YARN簡介
一、YARN是什么
YARN不是facebook的那個yarn,它從Hadoop 2引入,最初目的是改善MapReduce的實作,但是因為具備足夠通用性,同樣也可以支持其他的分布式計算模式,YARN全稱是Yet Another Resource Negotiator,翻譯過來是另一種資源協調者,名字聽起來有點奇怪,但是不難看出它的用途是管理和調度Hadoop中的資源,具體來說是計算資源,
YARN和DHFS一樣也是主從架構,它有兩種服務,分為resourcemanager和nodemanager,resourcemanager負責管理nodemanager和application master行程,nodemanager負責管理容器,以及監控容器使用資源,
YARN有幾個重要的概念:
- resourcemanager:資源管理器,管理和協調集群資源
- nodemanager:節點管理器,啟動容器運行應用,監控容器的資源使用資源,周期向資源管理器報告自己的狀態
- container:容器,nodemanager管理的資源的最小單元
- application master:應用的第一個行程,可以直接運行或者繼續向資源管理器申請資源
一個YARN應用的啟動流程如下,圖中每一個虛線框代表一個物理機器:
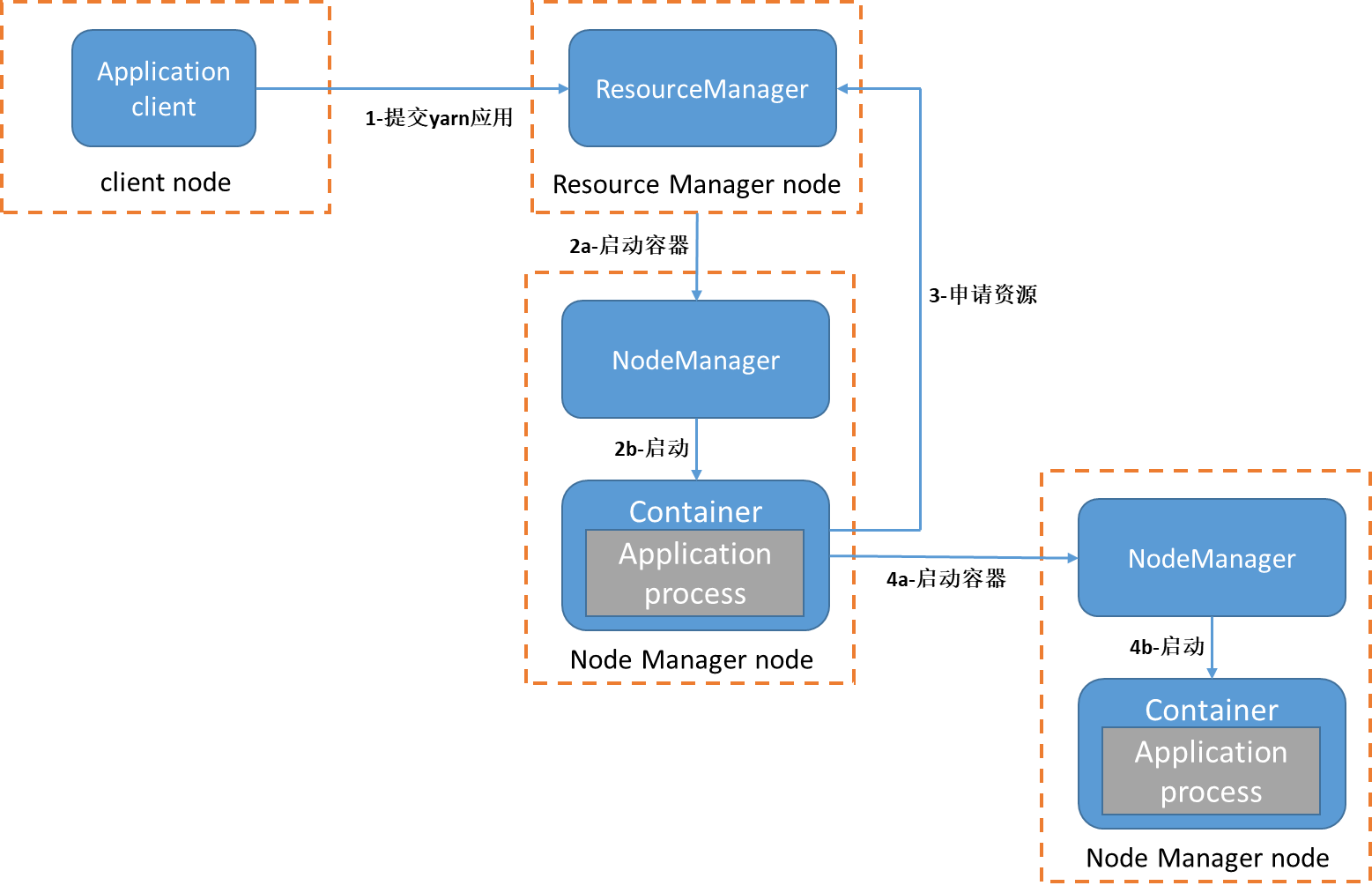
首先客戶端提交作業到resourcemanager資源管理器(圖中第1步),resourcemanager資源管理器尋找集群中可用資源,向nodemanager節點管理器發出創建容器請求(圖中2a步驟),隨后容器啟動并運行應用程式,也就是application master行程(圖中2b步驟),application master會運行周期的向資源管理器報告自己的狀態,應用程式可能做什么取決于應用本身,應用可能只是簡單執行任務,或者向集群繼續申請資源運行多個子任務,例如MapReduce應用,它會把大任務拆分成小任務,然后向resourcemanager資源管理器申請資源(圖中第3步),并且運行小任務(圖中4a和4b步驟),YARN本身并不會為應用的行程提供通信手段,應用之間的通信手段是專屬于應用本身,
二、一個MapReduce應用運行的簡單分析
下面通過在集群運行一個簡單MapReduce應用來理解YARN應用的啟動流程
1、集群拓撲圖
筆者的集群拓撲圖如下:
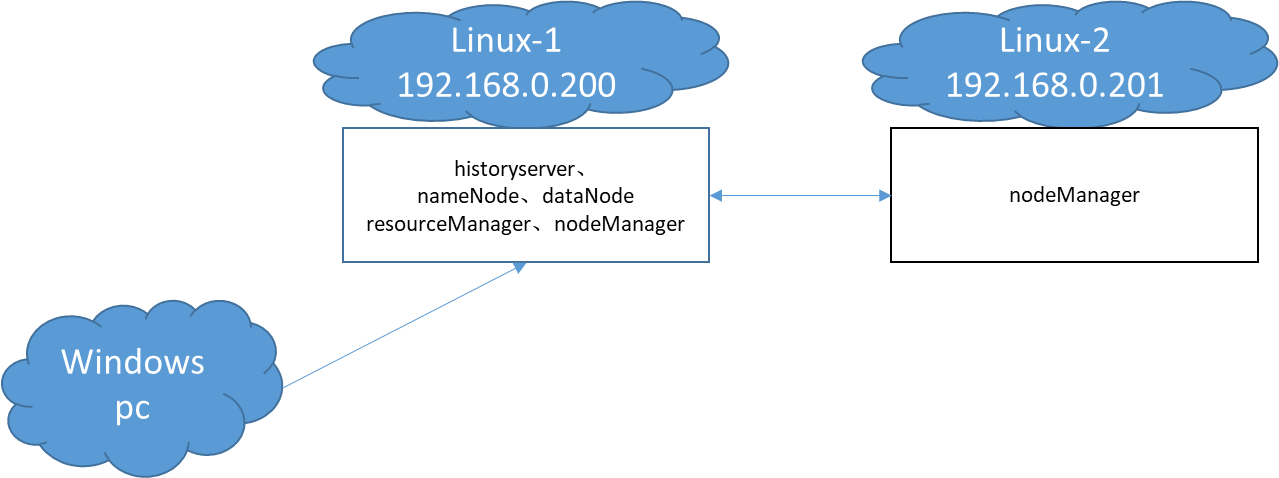
Linux-1運行一個資源管理器和節點管理器,Linux-2只運行一個節點管理器,提交任務的是一臺Windows主機,Windows機器的ip是192.168.0.109
2、應用啟動
先用jps查看集群各個機器當前運行的行程:
-- Linux-1 192.168.0.200
debian@Linux-1:~$ jps
848 ResourceManager
4112 Jps
752 DataNode
1088 NodeManager
663 NameNode
-- Linux-2 192.168.0.201
debian@Linux-2:~$ jps
15893 Jps
10219 NodeManager
然后向集群提交應用,可能會看到如下輸出:
這里提交的應用還是maxSaleMapReduce,唯一不同的是組態檔mapreduce.job.running.map.limit(map同時最大運行數量)設定成3,可以在https://github.com/xunpengliu/hello-hadoop獲取代碼,如果之前已經下載過需要拉取最新代碼后重新打包
23/02/07 17:26:27 INFO client.RMProxy: Connecting to ResourceManager at /192.168.0.200:8032
23/02/07 17:26:37 INFO input.FileInputFormat: Total input files to process : 5
23/02/07 17:26:37 INFO mapreduce.JobSubmitter: number of splits:15
23/02/07 17:26:38 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1675757920071_0004
23/02/07 17:26:38 INFO conf.Configuration: resource-types.xml not found
23/02/07 17:26:38 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
23/02/07 17:26:38 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
23/02/07 17:26:38 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
23/02/07 17:26:38 INFO impl.YarnClientImpl: Submitted application application_1675757920071_0004
23/02/07 17:26:38 INFO mapreduce.Job: The url to track the job: http://192.168.0.200:8088/proxy/application_1675757920071_0004/
23/02/07 17:26:38 INFO mapreduce.Job: Running job: job_1675757920071_0004
23/02/07 17:26:43 INFO mapreduce.Job: Job job_1675757920071_0004 running in uber mode : false
23/02/07 17:26:43 INFO mapreduce.Job: map 0% reduce 0%
23/02/07 17:26:59 INFO mapreduce.Job: map 3% reduce 0%
23/02/07 17:27:00 INFO mapreduce.Job: map 11% reduce 0%
可以看到當前應用id是application_1675757920071_0004,作業id是job_1675757920071_0004,從 http://192.168.0.200:8088/proxy/application_1675757920071_0004/ 可以查詢到應用運行狀態,
等一小會,再使用jps查看運行的行程,可以看到多了1個MRAppMaster和3個YarnChild和行程,查看MRAppMaster行程埠系結情況和NodeManager的行程樹:
-- Linux-1 192.168.0.200
debian@Linux-1:~$ jps
848 ResourceManager
752 DataNode
1088 NodeManager
3649 MRAppMaster
663 NameNode
3754 YarnChild
3789 Jps
debian@Linux-1:~$ pstree -T -p 1088
java(1088)─┬─bash(3628)───bash(3648)───java(3649)
└─bash(3795)───bash(3750)───java(3754)
debian@Linux-1:~$ lsof -i | grep 3649
java 3649 debian 262u IPv6 88478 0t0 TCP *:43763 (LISTEN)
java 3649 debian 273u IPv6 88485 0t0 TCP *:42565 (LISTEN)
java 3649 debian 279u IPv6 88487 0t0 TCP *:41731 (LISTEN)
java 3649 debian 289u IPv6 96002 0t0 TCP 192.168.0.200:50682->192.168.0.200:8030 (ESTABLISHED)
java 3649 debian 291u IPv6 91613 0t0 TCP 192.168.0.200:43763->192.168.0.109:55029 (ESTABLISHED)
java 3649 debian 292u IPv6 96258 0t0 TCP 192.168.0.200:41731->192.168.0.200:46720 (ESTABLISHED)
java 3649 debian 293u IPv6 91977 0t0 TCP 192.168.0.200:41731->192.168.0.201:56746 (ESTABLISHED)
java 3649 debian 261u IPv6 96005 0t0 TCP 192.168.0.200:41731->192.168.0.201:56744 (ESTABLISHED)
-- Linux-2 192.168.0.201
debian@Linux-2:~$ jps
10219 NodeManager
15356 Jps
15326 YarnChild
15295 YarnChild
debian@Linux-2:~$ pstree -T -p 10219
java(10219)─┬─bash(15291)───bash(15293)───java(15295)
└─bash(15320)───bash(15323)───java(15326)
MRAppMaster也就是MapReduce應用的application master行程,它啟動后向資源管理器繼續申請資源,然后啟動3個YARNChild行程來執行子任務,3個子任務分別運行在Linux-1和Linux-2機器上,
maxSaleMapReduce的map任務和reduce任務在啟動和完成會各輸出一行日志,日志內容有ip、行程啟動時間、主類名稱、行程pid,日志檔案位置在userlogs/${appid}目錄中,如果你的集群像筆者一樣沒開日志聚合也沒修改目錄,userlogs目錄在Hadoop安裝位置的logs目錄下,日志是按容器進行分組的,例如Linux-2上的application_1675757920071_0004目錄就有下面幾個檔案夾:
debian@Linux-2:~/program/hadoop-2.10.2/logs/userlogs/application_1675757920071_0004$ ll
總用量 44
drwx--x--- 2 debian debian 4096 2月 7 17:26 container_1675757920071_0004_01_000002
drwx--x--- 2 debian debian 4096 2月 7 17:26 container_1675757920071_0004_01_000003
drwx--x--- 2 debian debian 4096 2月 7 17:27 container_1675757920071_0004_01_000007
drwx--x--- 2 debian debian 4096 2月 7 17:27 container_1675757920071_0004_01_000008
drwx--x--- 2 debian debian 4096 2月 7 17:27 container_1675757920071_0004_01_000009
drwx--x--- 2 debian debian 4096 2月 7 17:27 container_1675757920071_0004_01_000011
drwx--x--- 2 debian debian 4096 2月 7 17:27 container_1675757920071_0004_01_000012
drwx--x--- 2 debian debian 4096 2月 7 17:28 container_1675757920071_0004_01_000014
drwx--x--- 2 debian debian 4096 2月 7 17:28 container_1675757920071_0004_01_000015
drwx--x--- 2 debian debian 4096 2月 7 17:28 container_1675757920071_0004_01_000017
drwx--x--- 2 debian debian 4096 2月 7 17:28 container_1675757920071_0004_01_000018
debian@Linux-2:~/program/hadoop-2.10.2/logs/userlogs/application_1675757920071_0004$ ll container_1675757920071_0004_01_000002
總用量 32
-rw-r--r-- 1 debian debian 0 2月 7 17:26 prelaunch.err
-rw-r--r-- 1 debian debian 70 2月 7 17:26 prelaunch.out
-rw-r--r-- 1 debian debian 0 2月 7 17:26 stderr
-rw-r--r-- 1 debian debian 0 2月 7 17:26 stdout
-rw-r--r-- 1 debian debian 27051 2月 7 17:27 syslog
syslog檔案有我們自定義輸出的日志,日志內容如下:
-- Linux-1 192.168.0.200
debian@Linux-1:~/program/hadoop-2.10.2/logs/userlogs/application_1675757920071_0004$ cat */syslog | grep mainClass
2023-02-07 17:26:44,392 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.200,startTime->2023-02-07 17:26:42,pid->3754,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000002_0, 4]
2023-02-07 17:26:56,849 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.200,pid->3754,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000002_0, 4]
2023-02-07 17:27:06,347 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.200,startTime->2023-02-07 17:27:04,pid->3839,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000003_0, 6]
2023-02-07 17:27:18,586 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.200,pid->3839,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000003_0, 6]
2023-02-07 17:27:27,675 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.200,startTime->2023-02-07 17:27:25,pid->3904,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000006_0, 10]
2023-02-07 17:27:39,979 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.200,pid->3904,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000006_0, 10]
2023-02-07 17:27:48,950 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.200,startTime->2023-02-07 17:27:47,pid->3965,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000009_0, 13]
2023-02-07 17:28:01,263 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.200,pid->3965,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000009_0, 13]
2023-02-07 17:28:10,980 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.200,startTime->2023-02-07 17:28:09,pid->4026,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000012_0, 16]
2023-02-07 17:28:15,964 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.200,pid->4026,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000012_0, 16]
-- Linux-2 192.168.0.201
debian@Linux-2:~/program/hadoop-2.10.2/logs/userlogs/application_1675757920071_0004$ cat */syslog | grep mainClass
2023-02-07 17:26:43,338 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:26:41,pid->15295,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000000_0, 2]
2023-02-07 17:26:58,315 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15295,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000000_0, 2]
2023-02-07 17:26:44,621 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:26:42,pid->15326,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000001_0, 3]
2023-02-07 17:26:59,053 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15326,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000001_0, 3]
2023-02-07 17:28:32,397 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleReducer: reducer task setup,ip->192.168.0.201,startTime->2023-02-07 17:27:05,mainClass->org.apache.hadoop.mapred.YarnChild,pid->15421
2023-02-07 17:28:44,596 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleReducer: reducer task cleanup,ip->192.168.0.201,pid->15421,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_r_000000_0, 7]
2023-02-07 17:27:09,522 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:27:07,pid->15467,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000004_0, 8]
2023-02-07 17:27:24,832 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15467,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000004_0, 8]
2023-02-07 17:27:11,552 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:27:08,pid->15500,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000005_0, 9]
2023-02-07 17:27:32,893 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15500,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000005_0, 9]
2023-02-07 17:27:36,450 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:27:34,pid->15567,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000007_0, 11]
2023-02-07 17:27:52,060 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15567,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000007_0, 11]
2023-02-07 17:27:41,647 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:27:40,pid->15617,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000008_0, 12]
2023-02-07 17:27:56,207 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15617,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000008_0, 12]
2023-02-07 17:28:01,633 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:28:00,pid->15679,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000010_0, 14]
2023-02-07 17:28:07,591 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15679,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000010_0, 14]
2023-02-07 17:28:04,827 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:28:03,pid->15725,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000011_0, 15]
2023-02-07 17:28:11,105 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15725,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000011_0, 15]
2023-02-07 17:28:16,469 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:28:14,pid->15783,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000013_0, 17]
2023-02-07 17:28:25,503 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15783,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000013_0, 17]
2023-02-07 17:28:17,918 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task setup,ip->192.168.0.201,startTime->2023-02-07 17:28:16,pid->15814,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000014_0, 18]
2023-02-07 17:28:25,095 INFO [main] org.example.helloHadoop.maxSaleMapReduce.MaxSaleMapper: mapper task cleanup,ip->192.168.0.201,pid->15814,mainClass->org.apache.hadoop.mapred.YarnChild,args->[192.168.0.200, 41731, attempt_1675757920071_0004_m_000014_0, 18]
3、應用執行分析
通過日志可以得到map任務和reduce任務甘特圖:
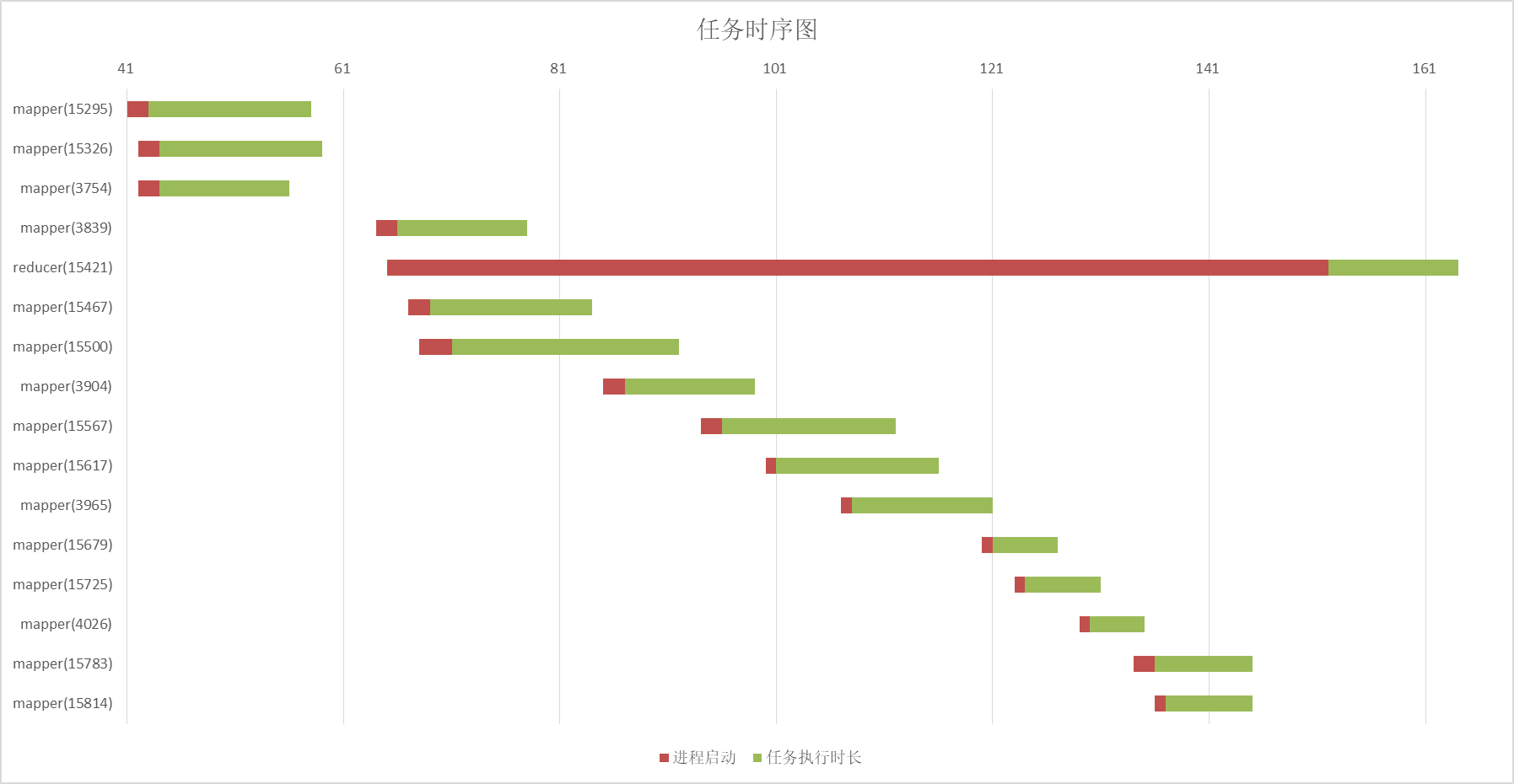
紅條是行程啟動時間,綠條是任務真正開始消耗的時間
從圖中不難看出同一時間最多只有3個map任務在運行,reduce任務很早就啟動了,但是要等map任務全部完成才真正開始,這個是因為MapReduce的“慢啟動”機制,由引數mapreduce.job.reduce.slowstart.completedmaps控制,默認值0.05,相當于map任務完成5%就開始啟動reduce任務,
MRAppMaster通過網路連接獲取子任務的狀態,MRAppMaster地址和系結的埠會通過啟動引數傳給子行程,也就是日志輸出的192.168.0.200, 41731,同時MRAppMaster會周期性向資源管理器報告自己的狀態,也就是這條連接192.168.0.200:50682->192.168.0.200:8030,
所以基本可以簡單說明:
- 任務啟動首先會運行application master行程
- 節點管理器負責啟動容器運行應用的任務
- application master向資源管理器報告自己狀態
- application master會根據需要繼續申請資源
- 應用通信依賴自身,而不是通過YARN來中轉
任務會被分配到不同的機器執行,那執行檔案是如何共享的呢?答案是通過HDFS共享,在MRAppMaster的日志中有這樣兩行:
The job-jar file on the remote FS is hdfs://192.168.0.200:8082/tmp/hadoop-yarn/staging/debian/.staging/job_1675757920071_0004/job.jar
The job-conf file on the remote FS is /tmp/hadoop-yarn/staging/debian/.staging/job_1675757920071_0004/job.xml
從HDFS下載檔案對比可以發現,這兩個就是任務的可執行檔案和使用的配置,同時當前目錄下還有一些其他檔案,比如我們的自定義依賴庫就在libjars檔案夾中,
三、YARN調度資源的幾種模式
1、三種調度模式
YARN有三種調度器,分別是FIFO調度器(先進先出),容量調度器和公平調度器,
FIFO調度器是最簡單的調度器,不需要任何配置,每個應用通過排隊的方式使用集群資源,容量調度器通過佇列分割資源,不同佇列配置的容量不同,應用運行在不同的佇列上,公平調度器通過動態的方式調度資源,當一個應用啟動它會占用集群所有資源,當第二個應用啟動后,它會慢慢等第一個應用釋放出的部分資源,最終達到一個動態的公平共享資源,
2、容量調度器配置
假設有這樣一個佇列層次結構
root─┬─default
└─dev
└─test1
└─test2
修改etc/hadoop/capacity-scheduler.xml檔案內容為如下:
更多配置可以參考 https://hadoop.apache.org/docs/r2.10.2/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
最大可以運行多少個應用
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.1</value>
<description>
application master行程占用的最大資源比例
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default,dev</value>
<description>
root佇列下的佇列
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>test1,test2</value>
<description>
dev佇列下的佇列
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>70</value>
<description>
default佇列默認容量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>90</value>
<description>
default佇列最大容量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
哪些用戶可以提交作業到default,*全部
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
哪些用戶可以控制default佇列任務,*全部
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name>
<value>*</value>
<description>
哪些用戶可以在default佇列設定任務優先級,*全部
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>30</value>
<description>
dev佇列默認容量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>50</value>
<description>
dev佇列最大容量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.acl_submit_applications</name>
<value>*</value>
<description>
哪些用戶可以提交作業到dev,*全部
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.acl_administer_queue</name>
<value>*</value>
<description>
哪些用戶可以控制dev佇列任務,*全部
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.acl_application_max_priority</name>
<value>*</value>
<description>
哪些用戶可以在dev佇列設定任務優先級,*全部
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.test1.capacity</name>
<value>50</value>
<description>
test1佇列默認容量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.test2.capacity</name>
<value>50</value>
<description>
test2佇列默認容量
</description>
</property>
</configuration>
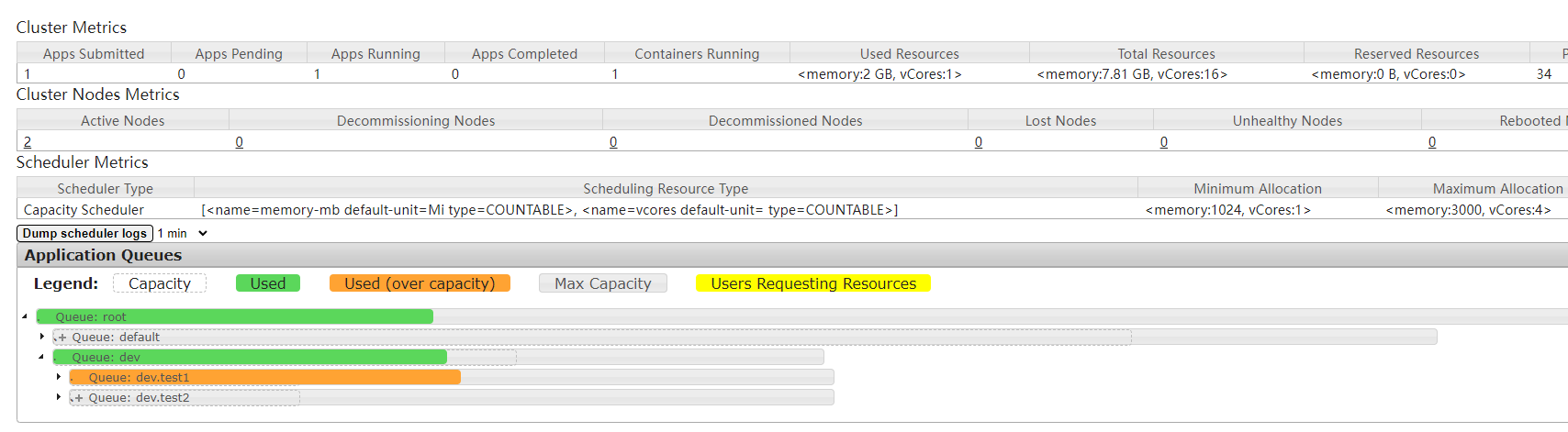
default佇列和dev佇列分別分配到了70%和30%的資源,dev佇列又被分成了test1和test2兩個佇列,test1和test2平分dev佇列資源,可以在資源管理器的web服務看到佇列配置:
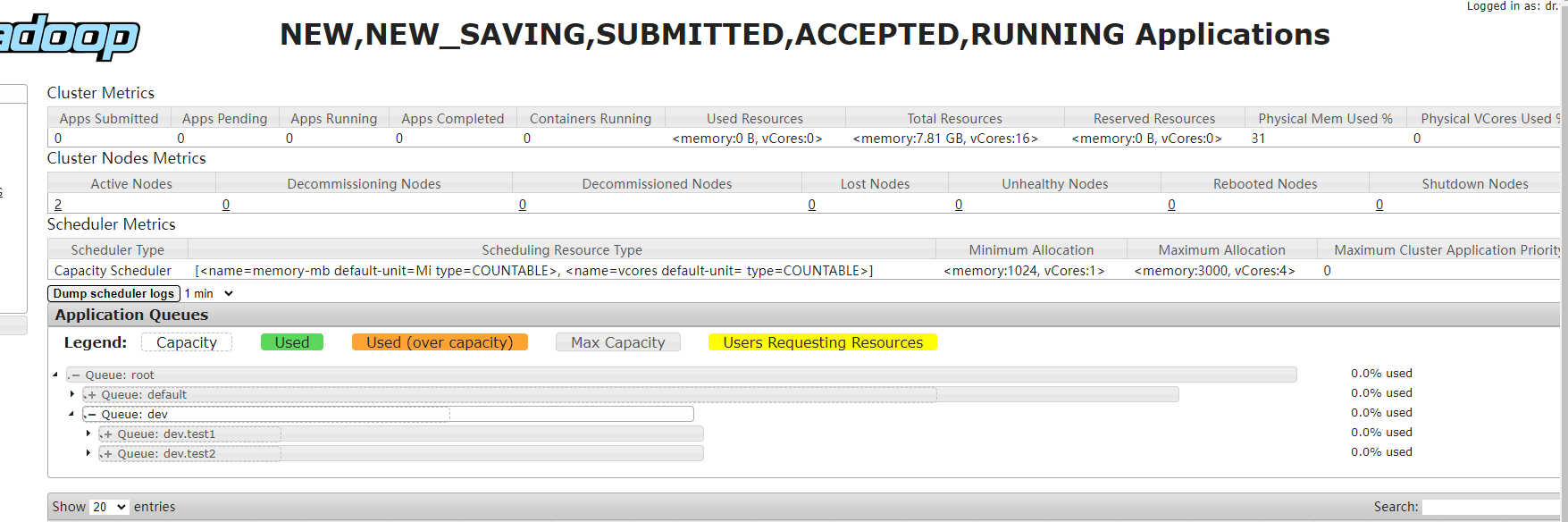
MapReduce應用通過配置mapreduce.job.queuename來指定運行佇列,默認值是default,需要注意的是應該配置的是佇列名,例如test1,而不是佇列的全域限定名root.dev.test1,
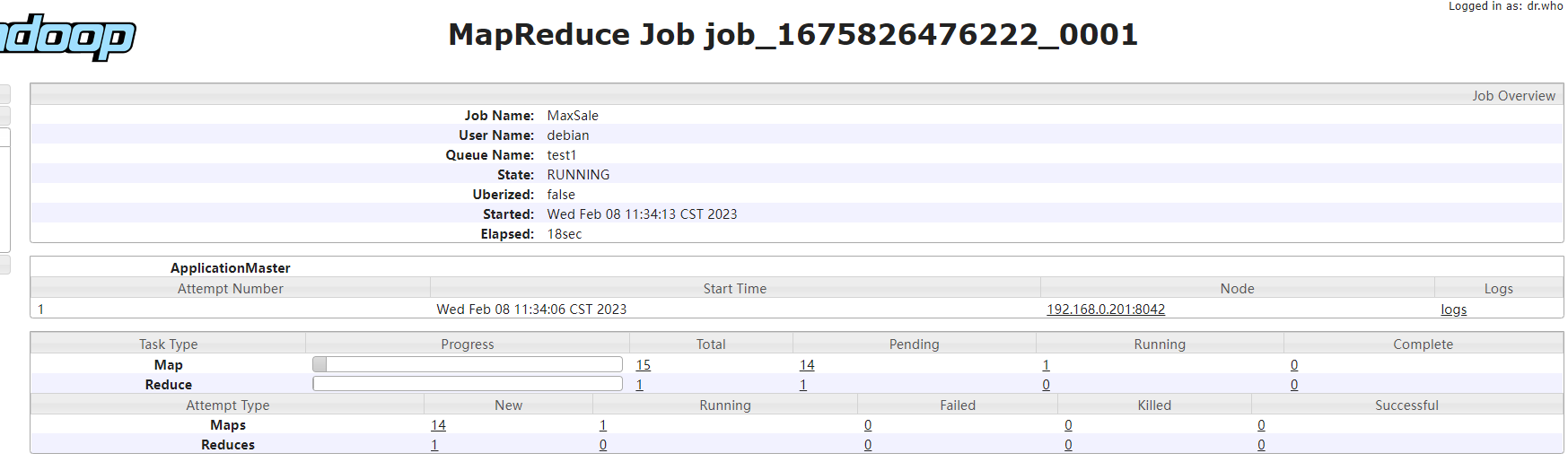
修改應用組態檔mapreduce.job.queuename為test1,再次運行maxSaleMapReduce應用,可以發現此時只會啟動1個application master和1個YarnChild行程,
啟動行程數量和集群資源相關,因為資源受限,可以發現此時應用執行時間明顯偏長
佇列狀態:
任務資訊:
3、公平調度器配置
還是剛才的佇列層次結構:
root─┬─default
└─dev
└─test1
└─test2
首先要修改yarn-site.xml檔案中的配置yarn.resourcemanager.scheduler.class為org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
然后創建fair-scheduler.xml檔案,內容如下:
更多配置可以參考 https://hadoop.apache.org/docs/r2.10.2/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
<?xml version="1.0"?>
<allocations>
<!-- 佇列內默認調度策略 -->
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<queue name="default">
<weight>70</weight>
<!-- 佇列內調度策略,支持fifo,fair,drf -->
<schedulingPolicy>fifo</schedulingPolicy>
<!-- 允許提交的用戶 -->
<aclSubmitApps>*</aclSubmitApps>
<!-- 允許管理的用戶 -->
<aclAdministerApps>*</aclAdministerApps>
</queue>
<queue name="dev">
<weight>30</weight>
<!-- 允許提交的用戶 -->
<aclSubmitApps>*</aclSubmitApps>
<!-- 允許管理的用戶 -->
<aclAdministerApps>*</aclAdministerApps>
<queue name="test1">
<weight>50</weight>
</queue>
<queue name="test2">
<weight>50</weight>
</queue>
</queue>
<!-- 任務匹配佇列規則 -->
<queuePlacementPolicy>
<rule name="specified" />
<rule name="default" queue="dev.test2" />
</queuePlacementPolicy>
</allocations>
defaultQueueSchedulingPolicy配置指定佇列內默認調度模式,如果佇列自身沒有指定調度模式,則采用此配置的值,
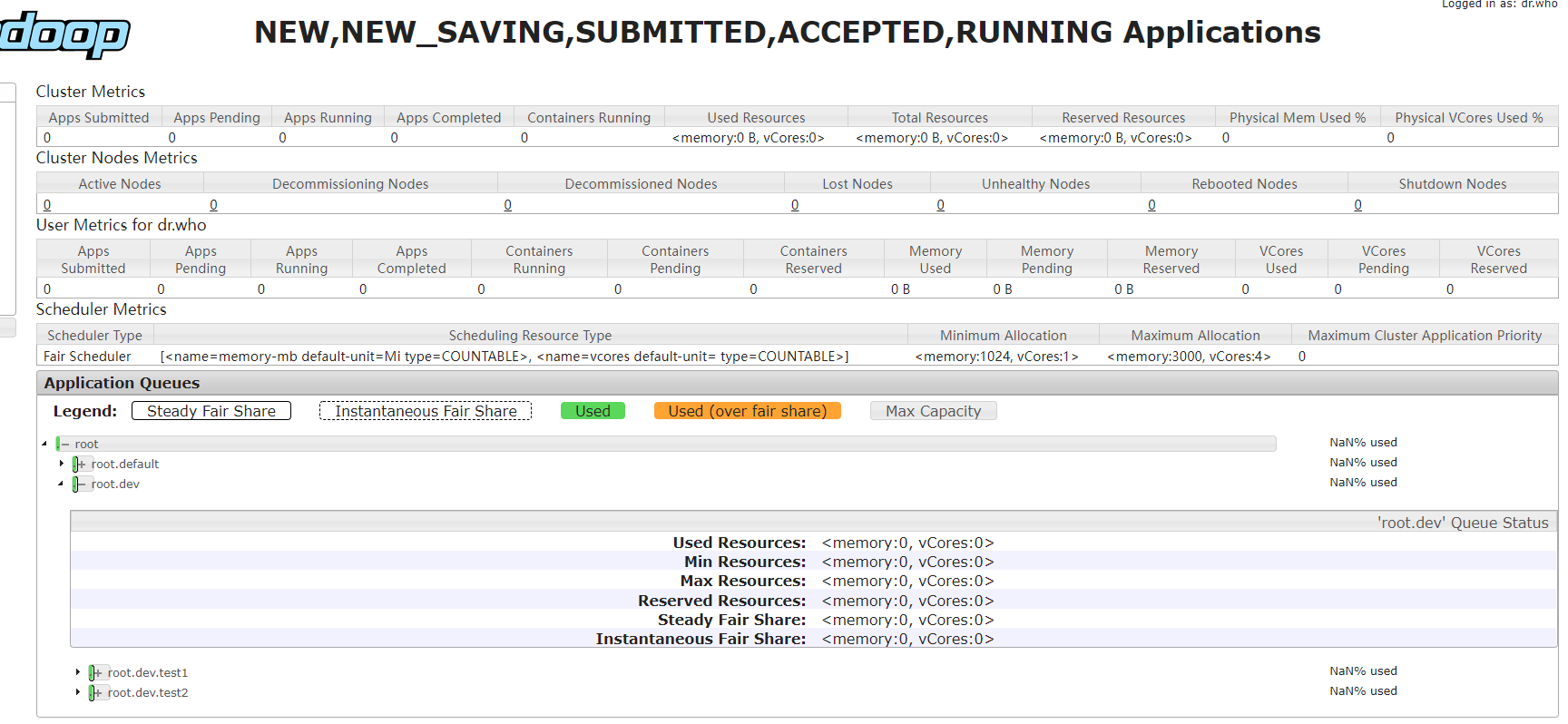
queuePlacementPolicy配置包含一個規則,用于匹配應用放置在哪個佇列,specified表示優先采用應用指定的佇列,如果匹配失敗則繼續匹配下一條規則,如果所有規則都不匹配則命中default規則,應用會放置在test2佇列中,
重啟資源管理器,web服務顯示資訊如下:
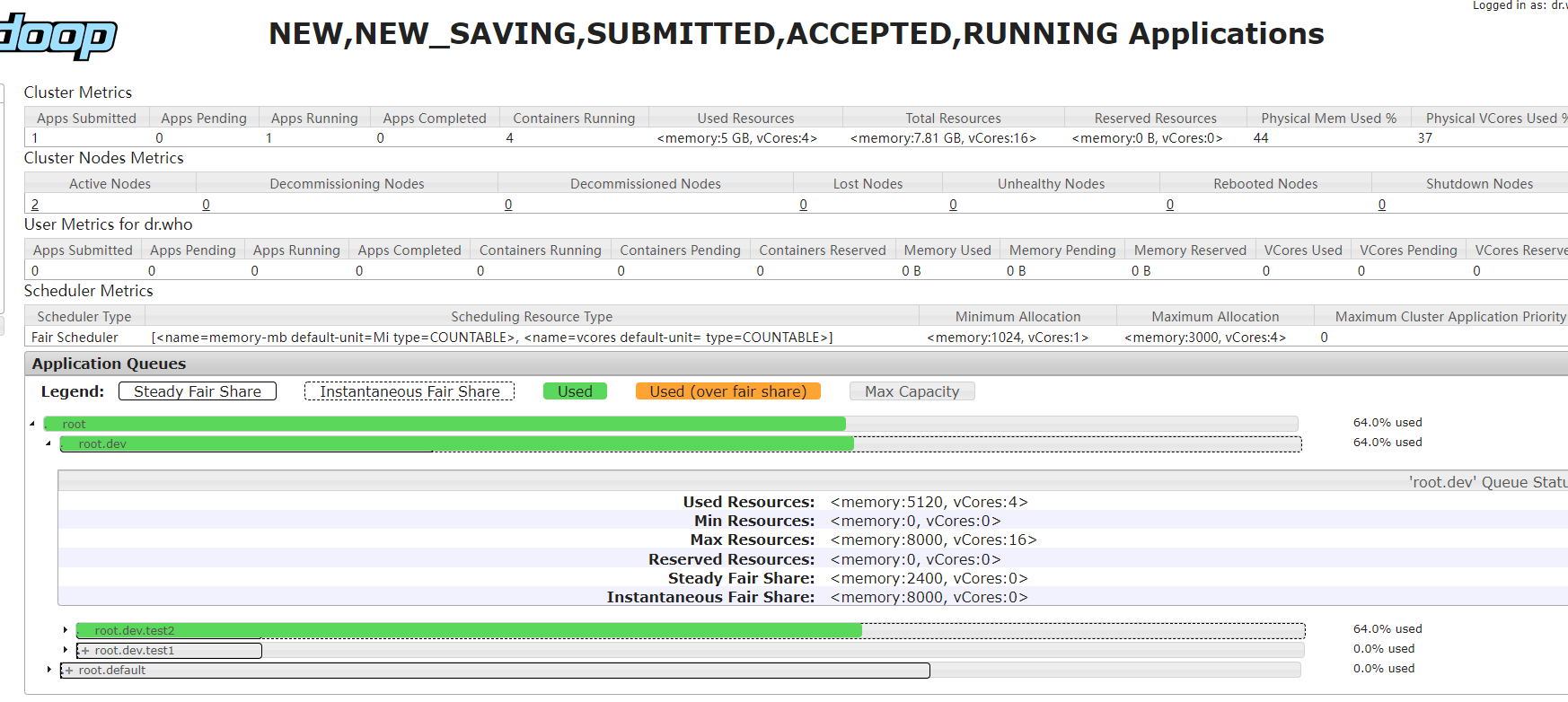
不配置mapreduce.job.queuename引數啟動應用,可以發現應用被調度到佇列test2上:
佇列狀態:
任務資訊:
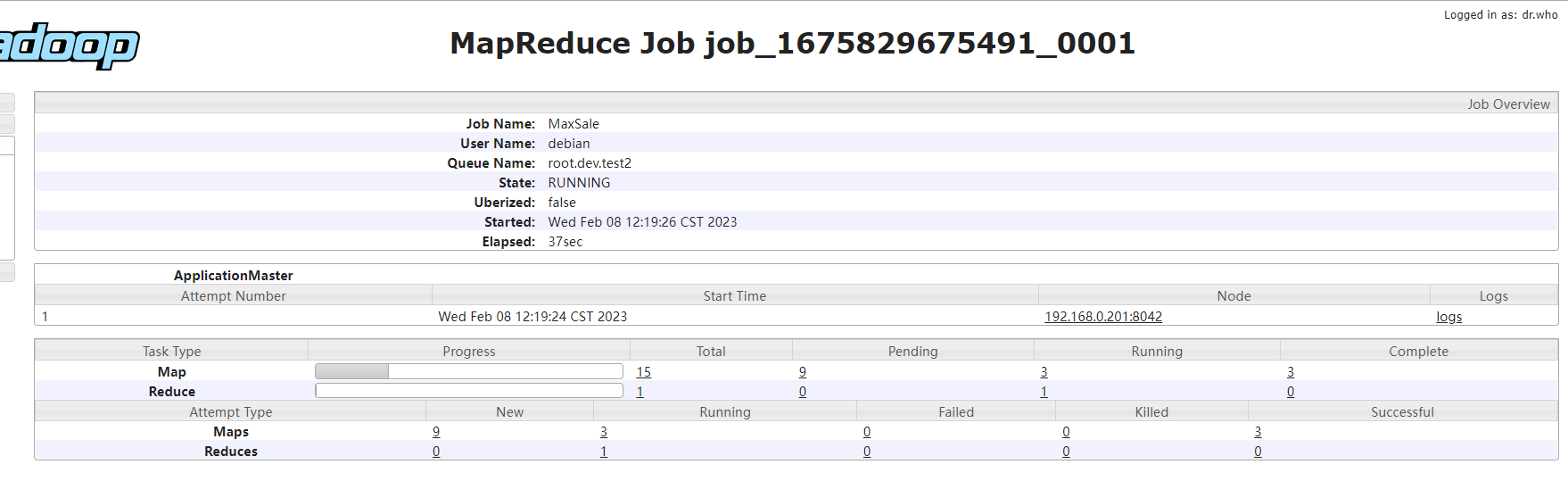
與容量調度器不同的是,test1雖然只設定了dev的一半的權重,但是實際使用了dev全部資源,而dev也超出了自身的30%的權重,這個是因為當前集群只有一個任務,所以這個任務可以獨占集群所有資源,
如果一個集群非常繁忙,當任務被提交后,任務不會立即啟動,任務會等待已經運行的任務釋放資源才會啟動,為了使任務從提交到執行的時間可預測,公平調度器支持“搶占”功能,
所謂搶占就是允許調度器主動終止超過權重的佇列中運行的任務,釋放的資源會被分配給低于應得權重的佇列,但是因為任務被終止,所以被終止的任務會被重新執行,相當于降低了整個集群的運行效率,
通過設定yarn.scheduler.fair.preemption為true啟動搶占功能,更詳細的引數可以參考 https://hadoop.apache.org/docs/r2.10.2/hadoop-yarn/hadoop-yarn-site/FairScheduler.html 中的Configuration內容,
4、總結
YARN提供了三種調度器,分別是FIFO調度器(先進先出),容量調度器和公平調度器,FIFO調度器規則最為簡單,任務可以獨占所有資源以便更快的完成,但是如果出現大任務的情況會阻塞后續任務的執行,容量調度器通過佇列來分割和保留集群資源,在一個繁忙的集群中可以為某些任務有效的保留可用資源,缺點是無法高效利用集群整體資源,公平調度器通過動態調度的模式調度資源,應用之間支持主動讓出和搶占分配資源,
使用哪種模式要根據集群的業務場景來決定,不存在哪種調度模式更好或更差,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/543354.html
標籤:其他
上一篇:優化數倉業務視圖:過濾條件傳遞
下一篇:MySQL 定時備份資料庫