微信公眾號中(這里)看到一個關于MySQL的innodb_deadlock_detect與并發相關的細節,覺得比較有意思,也即innodb_deadlock_detect這個引數的設定問題

死鎖檢測是一個MySQL Server層的自動檢測機制,可以及時發現兩個或者多個session間互斥資源的申請造成的死鎖,且會自動回滾一個(或多個)事物代價相對較小的session,讓執行代價最大的先執行,
該引數默認就是打開的,按理說也是必須要打開的,甚至在其他資料庫中沒有可以使其關閉的選項,
innodb_deadlock_detect
如果關閉innodb_deadlock_detect,也即關閉了死鎖自動監測機制時,當兩個或多個session間存在死鎖的情況下,MySQL怎么去處理?
這里會涉及到另外一個引數:鎖超時,也即innodb_lock_wait_timeout,該引數指定了“鎖申請時候的最長等待時間”
官方的解釋是:The length of time in seconds an InnoDB transaction waits for a row lock before giving up.
innodb_lock_wait_timeout默認值是50秒,也就是意味著session請求時,申請不到鎖的情況下最多等待50秒鐘,然后呢,就等價于死鎖,自動回滾當前事物了?其實不是的,事情沒有想象中的簡單,
innodb_rollback_on_timeout
這里就涉及到另外一個引數:innodb_rollback_on_timeout,默認值是off,該引數的決定了當前請求鎖超時之后,回滾的是整個事物,還是僅當前陳述句,
官方的解釋是:InnoDB rolls back only the last statement on a transaction timeout by default,
默認值是off,也就是回滾當前陳述句(放棄當前陳述句的鎖申請),有人強烈建議打開這個選項(on),也就是一旦鎖申請超時,就回滾整個事物,
需要注意的是,默認情況下只回滾當前陳述句,而不是整個事物,當前的事物還在繼續,連接也還在,這里與死鎖自動監測機制打開之后會主動犧牲一個事物不同,鎖超時后并不會主動犧牲其中任何一個事物,
這意味著會出現一種非常嚴重的情況,舉個例子,可以想象一下如下這種情況:
session1 session2
start transaction; start transaction;
update A set val = 'xxx' where id = 1 update B set val = 'yyy' where id = 1
…… ……
update B set val = 'xxx' where id = 1 update A set val = 'yyy' where id = 1
if 鎖超時 if 鎖超時
#繼續申請鎖 #繼續申請鎖
update B set val = 'xxx' where id = 1 update A set val = 'xxx' where id = 1
關閉了死鎖監測機制后,在innodb_rollback_on_timeout保持默認的off的情況下,session1和session2都是無法正常執行下去的,且永遠都無法執行下去,
任意一個session出現鎖超時,放棄當前的陳述句申請的鎖,而不是整個事物持有的鎖,當前session并不釋放其他session請求的鎖資源,
即便是繼續下去,依舊如此,兩者又陷入了相互等待,相互鎖請求超時,繼續死回圈,
從這里可以看到,與死鎖自動檢測機制在發現死鎖是主動選擇一個作為犧牲品不同,一旦關閉了innodb_deadlock_detect,Session中的任意一方都不會主動釋放已經持有的鎖,
此時如果應用程式如果不足夠的健壯,繼續去申請鎖(比如重試機制,嘗試重試相關陳述句),session雙方會陷入到無限制的鎖超時死回圈之中,
事實上推論是不是成立的?做個測驗驗證一下,資料庫環境資訊如下
模擬事物雙方在當前陳述句的鎖超時之后,繼續申請鎖,確實是會出現無限制的鎖超時的死回圈之中,
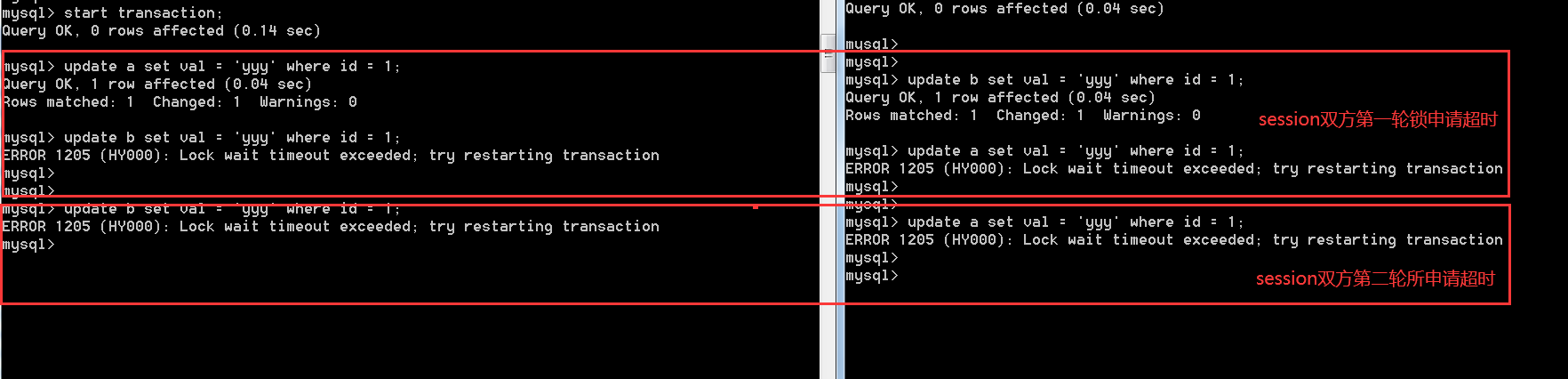
以上就比較有意思了,與死鎖主動監測并犧牲其中一個事物不同,此時事物雙方互不相讓,當然也都無法成功執行,
這只不過是一個典型的負面場景,除此之外,還會有哪些問題值得思考?
1,因為事物無法快速提交或者回滾,那么連接持有的時間會增加,一旦并發量上來,連接數可能成為一個問題,
2,鎖超時時間肯定要設定為一個相對較小的時間,但具體又設定為多少靠譜,
3,關閉死鎖檢測,帶來的收益,與副作用相比哪個更高,當前業務型別是否需要關閉死鎖檢測,除非資料庫中相關操作大部分都是短小事物且所沖突的可能性較低,
4,面對鎖超時,應用程式端如何合理地處理鎖超時的情況,是重試還是放棄,
5,與此關聯的innodb_rollback_on_timeout如何設定,是保持默認的關閉(鎖超時的情況下,取消當前陳述句的所申請),還是打開(鎖超時的情況下,回滾整個事物)
最后,其實這個問題屬于一個系統工程,不是一個單點問題,除此之外還有可能潛在一些其他的問題,原作者是大神,當然是一個整體方案,需要在整體架構上做處理,作者也給出了一個客觀的處理方式,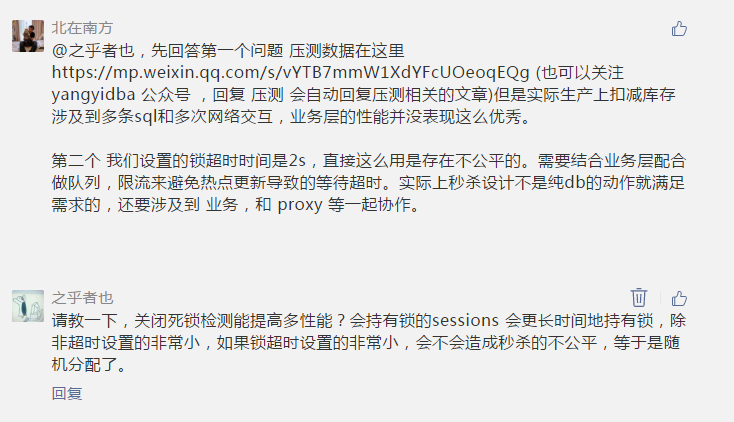
參考鏈接
https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_lock_wait_timeout
關于innodb_deadlock_detect引數,這里有一篇比較好的文章,來源:https://www.fromdual.com/comment/1018
以下為譯文:
最近,我們有一位新客戶,他時不時遇到大量他無法理解的資料庫問題,當我們查看 MySQL 組態檔 (my.cnf) 時,我們發現此客戶已禁用 InnoDB 死鎖檢測 (innodb_deadlock_detect),
因為到目前為止,我們建議不要這樣做,但在實踐中我從未偶然發現過這個問題,所以我對MySQL變數innodb_deadlock_detect進行了更多的調查,
MySQL 檔案告訴我們以下 {1}:
禁用死鎖檢測
在高并發系統上,當許多執行緒等待同一鎖時,死鎖檢測可能會導致速度變慢,有時,禁用死鎖檢測并依賴于innodb_lock_wait_timeout設定以在發生死鎖時進行事務回滾可能更有效,可以使用innodb_deadlock_detect配置選項禁用死鎖檢測,
關于引數innodb_deadlock_detect本身 [2] :
此選項用于禁用死鎖檢測,在高并發系統上,當許多執行緒等待同一鎖時,死鎖檢測可能會導致速度變慢,有時,禁用死鎖檢測并依賴于innodb_lock_wait_timeout設定以在發生死鎖時進行事務回滾可能更有效,
問題是,每次 MySQL 執行 (行)鎖或表鎖時,如果鎖導致死鎖,都會進行檢查,這個檢查的代價很高,順便說一下:禁用InnoDB死鎖檢測的功能是由Facebook為WebScaleSQL開發的[3],
相關功能可在 [4] 中找到:
class DeadlockChecker, method check_and_resolve (DeadlockChecker::check_and_resolve) Every InnoDB (row) Lock (for mode LOCK_S or LOCK_X) and type ORed with LOCK_GAP or LOCK_REC_NOT_GAP, ORed with LOCK_INSERT_INTENTION Enqueue a waiting request for a lock which cannot be granted immediately. lock_rec_enqueue_waiting()
和
Every (InnoDB) Table Lock Enqueues a waiting request for a table lock which cannot be granted immediately. Checks for deadlocks. lock_table_enqueue_waiting()
這意味著,如果變數innodb_deadlock_detect為每個鎖定(行或表)啟用(= 默認值),則檢查該變數(如果導致死鎖),
如果禁用該變數,則檢查未完成(速度更快),事務將掛起(死)鎖定,直到釋放鎖定或超過innodb_lock_wait_timeout時間(默認 50 秒),然后 InnoDB 鎖定等待超時(探測器?)罷工并殺死事務,
SQL> SHOW GLOBAL VARIABLES LIKE 'innodb_lock_wait%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_lock_wait_timeout | 50 |
+--------------------------+-------+
這意味著,停用 InnoDB 死鎖檢測是有趣的,如果你有許多(如 Facebook一樣)短小事物,你期望現在很少發生沖突,此外,建議將 MySQL 變數innodb_lock_wait_timeout設定為非常小的值(幾秒),
因為我們的大多數客戶沒有 Facebook 的規模,因為他們沒有那么多并發的短交易和小交易,而是很少但交易多(可能有許多鎖,因此存在高死鎖概率),我可以想象,禁用此引數是客戶系統的hickup(鎖堆積)的原因,
這導致超過max_connections,最后整個系統崩潰,
因此,我強烈建議,讓InnoDB死鎖檢測啟用,除了你知道你在做什么(經過大約2周的廣泛測驗和測量),
參考文獻
- [1] Deadlock Detection and Rollback
- [2] InnoDB Startup Options and System Variables: innodb_deadlock_detect
- [3] Introduction of the variable
innodb_deadlock_detectin WebScaleSQL by Facebook on Github - [4] MariaDB/MySQL Source Code:
storage/innobase/lock/lock0lock.cc - [5] MariaDB InnoDB System Variables: innodb_deadlock_detect
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/54227.html
標籤:MySQL
下一篇:mongo連接報錯