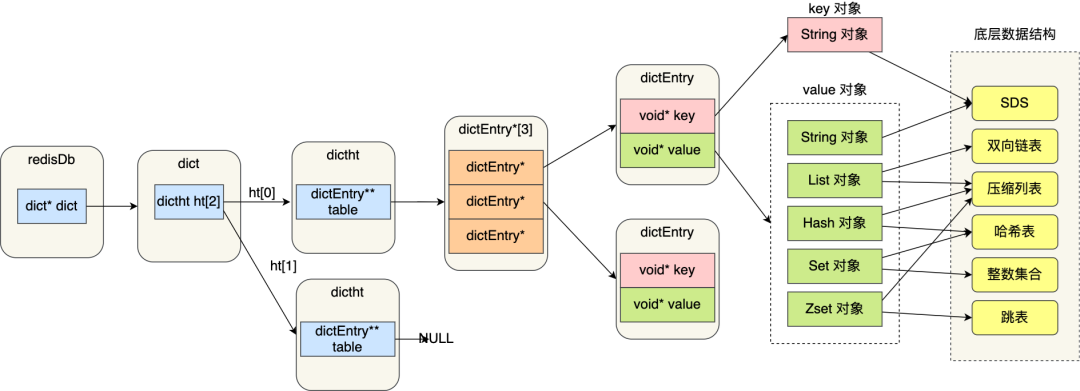
本文主要描述reids資料結構和底層資料結構的實作,用于熟悉redis的底層資料結構實作原理,下圖是reids的整個資料結構組成,這篇文章主要介紹value物件這部分資料結構
SDS初識
string結構對應底層SDS資料結構,SDS是redis最簡單的資料結構,一般用于分布式鎖和Json序列化物件存盤,
SDS命令:
-
設定SDS的值 set <key> <value>:SET NAME XIAOMING
- 獲取SDS值 get <key>:GET NAME
- 計數 incr <key>:INCR NUM
- 設定SDS過期時間 expire <key>:EXPIRE NAME 100
- 查看SDS過期剩余時間 ttl <key>:TTL NAME
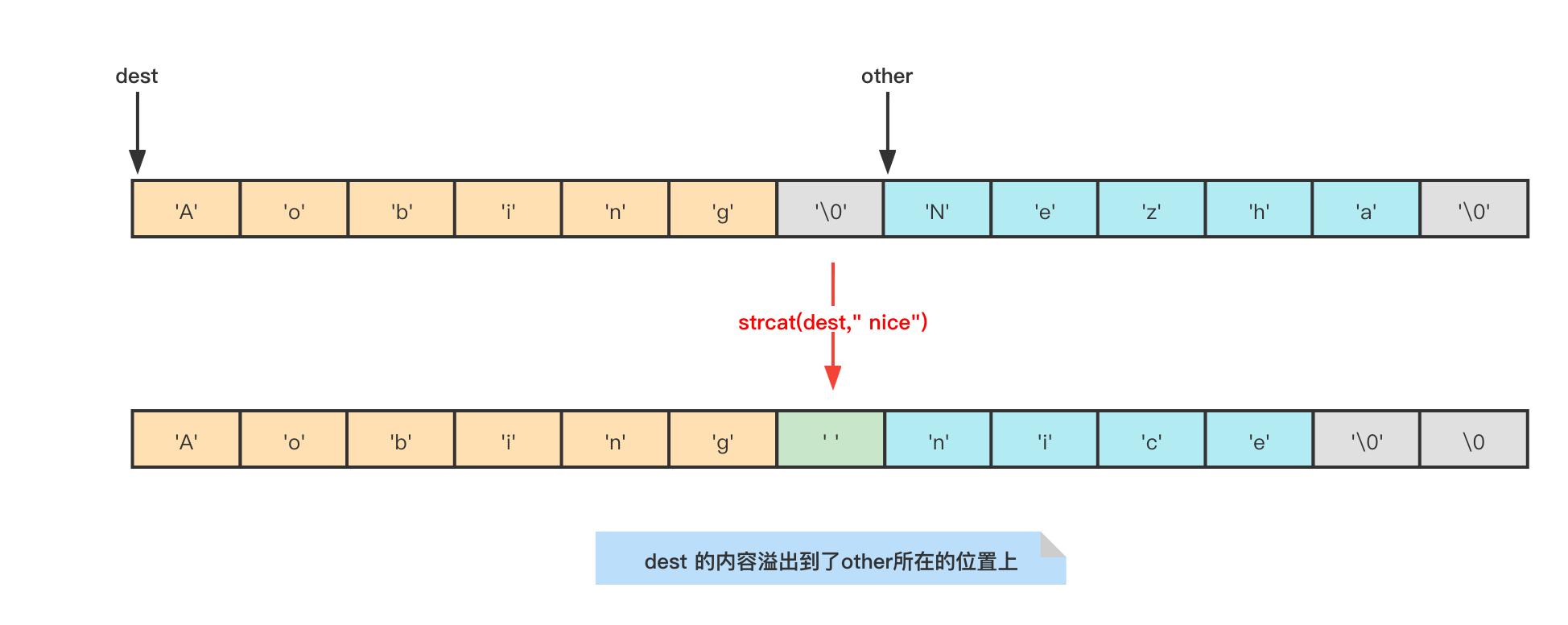
C語言字串的問題
- C語言中以”/0“識別字串的結尾,redis可以存盤任何檔案,那特殊檔案中資料就會有"\0"的存在,這樣就會導致資料截斷,
- C語言中獲取字串長度的時候,也是遍歷字符集,判斷到"\0"時就計算完畢,每次計算都是一個O(n)的操作,
-
字串合并時需要手動分配空間,容易導致記憶體溢位,
char * __cdecl strcat (char * dst, const char * src) { char * cp = dst; while( *cp ) cp++; while( *cp++ = *src++ ) ; return( dst ); }
SDS資料結構:

面對上述的幾個問題,SDS如何解決:
- 所有字符都存盤在buf陣列中,最后一位存盤的是”\0“
- len記錄了當前字串的長度,每次獲取只需要O(1)操作
-
字串合并分配空間時,需要len相加,然后看當前字串alloc中的空間是否足夠承載合并后的字符,不夠直接申請空間
sds sdscatsds(sds s, const sds t) { return sdscatlen(s, t, sdslen(t)); } sds sdscatlen(sds s, const void *t, size_t len) { size_t curlen = sdslen(s); s = sdsMakeRoomFor(s,len); if (s == NULL) return NULL; memcpy(s+curlen, t, len); sdssetlen(s, curlen+len); s[curlen+len] = '\0'; return s; }
極致的優化:
SDS實際還分為了物種型別的SDS,主要是用來分別SDS存盤的資料大小使用哪種資料結構,他們分別是:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
typedef struct __attribute__ ((__packed__)) 設定記憶體不對齊,固定資料在記憶體分配的大小,不需要編譯器優化補全
struct my
{
char ch;
int a;
} sizeof(int)=4;sizeof(my)=8;(非緊湊模式)
struct my{
char ch;
int a;
}__attrubte__ ((packed)) sizeof(int)=4;sizeof(my)=5
為什么Reids不補全?因為redis中的SDS中指標指的是buf陣列,獲取其他欄位是只需要移動申明時的空間就可以得到其他欄位,如果補全的話不清楚最大陣列會補全到多少
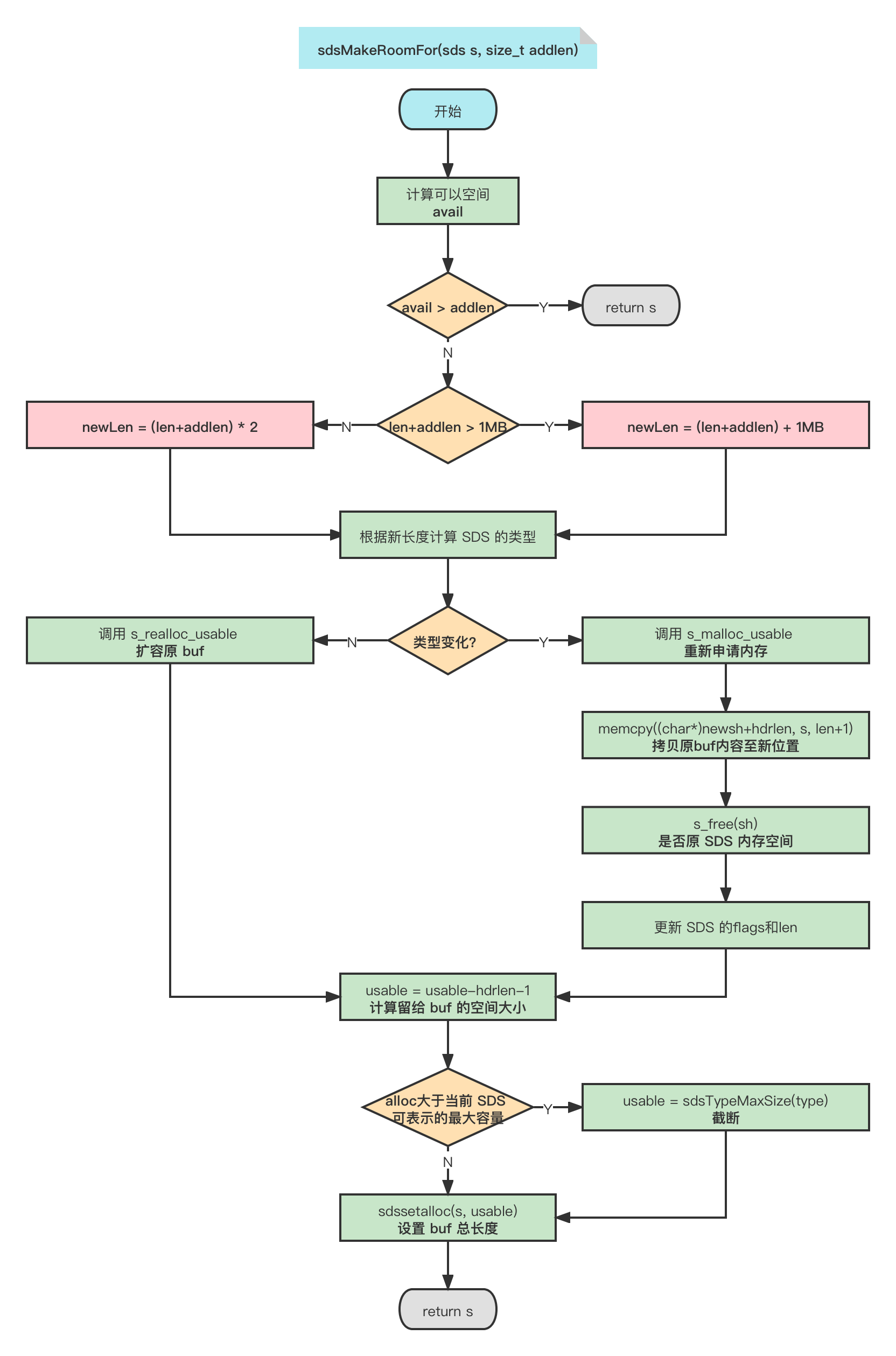
自動擴容機制總結:
擴容階段:
若 SDS 中剩余空閑空間 avail 大于新增內容的長度 addlen,則無需擴容;
若 SDS 中剩余空閑空間 avail 小于或等于新增內容的長度 addlen:
若新增后總長度 len+addlen < 1MB,則按新長度的兩倍擴容;
若新增后總長度 len+addlen > 1MB,則按新長度加上 1MB 擴容,
記憶體分配階段:
根據擴容后的長度選擇對應的 SDS 型別:
若型別不變,則只需通過 s_realloc_usable擴大 buf 陣列即可;
若型別變化,則需要為整個 SDS 重新分配記憶體,并將原來的 SDS 內容拷貝至新位置,
壓縮串列初識
壓縮串列在Redis中的List和Hash中都有使用,一般存盤一個序列的物件,
List命令:
- lpush <key> <value> :LPUSH NAME XIAOMING
- lpop <key>:LPOP NAME
- llen <key>:LLEN NAME
- rpush <key> :RPUSH NAME
- rpop <key>:RPOP NAME
Hash命令:
- hset <key> <field><value>:HSET XIAOMING AGE 12
- hexists <key> <field>:HEXISTS XIAOMING AGE
- hgetall <key>:HGETALL XIAOMING
zipList資料結構:
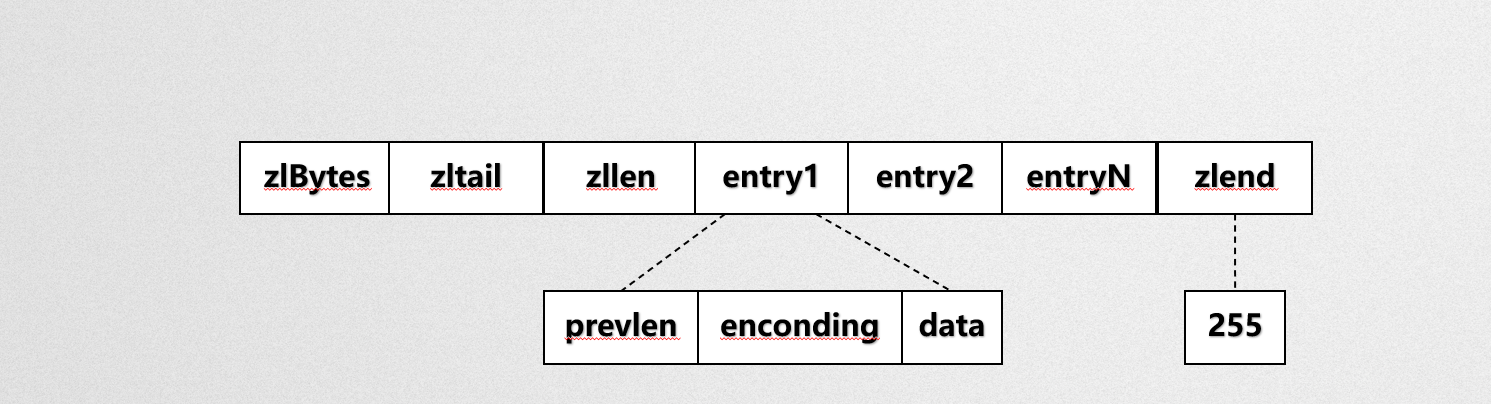
zlBytes:壓縮串列存盤的位元組數
zltail:壓縮串列尾部節點
zllen:壓縮串列長度
entry:壓縮串列元素
zlend:壓縮串列結尾標識,永遠都是255
entry:{
prevlen:前繼節點長度
encoding:編碼格式
data:資料內容
}
ziplist優點:
- 記憶體連續,使用完成的記憶體存盤資料
- 支持從后向前的遍歷資料
zipList資料結構解讀:
Q:為什么結尾標識一直是255?
A:這個標識是redis中固定的結尾是255,在prevLen中存盤的格式,當前前一個資料長度小于254,使用1個位元組存盤前一個節點的長度,如果大于254就用5個位元組存盤前一個節點的長度,定義成255是一個主要的標識,識別是否是結尾
prevlen:
| 位元組長度 | 存盤格式 |
|---|---|
| 1~253 | 8bit 1~253 |
| 254 |
8bit 32bit 254 prevLen |
Q:連鎖更新的問題?
A:每個entry存盤著前一個節點的長度,用于遍歷查找時使用,這也就是說當一個節點更新內容時,需要更新后繼節點中的prevlen,更新節點prevlen從1個位元組到5個位元組,后續的所有節點都需要更新,這就是典型的連鎖更新問題,
快速串列初識
在 redis 3.2 之后,list 的底層實作變為快速串列 quicklist,快速串列是 linkedlist 與 ziplist 的結合: quicklist 包含多個記憶體不連續的節點,但每個節點本身就是一個 ziplist,
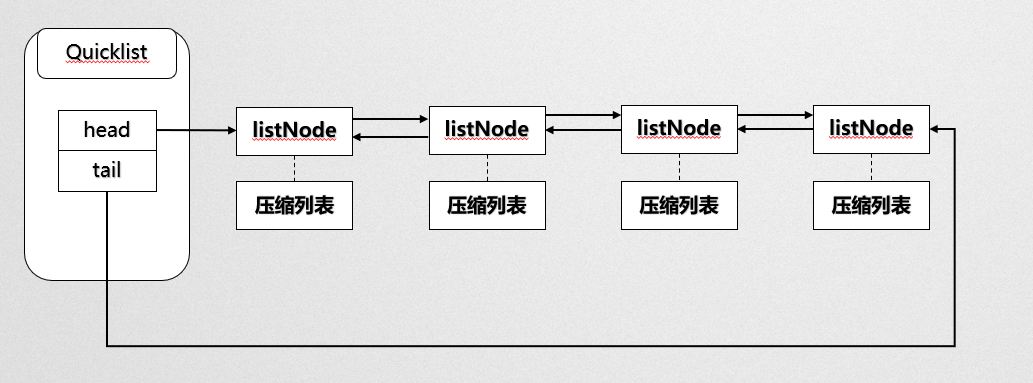
- 當串列物件中元素的長度比較小或者數量比較少的時候,采用壓縮串列 ziplist 來存盤
- 當串列物件中元素的長度比較大或者數量比較多的時候,則會轉而使用雙向串列 linkedlist 來存盤
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz;
unsigned int count : 16;
unsigned int encoding : 2;
unsigned int container : 2;
unsigned int recompress : 1;
unsigned int attempted_compress : 1;
unsigned int extra : 10;
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz;
char compressed[];
} quicklistLZF;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count;
unsigned long len;
int fill : 16;
unsigned int compress : 16;
} quicklist;quick 中使用之前的LinkedList和ZipList存盤資料,quicklist.compress 指定在雙向串列中前后有幾個節點不進行壓縮,這是方便在遍歷時不用從zipList尋址,
quickList資料結構優點:
- 有效解決了連鎖更新的問題,但是沒有徹底解決,只是修改為部分連鎖更新,當LinkListNode中的ZipList更新時只在當前的LinkListNode中做連鎖更新,
- 支持存盤更多的資料
- 支持雙向查找
哈希表初識
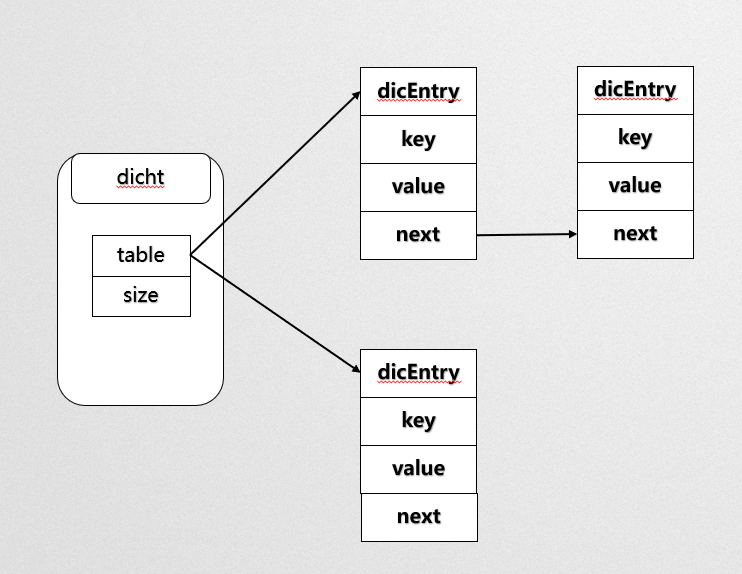
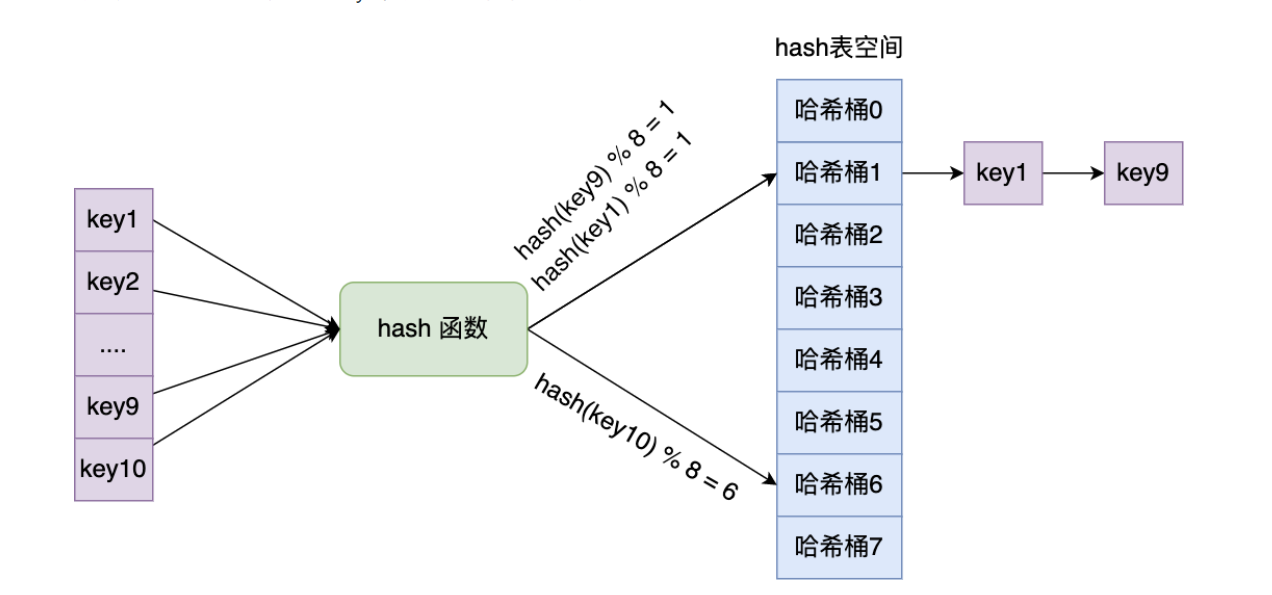
hash表中使用key:value這樣的方式存盤資料,next指標存盤了下個entry資料地址,在redis中Hash、zset、set使用哈希表存盤資料
set命令:
- sadd <key> <value> :SADD NAME XIAOMING
- sismember <key> <value>:SISMEMBER NAME XIAOMING
- smembers <key>:SMEMBERS NAME
- sscan <key> <number> :SSCAN NAME 0
- srem <key> <value>:SREM NAME XIAOMING
zset命令:
- zadd <key> number <value>:ZADD XIAOMING 6 AGE
- zcount <key> min max:ZCOUNT XIAOMING 0 1
-
zrangebyscore <key> min max:ZRANGEBYSCORE XIAOMING 0 100
-
zremrangebyscore <key> min max:ZREMRANGEBYSCORE XIAOMING 0 1
- zrem <key> <value>:ZREM XIAOMING AGE
Dic資料解讀
Dicht中的hash沖突
從資料結構中可以看到redis中的hash沖突使用鏈表尋址法,當前節點存盤了在同一個bucket中的下個節點,這樣處理hash沖突的優點是同一個Key只需要經過一次hash演算法找到存盤資料的Bucket就可以找到資料,缺點是在一個Dic中資料存盤過多,沖突發生的較多時,獲取資料需要耗費更多的O(n)的操作下完成
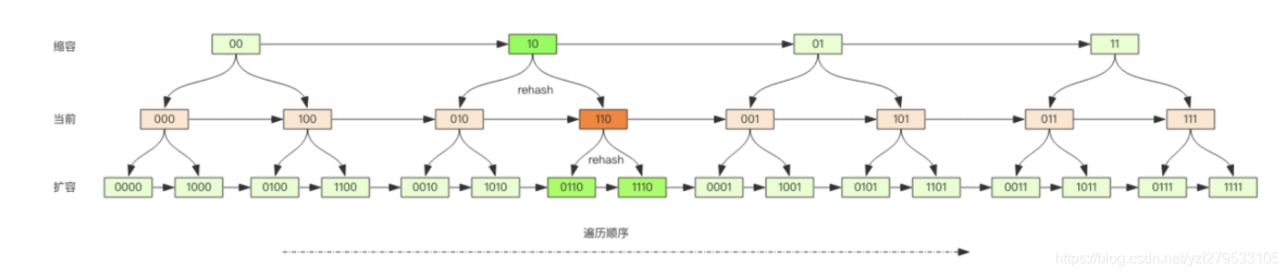
Dic中的rehash
第一個圖中可以看到Dic中有兩個table,在redis中所有的資料都是存盤在dic中的,當dic進行擴容時,就需要進行rehash,也就是把key重新進行hash存盤到擴容后的dic中,
Q:什么時候觸發rehash
- 擴容操作
如果沒有進行bgsave 元素數量達到hash長度時就會擴容(負載因子大于等于 1)
如果進行bgsave,元素數量達到hash長度的5倍會進行擴容(負載因子大于等于 5)
- 收縮操作
當哈希表的負載因子小于 0.1時, 程式自動開始對哈希表執行收縮操作,
Q:rehash執行了什么操作
A: 在字典中維持一個索引計數器變數 rehashidx , 并將它的值設定為 0 , 表示 rehash 作業正式開始;
為 ht[1] 分配空間, 讓字典同時持有 ht[0] 和 ht[1] 兩個哈希表
- 若是擴展操作,那么ht[1]的大小為>=ht[0].used*2的2^n
- 若是收縮操作,那么ht[1]的大小為>=ht[0].used的2^n
將保存在 ht[0] 中的所有鍵值對 rehash 到 ht[1] 上
當 ht[0] 包含的所有鍵值對全部遷移到了 ht[1] 之后,釋放 ht[0] ,將 ht[1] 設定為 ht[0],并重置 ht[1] ,最好將 rehashidx 屬性的值設為 -1 , 表示 rehash 操作已完成,
rehashidx還有一個作用:記錄的是ht[0]的下標位置的位置,下次rehash就從該位置繼續進行,
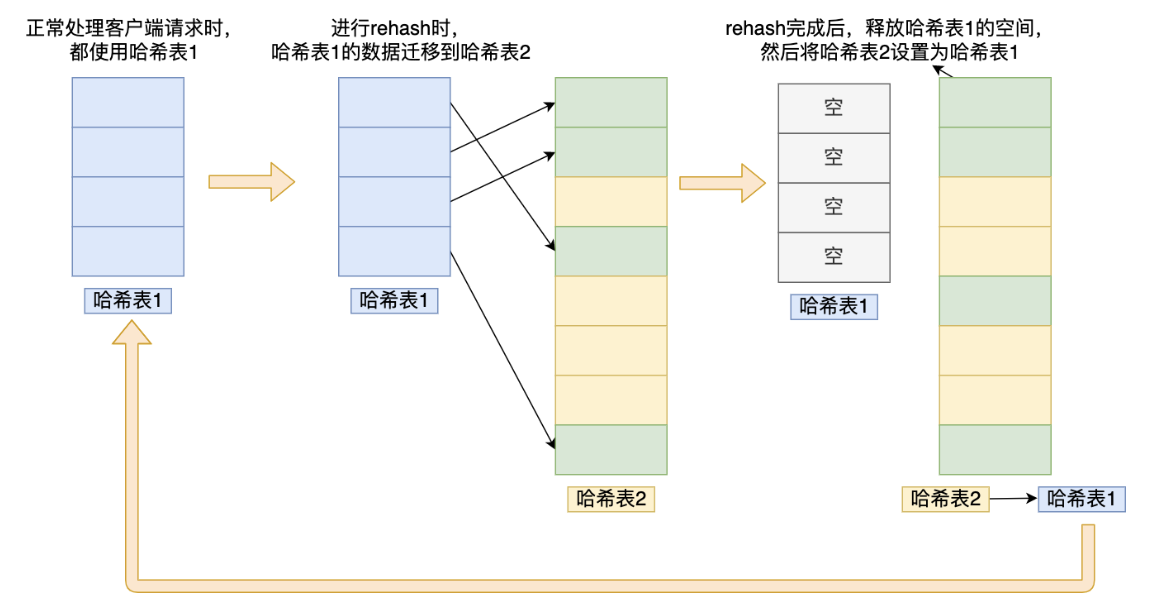
Q:rehash大資料時阻塞請求?
A:redis在進行rehash進行了漸進式rehash操作,每次操作哈希表1中的資料時才會將資料添加到哈希表2中,每次之操作一個key,
Q:rehash演算法是什么樣的,如何保證rehash之后的順序和不沖突?
A:redis采用高位加位法,在擴容之后之前相鄰的key還是相鄰的,縮容之后依舊相鄰,
核心演算法:
a mod 8 = a & (8-1) = a & 7
a mod 16 = a & (16-1) = a & 15
a mod 32 = a & (32-1) = a & 31
7,15,31也就是Mask,所謂的掩碼,每個key在進行hash計算的時候都經過了相同的掩碼,
跳表初識

redis中zset使用跳表存盤資料,主要使用跳表計算score,支持按照score區間查找資料,
跳表資料結構解讀
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;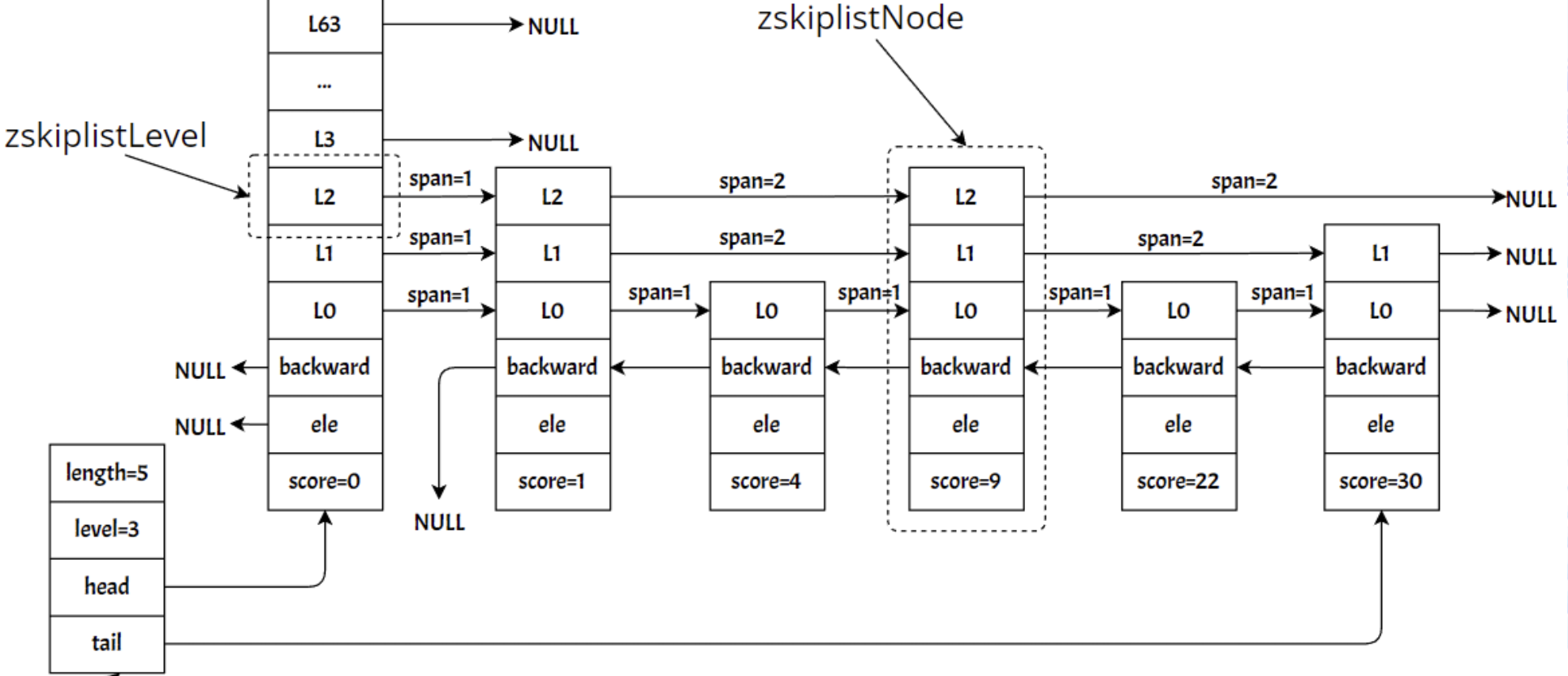
跳表由多個陣列組成,每個陣列代表一層,最底層的陣列存盤所有的資料,上面的每一層存盤的是資料的索引(就好比B+ tree),redis中的跳表節點,存盤了前繼節點的指標、socre、和資料(在不同的跳表實作中會存盤不同的節點資訊,包括上層節點,前繼節點,下層節點,)
跳表的來歷
跳表的研究來源于,有一個1至9的陣列,我需要查9,
第一次,從1到9一個一個查詢,需要查詢9次,才能回傳我想要的9,
來如果我每次差兩個數字,第5次就可以查到9,依次類推,每次多差一次,查詢次數就是9/n次,n越大,回圈的次數就越少,但是n很大時,直接跳過了我要尋找的資料,也是不行的,所以這個n是無法估量的一個數字,所以產生了跳表,由資料的數量決定每一層的n是多少,
如何升層
如何才能知道我當前的資料是否可以到更高層?這個有幾種演算法:
1.固定的間隔,固定的間隔會隨著資料增多層數越來越高,每次查找資料都需要經過固定的間隔
2.隨機升層,不穩定升層,有可能同一層的資料很多了,但是還是沒有升層資料,查詢發生O(n)的操作
reids使用拋硬幣的原理計算是否在更高層建立索引,只要計算是小于0.25那么就在高層建立索引,但是也有一個最大層(64)的限制
int randomlevel() {
//初始化為一級索引
int level = 1;
//翻硬幣,如果求余2等于1 則 level增加一層
while( rand() % 2 ) level++;
//如果level 沒有超過最大層數就回傳,否則就回傳最大層數
level = ( maxlevel > level ) ? level : maxlevel;
return level;
}為何限制64層
- 跳表層數越高,查詢的復雜度就越高,想想一下一個滿層(64層)的跳表,需要查詢到中間內容,需要查幾次呢?描述一下跳表查詢步驟,從最高層的索引處第一個元素查詢資料,如果比第一層的第二元素小并且比第一個元素大,那么向下一層的前一個元素的區間查找,沒向下一層就會有N個節點區間,層數越高,節點區間越多,復雜度就越高,
- 維護一個滿層的資料結構,添加一個資料,需要重新建立索引,如果是從底層建立到最高層,那就需要調整所有層中的索引,這其中包括升層,降層,
跳表和樹的比較
| 資料結構 | 簡介 | 存盤特性 | 查找復雜度 | 插入復雜度 |
|---|---|---|---|---|
| 跳表 | 使用層級創建索引,支持跳躍查詢 | 最底層存盤資料,上層建立索引 | logN | logN |
| 紅黑樹(AVL) | 平衡二叉樹 | 每個數節點只能由兩個葉節點組成,樹節點存盤資料 | log2N | log2N |
| B+樹 | 索引平衡二叉樹,葉子節點存盤資料,樹節點存盤索引 | 每個樹節點由兩個葉子節點組成,最底層葉子節點存盤資料,樹節點存盤索引 | logmN | logmN |
| B樹 | 索引平衡二叉樹,樹節點存盤資料 | 樹節點有多個葉節點組成,樹節點存盤資料和索引 | logN | 近似logN |
學習的工具
在線測驗redis命令:https://try.redis.io/
redis官網:https://redis.io/
書:《redis深度歷險記》
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/545641.html
標籤:其它
上一篇:redis(14)主從復制
下一篇:sql快速查詢表結構方法