
你想要的 ClickHouse 優化,都在這里,
ClickHouse 是 OLAP(Online analytical processing)資料庫,以速度見長[1],ClickHouse 為什么能這么快?有兩點原因[2]:
-
架構優越 -
列式存盤 -
索引 -
資料壓縮 -
向量化執行 -
資源利用 -
關注底層細節
但是,資料庫設計再優越也拯救不了錯誤的使用方式,本文以 MergeTree 引擎家族為例講解如何對查詢優化,
ClickHouse 查詢執行程序
?? 本節基于 ClickHouse 22.3 版本分析
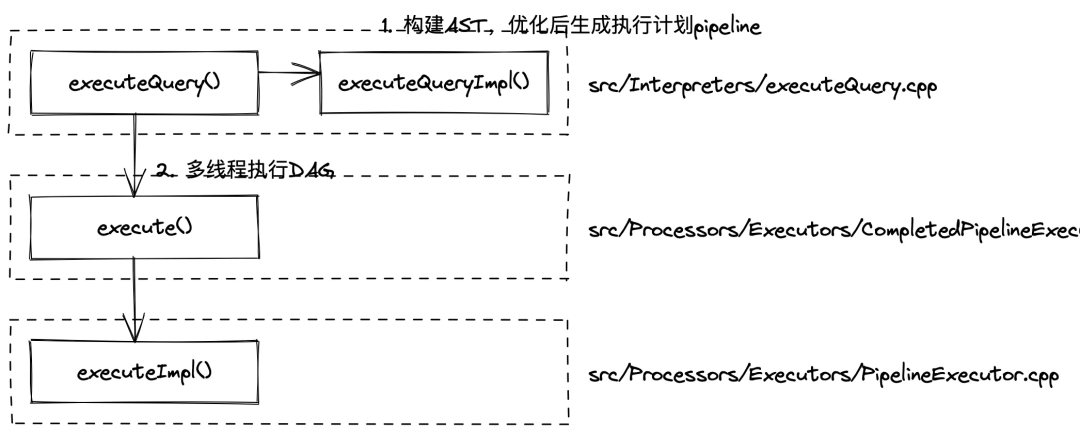
clickhouser-server啟動后會在 while 回圈中等待請求,接收到查詢后會呼叫executeQueryImpl()行數構建 AST、優化并生成執行計劃 pipeline,最后在executeImpl()中多執行緒執行 DAG 獲取結果,這篇文章只關心 SQL 執行,省略掉網路互動部分,查詢執行流程如下圖所示:
SQL 的決議優化和編譯原理息息相關,本節將包含大量編譯原理和代碼細節,屬擴展知識,
詞法決議和語法決議
ClickHouse 拿到需要執行的 SQL,首先需要將 String 格式的字串決議為它能理解的資料結構,也就是 AST 和執行計劃,構造 AST 部分代碼如下所示:
// src/Interpreters/executeQuery.cpp
static std::tuple<ASTPtr, BlockIO> executeQueryImpl()
{
// 構造Parser
ParserQuery parser(end, settings.allow_settings_after_format_in_insert);
// 將SQL轉為抽象語法樹
ast = parseQuery(parser, begin, end, "", max_query_size, settings.max_parser_depth);
// 設定query的背景關系,比如SETTINGS
...
if (async_insert)
{
...
} else {
// 生成interpreter實體
interpreter = InterpreterFactory::get(ast, context, SelectQueryOptions(stage).setInternal(internal));
// interpreter優化AST并回傳執行計劃
res = interpreter->execute();
}
// 回傳抽象語法樹和執行計劃
return std::make_tuple(ast, std::move(res));
}值得一提的是,決議 SQL 生成語法樹這是編譯原理中詞法分析和語法分析部分覆寫的事情,詞法分析只是簡單拆解資料流為一個個 token,而語法分析分為自頂向下和自底向上兩種方式,常見的語法分析方式也分為手寫語法分析(往往是自頂向下的有限狀態機,遞回下降分析)和語法分析工具(往往是自底向上,如 Flex、Yacc/Bison 等),
-
曾經 GCC 使用 yacc/bison 作為語法決議器,在 3.x 某個版本之后改為手寫遞回下降語法分析[3] -
clang 一直是手寫遞回下降語法分析[4]
手寫語法分析比起語法分析工具有幾個優勢(當然要寫得好的情況):
-
性能更好,可以優化熱點路徑等 -
診斷和錯誤恢復更清晰明了,手寫狀態機可以完全掌控系統狀態,錯誤處理更容易 -
簡單,不需要掌握新語法
ClickHouse 決議 SQL 的函式如下所示:
// src/Parsers/parseQuery.cpp
ASTPtr tryParseQuery()
{
// 將SQL拆分為token流
Tokens tokens(query_begin, all_queries_end, max_query_size);
IParser::Pos token_iterator(tokens, max_parser_depth);
// 將token流決議為語法樹
ASTPtr res;
const bool parse_res = parser.parse(token_iterator, res, expected);
return res;
}可以看到先將 SQL 字串拆解為 token 流(詞法分析),再呼叫perser.parse()函式進行語法分析,它的實作如下:
// src/Parsers/ParserQuery.cpp
bool ParserQuery::parseImpl(Pos & pos, ASTPtr & node, Expected & expected)
{
ParserQueryWithOutput query_with_output_p(end, allow_settings_after_format_in_insert);
ParserInsertQuery insert_p(end, allow_settings_after_format_in_insert);
ParserUseQuery use_p;
ParserSetQuery set_p;
ParserSystemQuery system_p;
ParserCreateUserQuery create_user_p;
ParserCreateRoleQuery create_role_p;
ParserCreateQuotaQuery create_quota_p;
ParserCreateRowPolicyQuery create_row_policy_p;
ParserCreateSettingsProfileQuery create_settings_profile_p;
ParserCreateFunctionQuery create_function_p;
ParserDropFunctionQuery drop_function_p;
ParserDropAccessEntityQuery drop_access_entity_p;
ParserGrantQuery grant_p;
ParserSetRoleQuery set_role_p;
ParserExternalDDLQuery external_ddl_p;
ParserTransactionControl transaction_control_p;
ParserBackupQuery backup_p;
bool res = query_with_output_p.parse(pos, node, expected)
|| insert_p.parse(pos, node, expected)
|| use_p.parse(pos, node, expected)
|| set_role_p.parse(pos, node, expected)
|| set_p.parse(pos, node, expected)
|| system_p.parse(pos, node, expected)
|| create_user_p.parse(pos, node, expected)
|| create_role_p.parse(pos, node, expected)
|| create_quota_p.parse(pos, node, expected)
|| create_row_policy_p.parse(pos, node, expected)
|| create_settings_profile_p.parse(pos, node, expected)
|| create_function_p.parse(pos, node, expected)
|| drop_function_p.parse(pos, node, expected)
|| drop_access_entity_p.parse(pos, node, expected)
|| grant_p.parse(pos, node, expected)
|| external_ddl_p.parse(pos, node, expected)
|| transaction_control_p.parse(pos, node, expected)
|| backup_p.parse(pos, node, expected);
return res;
}可以發現 ClickHouse 將 Query 分為了 18 種型別(截止 2022-11-12 日),每種 Query 都有自己的 Parser,通過關鍵詞匹配構造 AST 上的節點,最終生成語法樹,遞回下降部分超綱了,這里就不鋪開講,
優化器
經過語法分析后生成的 AST 并不是執行最優解,ClickHouse 包含大量基于規則的優化(rule based optimization),每個 Query 會遍歷一遍優化規則,將滿足的情況進行不改變查詢語意地重寫,
每一種 Query 型別都有對應的 Interpreter,后文都以 Select 查詢舉例,代碼如下:
// src/Interpreters/InterpreterFactory.cpp
std::unique_ptr<IInterpreter> InterpreterFactory::get()
{
...
if (query->as<ASTSelectQuery>())
{
return std::make_unique<InterpreterSelectQuery>(query, context, options);
}
...
}在InterpreterSelectQuery類的建構式中將 AST 優化、重寫,代碼詳見src/Interpreters/InterpreterSelectQuery.cpp,這里只畫流程圖:
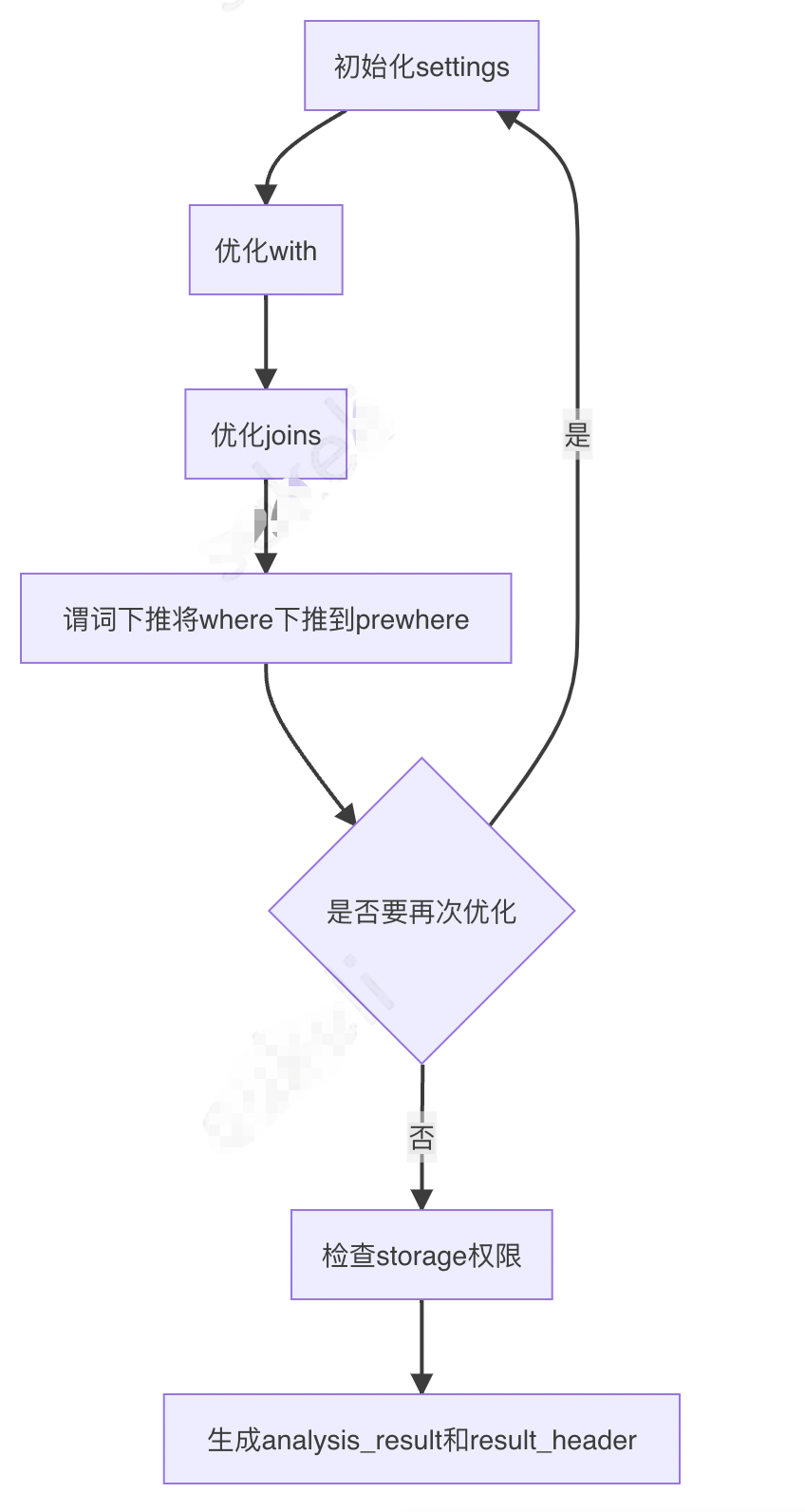
是否初始化 settings 優化 with 優化 joins 謂詞下推將 where 下推到 prewhere 是否要再次優化檢查 storage 權限生成 analysis_result 和 result_header
構造執行計劃
src/Interpreters/InterpreterSelectQuery.cpp檔案InterpreterSelectQuery::executeImpl()方法將優化分析得到的中間資料輔助生成最終的執行計劃,代碼如下:
// src/Interpreters/InterpreterSelectQuery.cpp
void InterpreterSelectQuery::executeImpl()
{
...
// 個人理解針對EXPLAIN PLAN,只構建執行計劃不執行
if (options.only_analyze)
{
...
}
else
{
// 從磁盤讀取所需列,注意這一行,后文跳轉進去分析
executeFetchColumns(from_stage, query_plan);
}
if (options.to_stage > QueryProcessingStage::FetchColumns)
{
// 在分布式執行Query時只在遠程節點執行
if (expressions.first_stage)
{
// 當storage不支持prewhere時添加FilterStep
if (!query_info.projection && expressions.filter_info)
{
...
}
if (expressions.before_array_join)
{
...
}
if (expressions.array_join)
{
...
}
if (expressions.before_join)
{
...
}
// 可選步驟:將join key轉為一致的supertype
if (expressions.converting_join_columns)
{
...
}
// 添加Join
if (expressions.hasJoin())
{
...
}
// 添加where
if (!query_info.projection && expressions.hasWhere())
executeWhere(query_plan, expressions.before_where, expressions.remove_where_filter);
// 添加aggregation
if (expressions.need_aggregate)
{
executeAggregation(
query_plan, expressions.before_aggregation, aggregate_overflow_row, aggregate_final, query_info.input_order_info);
/// We need to reset input order info, so that executeOrder can't use it
query_info.input_order_info.reset();
if (query_info.projection)
query_info.projection->input_order_info.reset();
}
// 準備執行:
// 1. before windows函式
// 2. windows函式
// 3. after windows函式
// 4. 準備DISTINCT
if (expressions.need_aggregate)
{
// 存在聚合函式,在windows函式/ORDER BY之前不執行
}
else
{
// 不存在聚合函式
// 存在windows函式,應該在初始節點運行
// 并且,ORDER BY和DISTINCT依賴于windows函式,這里也不能運行
if (query_analyzer->hasWindow())
{
executeExpression(query_plan, expressions.before_window, "Before window functions");
}
else
{
// 沒有windows函式,執行before ORDER BY、準備DISTINCT
assert(!expressions.before_window);
executeExpression(query_plan, expressions.before_order_by, "Before ORDER BY");
executeDistinct(query_plan, true, expressions.selected_columns, true);
}
}
// 如果查詢沒有GROUP、HAVING,有ORDER或LIMIT,會在遠程排序、LIMIT
preliminary_sort();
}
// 在分布式執行Query時只在初始節點執行或optimize_distributed_group_by_sharding_key開啟時
if (expressions.second_stage || from_aggregation_stage)
{
if (from_aggregation_stage)
{
// 遠程節點聚合過,這里啥也不干
}
else if (expressions.need_aggregate)
{
// 從不同節點拉取資料合并
if (!expressions.first_stage)
executeMergeAggregated(query_plan, aggregate_overflow_row, aggregate_final);
if (!aggregate_final)
{
// 執行group by with totals/rollup/cube
...
}
// 添加Having
else if (expressions.hasHaving())
executeHaving(query_plan, expressions.before_having, expressions.remove_having_filter);
}
// 報個錯
else if (query.group_by_with_totals || query.group_by_with_rollup || query.group_by_with_cube)
throw Exception("WITH TOTALS, ROLLUP or CUBE are not supported without aggregation", ErrorCodes::NOT_IMPLEMENTED);
// 準備執行:
// 1. before windows函式
// 2. windows函式
// 3. after windows函式
// 4. 準備DISTINCT
if (from_aggregation_stage)
{
if (query_analyzer->hasWindow())
throw Exception(
"Window functions does not support processing from WithMergeableStateAfterAggregation",
ErrorCodes::NOT_IMPLEMENTED);
}
else if (expressions.need_aggregate)
{
executeExpression(query_plan, expressions.before_window,
"Before window functions");
executeWindow(query_plan);
executeExpression(query_plan, expressions.before_order_by, "Before ORDER BY");
executeDistinct(query_plan, true, expressions.selected_columns, true);
}
else
{
if (query_analyzer->hasWindow())
{
executeWindow(query_plan);
executeExpression(query_plan, expressions.before_order_by, "Before ORDER BY");
executeDistinct(query_plan, true, expressions.selected_columns, true);
}
else
{
// Neither aggregation nor windows, all expressions before
// ORDER BY executed on shards.
}
}
// 添加order by
if (expressions.has_order_by)
{
// 在分布式查詢中,沒有聚合函式卻有order by,將會在遠端節點order by
...
}
// 多source order by優化
...
// 多條流時再次執行distinct
if (!from_aggregation_stage && query.distinct)
executeDistinct(query_plan, false, expressions.selected_columns, false);
// 處理limit
...
// 處理projection
...
// 處理offset
...
}
// 需要子查詢結果構建set
if (!subqueries_for_sets.empty())
executeSubqueriesInSetsAndJoins(query_plan, subqueries_for_sets);
}
}其中InterpreterSelectQuery::executeFetchColumns()函式是讀取所需列的階段,從代碼中可以看到它也做了很多的優化:
-
count()優化 -
只有 LIMIT 情況的優化 -
quota限制
可以看到:
-
limit 大部分情況下是計算完成后再執行,而 quota 是在讀取資料時執行的 -
加速的關鍵是減少讀入的資料量,也就是說善用索引 -
用 count()、count(1)和count(*),ClickHouse 都有優化,但不要count(any_field)
索引設計
索引是 ClickHouse 快速查詢最重要的一環,分為主鍵索引(sparse indexes)和跳表索引(data skipping indexes),在執行查詢時,索引命中順序如下圖所示:
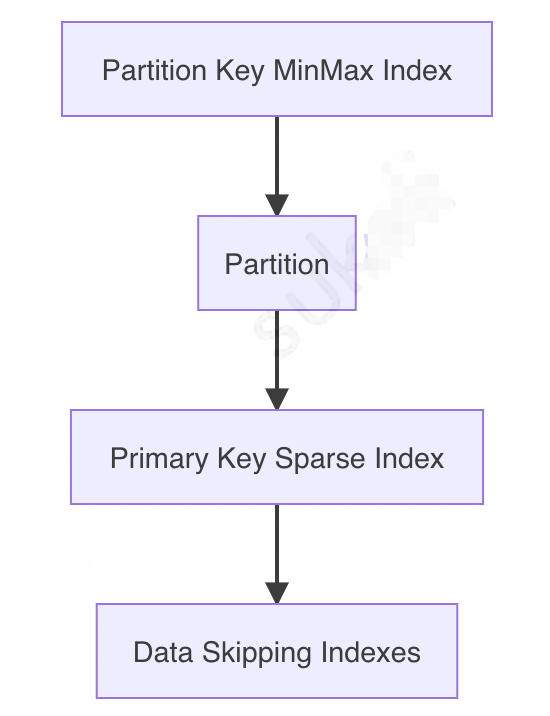
Partition Key MinMax IndexPartitionPrimary Key Sparse IndexData Skipping Indexes
詳見代碼:
// src/Processors/QueryPlan/ReadFromMergeTree.cpp
MergeTreeDataSelectAnalysisResultPtr ReadFromMergeTree::selectRangesToRead()
{
...
try
{
// 使用partition by選取需要parts
MergeTreeDataSelectExecutor::filterPartsByPartition(...);
// 處理抽樣
...
// 使用主鍵索引和跳表索引
result.parts_with_ranges = MergeTreeDataSelectExecutor::filterPartsByPrimaryKeyAndSkipIndexes(...);
}
catch(...)
{
...
}
...
}值得注意的是,主鍵的 sparse index 使用二分查找直接縮小范圍到所需要的 parts,而跳表索引就需要在選出來的 parts 里,每 n 個(用戶自定義)granules 就需要比較 n 次,
最佳實踐:
partition by 需要一個可以轉為時間的列,比如 Datatime、Date 或者時間戳,而如果 primary key 中也有時間欄位,可以使用同一個欄位避免查詢時需要同時指定兩個時間欄位,比如:指定為資料處理時間,
Partition
首先要辨析 part 和 partition 的區別,ClickHouse 應用層面定義了 partition,用戶指定 partition by 關鍵詞設定不同的 partition,但是 partition 只是邏輯磁區,真正存盤到磁盤時按 part 來存盤,每一個 part 一個檔案夾,里面存盤不同欄位的.mrk和.bin檔案,以及一個minmax_{PARTITION_KEY_COLUMN}.idx檔案,不同 part 的 minmax 作為一個索引存盤于記憶體,
當查詢的 WHERE 帶有 partition key 時,首先會比較每一個 part 的 minmax 索引過濾不相關 parts,之后再根據 PARTITION BY 定義的規則過濾不相關 partition,
可是 partition 不是越小越好,
partitioning 并不會加速查詢(有主鍵存在),過小的 partition 反而會導致大量的 parts 無法合并(MergeTree 引擎家族會在后臺不斷合并 parts),因為屬于不同 partition 的 parts 無法合并,[5]
最佳實踐[6]:
-
一個(Replicated)MergeTree 的 partition 大概 1 ~ 300GB -
Summing/ReplacingMergeTree 的 partition 大概 400MB ~ 40GB -
查詢時涉及盡量少 partition -
插入時最好只有 1 ~ 2 個磁區 -
一張表維持 100 個磁區以內
Primary key index
主鍵是 ClickHouse 最重要的索引,沒有之一,好的主鍵應該能有效排除大量無關的資料 granules,減少磁盤讀取的位元組數,
先講幾個主鍵的背景知識:
-
主鍵用于資料排序 -
ClickHouse 講資料按主鍵排序,再按 index_granularity設定的大小(默認 8192)將資料分為一個個 granules[7] -
每個 granules 的第一行作為主鍵索引中的一個元素[8] -
查詢時在主鍵上使用二分查找跳過無關 granules[9] -
主鍵只能通過前綴命中索引[10] -
每一個 part 內的 .bin檔案存盤了 n 個 granules,用.mrk檔案記錄每一個 granules 在.bin檔案的地址偏移[11] -
ClickHouse 會在后臺不斷合并同一個 partition 的不同 parts,直到大小/分布達到“預期”
主鍵的選擇應該盡可能考慮周全,因為主鍵是無法修改的,只能建新表后資料遷移,
最佳實踐[12](針對(Replicated)MergeTree 引擎):
-
選擇永遠會用于過濾條件的列 -
越重要的、基數越低的放左邊 -
主鍵中不要出現兩個高基數欄位,一般最后一列可以為總體增長的時間欄位 -
將行的特征欄位加入,將相似的行放一起,提高壓縮率 -
若主鍵包含主從關系,主放左邊,從放右邊
Data skipping indexes
最后一步是跳表索引,這個沒有太多可以講的地方,和其他資料庫相同,跳表索參考于盡量減少讀取的行數,具體參看官方檔案,
配置優化
配置優化分為兩部分,全域配置優化和 MergeTree 表配置優化,
全域配置優化
參看Altinity選擇性配置優化項,
這里寫三個推薦的配置:
-
添加 force_index_by_date和force_primary_key避免全盤讀取 -
調整記憶體配置,參考Altinity -
系統表添加 TTL 和 ttl_only_drop_parts表配置
表配置優化
除了全域配置,MergeTree 引擎家族每張表也有自己的配置項,[13]
推薦設定如下配置:
-
ttl_only_drop_parts=1,只有 parts 中所有資料都過期了才會 DROP,可以有效減少TTL_MERGE發生的頻率,降低磁盤負載, -
merge_with_ttl_timeout=86400,配合上一項配置,將 TTL 檢查調整為 1 天一次(默認 4 小時一次), -
use_minimalistic_part_header_in_zookeeper=1,可以有效降低 Zookeeper 負載,避免 Zookeeeper 成為性能瓶頸(插入),
欄位優化
除了索引、磁區和配置外,還有表欄位可以優化,接下來將講述 Schema 型別、CODEC 和快取三個方面,
注意,盡量避免使用 Null,在 ClickHouse 中 Null 會用一個單獨 Null masks 檔案存盤哪些行為 Null[14],因此讀取某個普通欄位只需要.bin和.mrk兩個檔案,而讀取 Nullable 欄位時需要.bin、.mrk和 masks 檔案,社區查詢驗證,最高會有 2 倍性能損失,[15]
Schema 型別
使用 ClickHouse 存盤時,一般用戶都會創建大寬表,包含大量數值、字串型別的欄位,這里提及兩種 Schema 型別[16],沒有哪個更優越,由讀者執行評估業務適合哪一種,
平鋪欄位
這是我們主表正在使用的型別,將可能用到的欄位預留平鋪,除了一系列基礎欄位外,增加大量metric1, metric2...metricN和tag1, tag2...tagN等等欄位,
優點:
-
簡單 -
只讀取所需要的列,非常高效 -
每個指標、標記都可以有特殊型別 -
適合密集記錄(所有預留欄位幾乎全用上)
缺點:
-
添加欄位需要改變 schema -
預留欄位不能過多,最多 100 ~ 200 個 -
如果使用很稀疏,會創建大量 sparse file 欄位 -
需要標識“資料缺失”的情況(Null 或者默認值) -
讀取的列越多,需要讀取檔案越多,IO 次數越多
arrays/nested/map 欄位
這是我們 ctree 功能正在使用的型別,將業務欄位塞入嵌套資料型別中,比如 array、nested struct 和 map,后文以 array 舉例:metric_array、tag_array,
優點:
-
動態擴展 -
ClickHouse 有大量高效的相關處理函式,甚至可以針對 Array、Map 設定索引 -
適合稀疏記錄(每行存盤少量值,盡管總基數很高)
缺點:
-
只需要其中一個 metric/tag 時,需要將整個 array 全部讀入記憶體 -
不通用,與其他系統互動時比較麻煩,比如 spark 使用 jdbc 時,嵌套型別無法支持比如 array(array(string)) -
不通意義的值存盤在相同欄位,壓縮率變低 -
需要不同型別的預留欄位時需要創建不同型別
總結
關于 Schema 設計這里,讀者可以考慮 28 原則,理論上 80%查詢只會用到 20%的業務欄位,因此可以將使用頻率高的業務欄位平鋪,將使用頻率低的欄位放入嵌套結構中,
CODEC
CODEC 分為壓縮演算法 CODEC、存盤格式 CODEC 和加密 CODEC,一般可以組合一起使用,在 ClickHouse 中,未顯示指定 CODEC 的欄位都會被分配一個 DEFAULT 默認 CODEC LZ4(除非用戶修改 clickhouse 配置 compression 部分[17]),
壓縮演算法 CODEC 的選擇是一個平衡板問題,更高的壓縮度可以有更少的 IO 但是更高的 CPU,更低的壓縮度有更多的 IO 但是更少的 CPU,這需要讀者根據部署機器配置自行選擇合適的壓縮演算法和壓縮等級,
這里提供兩個判斷策略:
-
存在索引的欄位可以設定更高的壓縮等級 -
用于 where 條件的欄位應該設定更低壓縮等級
存盤格式 CODEC 主要是Delta、DoubleDelta、Gorilla、FPC和T64幾種,
-
Delta存盤行之間的變化值,適合變化較小且比較固定的列,比如時間戳,需要配合 ZSTD 使用 -
DoubleDelta存盤Delta的Delta,適合變化很慢的序列 -
Gorilla適合不怎么變動的 integer、float 型別[18] -
FPC適合于 float 型別,由于我們未使用 float 欄位這里略過 -
T64存盤編碼范圍內最大、最小值,以轉為 64bit 存盤,適合較小的 integer 型別
擴展閱讀:
-
Altinity Blog: New Encodings to Improve ClickHouse Efficiency -
Altinity Wiki: Codecs sped
快取
mark_cache_size可以調整.mrk檔案的快取大小,默認為 5GB,適當調大可以減少查詢時 IO 次數,有效降低磁盤壓力,[19]
-
欄位越多, .mrk檔案越大 -
index_granularity與.mrk檔案大小成負相關
可以通過如下 SQL 查詢當前所有表的 parts 資訊:
SELECT
database,
table,
count() AS parts,
uniqExact(partition_id) AS partition_cnt,
sum(rows),
formatReadableSize(sum(data_compressed_bytes) AS comp_bytes) AS comp,
formatReadableSize(sum(data_uncompressed_bytes) AS uncomp_bytes) AS uncomp,
uncomp_bytes / comp_bytes AS ratio,
formatReadableSize(sum(marks_bytes) AS mark_sum) AS marks,
mark_sum / uncomp_bytes AS mark_ratio
FROM cluster(default_cluster, system.parts)
WHERE active
GROUP BY
database,
table
ORDER BY comp_bytes DESC可以通過如下查詢獲取當天 mrk 快取命中情況:
WITH (ProfileEvents.Values[indexOf(ProfileEvents.Names, 'MarkCacheHits')]) AS MARK_CACHE_HITS
SELECT
toHour(event_time) AS time,
countIf(MARK_CACHE_HITS != 0) AS hit_query_count,
count() AS total_query_count,
hit_query_count / total_query_count AS hit_percent,
avg(MARK_CACHE_HITS) AS average_hit_files,
min(MARK_CACHE_HITS) AS minimal_hit_files,
max(MARK_CACHE_HITS) AS maximal_hit_files,
quantile(0.5)(MARK_CACHE_HITS) AS "50",
quantile(0.9)(MARK_CACHE_HITS) AS "90",
quantile(0.99)(MARK_CACHE_HITS) AS "99"
FROM clusterAllReplicas('default_cluster', system.query_log)
WHERE event_date = toDate(now())
AND (type = 2 OR type = 4)
AND query_kind = 'Select'
GROUP BY time
ORDER BY time ASC以及如下查詢獲取當前 mrk 快取記憶體占用情況:
SELECT formatReadableSize(value)
FROM asynchronous_metrics
WHERE metric = 'MarkCacheBytes'以及 mrk 快取具體快取多少檔案:
SELECT value
FROM asynchronous_metrics
WHERE metric = 'MarkCacheFiles'除此之外,ClickHouse 還可以調整uncompressed_cache快取一定量原始資料于記憶體中,[20]但是這個快取只對大量短查詢有效,對于 OLAP 來說,查詢千奇百怪,不太建議調整這個配置,
業務優化
到了最難的部分,由于接下來的部分和不同業務息息相關,為了講解我們業務上的優化,我先介紹下我們業務情況:
QAPM 主打應用性能監控,主要分為指標、個例兩張表,個例表包含更多基礎欄位,一般用戶展示;指標表主要用于聚合計算,
首先確定主鍵,毋庸置疑的前兩個一定是
-
app_id,放首位,因為可能存在同一個產品不同功能聯動的情況,比如會話分析 -
category,放第二位,因為功能之間獨立,大量查詢只涉及單功能
指標沒有特征鍵值,因此只添加處理時間作為第三個主鍵,
對于指標表,設定的主鍵為:app_id, category, entrance_time
個例存在特征 feature,由于:
-
大量查詢都包含 feature_md5 -
feature 是行的特征,相同的特征表明兩行相似,
將特征的 md5 增加到主鍵中,用于加速查詢、提高壓縮率,但是這里有兩個方向:
-
若 feature_md5 是高基數、大量長尾的欄位 -
設定的主鍵為: app_id, category, intDiv(entrance_time, 3600000), feature_md5 -
若 feature_md5 基數可以降低到千、萬量級 -
設定的主鍵為: app_id, category, feature_md5, entrance_time
磁區鍵設定為`PARTITION BY intDiv(entrance_time, 2592000000)鑒于SAMPLE BY需要將 xxHash 欄位放在主鍵中,主鍵都包含高基數欄位,就不設定抽樣鍵,而是在需要的時候軟抽樣[21]:
SELECT count() FROM table WHERE ... AND cityHash64(some_high_card_key) % 10 = 0; -- Deterministic
SELECT count() FROM table WHERE ... AND rand() % 10 = 0; -- Non-deterministic插入優化
資料插入看起來和查詢性能沒什么聯系,但是有間接影響,不合理的插入會導致更多的寫盤、更多的資料 merge 甚至有可能插入失敗,影響讀盤性能,
聚合寫入
ClickHouse 作為 OLAP 并不適合小批量、大并發寫入,相反而適合大批量、小并發寫入,官方建議插入資料每批次至少 1000 行,或者每秒鐘最多 1 次插入,[22]
這一小節我想強調原子(Atomic Insert)寫入的概念:一次插入創建一個資料 part,
前文提及,ClickHouse 一個 part 是一個檔案夾,后臺有個 merge 執行緒池不斷 merge 不同的 part,原子插入可以減少 merge 次數,讓 ClickHouse 負載更低,性能更好,
原子寫入的充分條件[23]:
-
資料直接插入 MergeTree表(不能有 Buffer 表) -
資料只插入一個 partition(注意前文提到的 partition 和 part 的區別) -
對于 INSERT FORMAT -
插入行數少于 max_insert_block_size(默認 1048545) -
關閉并行格式化 input_format_parallel_parsing=0 -
對于 INSERT SELECT -
插入行數少于 max_block_size -
小 block 被合并到合適的 block 大小 min_insert_block_size_rowsandmin_insert_block_size_bytes -
MergeTree表不包含物化視圖
這里貼一下我們生產的配置(users.xml),
經過統計,個例表每行大約 2KB,指標表每行大約 100B(未壓縮),
設定min_insert_block_size_rows為 10000000,指標會先滿足這個條件,大概一個 block 原始大小 1GB,設定min_insert_block_size_bytes為 4096000000,個例會先滿足這個條件,大概一個 block 原始大小 1G,約 1024000 行,
這三個配置項是客戶端配置,需要在插入的 session 中設定,而不是在那幾個.xml中配置,
max_insert_block_size: 16777216
input_format_parallel_parsing: 0
min_insert_block_size_rows: 10000000
min_insert_block_size_bytes: 1024000000注意,min_insert_block_size_rows和min_insert_block_size_bytes是“或”的關系:
// src/Interpreters/SquashingTransform.cpp
bool SquashingTransform::isEnoughSize(size_t rows, size_t bytes) const
{
return (!min_block_size_rows && !min_block_size_bytes)
|| (min_block_size_rows && rows >= min_block_size_rows)
|| (min_block_size_bytes && bytes >= min_block_size_bytes);
}讀寫分離
??:本方案并沒有經過生產驗證,酌情考慮
ClickHouse 有 Shard 和 Replica 可以配置,作用如下圖所示:
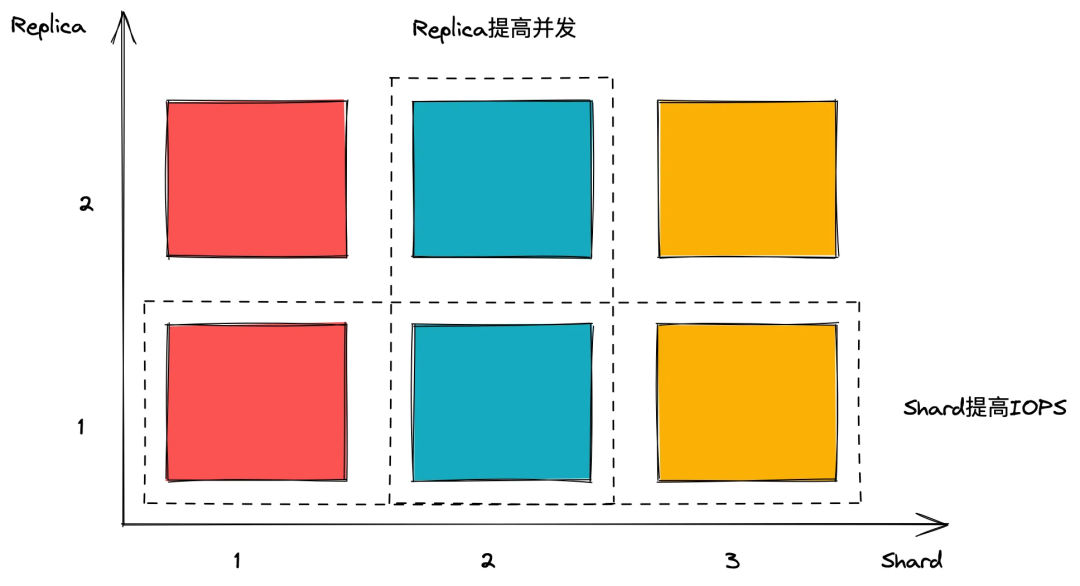
所謂讀寫分離也就是將 Shard 分為兩半,一半只用于查詢,只要讓分布式表查詢都匯入到 Shard1 即可(在users.xml中配置load_balancing為first_or_random);一半用于寫入,插入的程式手動控制插入 Shard2 的節點,由 ClickHouse 的 ReplicatedMergeTree 不同 Shard 資料依靠 zookeeper 自動同步的策略將資料同步到 Shard1,[24]
這種策略有天然的缺陷:
-
寫的那半 Shard 持續有一定量(不會很高)的資源消耗用于寫入 -
讀的那半 Shard 會有資源消耗用于同步寫入(由于不用處理,會比直接寫入的情況資源消耗更低),但是讀請求會導致資源消耗突增 -
并發增加時性能不如混合情況,因為讀寫分離相當于將讀資源砍半
??:或許可以配置兩邊 Shard 資源不一致來解決問題,比如寫入的 Shard 資源拉低,專用于處理資料插入;讀的 Shard 資源更高,專門用于處理突增并發流量,
BufferEngine
Buffer 并不推薦常規業務使用,只有在迫切需要查詢實時性+插入無法大批量預聚合時使用:
-
無法 atomic insert -
即使使用 BufferEngine,資料插入也至少 1000 行每次,或者每秒鐘最多 1 次插入[25]
KafkaEngine+MV
該部分待補充,想看的同學可以在評論區踢踢 ??
預聚合
預聚合有三種方法,ETL、物化視圖和投影,他們的區別如下[26]:
| ETL | MV | Projections | |
|---|---|---|---|
| Realtime | no | yes | yes |
| How complex queries can be used to build the preaggregaton | any | complex | very simple |
| Impacts the insert speed | no | yes | yes |
| Are inconsistancies possible | Depends on ETL. If it process the errors properly - no. | yes (no transactions / atomicity) | no |
| Lifetime of aggregation | any | any | Same as the raw data |
| Requirements | need external tools/scripting | is a part of database schema | is a part of table schema |
| How complex to use in queries | Depends on aggregation, usually simple, quering a separate table | Depends on aggregation, sometimes quite complex, quering a separate table | Very simple, quering the main table |
| Can work correctly with ReplacingMergeTree as a source | Yes | No | No |
| Can work correctly with CollapsingMergeTree as a source | Yes | For simple aggregations | For simple aggregations |
| Can be chained | Yes (Usually with DAGs / special scripts) | Yes (but may be not straightforward, and often is a bad idea) | No |
| Resources needed to calculate the increment | May be signigicant | Usually tiny | Usually tiny |
在我們業務中,個例是不應該預聚合的,因為資料需要被拉取展示而不用計算,指標需要聚合,資料量較大,每次實時計算對 ClickHouse 負載太大,
其實還有一種聚合方式,過期資料聚合,可以參考,同樣限制要求 group by 的鍵值為主鍵前綴,
在我們業務使用時,什么時候用哪一個呢?
-
需要針對某個功能加速時,可以考慮物化視圖/投影 -
全表預聚合加速查詢,需要使用 ETL
資源控制
最后,為了避免集群被某個查詢、插入弄垮,需要合理安排記憶體使用,需要給訪問賬戶分權限,在我們業務分為:
-
default:最高級賬號,不使用 -
root:資料插入,配置聚合寫入部分的幾個配置項 -
monitor:內部開發使用,權限較高 -
viewer:web 使用,添加大量限制
viewer賬戶配置如下所示:
<yandex>
<profiles>
<query>
<max_memory_usage>10000000000</max_memory_usage>
<max_memory_usage_for_all_queries>100000000000</max_memory_usage_for_all_queries>
<max_rows_to_read>1000000000</max_rows_to_read>
<max_bytes_to_read>100000000000</max_bytes_to_read>
<max_rows_to_group_by>1000000</max_rows_to_group_by>
<group_by_overflow_mode>any</group_by_overflow_mode>
<max_rows_to_sort>1000000</max_rows_to_sort>
<max_bytes_to_sort>1000000000</max_bytes_to_sort>
<max_result_rows>100000</max_result_rows>
<max_result_bytes>100000000</max_result_bytes>
<result_overflow_mode>break</result_overflow_mode>
<max_execution_time>60</max_execution_time>
<min_execution_speed>1000000</min_execution_speed>
<timeout_before_checking_execution_speed>15</timeout_before_checking_execution_speed>
<max_columns_to_read>25</max_columns_to_read>
<max_temporary_columns>100</max_temporary_columns>
<max_temporary_non_const_columns>50</max_temporary_non_const_columns>
<max_subquery_depth>2</max_subquery_depth>
<max_pipeline_depth>25</max_pipeline_depth>
<max_ast_depth>50</max_ast_depth>
<max_ast_elements>100</max_ast_elements>
<readonly>1</readonly>
</query>
</profiles>
</yandex>同時建議設定 quota,減少大量讀盤計算、LIMIT 少量資料回傳的情況發生,
我們是 CSIG 性能工程二組 QAPM 團隊,QAPM 時一款應用性能監控工具,覆寫 android、ios、小程式、mac 和 win 多端,已有騰訊會議、優衣庫等大用戶接入,值得信賴,歡迎同事試用我們 QAPM 產品~跳轉鏈接
在 ClickHouse 優化程序遇到無數的問題,卡在 ClickHouse 自身監控無法覆寫的角落時,全靠性能工程三組員工的 Drop(雨滴)工具的鼎力相助,高效直觀監控 CVM 各項指標,降低優化門檻,助力業務增效~跳轉鏈接
參考
腳注
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/ClickHouse-query-optimization-in-detail.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/543934.html
標籤:大數據