
大資料平臺建設有其天生的復雜性,每一年都在推陳出新,從WareHouse、DataLake到LakeHouse,各種各樣的Batch、Stream、MPP、Machine Learning、Neural Network計算引擎,對應解決的場景和組合的方式非常個性化,建設程序會遇到包括技術層面、組織層面、方法論層面種種問題,包括存盤計算組件選型、離線實時湖倉架構方案設計以及場景化的性能分析,隨著時間推進也會出現持續的組織管理、資料和平臺運營、擴容、穩定性優化等問題,出現多個平臺共存,存盤和計算集群技術堆疊多樣化以及資料分散等常態化問題,面臨保留原架構還是推倒重來遷移到新的平臺的困擾,有沒有一套Architecture FrameWork能夠屏蔽底層技術和開發細節,Data Fabric、Data Mesh似乎是為了解決這個問題而生,從技術和方法論的角度探討如何影響大資料平臺的建設、資料工程和架構持續演進,
本文重點聚焦在相對比較容易混淆的Data Fabric和Data Mesh這兩個概念,嘗試說明這兩個概念要解決的問題、架構特征以及可行的技術堆疊,距離成熟還有哪些不足,以及圍繞兩個技術領域跟我們做的大資料服務之間的關系,
大資料組件多樣化,底層存盤、資料格式、計算表達決議、計算引擎(MR、DAG、MPP等不同的邏輯計劃&物理計劃生成和優化器)、調度、快取、血緣、資料集成在對應組件集合中可以看到很多選擇,大資料產品不存在銀彈,在滿足不同的場景通常需要將大資料的架構像積木一樣靈活的組合,
-
系統平臺 (Hadoop、CDH、HDP)
-
云平臺 (AWS、GCP、Microsoft Azure)
-
監控管理 (CM、Hue、Ambari、Dr.Elephant、Ganglia、Zabbix、Eagle、Prometheus)
-
檔案系統 (HDFS、GPFS、Ceph、GlusterFS、Swift 、BeeGFS、Alluxio、JindoFS)
-
資源調度 (K8S、YARN、Mesos、Standlone)
-
協調框架 (ZooKeeper 、Etcd、Consul)
-
資料存盤 (HBase、Cassandra、ScyllaDB 、MongoDB、Accumulo、Redis 、Ignite、Geode、CouchDB、Kudu)
-
行列存盤 (Parquet、ORC、Arrow、CarbonData、Avro)
-
資料湖 (IceBerg、Hudi、DeltaLake)
-
資料處理 (MaxCompute、Hive、MapReduce、Spark、Flink、Storm、Tez、Samza、Apex、Beam、Heron)
-
OLAP (Hologres、StarRocks、GreenPlum、Trino/Presto、Kylin、Impala、Druid、ElasticSearch、HAWQ、Lucene、Solr、 Phoenix)
-
資料采集 (Flume、Filebeat、Logstash、Chukwa)
-
資料交換 (Sqoop 、Kettle、DataX 、NiFi)
-
訊息系統 (Pulsar、Kafka、RocketMQ、ActiveMQ、RabbitMQ)
-
任務調度 (Azkaban、Oozie、Airflow、Contab、DolphinScheduler)
-
資料安全 (Ranger、Sentry、Atlas)
-
資料血緣 (OpenLineage、Egeria、Marquez、DataHub)
-
機器學習 (Pai、Mahout、MADlib、Spark ML、TensorFlow、Keras、MxNet)
平臺建設程序中面臨大資料選型(誰更快更強)、組合(誰做存盤誰做計算)與組織管理等問題:比如選什么 who vs who?怎么搭配 who on who?迭代演進還是推倒重來?資料分散是集中到一個團隊分析還是自治,歷史原因可能多個組合共存,常見技術堆疊組合:
-
Iceberg+S3+Starrocks+Flink
-
HDFS+Alluxio+Spark+Trino
-
HDFS+Hive+GreenPlum
-
Minio+LakeFS+Marquez+Trino
舉個具體的例子,在存盤和計算的組合上,根據研發的習慣可以采用Hive on Spark,也可以選擇Spark on hive(依賴hive metastore),表現為上層誰作為查詢語言的表達和決議優化,誰作為執行引擎或者catalog存盤,根據團隊的使用習慣以及歷史發展甚至會有多個集群、多種版本共存,資料在平臺之間通過集成或者計算框架的Source/Sink IO直接讀寫,中間經歷各種序列化、反序列化的程序,我們所服務的某互聯網搬歷史就遺留統計、演算法、廣告三個集群,分別采用了Azkaban、Crontab、Oozie作為調度框架,多個集群資料的存盤和計算之間血緣隱含復雜的依賴關系,缺少統一的產品或者方法再繼續運營,客戶最終選擇重構并遷移到阿里大資料平臺架構,
從過去大資料服務程序我們看到各行業大資料平臺的現狀,大體量的客戶由于業務場景差異、組織變更、長期演進導致的架構不統一、資料標準不統一,多套架構共存,資料分布存在成為常態,是否有更先進的技識訓者方法論提高資料分析的效率,是在當前基礎上構建統一的管控平臺還是推翻重建統一技術堆疊,也許沒有一個最終的答案,在這個背景下我們繼續討論data fabric與data mesh的概念,對于業務模式簡單、小體量、集中式單體資料平臺能解決的場景不在討論范圍內,
Data Fabric/Data Mesh解決的問題
-
技術問題:大資料建設架構層出不窮,一直有“Next-Generation”的新產品與組件出現,持續建設導致技術架構多樣化,資料存算分散成為常態,(比如某運營商客戶同時運維N個小的業務域集群,總部和各省區域集群,資料處理ETL程序冗長,管理運維成本高)
-
組織問題:單一資料團隊架構帶來的資料工程需求壓力,持續積累汪洋大海一樣的資料目錄帶來高額的分析探查成本,缺少統一的血緣和業務知識導致的資料分析運營困難,而資料價值的挖掘存在知識壁壘,資料分析需求由單一資料部門來回應成為瓶頸,溝通成本高,表面在中臺內開發但依然垂直建設煙囪的局面,未來面臨一次又一次的重構,
“A data fabric and a data mesh both provide an architecture to access data across multiple technologies and platforms, but a data fabric is technology-centric, while a data mesh focuses on organizational change”
簡單說,二者都是為了解決跨技術堆疊和平臺的資料接入和分析問題,讓資料還保留在原來的地方,而不是集中到一個平臺或者領域,Data fabric是以技術為中心,data mesh聚焦于方法論、組織協同上的變化,
概念
“Conceptually, a big data fabric is essentially a metadata-driven way of connecting a disparate collection of data tools that address key pain points in big data projects in a cohesive and self-service manner. Specifically, data fabric solutions deliver capabilities in the areas of data access, discovery, transformation, integration, security, governance, lineage, and orchestration. ”
-
定位:解決分散的資料平臺,從技術和產品角度打造元資料驅動的統一的Virtual Layer,屏蔽底層各種資料集成、湖、倉、MPP資料庫的差異,資料的讀寫和計算在各種底層的Warehouse中往來,在統一的自服務平臺中編排和計算,
-
技術要素:資料集成、服務集成、統一的語意(跨引擎)、主動元資料、知識圖譜(元資料圖結構)、智能資料目錄,主動適配各種大資料產品,避免廢棄重建,增加了一個虛擬層,在虛擬層中自動進行必要的ETL、計算下推、資料目錄智能推薦、資料虛擬化、聯邦計算等程序,使開發人員和資料分析對于底層差異無感,
-
不涉及組織變化:資料分析可以由維護資料平臺的人來統一管理和保障也可以跨組織協同,對組織架構無干涉,
Tech stack
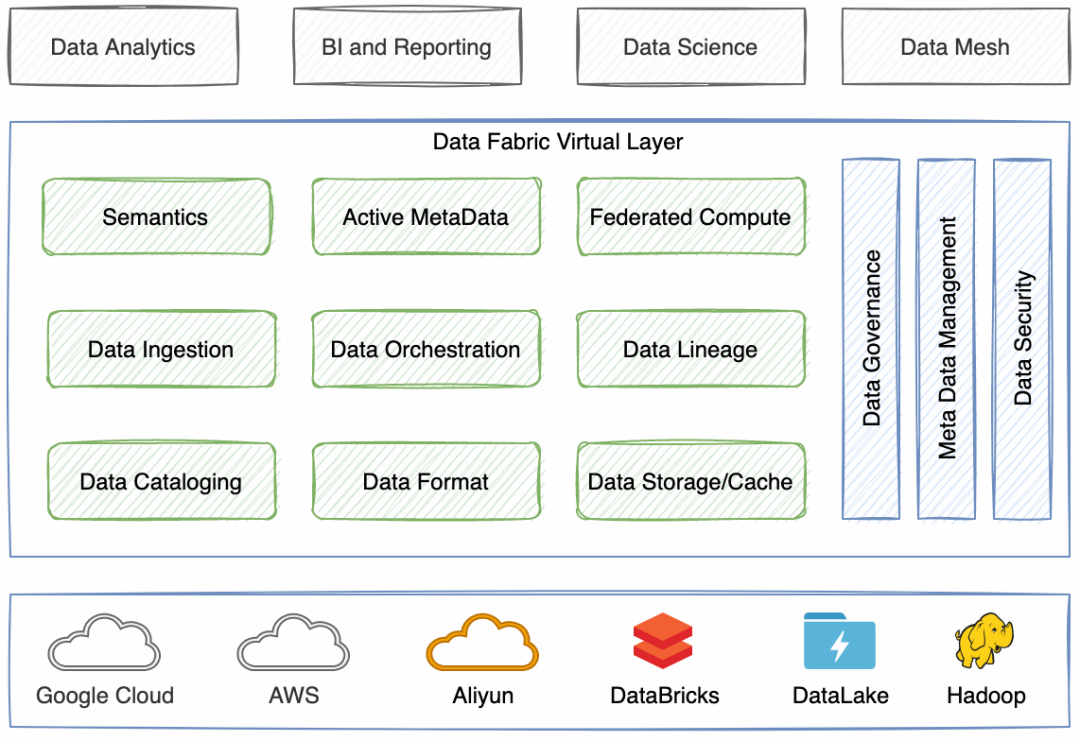
Data Fabric Architecture
目前data fabric更多的是一種Architecture,并不是某一個產品,需要組合多種技術達到類似的效果,逐步統一各個技術要素,收集跨平臺的元資料、資料目錄并構建統一的編排和語意層,基于統一的元資料和底層所納管的各個引擎的特點實作計算編排、下推,聯動多個產品實作資料分析,目前市面上有也有類似的商業化產品,部分實作統一的catalog、storage、etl等能力,支持全域資料的即席訪問和聯合分析,
概念
“In short, while the data fabric seeks to build a single, virtual management layer atop distributed data, the data mesh encourages distributed groups of teams to manage data as they see fit, albeit with some common governance provisions.”
Data fabric目標是在異構分布式資料平臺基礎上建立單體統一的虛擬資料管理層,data mesh鼓勵分布式的組織去管理自己的資料,領域內自倍訓,基于data product對外提供服務,
“So instead of building a complex set of ETL pipelines to move and transform data to specialized repositories where the various communities can analyze it, the data is retained in roughly its original form, and a series of domain-specific teams take ownership of that data as they shape the data into a product.”
可以認為Data Mesh就是資料分析領域的“微服務”,在應用開發對應微服務的ServiceMesh理念有共同點,解決單體應用開發、部署、擴容等問題,微服務也為不同的服務節點所選擇的語言提供一定的靈活性,應用之間通過API來通信,實作Service Mesh服務編排需要的技術組件包括可選的Service Discovery、API Gateway、Spring Framework、Docker、SideCar等,Data Mesh也是一種分布式大資料分析方法論,避免開發復雜的ETL將資料全量同步到某個資料倉庫,而是根據需求選擇不同的self-serve大資料技術與其場景匹配,旨在提供更靈活的自治的資料分析能力,讓資料保留原始形態,提高分析實效性需求的回應速率,在需要Cross-Domain分析的情況下將資料編排起來,最大化利用原Data Product的價值,基于聯合計算聯合分析,或者通過編排將資料在各個域的分析驅動起來,
-
面向領域的分布式資料權責劃分和架構設計;
-
資料作為產品;Data as Product;
-
自服務的平臺技術架構;
-
通過資料驅動、領域驅動,不同的資料分析團隊聚焦在自身的Domain建設中,發布自己的資料產品,其建設程序可以選擇非單一架構的數倉、MPP、資料湖或者資料庫引擎,資料以服務或者表的形式對外提供,對于Cross-Domain的資料分析依然依賴聯合查詢計算等技術,
治理級別
當資料足夠復雜,系統中有幾十萬張表存在的時候,理想中的中臺架構會面臨局限,沒有人能說清楚某個表的價值和口徑的準確性,為了資料的準確性不得不從基礎資料以煙囪的形式重新計算的案例比比皆是,比如某客戶出現過新中間層大規模重構程序,老中間層占用大量存盤計算資源,但由于人員離職業務口徑和檔案準確性問題導致中間層已經錯綜復雜無法繼續維護,在真實世界里,當復雜的體系到達一定規模區域會出現小世界模型,小世界通過主干進行連接,可以形象的類比Data mesh的每個Domain都是一個關聯度很高的小世界模型,大部分的資料保留在自己的領域中,對于資料的理解、探查更直接,
Data mesh的概念是為了減少業務知識的壁壘,理論上生產資料業務相關的開發人員對于自己的需求和資料理解的更準確,將資料通過復雜的ETL集中到中央存盤,將元資料知識傳遞給資料工程技術人員,等待與不那么可靠的數倉CDM資料聯合進行分析和反饋,不管是從資料鏈路還是溝通鏈路都不夠效率,通過data mesh將資料分析權責像微服務一樣分配到不同的團隊,自主分析減少業務知識傳遞的壁壘,同時提高技術選型的靈活度,比如一個團隊用湖倉、一個用MPP,或者直接用的就是某個Data Fabric單體平臺,
各個團隊或者Domain不一定達到同樣的Level,data mesh的領域分析級別分級如下:
-
Level 0: No Data Analytics
-
Level 1: Operational Database Queries
-
Level 2: Analyze Own Data
-
Level 3: Analyze Cross-domain Data
-
Level 4: Publish Data as a Product
Tech stack
底層所依賴的Self-serve Data Platform可以根據需求自由組合,也可以選擇某種Data Fabric的產品,常見的自服務大資料技術堆疊舉例:
-
DataWorks and MaxCompute
-
AWS S3 and Athena
-
Azure Synapse Analytics
-
dbt and Snowflake
-
Databricks
-
MinIO and Trino and LakeFS
二者的相同與不同
-
共同:Self-Serve Data Platform, No ETL,立足于解決資料現狀分散的問題,是一種架構框架,而不是某款產品,
-
不同:Mesh偏向方法論,分布式的敏捷資料開發,類比微服務的Service Mesh,Fabric偏向構建虛擬的單體技術架構,
Data Mesh 是微服務與單體架構的區別,從方法論層面DataMesh與資料中臺的對比,治理程序是自下而上,在方法論層面與資料中臺可以互補,“ top-down style of management that organizations have tried to impose on data lakes has been a failure. The data mesh tries to re-imagine that ownership structure in a bottoms-up manner”
Data Fabric是與WareHouse、DataLake、LakeHouse等技術類似的概念,可以認為是第X代的DataPlatform,一種新的magic,Data Fabric側重技術,通過各種組件構建統一元資料、聯邦計算引擎、智能的資料編排消費探查工具實作面向業務人員的統一開發和管控平臺,資料也是分散在各個存盤計算引擎,從技術上也可以作為支撐Data Mesh的一種Self serve資料平臺底座,兩者并不沖突,體現方法論和技術的結合,
Data Mesh可以建設在Fabric單體虛擬層之上,底座在技術上解決元資料、資料目錄、聯邦計算、湖倉等一體化開發運營能力,上層基于方法論實作資料的服務化、跨域的編排與分析,在沒有比較完美的Data Fabric資料產品之前,可以通過現有的資料平臺組合實作Mesh架構落地效果,這種情況下Data Mesh也需要額外建設跨域的全鏈路大資料的觀測、元資料采集、統一服務目錄、DataProduct的消費管理能力以及跨域聯合計算的技術能力,但主要的業務資料分析計算程序不需要侵入到每個Domain的資料平臺之中,資料依然主要在自己的Self-Serve Data Platform計算,各領域保持自治,上層進行相對輕量級的聚合分析,
什么情況應該避免用DataMesh
-
-
高內聚的單體平臺(比如SAP、DataPhin)滿足需求
-
實效性要求高(網格化的資料通過CDC類實時的集成和計算也可以保證低延時)
Gartner怎么看
“Data mesh is obsolete before plateau,data fabric 還有5-10年才能成熟”
二者依賴的基礎技術需要幾年時間才能成熟,相比起來Data Mesh出現時間較短,業界也有出現Data Mesh碰瓷Data Fabric的說法,二者的理念不同也會造成一些沖突,我們能認為二者可以在技術和方法論層面進行互補,
至此二者的概念已經比較明確,我們從技術上分析下實作Fabirc或者Mesh的落地還需要哪些能力,相對于架構概念和方法論,實際的支撐的資料產品和技術實作更重要,對于微服務而言,Spring、Docker容器技術已經成為Java微服務框架的事實標準,而在大資料領域完美的實作Data fabric 理論上還比較遙遠,
Data Fabric架構旨在異構的平臺之上提供相對統一的資料分析能力,要實作這個目標需要將各種大資料分析程序中的關鍵要素進行適配和統一,屏蔽掉底層引擎的各種細節,我們將實作統一的Virtual Layer的技術要素羅列如下:
-
統一的資料集成、服務集成
-
統一的語意表達
-
主動元資料+知識圖譜(元資料圖結構、血緣),基于元資料的推薦等擴展能力
-
統一資料目錄、統一的Table行列存盤結構、統一快取
-
跨域聯邦計算、自動計算下推,
實作以上技術要素打造統一的虛擬層,為用戶提供元資料驅動的資料推薦、計算下推和分散在各個存算引擎的資料資產的管理能力,讓資料分析和架構設計更靈活,把復雜留給自己,簡單留給用戶,本文我們選擇Catalogue、Data Format、Cache、DataLineage、統一開發和語意幾個方面看下當前大資料領域技術方案現狀,要實作完美的“統一”還差哪些作業,
Catalogue
在大資料產品中,資料目錄的組織通常分為三成,這里用比較通用的Catalog-Database-Table進行展示,類比到MaxCompute(Project-Schema-Table),不同計算引擎內部的定義不一樣,比如Hive 沒有Catalog這一層,只有Database(Schema)-Table兩級,實作統一的Catalogue,需要有一個標準層將個性化資料目錄的結構進行轉換,轉換成某個標準化的統一的Catalogue Virtual Layer,通常三層資料目錄架構的實作包括以下細節:
通常每個引擎內部都有自己的Catalog實作比如Spark有自己的SparkCatalog,StarRocks有自己的StarRocksCatalog,支撐其計算引擎的邏輯計劃、物理計劃生成和優化,其資料結構的細節會有差異,通常包括以下配置:
-
Impl:具體Catalog的實作類,影響URL和IO的配置
-
Url: Catalog的存盤地址,可以是S3、HDFS,根據Impl的定義有差異
-
IO: Catalog具體的IO讀寫實作,比如S3的Catalog存盤既可以選擇用Hadoop-S3去讀寫,也可以直接使用S3FileIO Client讀寫,或者通過Restful API
-
Warehouse:實際資料的存盤地址,可以是HDFS、S3或其他分布式存盤
如果要實作跨引擎的Catalog通用,比如讓Spark識別Hive MetaStore里邊的元資料,需要在Spark的運行時加載HiveCatalog的實作遠程讀寫HMS并轉換成Spark內部的計算引擎可以使用的元資料,我們以目前比較流行的Data Lake舉例,Iceberg對各個引擎的適配比較好,統一Table Schema與Catalog的讀寫屏蔽一些引擎的差異,下圖展示我們常見的一些數倉、資料湖產品元資料目錄的實作,簡單示意Iceberg是怎么實作的,
Iceberg已經實作了多種Catalog存盤的兼容,支持多種計算引擎使用Iceberg的Catalog來建立External Table,這個程序需要定制化將Iceberg的Catalog轉換成其引擎內部支持的Catalog的具體Implement,也就是上圖所依賴的iceberg-spark-runtime-3.3_2.12:1.1.0.jar,后邊的一串數字3.3_2.12:1.1.0 表示適配基于Scala 2.12編譯的Spark 3.3版本,冒號后邊的1.1.0代表IceBerg的版本,不同版本的計算引擎、湖之間的適配不夸張的說是個笛卡爾積的程序,每發行一個新的runtime要適配各種引擎的各種版本,不小心用錯了3.2版本的Spark的runtime jar,有可能在3.3集群上就會出各種Class Not Found的錯誤,
@Override
public Database getDB(String dbName) throws InterruptedException, TException {
org.apache.hadoop.hive.metastore.api.Database db = clients.run(client -> client.getDatabase(dbName));
if (db == null || db.getName() == null) {
throw new TException("Hive db " + dbName + " doesn't exist");
}
return convertToSRDatabase(dbName);
}
以IcebergHiveCatalog里邊的一個方法舉例來說要想實作StarRocks與IceBerg的聯通,依賴個性化的適配邏輯導致適配本身是個點對點的程序,StarRocks目前支持HiveMetaStore以及Custom MetaData,IcebergHiveCatalog支持StartRocks讀取HMS里邊的Database&Table資訊并轉換為StartRocks Catalog的程序,以getDB為例,hms client讀取db資訊并convertToSRDatabase,適配的這個Class需要耦合源端、目標端的Catalog的轉換邏輯,根據具體Catalog的存盤的IO的讀寫程序,相當于一個三方的樞紐,而每種引擎的集成都類似,需要定制化一個IcebergXxxxCatalog,包括Flink、Spark、Hive等等引擎,涉及到Catalog的轉換與其物理存盤的讀寫,在大量的適配程序中元資料、存盤、計算形成了一種錯綜復雜的網路,且當某個引擎增加了新的特性適配層沒有跟上也會影響整體大資料架構的升級,統一和效率之間就存在了矛盾,
Iceberg以及各個引擎的合作已經實作了非常多的引擎和Catalog存盤之間點對點的適配,也是在其自身價值得到證實的情況下持續迭代、開源社區推廣運營的結果,要實作Data Fabric需要獨立實作一個更上層的統一的Catalogue層,兼容IceBerg、Hudi、DeltaLake等不同的資料湖格式,僅僅是Catalog的適配就需要很大的作業量,且很有可能更新跟不上各個引擎或者存盤百花齊放的演進速度,
實作統一的Virtual Layer,本質上是執行效率、學習成本和通用性的沖突和平衡,如何找到一個演進的動態平衡點,而目前可行的存算都是點對點集成方式,統一集成對于虛擬層來說成本高,新Feature兼容壓力大,需要找到一個演進的平衡點,
Data Format
除Catalog外,Data Fabric實作所需要的每個技術要素都需要類似的架構出現,以下例子從簡,從圖中所展示的連接關系可以發現類似的規律,比如Apache Arrow作為一種Columnar memory format 支持不同的引擎比如spark、impala里邊的dataframe計算抽象,提高計算效率,優化資料在不同的計算引擎中抽象和轉換的計算效率,統一資料格式,優化切換引擎中間結果落盤程序中序列化和反序列化的處理效率,
構建Data Fabric的資料平臺同樣需要有一種資料格式抽象解決存算分離架構下資料的存盤格式問題,當底層引擎有Parquet、CarbonData等不同的檔案格式,上層構建的聯合計算引擎需要能夠兼容不同的檔案格式,Data Format這一層的抽象必不可少,在跨引擎的計算程序中減少不必要的序列化,
Data Lineage | Data Discovery
資料血緣是大資料分析的必備組件,大多數的計算引擎都有其內部的元資料和DAG管理能力,當資料鏈路存在跨引擎或者平臺的依賴,需要將上下游的血緣聚合到統一的血緣中心,形成完整的資料鏈路全景,提高問題溯源分析和影響分析,有些大資料組件的的元資料和血緣集成在自身Catalog能力,有些大資料產品只支持基礎的資料目錄和Table Schema,還有一些支持到Table Lineage&Column Lineage,構建跨平臺的資料血緣我們需要有一個第三方的組件建立血緣標準,支持將資料的血緣從其自身的元資料存盤、任務提交和運行的程序匯總,轉換成通用的血緣Model,并將跨平臺的血緣資訊整合為血緣全景,支持跨引擎的代碼提示或者計算優化,
Data Lineage Architecture
資料血緣目前有非常多的第三方組件,在構建大資料平臺程序中選擇較多,也會造成點對點集成的情況,我們可以選擇其一作為統一的后端,依賴各種采集、決議和標準化技術將分散在引擎和元資料中的任務、表和欄位之間的關系固化到統一的后端服務,我們以Open Lineage和DataHub為例,OpenLineage通過Wrapper、Proxy或者javaagent將運行時提交任務程序的事件資訊采集到統一的血緣中心,實作表、任務之間的血緣存盤和展示,目前已經開始支持Column LIneage,
-
Cli Wrapper:對于Python開發的客戶端,代碼可以重新封裝,替換原默認的命令列腳本,在提交程序決議任務執行的代碼,分析血緣并轉發給后端;
-
java agent:適用于Java開發的submit job 程序,侵入Jvm加載位元組碼的程序,分析代碼中的血緣并轉發給LIneage Backend遠程地址;
-
event listener:對于支持Extra Listener擴展的計算框架,提供定制化的Listener配置,運行時程序中手機元資料資訊轉發給后端;
第三代的元資料中心DataHub支持流式的元資料日志協議,類似于CDC的MCP(Metadata Change Proposal)協議,通過source插件ingest并extract到內部的元資料存盤,根據元資料來源的特點也可以支持column-lineage以及自定義的元資料分析能力,比如基于databrick的unity catalog從元資料中獲取血緣,對于不支持血緣的比如hive就只能查詢到table、column的schema資訊以及資料統計資訊,類似于open lineage作為一個后端去存盤各種元資料,DataHub兼容的源端種類更多,2022年8月份的新Feature開始支持Column LIneage,支持pull-based/push-bashed元資料集成方式,做為大資料平臺之外的第三方元資料中心,通過實時的流式的元資料變更以及元資料聯邦查詢能力,訂閱源端元資料的變更事件提高元資料的實效性,保障實時可用,下游應用也可以訂閱DataHub元資料的變更來進行比如查詢優化、鏈路監測的能力,
統一的開發IDE與語意
以DBT為例,上文提到過Data Mesh可以通過dbt+snowflake的形式構建,dbt作為統一的開發管理層,實作類似軟體開發程序中的software enginerring、package management、macros、hooks 以及通過incremental materialization實作的 DAG level optimization能力,目標是提高代碼模塊的復用性,通過select語意以及ref 參考構建module的定義和關聯關系,compile生成目標warehouse sql提交給引擎運行,但dbt開發moddular data model使用的SQL并不是一種統一的表達形式,而是所選擇的warehouse自身的dialect,資料的處理不會離開sql運行的存算引擎,
dbt sn't actually Magic. your data is not processed outside of your warehouse.
dbt實作了snowflake、redshift、bigquery等平臺的adapter,作用于macros和compile的程序,資料的計算完全在底層引擎內執行,dbt控制代碼的復用、執行程序,而支持聯合計算的比如trino或者StarRocks提供了統一的SQL支持跨多種資料源和計算引擎的查詢,但Trino實作的是各種資料源的connector,資料會離開原來的位置在上層引擎進行,二者有很大的區別,
還有Semantics、Orchestration、Active MetaData、FederatedCompute等等
通過上文的catalog、format、lineage、sql的表達幾種技術要素方案的討論,可以看到這些圖長得都差不多,中間有一層抽象成統一的XX,實作Fabric的架構前提要把所有的點對點的集成都屏蔽掉,可以依賴以上的一些產品進行組合、擴展集成,拼裝成一層虛擬的Virtual Layer,而目前各種適配和統一還只存在于技術要素區域,宏觀上大資料產品的異構還是常態,為了追求計算效率計算引擎通常與存盤會避免通過中間層的額外做一層轉換,更可行的是在某個引擎作為基準來擴展支持更廣泛的資料源、資料格式和元資料,屏蔽底層其他種類的WareHouse或者資料湖的差異,現在比較流行的湖倉一體概念,可以看做是輕量化的Fabric實作,實作Catalog層面的統一,比如MaxCompute可以直接通過DLF或者對Hive MS的適配實作對外部資料湖、數倉的聯合計算,
Data Fabric目標是打造一個完整的虛擬層,創造一種新的魔法,基于同一的各種抽象開展資料工程,但這些統一的適配作業需要大量的作業,目前還沒有統一的語意的抽象能夠兼容所有的引擎,一些比較個性化的優化器、hint、存盤格式和壓縮演算法、物化與虛擬化的技術都會導致通用表達無法下推到底層的引擎,專業性與通用性一定是沖突的,需要進行兩層抽象,過度抽象可能會導致輪子以低功率運行,無法發揮底層引擎的優勢,
從可行性角度,Fabric可以在有限的存、算、調度組件上可行,聯合Data Mesh實作最終的架構效果,Trino 2022 Summit也提到“Elevating Data Fabric to Data Mesh: solving data needs in hybrid data lakes”,通過trino跨引擎、跨實體組合出Fabric的架構特點,并向Data Mesh的演進,未來支撐Fabric的組件也會持續出現,當前階段各資料平臺更多聚焦打造自己的核心能力,并兼顧對于外部優秀的元資料、調度、存盤等系統的適配,體現存算分離的基礎上讓自己的生存空間更大,同時標準化自己的擴展能力,開放Adapter的邏輯給社區,持續豐富其對外的各種適配,
實作Data Mesh相對來說要更靈活一些,不強求在統一的技術堆疊進行資料工程開發,資料在原地的同時,技術堆疊以及開發的習慣可以保持自治,二者組合在跨資料湖的集群實體上增加新的相對獨立的統一元資料中心和聯邦計算能力,讓DataProduct之間以類似微服務的API的形式流轉起來,支撐跨域的資料應用,
最后簡單說下這兩個概念對我們大資料技術服務的影響,回顧以上的概念和技術分析,Data Fabric和Data Mesh從框架理念上解決資料和組件分散的問題,在企業資訊化轉型中我們通常會遇到一些并非是從零開始構建大資料平臺的客戶,希望能夠上到公共云或者混合云阿里側的大資料產品,構建一套新的大資料平臺的同時要考慮現有的資料和任務如何平滑快速的遷移,在進行擴容和升級的時候,如何規劃架構的設計實作平滑的演進,多種架構如何共存,以及客戶已有的資料如何快速敏捷的支撐上層的應用建設,將資料匯聚到單體中臺還是靈活的Data Mesh結構,核心就是解決大資料平臺從A到B、AB共存以及長期的資料生產運營問題,
為了支持異構大資料組件之間的轉換和架構演進設計,我們在服務的程序中會參考DataFabric的技術思想沉淀技術組件和各種adapter,彌補平臺與平臺、平臺與用戶之間的GAP,持續打造標準的元資料、調度、集成抽象以及全鏈路的大資料可觀測的標準抽象,在此基礎上進行架構演進和資料生產運營,在Data Fabric的一些技術要素點上進行增強,也結合data mesh的方法論結合業務場景做一些架構設計:
-
大資料異構平臺的遷移(解決從A到B的問題):幫助客戶實作快速低成本資料、任務和調度統一遷移到云上阿里云大資料產品,搬站服務和工具的一些設計與輕量級的Data fabric關聯較大,比如資料遷移依賴MaxCompute的湖倉一體(Inside Hadoop方案)加速客戶的資料遷移程序,內部抽象統一的血緣分析和調度的標準化轉換屏蔽了客戶各種Script、調度DAG的差異,
-
湖倉、流批架構規劃服務(解決A與B共存演進問題):部分客戶提到希望可以提供持續演進的規劃,中間態多產品共存,比如通過擴展MaxCompute的標準插件實作與開源大資料引擎的聯合分析,或者基于HDFS聯邦新老集群共存,在在某些架構咨詢專案,設計統一的資料湖元資料中心組件實作存盤計算結構平滑擴容,
-
資料生產運營優化(資料價值與生產平衡問題):結合data fabric架構思想設計統一的全鏈路的資料血緣幫助客戶做全面的存盤、槽位、Quota等資源分析和優化,對于客戶當前已經有多平臺共存、云邊端協同等場景的大資料架構設計場景,基于data mesh的理論框架,實作資料敏捷分析、快速體現資料業務化價值,
搬站作業臺
大資料生產運營優化
大資料平臺運營程序中客戶的存盤和計算水位長期處于高位,資料集成等任務出現堆積,通過對大資料平臺的元資料、資料血緣、存盤的分布進行綜合分析,實作全鏈路的生產經營優化,結合Data Fabric架構設計伴生大資料平臺的獨立的第三方運營工具,抽象統一的元資料采集、圖譜關系構建,上下游影響分析,為運營優化技術服務提供資料與決策支撐,
從業務場景我們在能源與制造一些領域探索Data Mesh的方法論,生產資料的程序中通常在多個業務域都有自己的采集、處理和分析的需求,內部通常也有小規模的開源或者自建的大資料產品,同時各領域的資料需要協同計算,演算法團隊依賴工控的資料進行模型訓練,預測的結果以服務的形式對管控提供服務,結合Data Mesh的架構設計,將不同領域資料的生產程序的輸入輸出聯動起來,合理設計生產資料和分析資料的處理鏈路的邊界,資料的生產、基礎的計算分析和服務化保留在多個Domain中,通過MaxCompute與OSS外表結合簡化各個業務輸出資料之間的聯合分析,通過資料湖共享各個分析系統的資料產品,中間層設計相對簡化,減少由于鏈路長帶來的資料一致性和資料權責問題,
參考資料:
https://www.datamesh-architecture.com/
https://www.datanami.com/2021/10/25/data-mesh-vs-data-fabric-understanding-the-differences/
https://www.starrocks.io/
https://iceberg.apache.org/
https://openlineage.io/
https://www.gartner.com/doc/reprints?id=1-2B6AXOGW&ct=220920&st=sb
https://arrow.apache.org/
https://www.starrocks.io/
https://www.getdbt.com/
https://datahubproject.io/
作者| 王磊(汐衍)
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/DataFabric_VS_DataMesh.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/545257.html
標籤:其他
上一篇:Oracle中表欄位加中文注釋,應該怎么寫呢?
下一篇:有趣的`events_statements_current`表問題









