 一定是小于(D*T) D1 = K1 % D T1 = K1 / D 擴容后: 如果M為偶數,即M= 2*N K2 = H% (2DT) = (2NDT+K1)%(2DT) = K1%(2DT) ,K1 一定小于(2DT),所以K2=K1 D2 = K2%(2D) = K1 %(2D) T2 = K2/(2D) = K1 / (2D) 如果M為奇數,即M = 2*N+1 K2 = H%(2DT) = (2NDT +DT +K1)%(2DT) = (DT+K1)%(2DT) = DT + K1 D2 = K2 %(2D) = (DT+K1) % (2D) T2 = K2 /(2D) = (DT+K1) / (2D) 結論:擴容后庫序號和表序號都變化
思路三:二次分片法
思路二中整體思路正確,只是最后計算庫序號和表序號的時候,使用了庫數量作為影響表序號的因子,導致擴容時表序號偏移而無法進行,事實上,我們只需要換種寫法,就能得出一個比較大眾化的分庫分表方案,
func GetTableIdx(userId int64){ //①算Hash hash:=hashCode(userId) //②分片序號 slot:=hash%(DbCnt*TableCnt) //③重新修改二次求值方案 dbIdx:=slot/TableCnt tblIdx:=slot%TableCnt return dbIdx,tblIdx }
從上述代碼中可以看出,其唯一不同是在計算庫索引和表索引時,采用 TableCnt 作為基數(注:擴容操作時,一般采用庫個數 2 倍擴容),這樣在擴容時,表個數不變,則表索引不會變,
可以做簡要的證明:
某條資料的hash規則計算的值為H,分庫數為D,分表數為T
擴容前: 分片序號K1 = H % (D*T),則H = M*DT + K1 ,且K1 一定是小于(D*T) D1 = K1 / T T1 = K1 % T 擴容后: 如果M為偶數,即M= 2*N K2 = H% (2DT) = (2NDT+K1)%(2DT) = K1%(2DT) ,K1 一定小于(2DT),所以K2=K1 D2 = K2/T = K1 /T = D1 T2 = K2%T = K1 % T = T1 如果M為奇數,即M = 2*N+1 K2 = H%(2DT) = (2NDT +DT +K1)%(2DT) = (DT+K1)%(2DT) = DT + K1 D2 = K2 /T = (DT+K1) / T = D + K1/T = D + D1 T2 = K2 %T = (DT+K1) % T = K1 %T = T1 結論: M為偶數時,擴容前后庫序號和表序號都不變 M為奇數時,擴容前后表序號不變,庫序號會變化,
思路四:基因法
由思路二啟發,我們發現案例一不合理的主要原因,就是因為庫序號和表序號的計算邏輯中,有公約數這個因子在影響庫表的獨立性,那么我們是否可以換一種思路呢?我們使用相對獨立的 Hash 值來計算庫序號和表序號呢?
func GetTableIdx(userID int64)(int64,int64){ hash := hashCode(userID) return atoi(hash[0:4]) % DbCnt,atoi(hash[4:])%TableCnt }
這也是一種常用的方案,我們稱為基因法,即使用原分片鍵中的某些基因(例如前四位)作為庫的計算因子,而使用另外一些基因作為表的計算因子,
在使用基因法時,要主要計算 hash 值的片段保持充分的隨機性,避免造成嚴重資料偏斜問題,
思路五:關系表冗余
按照索引的思想,可以通過分片的鍵和庫表索引建立一張索引表,我們把這張索引表叫做“路由關系表”,每次查詢操作,先去路由表中查詢到資料所在的庫表索引,然后再到庫表中查詢詳細資料,同時,對于寫入操作可以采用隨機選擇或者順序選擇一個庫表進入寫入,
那么由于路由關系表的存在,我們在資料擴容時,無需遷移歷史資料,同時,我們可以為每個庫表指定一個權限,通過權重的比例調整來調整每個庫表的寫入資料量,從而實作庫表資料偏斜率調整,
此種方案的缺點是每次查詢操作,需要先讀取一次路由關系表,所以請求耗時可能會有一定增加,本身由于寫索引表和寫庫表操作是不同庫表寫操作,需要引入分布式事務保證資料一致性,極端情況可能帶來資料的不一致,
且索引表本身沒有分庫分表,自身可能會存在性能瓶頸,可以通過存盤在 redis 進行優化處理,
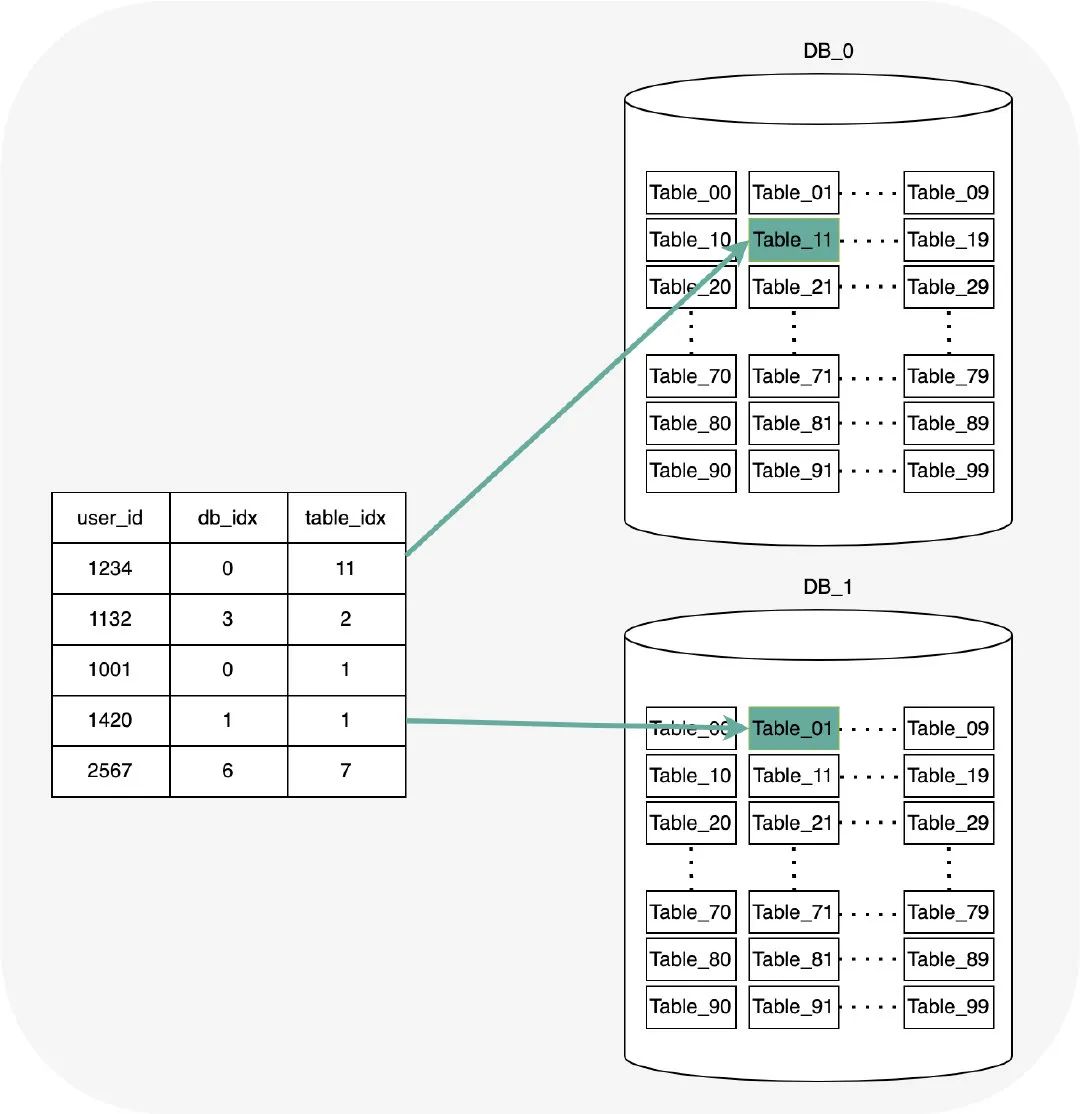
思路六:分段索引關系表
思路五中,需要將全量資料存在到路由關系表中建立索引,再結合 range 分庫分表方案思想,其實有些場景下完全沒有必要全部資料建立索引,可以按照號段式建立區間索引,我們可以將分片鍵的區間對應庫的關系通過關系表記錄下來,每次查詢操作,先去路由表中查詢到資料所在的庫表索引,然后再到庫表中查詢詳細資料,
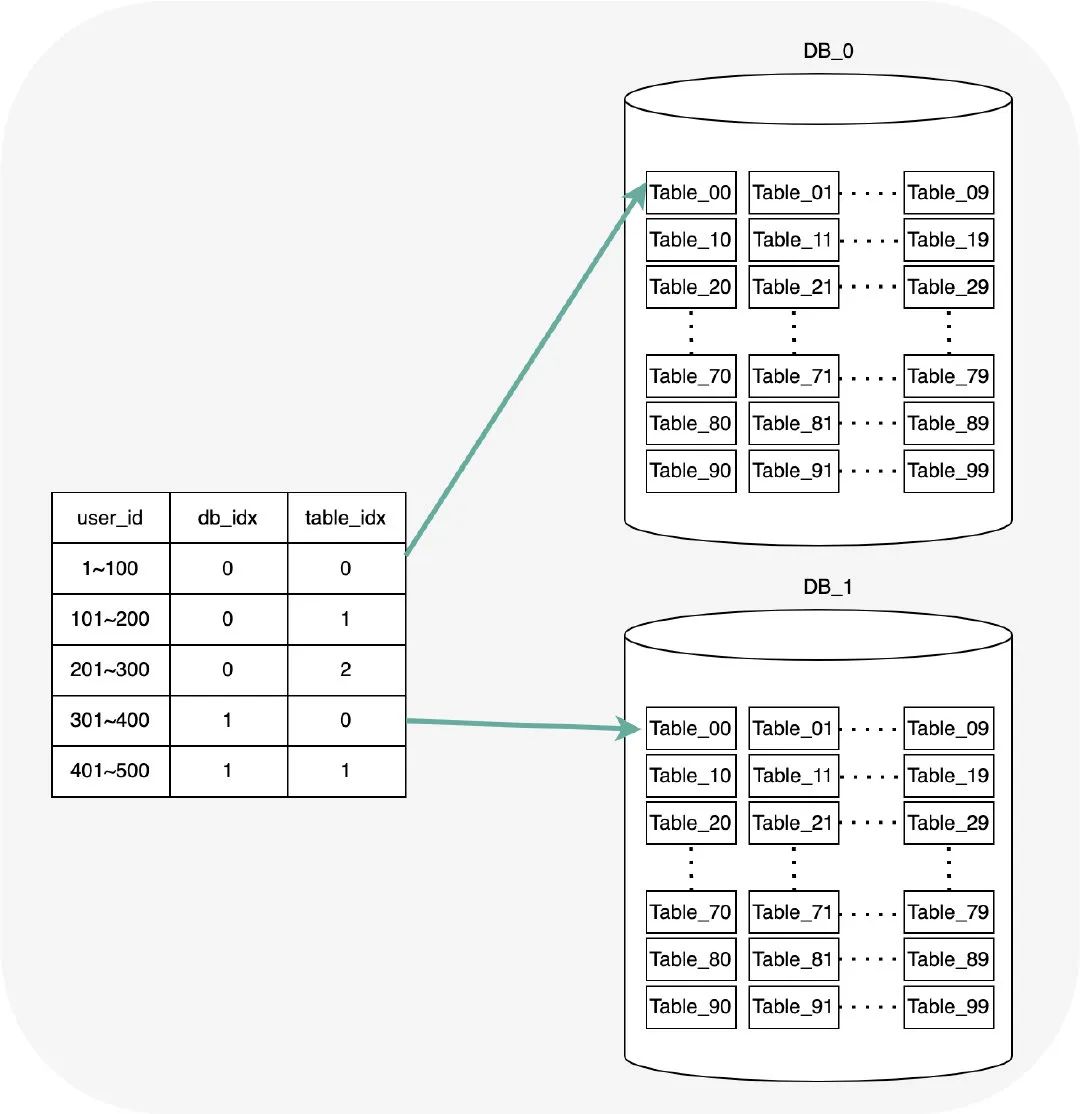
思路七:一致性 Hash 法
一致性 Hash 演算法也是一種比較流行的集群資料磁區演算法,比如 RedisCluster 即是通過一致性 Hash 演算法,使用 16384 個虛擬槽節點進行每個分片資料的管理,關于一致性 Hash 的具體原理這邊不再重復描述,讀者可以自行翻閱資料,
其思想和思路五有異曲同工之妙,
總結
本文從 5W1H 角度介紹了分庫分表手段,其在解決如 IO 瓶頸、讀寫性能、物理存盤瓶頸、記憶體瓶頸、單機故障影響面等問題的同時,也帶來如事務性、主鍵沖突、跨庫 join、跨庫聚合查詢等問題,anyway,在綜合業務場景考慮,正如快取的使用一樣,非必須使用分庫分表,則不應過度設計采用分庫分表方案,如資料庫確實成為性能瓶頸時,在設計分庫分表方案時也應充分考慮方案的擴展性,或者說可以考慮采用成熟熱門的分布式資料庫解決方案,如 TiDB,
作者:tayroctang
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/One-article-reading-database-optimization-sub-database-sub-table.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/541158.html
標籤:SQL Server