新的一年我們加緊了更新迭代的速度,增加了資料湖平臺EasyLake和大資料基礎平臺EasyMR,超40項功能升級優化,我們將繼續保持產品升級節奏,滿足不同行業用戶的更多需求,為用戶帶來極致的產品使用體驗,
以下為袋鼠云產品功能更新報告第四期內容,更多探索,請繼續閱讀,
資料湖平臺
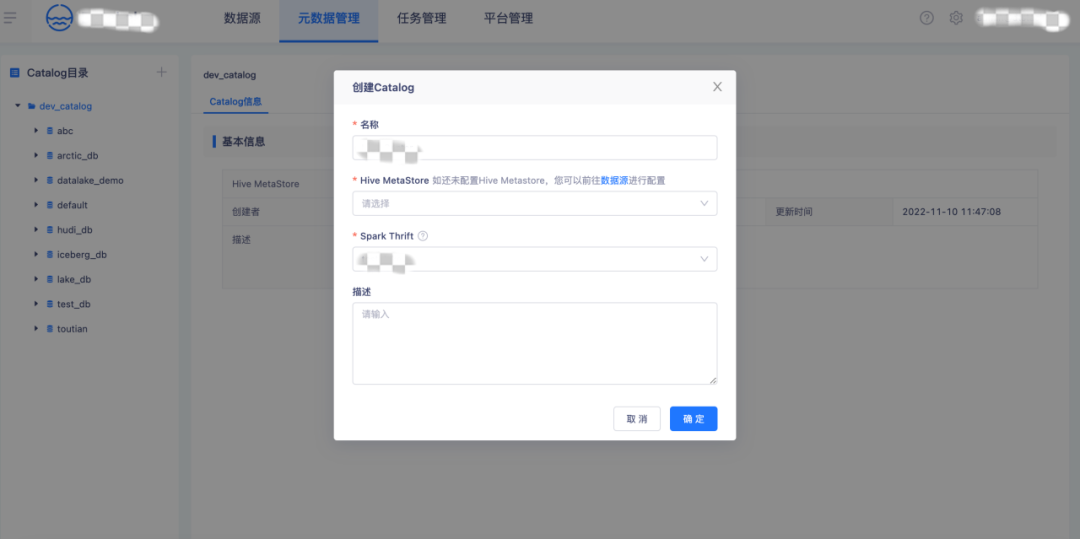
1.【元資料管理】Catalog創建
在【元資料管理】頁創建一個Catalog,填寫Catalog名稱、Hive MetaStore、Spark Thrift,
一個Calalog只允許系結一個Hive MetaStore,Spark Thrift用于Iceberg表創建、資料入湖轉表任務,用戶可以使用Calalog進行業務部門資料隔離,
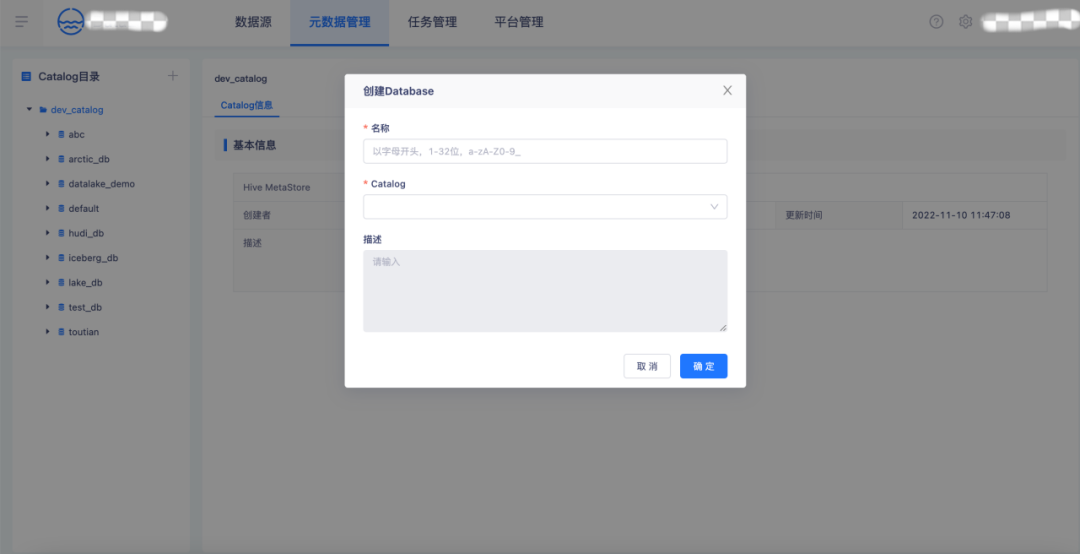
2.【元資料管理】Database創建
在【元資料管理】頁創建一個Database,系結Calalog,
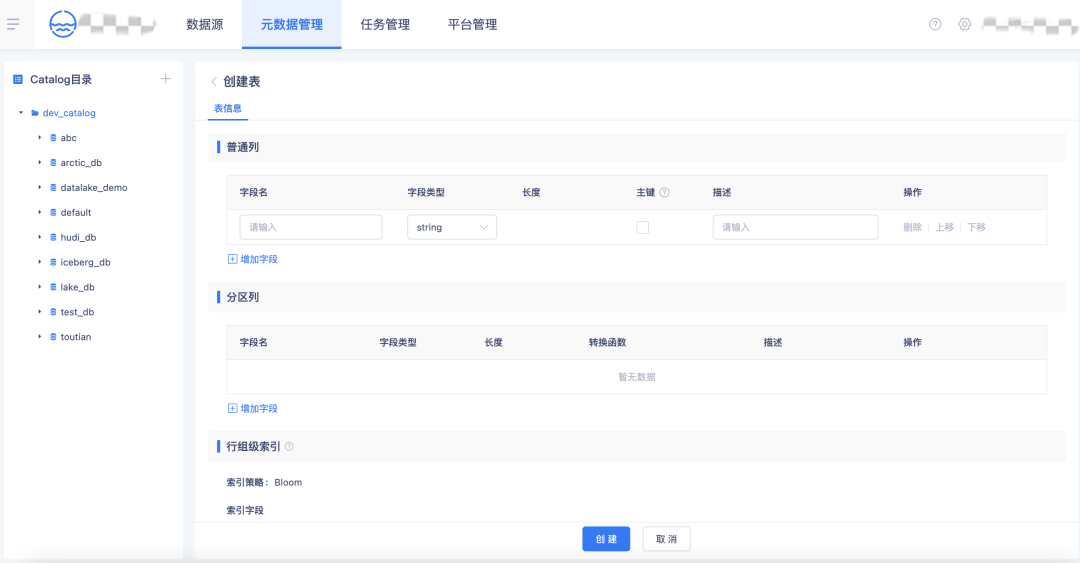
3.【元資料管理】Iceberg表創建
? 在【元資料管理】頁創建一個創建一張Table:選擇Table所在的Catalog、Database,目前只支持Iceberg湖表創建;
? 設定表普通列,支持對普通列欄位設定主鍵,可以用作湖表的唯一標識;
? 選擇普通列欄位作為磁區欄位,支持多種轉換函式,timestamp資料型別欄位支持時間欄位按照年、月、日和小時粒度劃磁區;
? 支持行組級索引設定,選擇普通列作為索引欄位,設定Bloom索引;
? 自定義高級引數設定,
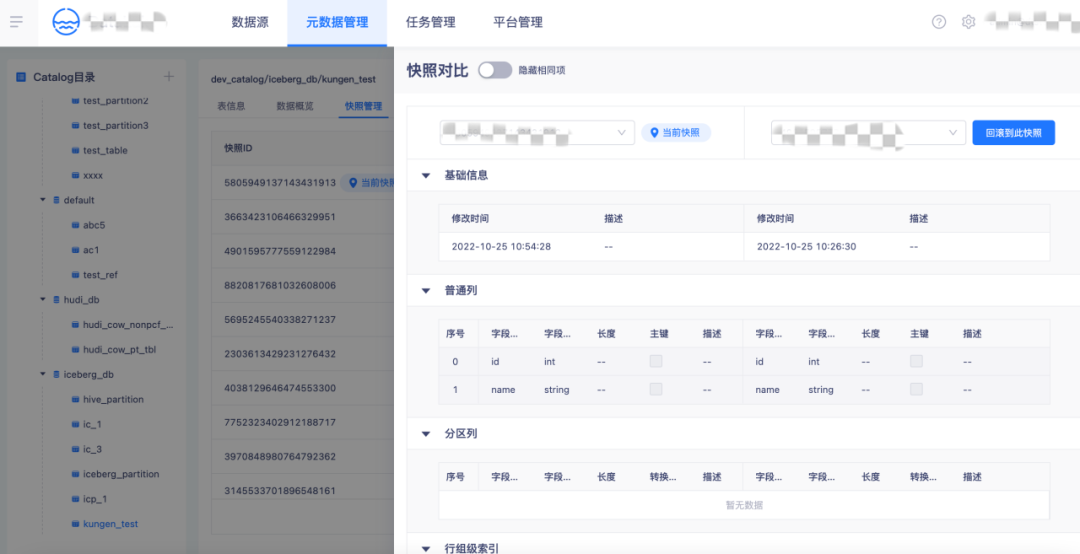
4.【元資料管理】Iceberg表快照管理
支持快照歷史管理,支持多版本間快照變更對比,支持湖表時間旅行,可一鍵回滾到指定資料版本,
5.【資料入湖】支持Hive轉Iceberg表實作Hive表入湖
在【資料入湖】頁創建一個入湖任務,選擇Parquet、ORC、Avro格式Hive表進行轉表入湖,一鍵生成湖表資訊.
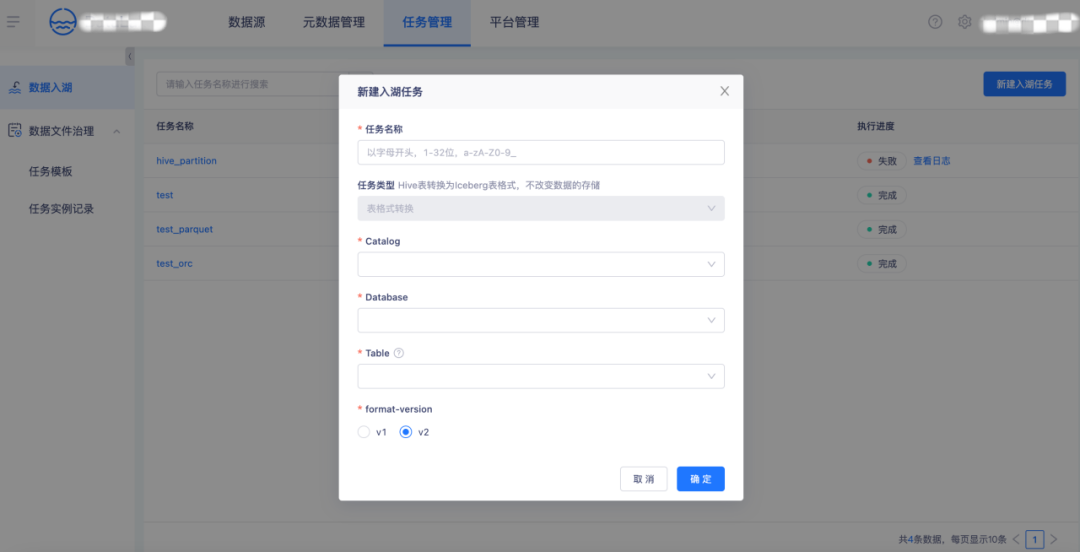
6.支持小檔案合并、孤兒檔案清理、過期快照清理
在【資料檔案治理】-【任務模板】頁新建任務模板,支持小檔案合并、快照清理、孤兒檔案清理等資料檔案治理任務,支持立即支持、預約治理、周期治理多種資料治理方式,
大資料基礎平臺
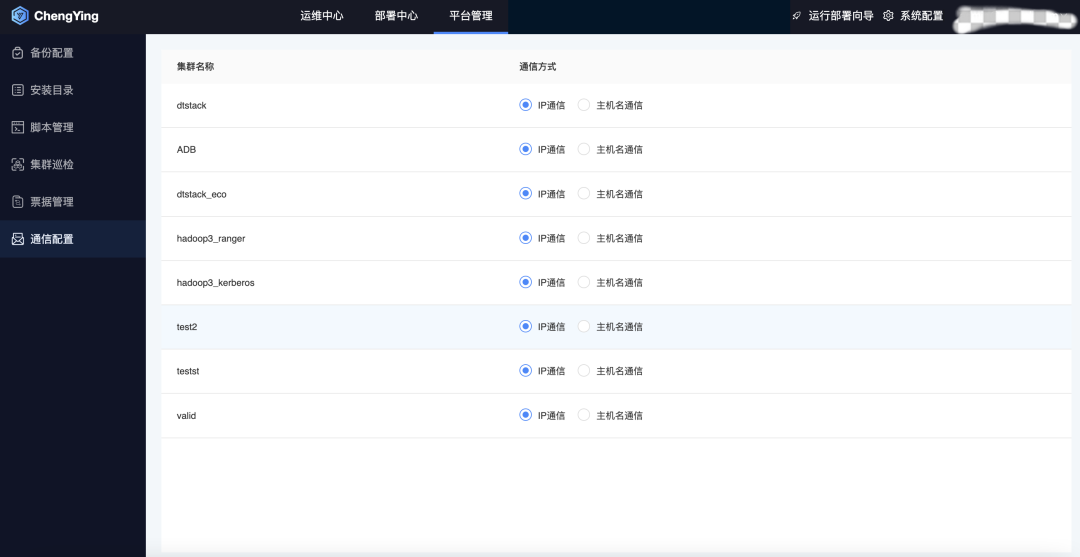
1.【全域】使用主機名作為機器唯一標識
? EM平臺產品上變更為以主機名Hostname作為唯一標識對主機進行管理;
? 主機間通信默認為IP通信,可在【平臺管理】-【通信配置】頁進行通信方式切換,
2.功能優化
? 告警:新建告警通道出現例外時dtalert和grafana告警通道不一致
? 告警:dtalert掛載目錄與上傳jar包目錄不一致
? 告警:添加自定義告警通道保存后編輯上傳jar包不顯示
? Hadoop安全:EM開啟Hadoop安全,服務未重啟,直接顯示開啟成功
? 備份優化:EM備份管理查詢優化
? redis角色獲取:redis運行正常,但是角色獲取資訊有誤,導致部署其他服務無法正確獲取redis角色狀態
離線開發平臺
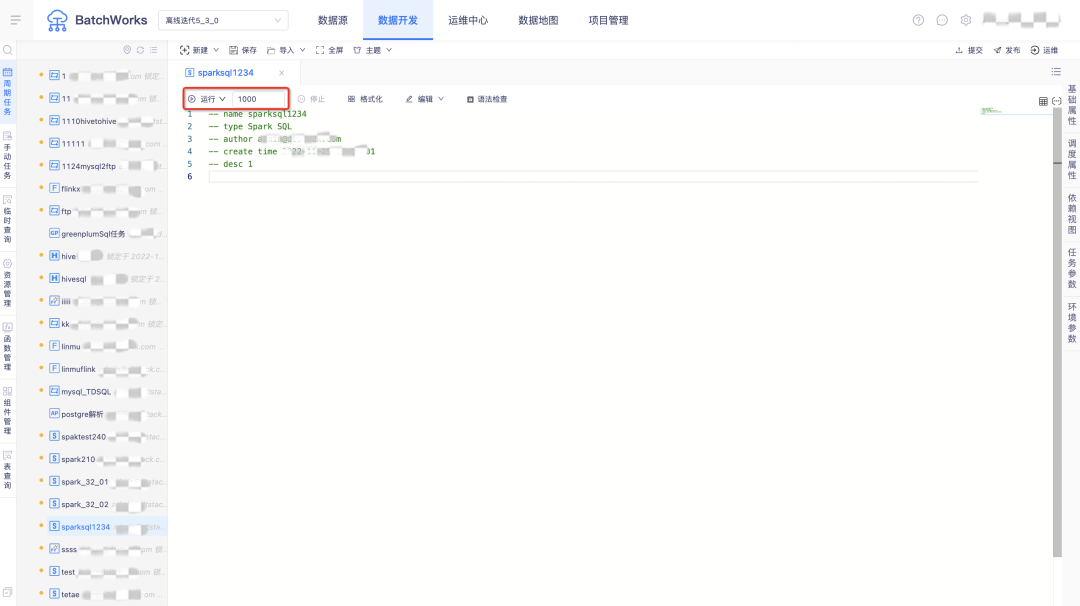
1.資料開發IDE中可限制資料查詢條數
用戶痛點:資料開發頁面的臨時運行沒有限制資料結果查詢條數,極端情況下有把系統磁盤打滿的風險,
新增功能說明:所有SQL型別任務,運行按鈕右側新增了資料查詢條數輸入框,默認查詢條數為1000條,上限最大值為1000000條(最高上限為配置項,可在后臺配置),
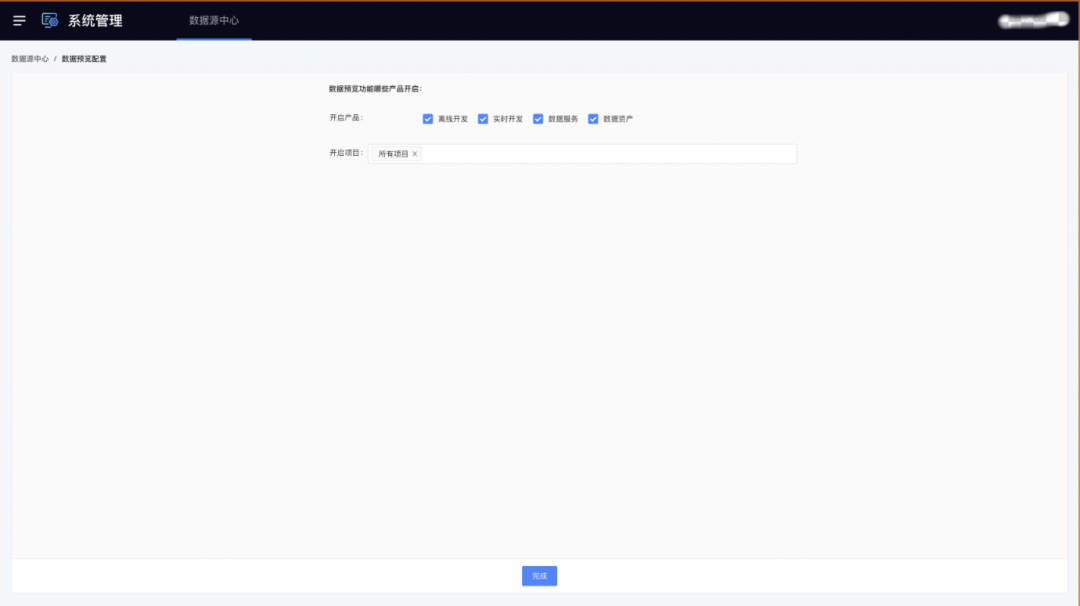
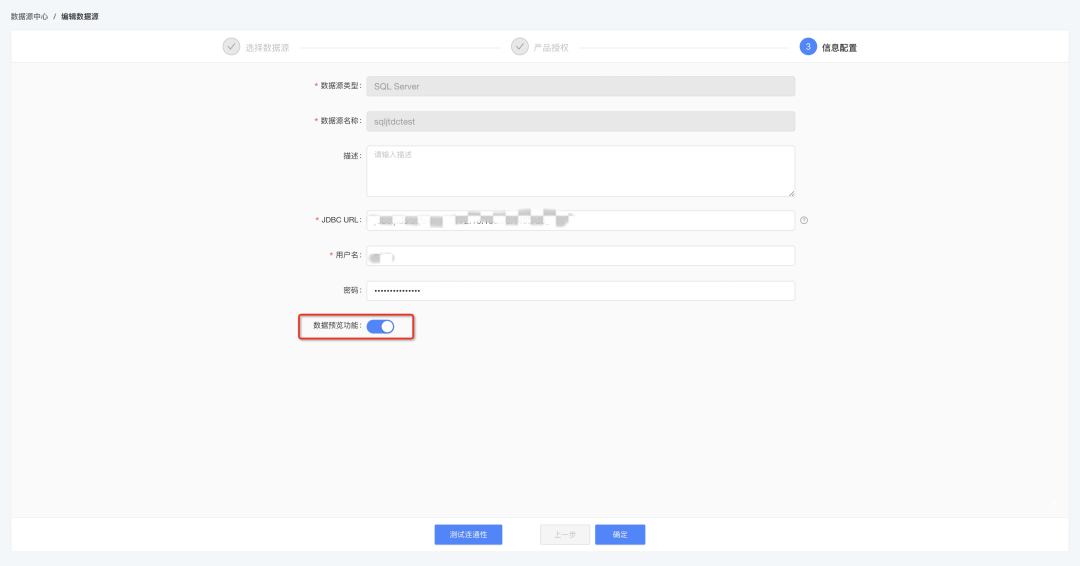
2.資料預覽全域管控功能對接
資料源中心新增資料預覽全域管控開關:
? 可進行子產品和專案的資料預覽全域管控
? 可進行單個資料源的資料預覽管控
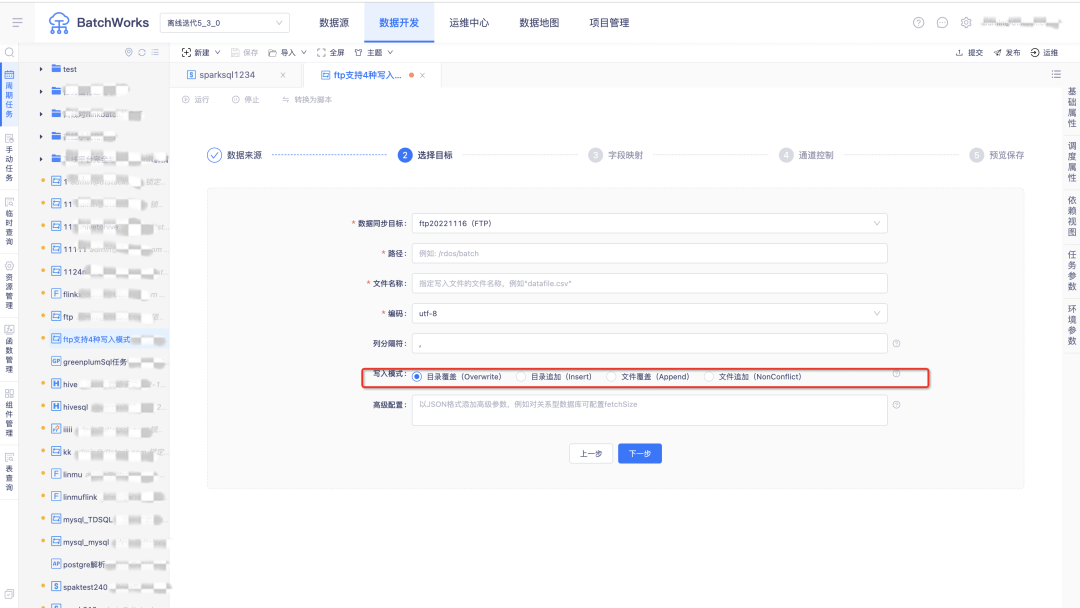
3.FTP作為目標資料源支持4種寫入模式
? append:按檔案名稱覆寫寫入;
? overwrite:先清空目錄下的檔案然后寫入;
? nonconflict:按檔案名稱查找,存在同名檔案則報錯,不存在同名檔案則可正常寫入;
? insert:檔案追加寫入,存在同名時通過添加后綴的方式修改新檔案的檔案名稱;
4.運行超時中斷
任務支持設定超時時間,運行時間超過此時間時后臺會自動殺死,
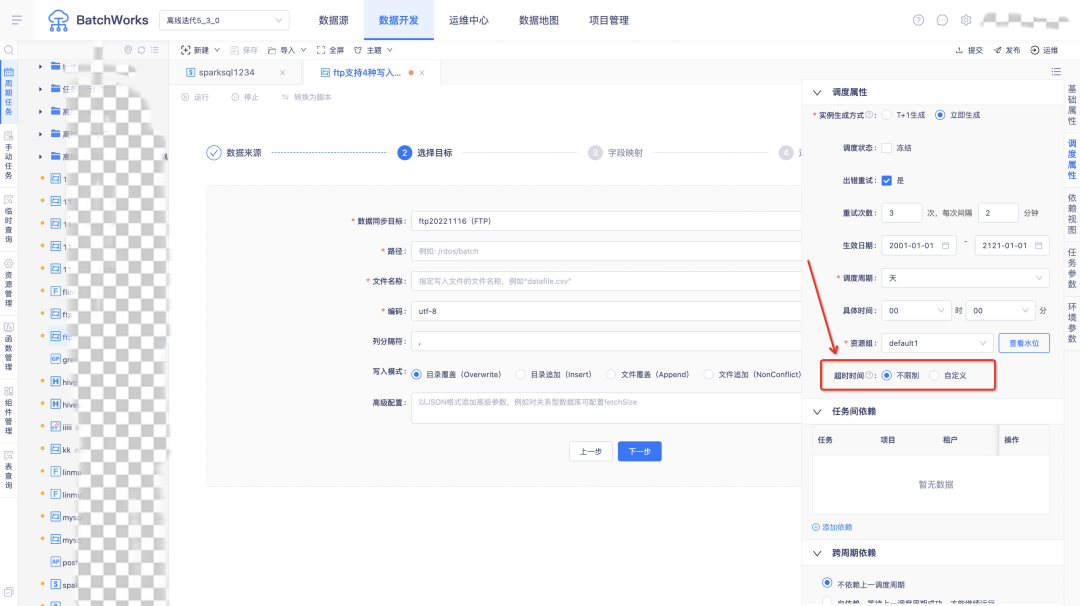
5.資料同步通道控制頁面支持配置高級引數
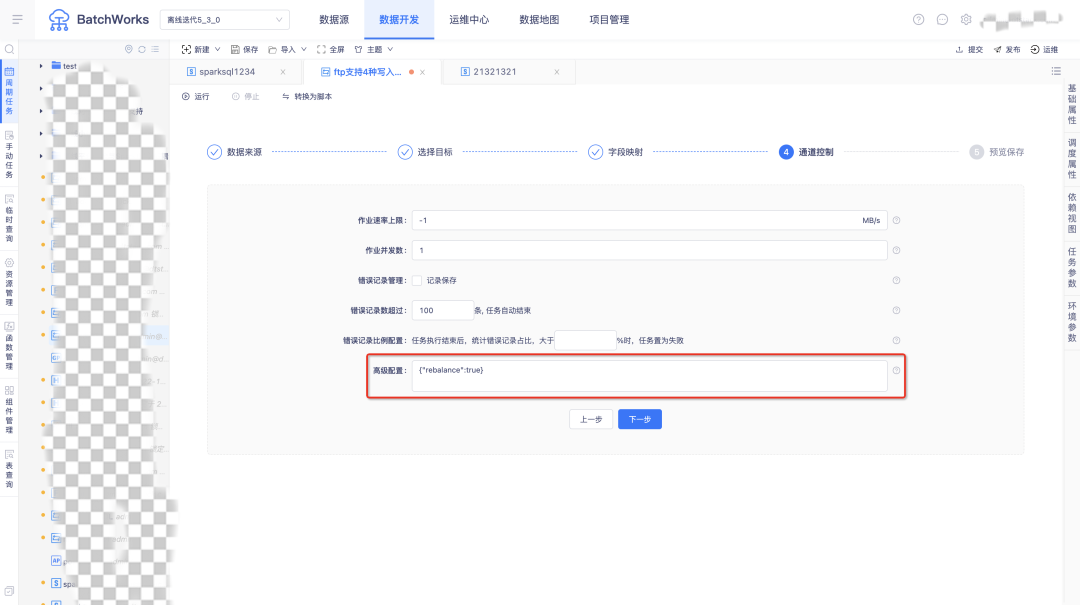
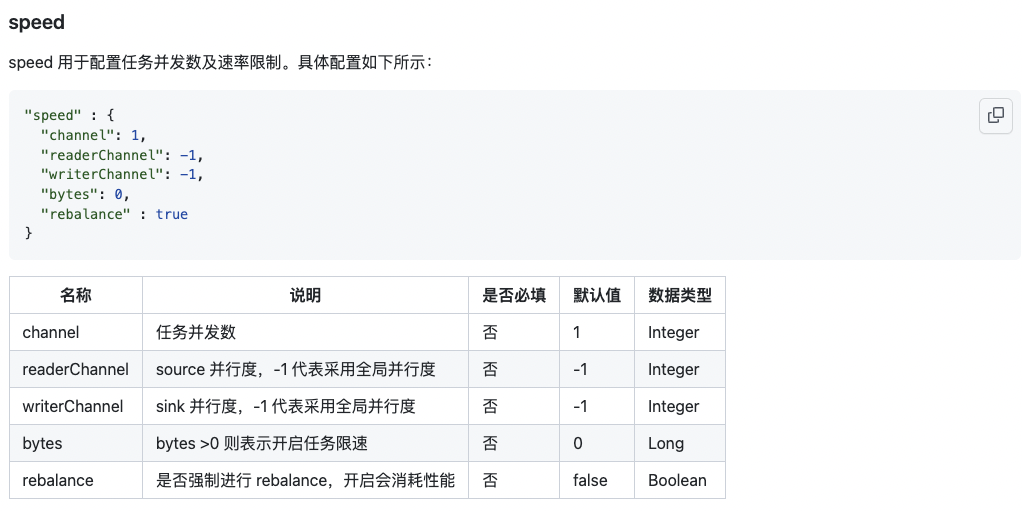
6.其他新增功能項
? Inceptor表接入資料地圖:Inceptor已資料地圖中支持元資料查詢、資料脫敏、血緣展示等功能;
? 支持Flink Batch任務型別;
? HBase REST API支持資料同步讀取;
? Sybase 支持資料同步讀取,
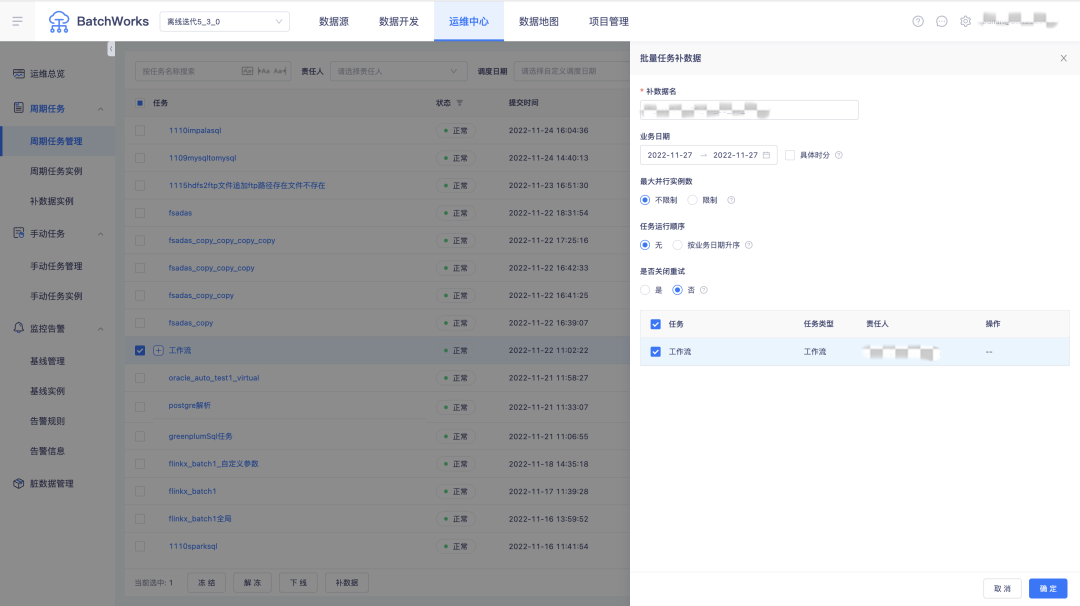
7.補資料優化
? 補資料支持三種補資料模式:單任務補資料、在任務管理串列按篩選條件篩選批量任務補資料、按任務上下游關系選擇多個任務補資料;
? 多個在同一依賴樹但彼此之間存在斷層/不直接依賴的任務,所生成的補資料實體仍將按原依賴順序執行;
? 支持選擇是否關閉重試;
? 補資料支持選擇未來時間,
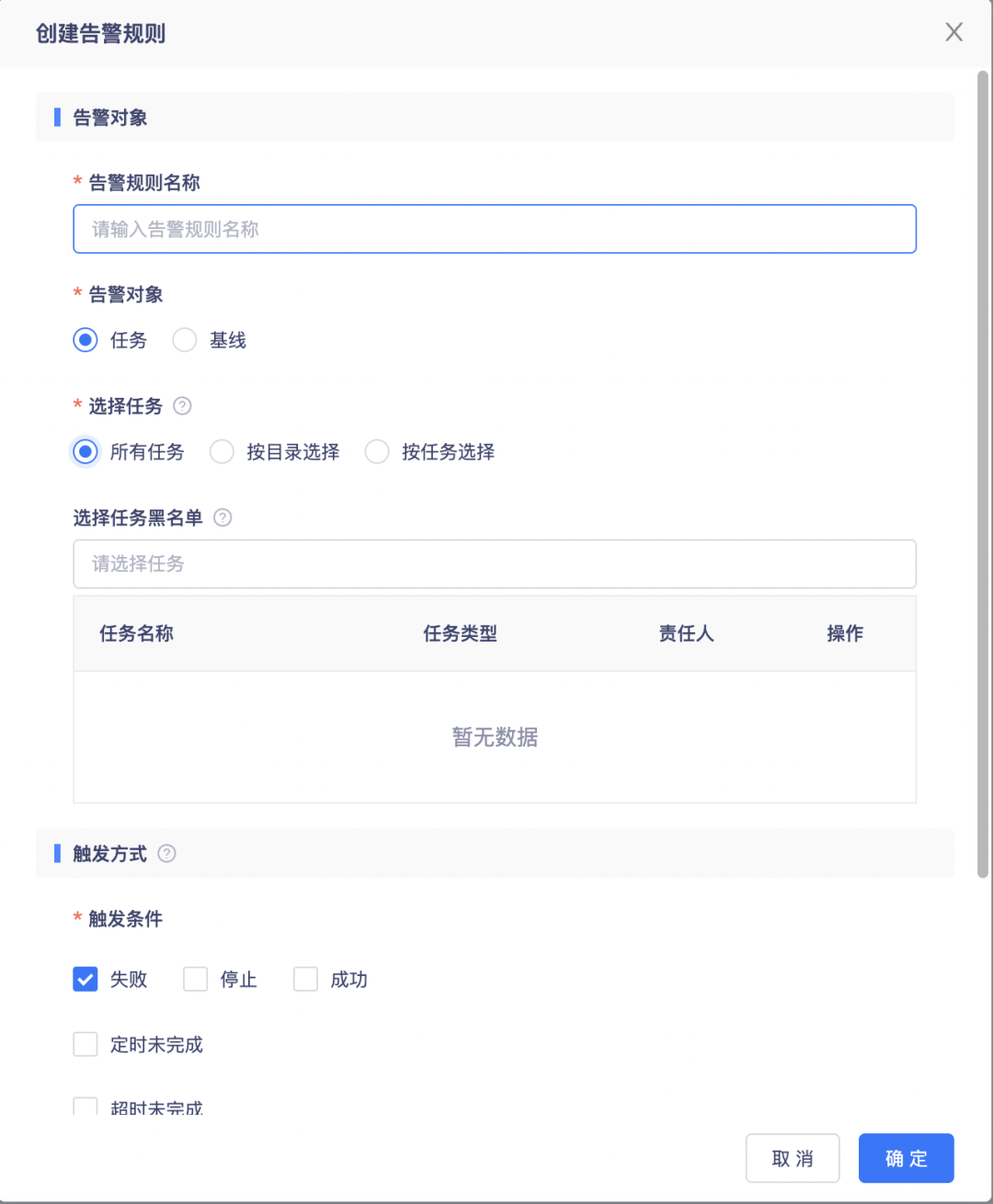
8.告警規則任務選擇方式優化
支持按專案全選任務或按任務管理目錄全選目錄下任務,
9.整庫同步功能優化
? 整庫同步支持選擇:Oracle MySQL DB2 Hive TiDB PostgreSQL ADB Doris Hana 作為整庫同步目標端;
? 高級設定能查看歷史配置,針對同一資料源和schema,能記錄高級設定的規則內容,
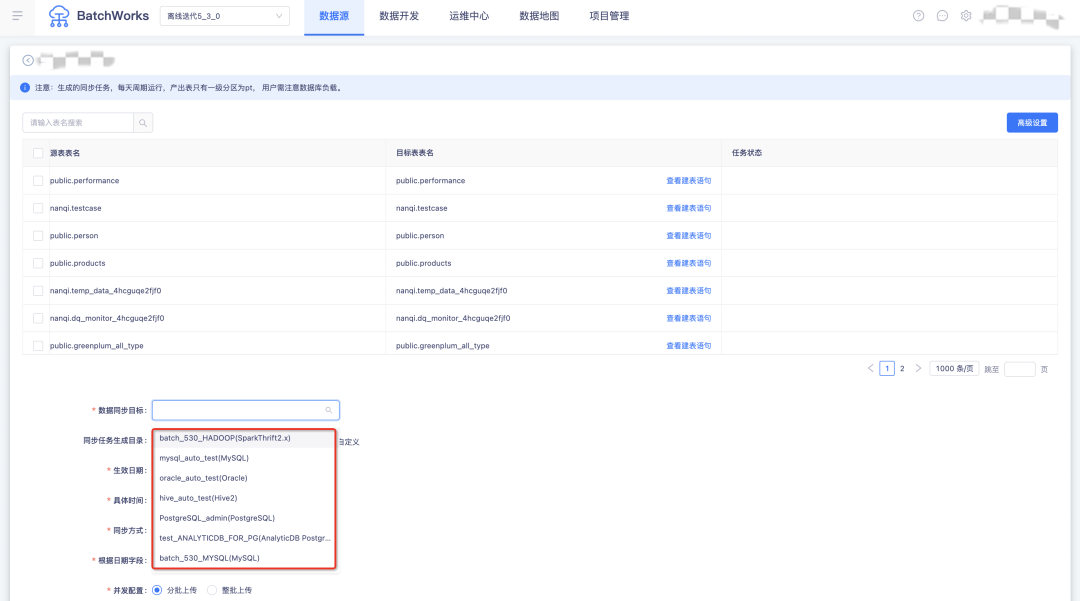
10.Greenplum任務調整
? Greemplum SQL 和 Inceptor SQL 臨時運行復雜SQL和包含多段SQL時運行邏輯從同步運行修改為異步運行;
? 表查詢中可查看Greenplum元資料資訊;
? 支持語法提示,
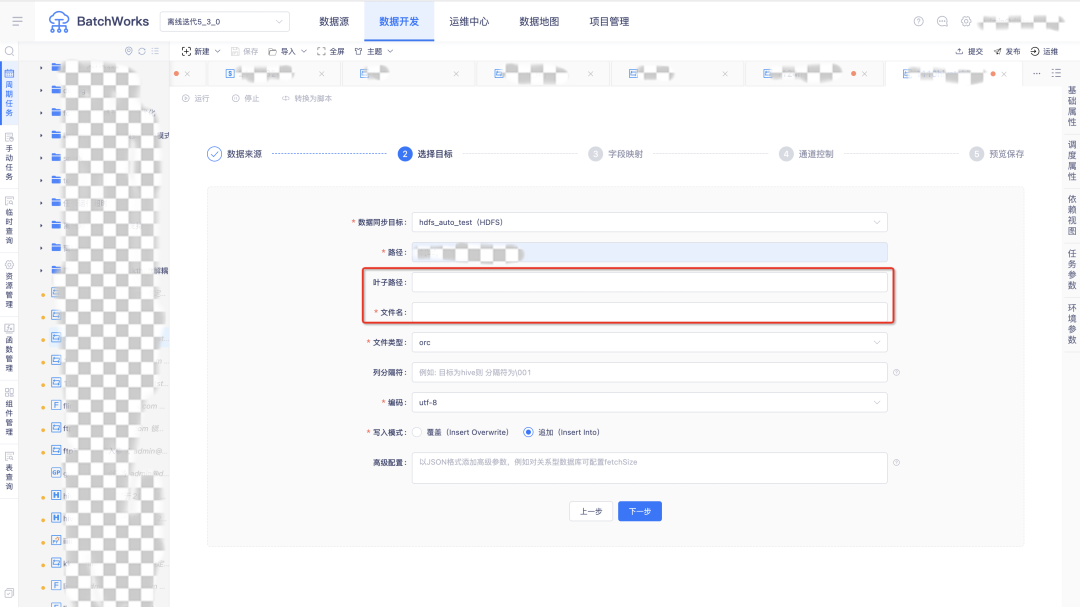
11.資料同步至HDFS時支持指定檔案名稱
用戶痛點:歷史寫HDFS時,指定檔案名實際是指定的葉子目錄名稱,實際無法指定檔案名稱,
體驗優化說明:在高級配置中新增了引數strictMode,當引數值為“true”時,開啟嚴格模式,當引數值為”false“時,開啟寬松模式,嚴格模式下,指定葉子路徑下的檔案名,僅允許存在一個檔案名,多并行度、斷點續傳將不生效,
12.創建專案只允許以英文字母開頭
因部分引擎只能創建/讀取以英文字母開頭的schema(例如Trino),所以創建專案時專案標識限制為只允許以英文字母開頭,
13.發布按鈕點擊邏輯優化
修改前:只有已提交的任務發布按鈕才可點擊,
修改后:所有狀態的任務發布按鈕均可點擊,
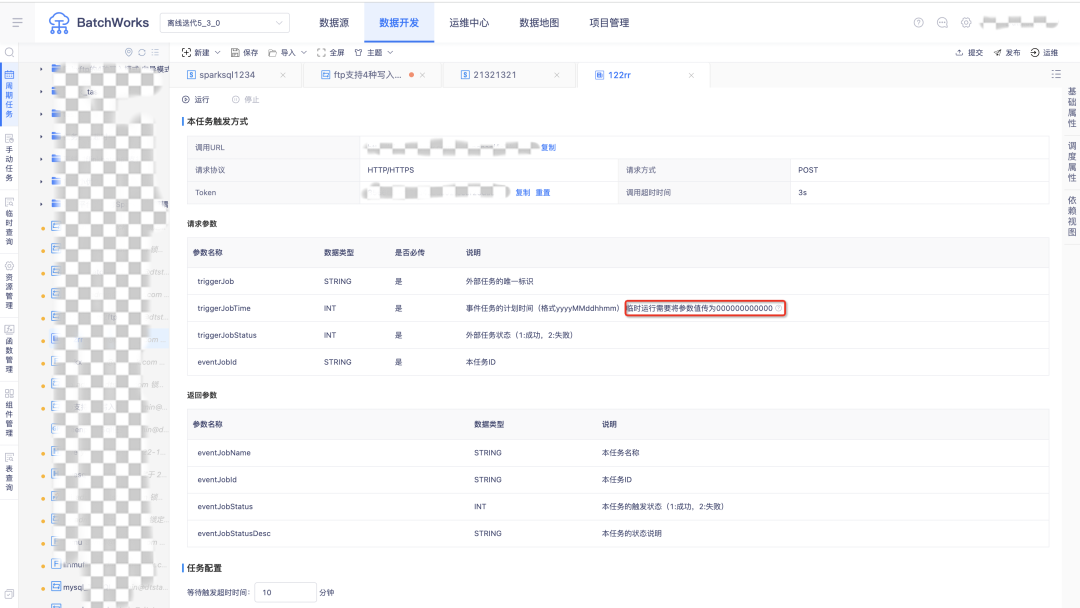
14.事件任務文案調整
臨時運行需要將引數值傳為000000000000,
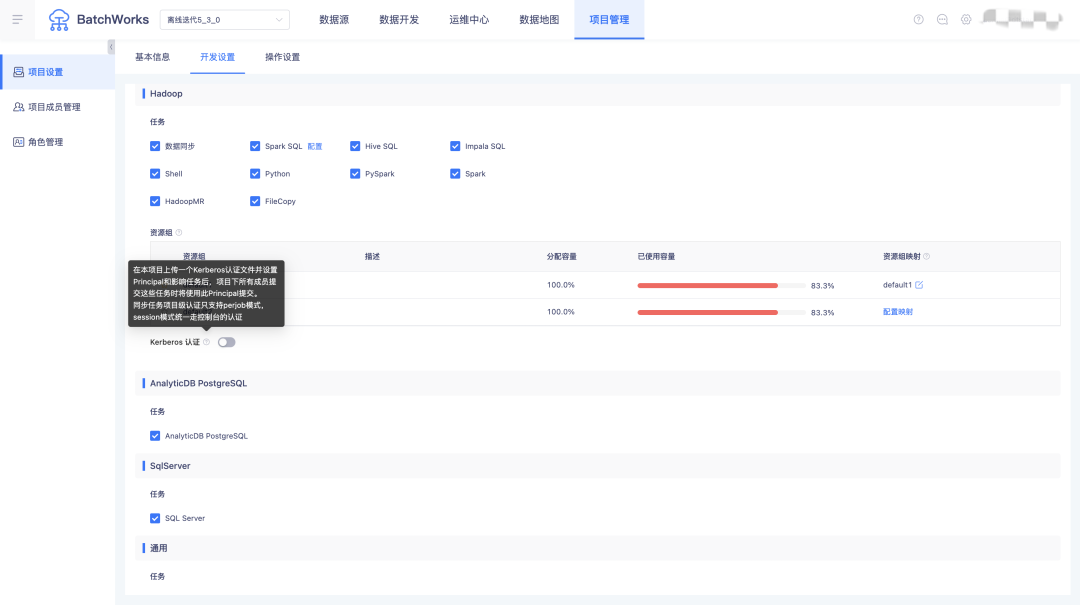
15.專案級kerberos新增提示
16.資料同步可選表范圍優化
用戶痛點:meta schema對應的資料源和連接用戶都是控制臺的,如果不限制專案里的這個資料源只能選擇專案對接的這一個schema,相當于每個專案都可以通過資料同步繞過資料權限管控把集群下所有別的專案的schema的表直接同步到當前專案中用,這是一個非常大的權限漏洞,
體驗優化說明:
? 過濾臟資料表;
? 針對所有meta schema所對應的資料源固定可選schema的范圍僅當前專案對接的schema;
? 如果需要在當前專案同步任務里要用到其他schema,可以把其他專案的meta schema通過租戶管理員授權引入當前專案里用,
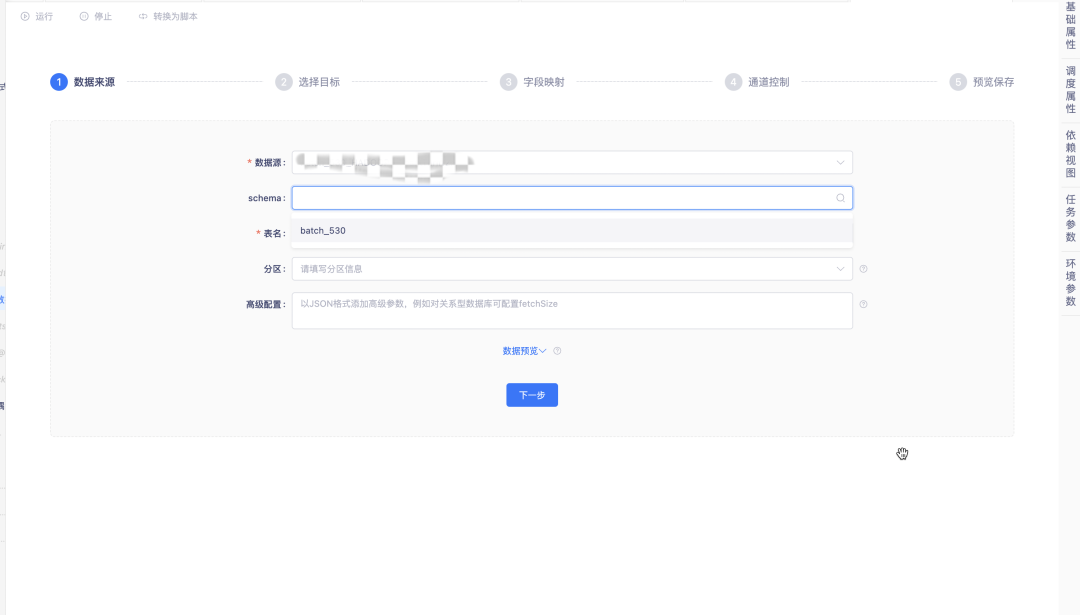
17.資料同步實體運行指標展示優化
資料同步任務實體的運行日志優化了同步性能展示方式,
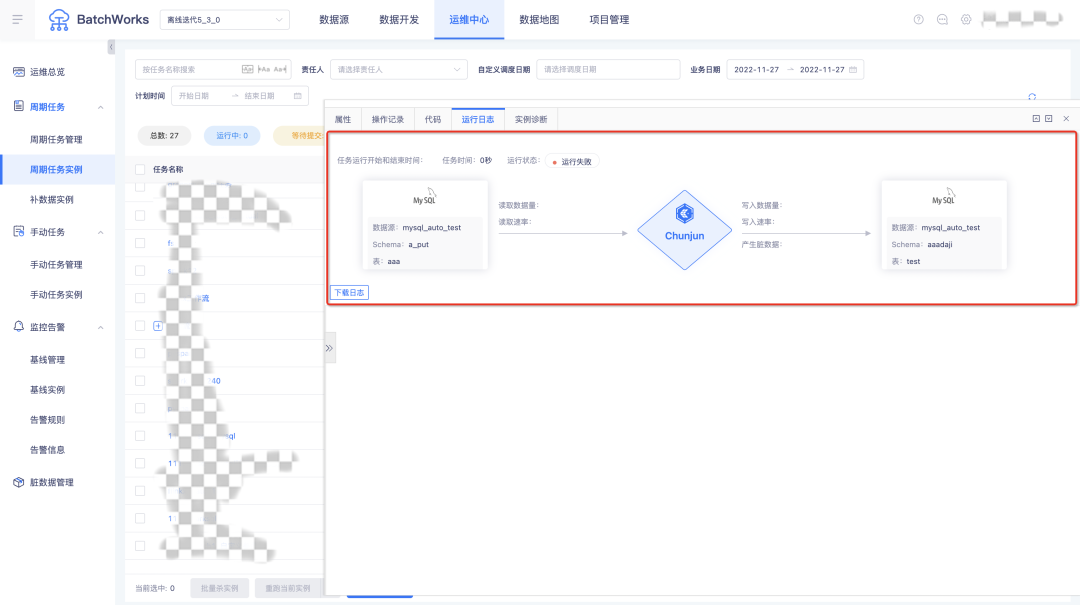
18.其他體驗優化項
? 安全審計操作物件“腳本”修改為“臨時查詢”;
? for回圈內網路開銷呼叫優化,
實時開發平臺
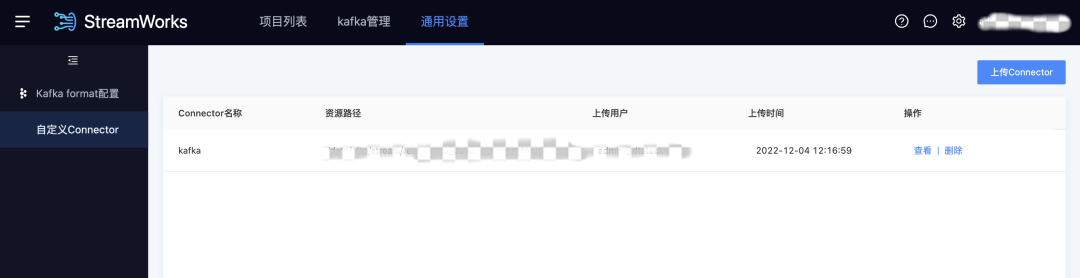
1.自定義Connector
用戶痛點:隨著實時產品客戶的增長,各種各樣的資料源插件需求不斷,我們希望有開發能力的客戶,可以不用等產品迭代,自行開發插件去使用產品,使產品能力越來越開放靈活,
新增功能說明:對于ChunJun尚未支持的資料源,支持上傳【用戶自行開發/第三方】的插件包(需符合Flink Connector的開發要求,平臺不校驗插件的可用性),然后在腳本模式的任務開發中使用,
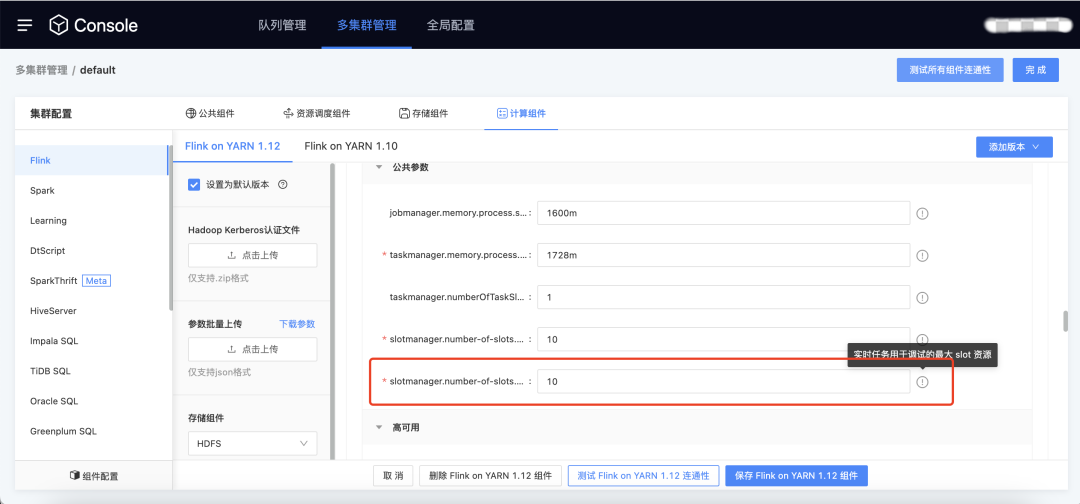
2.Session模式
用戶痛點:之前實時任務的除錯功能,和普通任務一樣走的per job模式,雖然該模式可以保障任務運行的穩定性,但是整個的提交-申請資源-運行,后端處理流程較長,不符合除錯的功能場景(除錯不需要持續的穩定性,但是需要快速的出結果),
新增功能說明:除錯任務以session模式運行,提高除錯效率,用戶需要先在控制臺為實時debug分配slot資源,
3.表管理
用戶痛點:之前每個實時任務的開發,都需要臨時映射Flink表,開發效率較低;之前提供的Hive catalog表管理,需要用戶維護Hive Metastore,對原Hive有一定的入侵,
新增功能說明:提供數堆疊MySQL作為Flink元資料的存盤介質;提供向導和腳本兩種模式維護Catalog-database-table;支持在IDE開發頁面直接創建、參考Flink庫表(需要已Catalog.DB.table的方式參考),
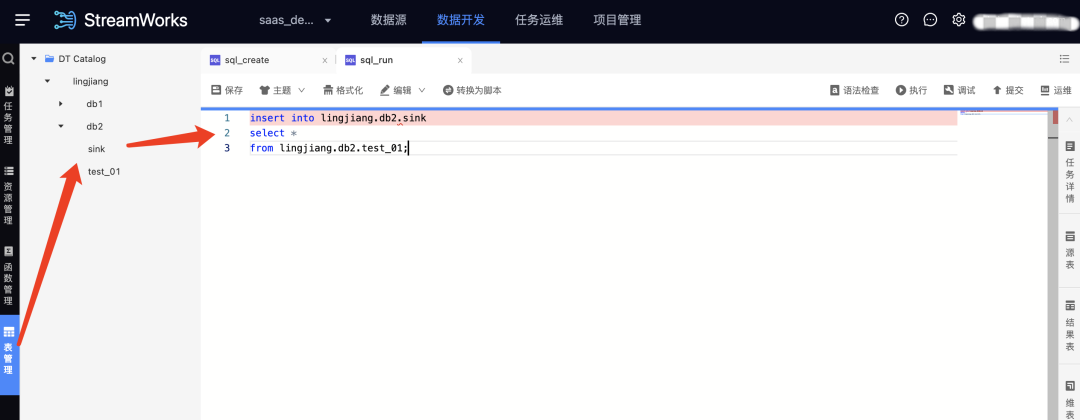
4.資料源新增/優化
? 新增GreatDB作為FlinkSQL的維表、結果表;
? 新增HBase2.x作為FlinkSQL的結果表;
? 新增Phoenix5.x作為FlinkSQL的結果表;
? 優化Oracle資料源,新增序列管理、clob/blob長文本資料型別支持,
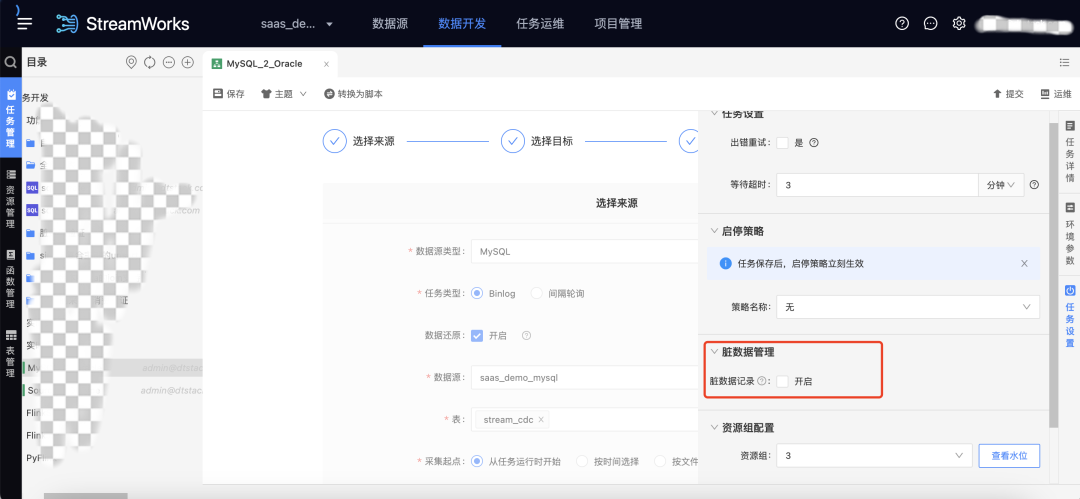
5.臟資料管理
用戶痛點:原臟資料管理僅支持FlinkSQL任務,
新增功能說明:實時采集也支持臟資料管理,
6.功能優化
? 任務運維:新增串列過濾器,支持按狀態、任務型別、責任人等過濾查詢;
? 資料開發:優化任務操作相關按鈕的排版;IDE輸入支持自動聯想;實時采集腳本模式支持注釋,
資料資產平臺
1.資料源
? 新增資料源支持:
Greenplum、DB2、PostgreSQL(V5.3.0)
Hive3.x(Apache)、Hive3.x(CDP)、TDSQL、StarRocks(V5.3.1)
? Meta資料源自動授權支持:
Hive3.x(Apache)、Hive3.x(CDP)(V5.3.0)
TiDB(V5.3.1)
2.資料地圖
? 新增指標:指標進資料地圖,作為資產平臺的一類資產;
? kafka元資料優化:Kafka隱藏表結構,新增磁區查詢tab;
? 標簽篩選優化:標簽采集到的任務,之前沒有根據物體進行區分,會出現標簽名稱相同的情況,新增功能為標簽添加「所屬物體」屬性并在快速篩選欄增加物體篩選;
? 表標簽優化:表維度進入時,顯示「表標簽」,其他維度顯示「標簽」;各個維度打的標簽相互隔離,從不同維度進入時,不再能看到全部標簽,
3.API血緣
實作了表到API、API到API的血緣鏈路打通,
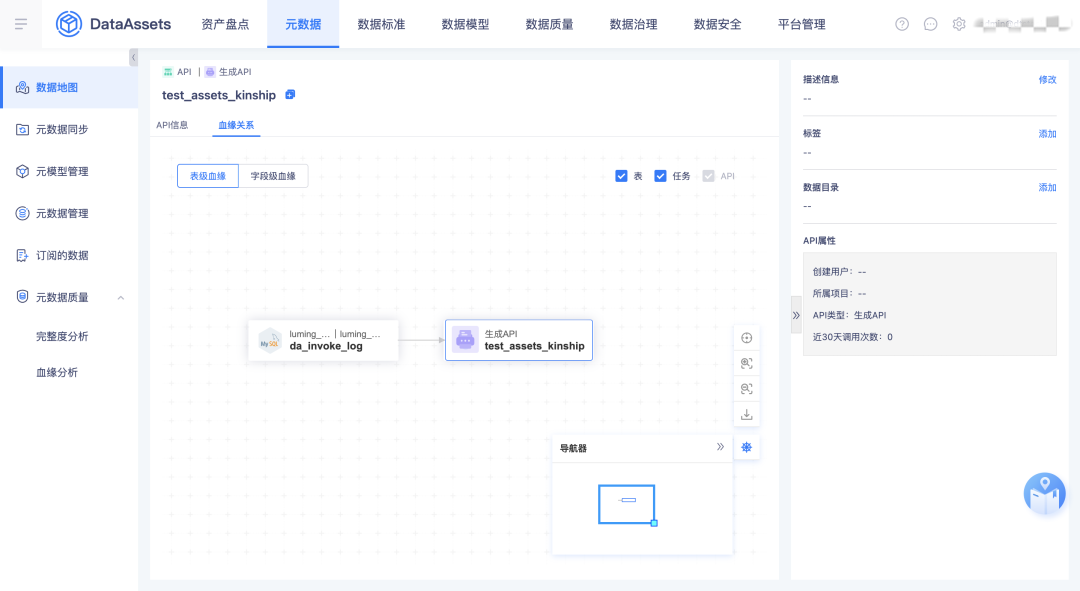
4.指標/標簽血緣
本期把指標標簽內部的血緣關系先拿到資產進行展示,下一期會實作表到指標、表到標簽的血緣關系,
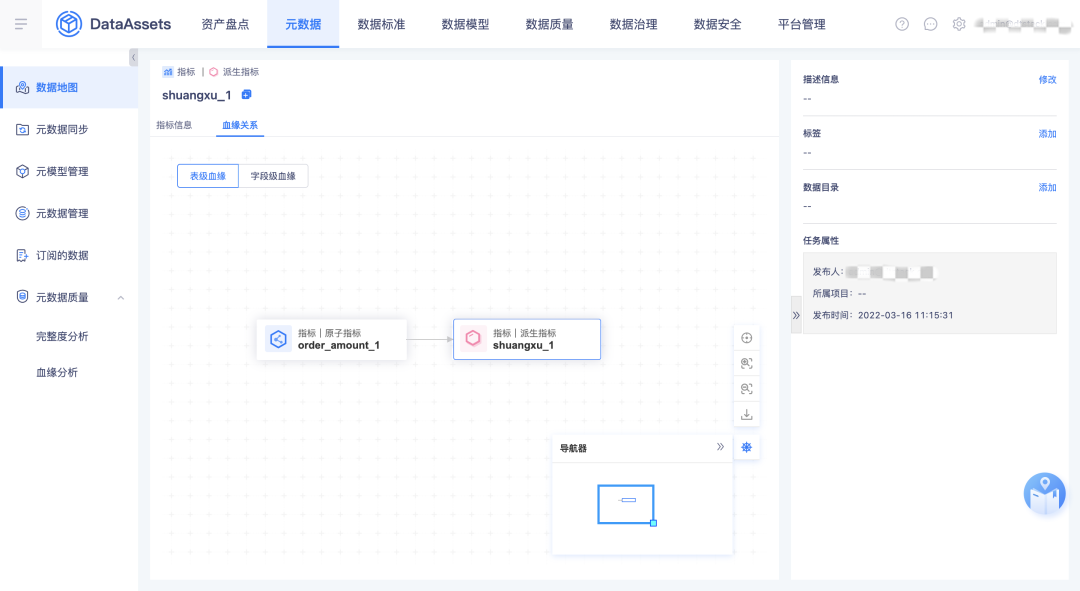
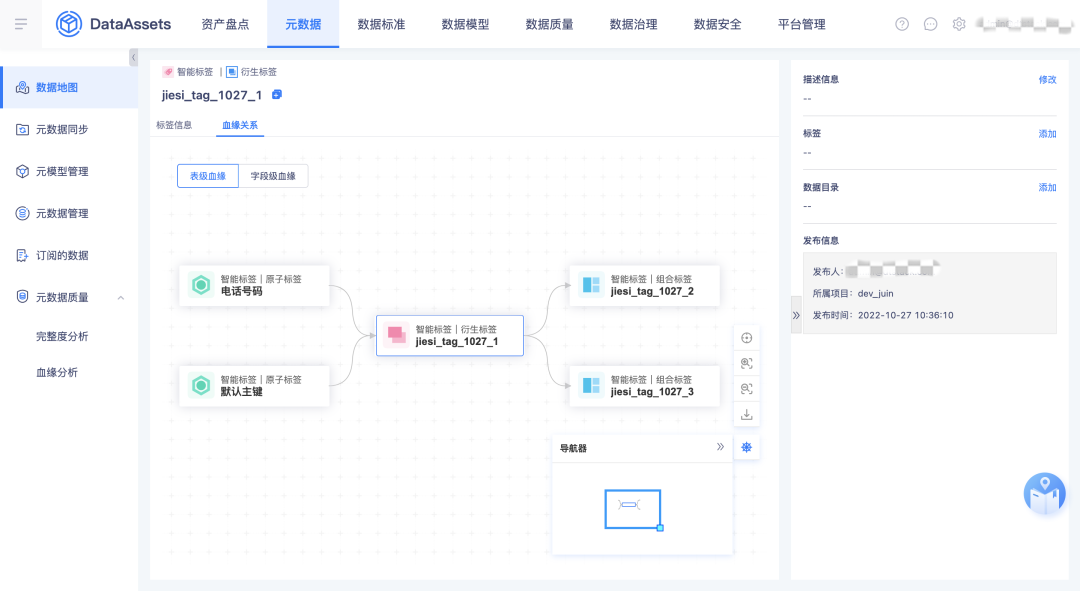
5.血緣優化
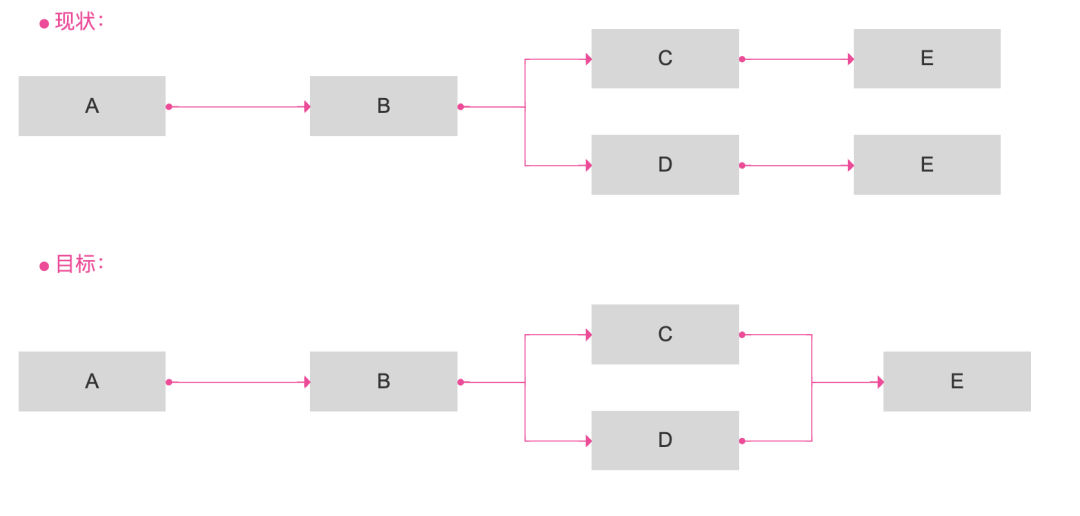
? 血緣決議新增truncate關鍵詞:當表發生trancate資料清空時,表與表之間、表與任務之間的血緣關系需要洗掉;
? 排除自身到自身的血緣以及重復展示的血緣;
? 解決線段與表相互覆寫問題:直角的血緣流向線段改為彎曲的灰色線;支持拖動;高亮當前覆寫或點擊的表的流入和流出,
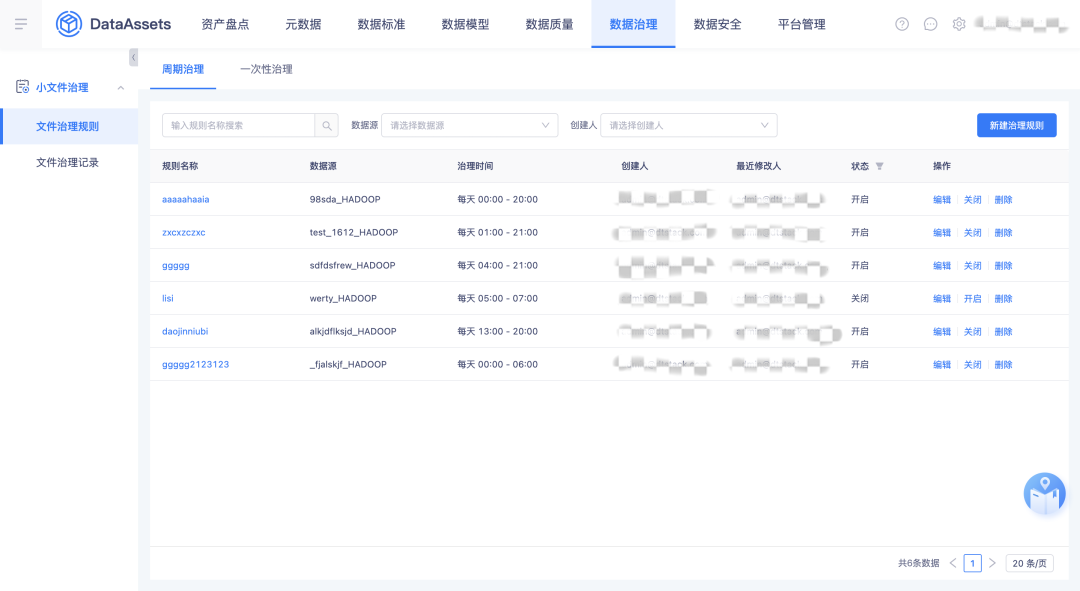
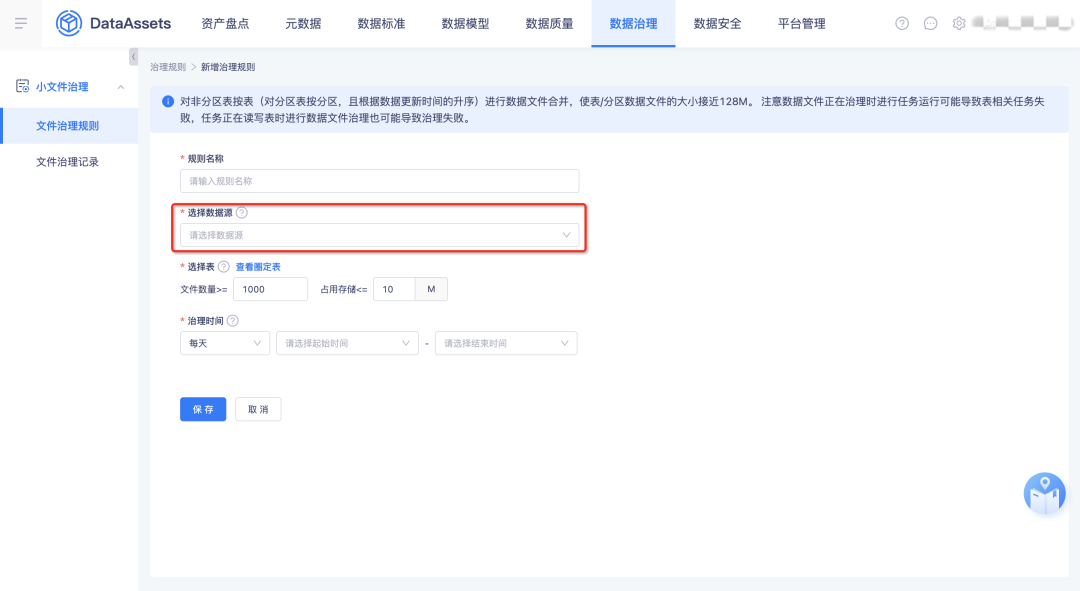
6.資料檔案治理
將離線側的資料檔案治理遷移到資產側的資料治理模塊并進行優化和兼容,治理規則包括周期治理和一次性治理,
7.資料檔案治理優化調整
? 周期治理「選擇專案」改為「選擇資料源」,治理范圍為可選的meta資料源,下拉框排序按照時間進行倒序;
? 一次性治理「選擇專案」改為「選擇資料源」,治理范圍為可選的meta資料源下的Hive表;
? 小檔案治理的時間如果超過3小時則治理失敗,超時的時間條件改為可配置項,可由組態檔支持,默認為3小時;
? 占用存盤的統計目標由一個磁區/表改為一個檔案,
8.元資料同步取消初始化流程
用戶痛點:V5.2合并改造,元資料同步與資料源管理功能拆分之前,原有邏輯是在引入資料源后會先進行初始化,初始化完成后會一次性拿到所有庫表名稱,進行元資料同步時再去查拿到的庫表資訊,這將占據較多的資源和存盤,并導致存在較多無用資料,如資產盤點加載資料慢等問題,
體驗優化說明:取消資料源引入之后的初始化流程,在元資料同步時實時查詢資料源內庫表資訊,
9.元資料中心耦合關系優化
? 增量SQL優化:目前元資料中心的定位基礎元資料中心,可以支持單獨部署,但是現在增量SQL無法支持;
? 產品權限優化:某個客戶有資產權限,在指標側呼叫元資料中心的資料模型沒問題,但是客戶如果沒有資產權限,呼叫元資料中心的資料模型就會提示沒有權限,
10.資料源插件優化
? 同步全部庫表引數,實際庫表發生變化,不傳引數,資料源插件實時去查庫表名稱;
? binlog關閉后重新開啟:腳本已停止,沒有被重新喚起,再次開啟時需要自動喚起,
11.功能優化
? 臟資料:管理默認存盤實效為90天,全域提示對應修改,臟資料管理范圍針對當前專案;
? 詞根匹配準確率提高:界面上增加的詞根、標準需要加入分詞器,解決了欄位中文名按照分詞去匹配,出現某些情況下無法匹配的問題,
客戶資料洞察平臺
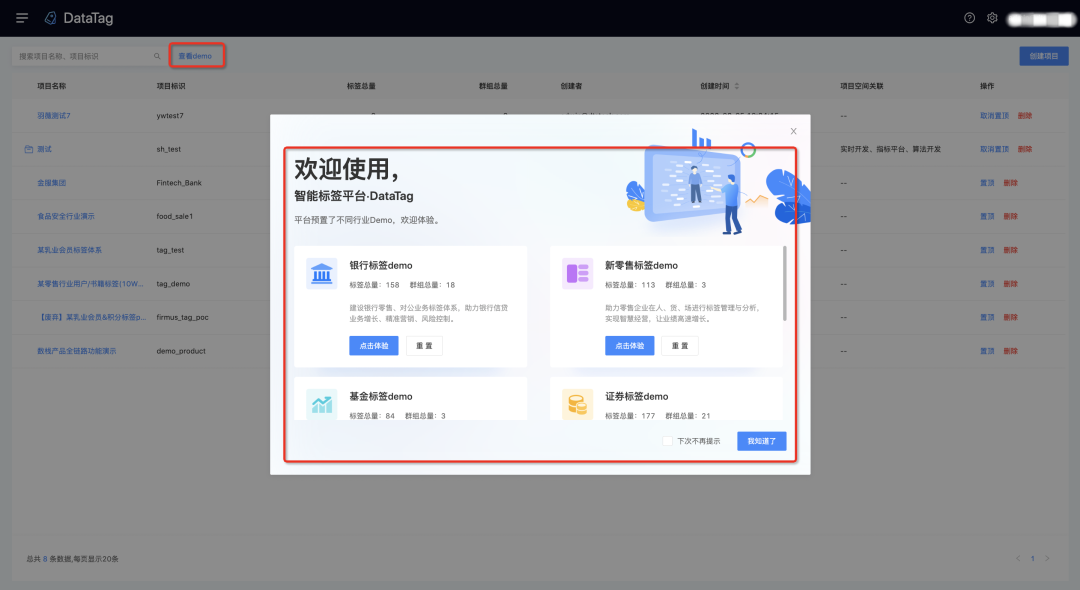
1.證券、銀行、保險標簽體系demo集成
進入標簽平臺,通過彈窗進行demo體驗,也可通過平臺首頁上方查看demo按鈕進入平臺體驗demo,
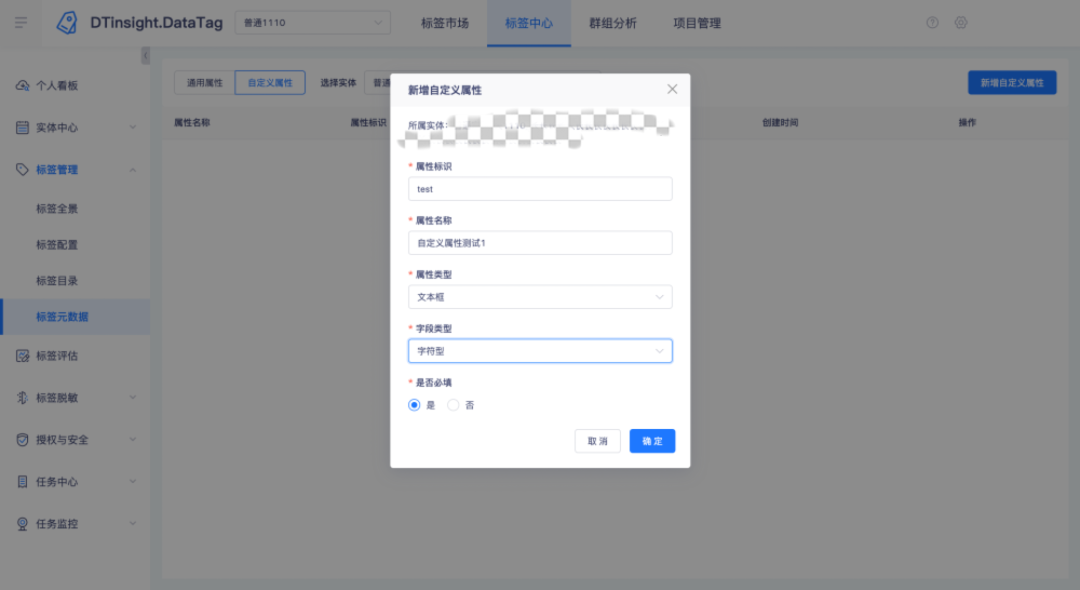
2.【標簽管理】支持配置自定義屬性
用戶痛點:目前標簽創建時的資訊是固定的,除了一些通用的屬性,不同行業客戶對標簽的元資料資訊各有不同,如銀行客戶有定義標簽金融安全等級的需求,但這個屬性不適配基金、零售客戶,所以要通過標簽自定義屬性來實作,
新增功能說明:
? 在「標簽元資料」頁面設定自定義屬性,并可在串列頁查看通用屬性和自定義屬性的元資料資訊;
? 通用屬性中增加標簽責任人、業務口徑、技術口徑欄位;
? 自定義的屬性用于后續創建標簽時進行屬性設定,
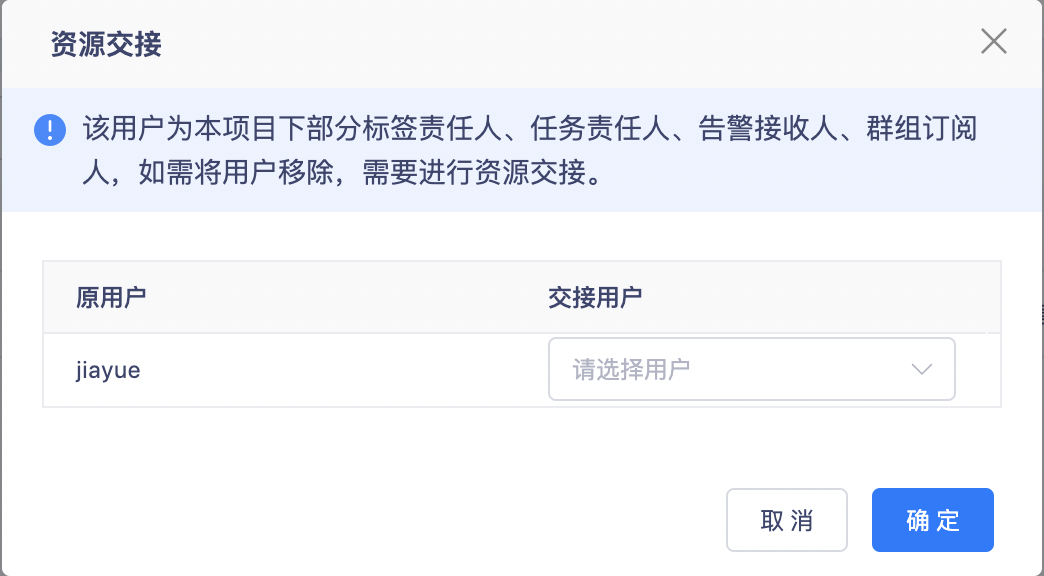
3.【專案管理】移除標簽責任人等時指定交接人
【專案管理】移除標簽責任人、任務責任人、告警接收人、群組訂閱人時指定交接人,
4.【專案管理】Hive表和HBase表支持自定義生命周期
? 支持對標簽大寬表進行生命周期設定,超期資料可全部洗掉,也可保留每個周期的特定時間的資料;
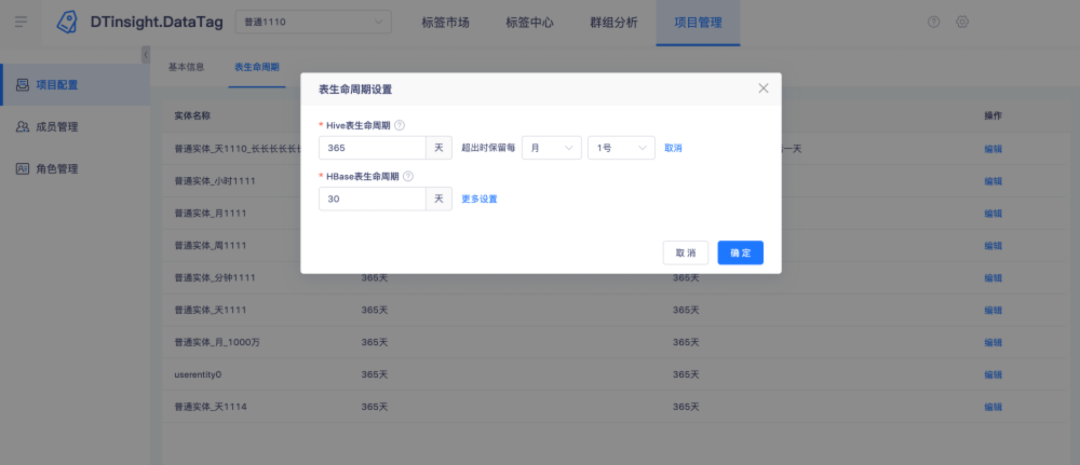
? 保存的標簽群組可設定生命周期,超期資料可全部洗掉,也可保留每個周期的特定時間的資料;
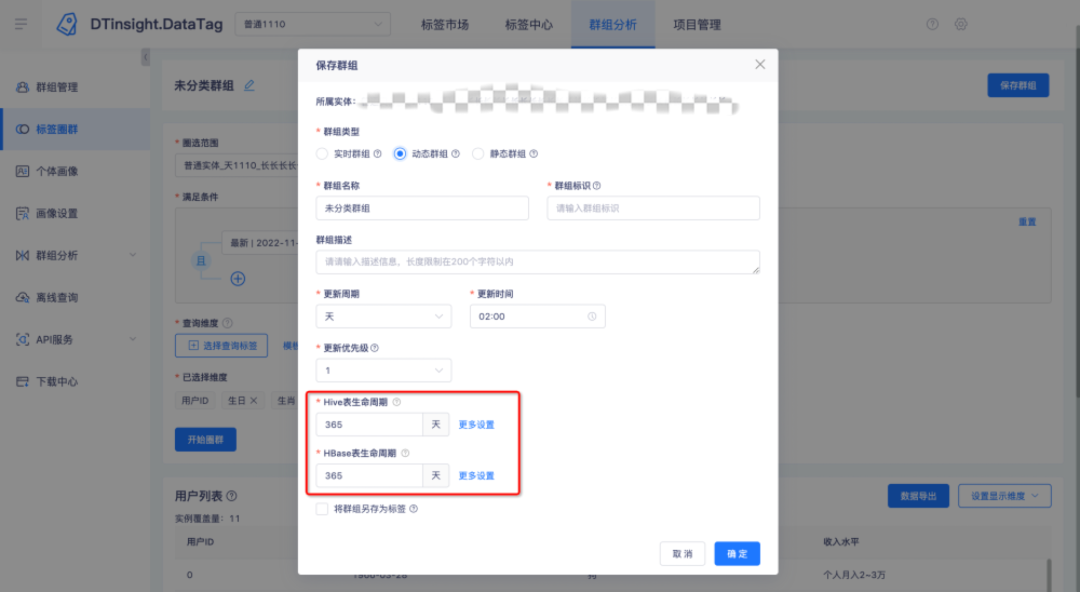
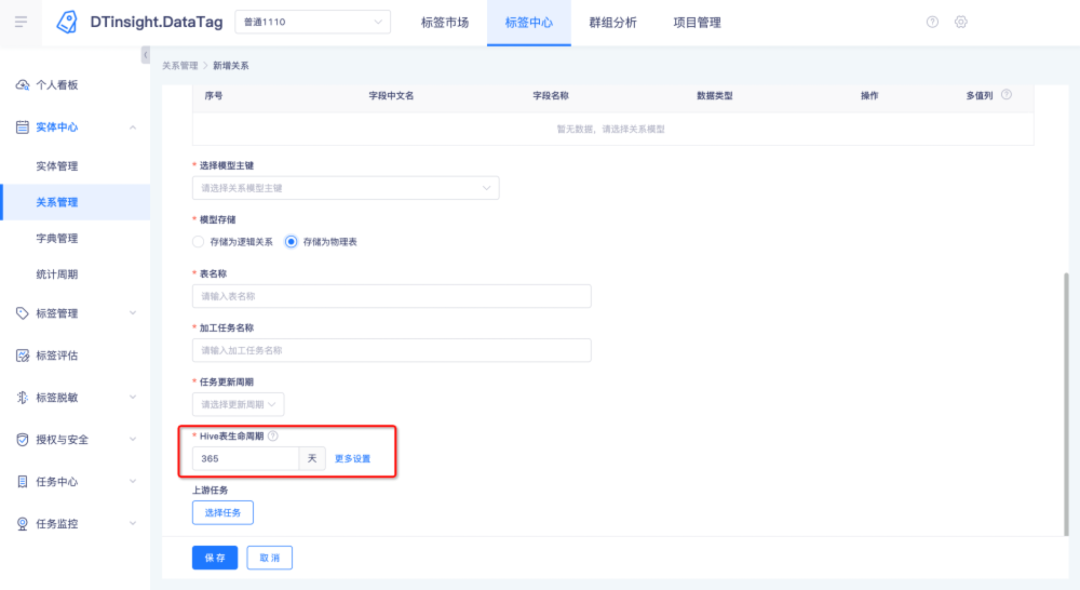
? 存盤為物理表的管理科設定生命周期,超期資料可全部洗掉,也可保留每個周期的特定時間的資料,
5.資料同步功能優化
? Rowkey預磁區功能優化:hbase表默認設定預磁區,且磁區數量 = 30,去除作業并發數對磁區計算產生的影響;
? 作業并發數優化:作業并發數輸入限制調整為1-100,滿足業務更多的資料同步效率需要;
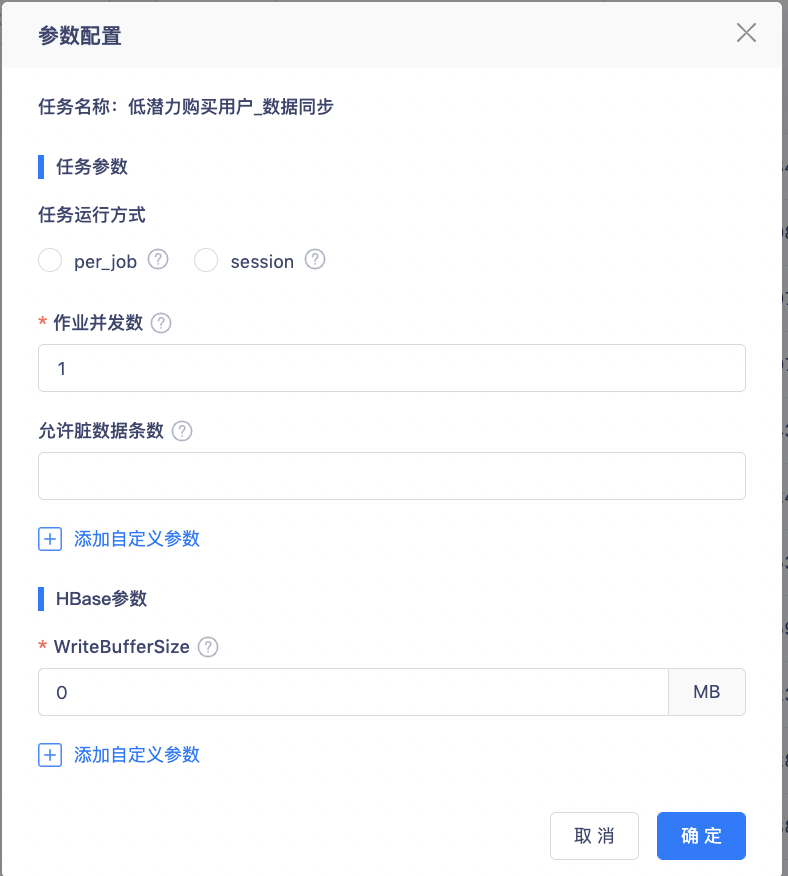
? 支持設定允許的臟資料條數:當產生的臟資料條數超過設定的閾值時,作業停止同步、置為失敗;設定為0或空時,表示不允許有臟資料出現,
6.【標簽API】支持不指定業務日期查詢標簽結果
用戶痛點:標簽API查詢資料的程序中,可能存在因資料同步任務尚未完成導致API無法查詢到指定的最新業務日期資料的情況,此時會造成業務阻塞,為不影響業務正常運行,需要對Hbase資料做降級備份處理,
體驗優化說明:hbase中將備份存盤一份同步成功的最新業務日期的最近一次同步成功資料,
API傳參時,業務日期調整為非必填項:
(1)指定業務日期,系統將回傳對應業務日期的資料;
(2)未指定業務日期,系統將回傳備份資料,
7.功能優化
SQL優化:數字開頭的schema讀取問題優化;
標簽目錄:標簽可以掛在父目錄和子目錄下;
API呼叫:增加pageNo欄位,
指標管理分析平臺
1.【指標管理】支持生命周期設定
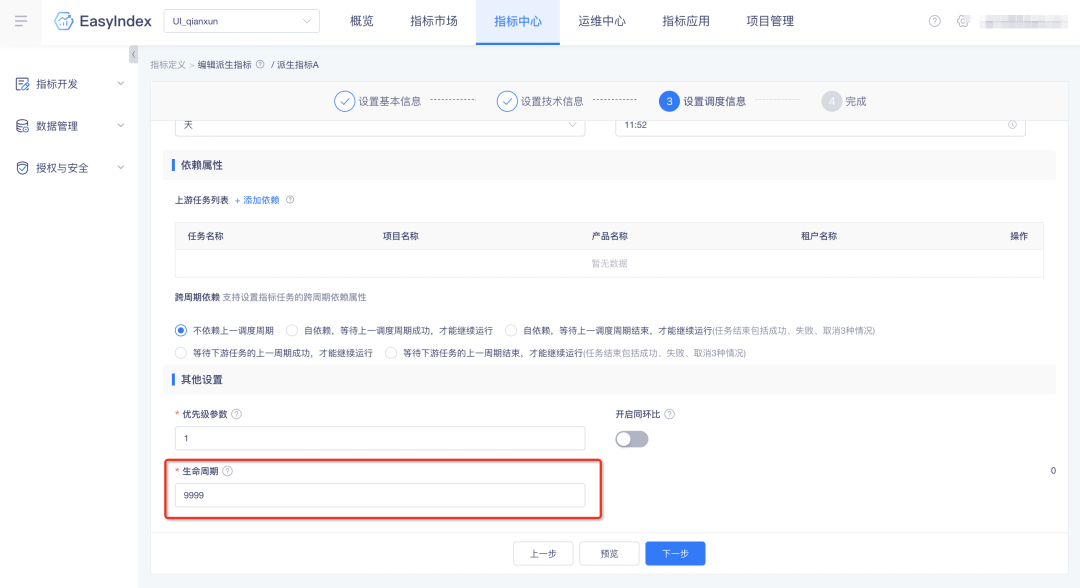
指標hive表支持生命周期設定;
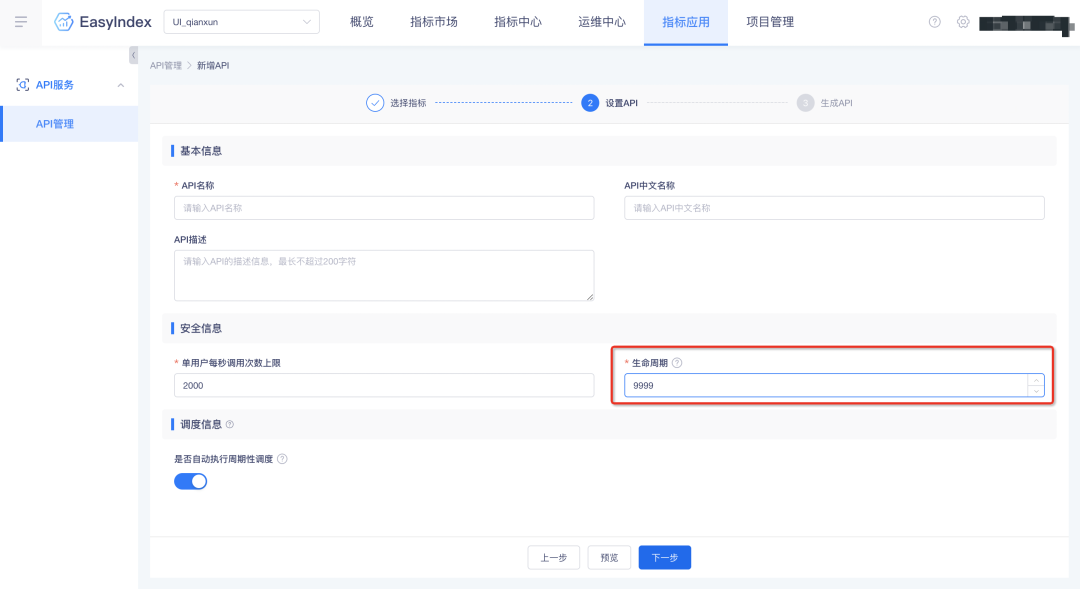
指標API支持生命周期設定,
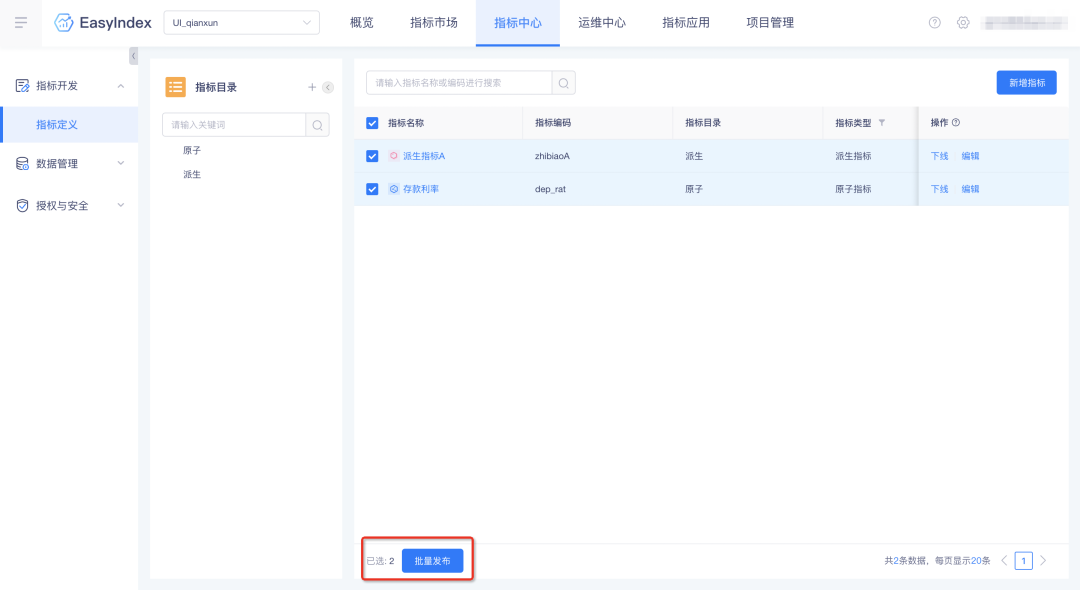
2.【指標管理】支持批量發布
支持批量發布未發布、已下線狀態的非自定義SQL指標,發布成功后,可在指標市場中查詢到此指標,
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/archive/2023/02/17/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/544239.html
標籤:其他
上一篇:mysql主從復制及分表分庫