?? 寫在前面
這篇5000多字博客也花了我幾天的時間??,主要是我對MySQL一部分重要知識點的理解【后面當然還會寫博客補充噻,歡迎關注我喲】,當然這篇文章可能也會有不恰當的地方【畢竟也寫了這么多字,錯別字可能也不少??】,不足的地方歡迎各位的指正,
ps:【文章最后有相關練習題的分享】
??一、主鍵和外鍵知識點補充
?1.1、 主鍵的概念
1、什么時候用主鍵?2、主鍵有什么用處 3、一張表可以設定幾個主鍵?4、一個主鍵只能是一列嗎?5、主鍵和唯一索引有什么區別?
1)每個表應該有一個主鍵 , 定義一個保證唯一標識每個logging的主鍵,
2)資料庫主鍵,指的是一個列或多列的組合,其值能唯一地標識表中的每一行,通過它可強制表的物體完整性,主鍵主要是用與其他表的外鍵關聯,以及文本記錄的修改與洗掉,
3) 一張表只可以有一個主鍵
4)主鍵不一定只有一列,有些表的主鍵是多個屬性構成的,表定義為列的集合
5)主鍵是一種約束,唯一索引是一種索引,兩者在本質上是不同的, 1、主鍵創建后一定包含一個唯一性索引,唯一性索引并不一定就是主鍵, 2、唯一性索引列允許空值,而主鍵列不允許為空值, 3、主鍵列在創建時,已經默認為空值 + 唯一索引了, 4、主鍵可以被其他表參考為外鍵,而唯一索引不能,
?1.2、主鍵的創建
??1.2.1、創建一個主鍵
比如我們要創建一張名為 "tb1"的表并且將它的id列設定為主鍵
creat table tb1( id int not null auto_increment primary key, )
??1.2.2、創建多個主鍵
為“tb1”的表創建多個主鍵
creat table tb1( id int not null auto_increment , pid int(11) not NULL, primary key(id, pid) )
??二、補充知識點
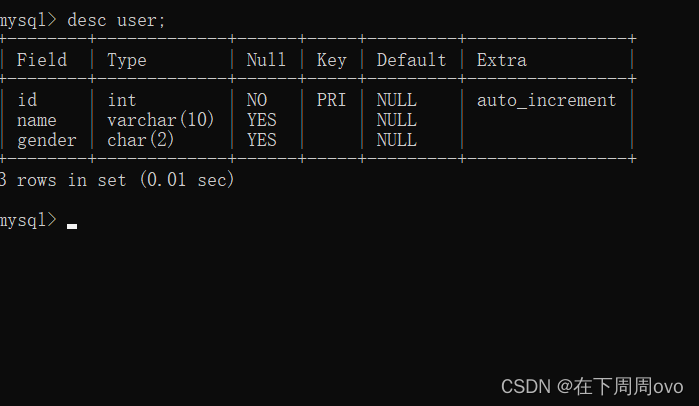
?2.1、desc 表名;
desc tablenames 主要用來查看資料表的表結構
比如用以下命令創建了一張‘user’表
create table user( id int auto_increment primary key, name varchar(10), gender char(2) )engine=innodb default charset=utf8;使用以上命令后可以得到如下結果:
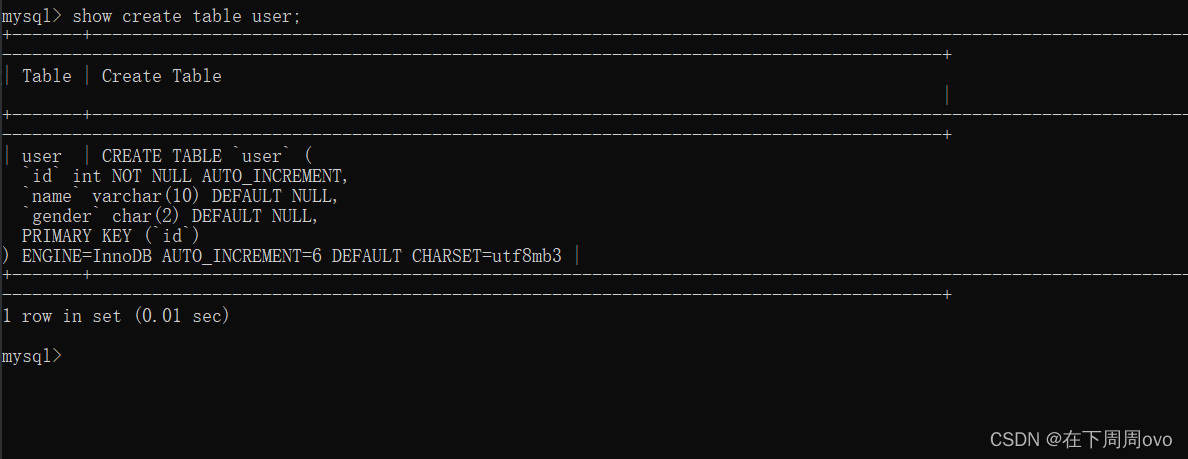
?2.2、show create table 表名;
該陳述句的功能:查看表創建時的定義
列如對上面的‘user’表執行該操作得到如下結果:
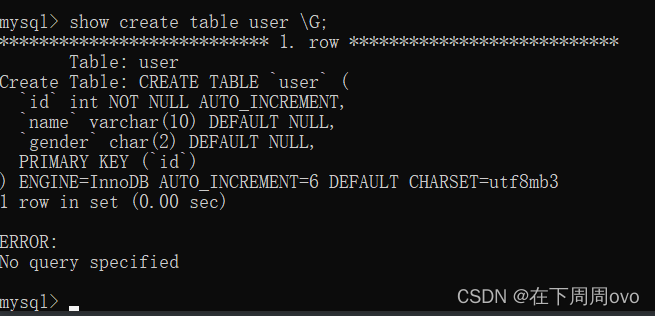
但是上面的結果看起來非常混亂,我們可以使用\G【\G 的作用是將查到的結構旋轉90度變成縱向】使得結果更加美觀
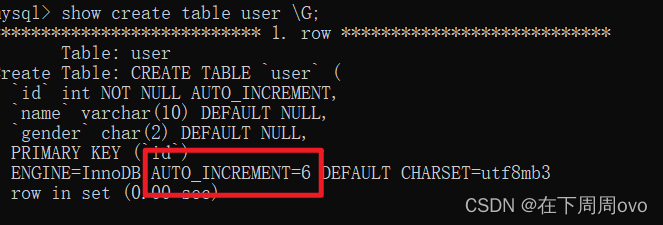
??三、自增列起始值設定
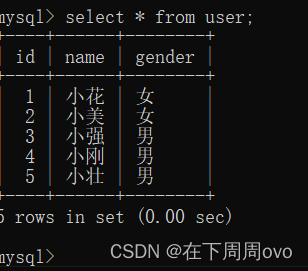
我們首先查看上面user表中的資料
不難看出這個表的id列已經自增到了5,其中show create table 表名;可以看出AUTO_INCREMENT=6,這個就表示接下來id列要遞增成為的數字,
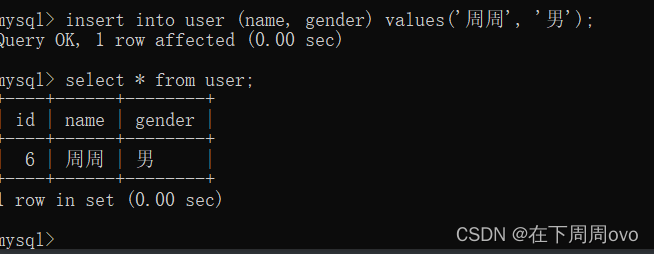
下一步我們使用delete from user;陳述句來洗掉這個表接著我們使用
insert into user (name, gender) values('周周', '男');再向表中插入一列會發現id列是從6開始遞增
這時我們就會想,可不可以重新從1開始,或者自定義開始遞增時的值呢?
?3.1、設定自增列初始值陳述句
alter table user AUTO_INCREMENT=1;
要特別注意如果設定的初始值小于原來表遞增列最后一個資料的值,那么陳述句是不會生效的
??四、自增列步長設定
?4.1、步長設定語法
步長設定我就不舉例了,上面是設定遞增列的初始值,這個是步長【不設定默認是1】
語法:
set session auto_increment_increment=2; 設定會話步長 show session variables like 'auto_inc%'; 查看全域變數但是要強調一點:
MySQL: 自增步長是基于會話級別的【登入一次mysql就是一次會話】,改變一次步長之后同一次會話創建的所有表的步長都會改變為你設定的步長;
SqlServer:自增步長:是基礎表級別的:可以單獨的對某一張表的步長進行設定,而不改變全域的步長;
總結:SqlServer方便一點
MySQL: 自增步長 基于會話級別: show session variables like 'auto_inc%'; 查看全域變數 set session auto_increment_increment=2; 設定會話步長 # set session auto_increment_offset=10; 基于全域級別(接下來開的所有會話的步長都會改變): show global variables like 'auto_inc%'; 查看全域變數 set global auto_increment_increment=2; 設定會話步長 # set global auto_increment_offset=10; 設定起始值 SqlServer:自增步長: 基礎表級別: CREATE TABLE `t5` ( `nid` int(11) NOT NULL AUTO_INCREMENT, `pid` int(11) NOT NULL, `num` int(11) DEFAULT NULL, PRIMARY KEY (`nid`,`pid`) ) ENGINE=InnoDB AUTO_INCREMENT=4, 步長=2 DEFAULT CHARSET=utf8 CREATE TABLE `t6` ( `nid` int(11) NOT NULL AUTO_INCREMENT, `pid` int(11) NOT NULL, `num` int(11) DEFAULT NULL, PRIMARY KEY (`nid`,`pid`) ) ENGINE=InnoDB AUTO_INCREMENT=4, 步長=20 DEFAULT CHARSET=utf8
??五、唯一索引知識點
?5.1、什么是唯一索引?
所謂唯一索引,就是在創建索引時,限制索引的欄位值必須是唯一的,通過該型別的索引可以比普通索引更快速地查詢某條記錄,唯一索引顧名思義不可以重復,但是可以為空,這也是它與主鍵的區別之一
?5.3、創建唯一索引的方式
創建方法一:
CREATE UNIQUE INDEX indexName ON mytable(username(length))創建方法二【聯合唯一索引】:
UNIQUE indexName (列名,列名),在創建表時的例子:
create table t1( id int ...., num int, xx int, UNIQUE 唯一索引名稱 (列名,列名), # 示例 UNIQUE uql (num,xx), )
??六、外鍵變種詳細知識點
?6.1、什么是外鍵變種
顧名思義就是外鍵的多種形式,下面會通過舉例子的方式講述
?6.2、外鍵變種之一對一
比如我們有兩張表【用戶表】 和【博客表】,如果每個用戶只能注冊一個博客,那么用戶賬號與博客賬號的外鍵關系就是一對一
用戶表: id name age 1 xaiom 23 2 eagon 34 3 lxxx 45 4 owen 83 博客表: id url user_id (外鍵 + 唯一約束) 1 /xiaom 2 2 /zekai 1 3 /lxxx 3 4 /owen 4
?6.3、外鍵變種之多對多
這個也是比較容易理解的,就比如我有兩張表【用戶表】 和【主機表】,每個用戶可以登入多臺主機,同時每臺主機也可以被多個用戶同時使用,這種關系就是多對多
用戶表: id name phone 1 root1 1234 2 root2 1235 3 root3 1236 4 root4 1237 5 root5 1238 6 root6 1239 7 root7 1240 8 root8 1241 主機表: id hostname 1 c1.com 2 c2.com 3 c3.com 4 c4.com 5 c5.com 為了方便查詢, 用戶下面有多少臺主機以及某一個主機上有多少個用戶, 我們需要新建第三張表: 用戶主機表: id userid hostid 1 1 1 2 1 2 3 1 3 4 2 4 5 2 5 6 3 2 7 3 4 創建的時候, userid 和 hostid 必須是外鍵, 然后聯合唯一索引 unique(userid, hostid),(避免重復出現)【聯合唯一索引在多對多的情況下可以視情況而寫】 Django orm 也會設計
??七、資料行操作補充
?7.1、增操作
向表的某一行插入資料
insert into 表名(列名1, 列名2) values('行一內容', '行一內容'), ('行二內容', '行二內容')向表的多行插入資料
insert into 表名(列名1, 列名2) values('行一內容', '行一內容'), ('行二內容', '行二內容')向某一張表中插入另一張表中的內容
insert into 表一(name,age) select name,age from 表二;
?7.2、刪操作
假設我創建了一張表叫【tb1】其中列名有【name】列和【id】列
# 洗掉表 delect from tb1 # 帶條件的洗掉 # 把id不等于2的行洗掉 delete from tb1 where id !=2 delete from tb1 where id =2 delete from tb1 where id > 2 delete from tb1 where id >=2 # 把id > 2,并且name='alex'的資料行洗掉 delete from tb1 where id >=2 or name='alex'
?7.3、改操作
同樣的使用上面刪操作的表
# 把tb1表中的id > 2,并且name='XX'的資料行,的名字設為'alex',其他的不變 update tb1 set name='alex' where id>12 and name='xx' update tb1 set name='alex',age=19 where id>12 and name='xx'
?7.4、查操作
基礎的查操作
# 查看表中所有資料 select * from tb1; # 查看表中id,name列的資料 select id,name from tb1; select id,name from tb1 where id > 10 or name ='xxx'; # 查看表中id,name列的資料,并將name列名重新取個叫cname的別名 select id,name as cname from tb1 where id > 10 or name ='xxx'; select name,age,11 from tb1;進階的查操作
select * from tb1 where id != 1 # 查看id為(1,5,12)中的數的行 select * from tb1 where id in (1,5,12); select * from tb1 where id not in (1,5,12); # 查tb1表中值id為tb11中元素的行 select * from tb1 where id in (select id from tb11) # 查看id為5到12之間數的行 select * from tb1 where id between 5 and 12;通配符的查操作
# 查詢表中以ale開頭的所有用戶 %表示后面可以有任意多個字符,比如可以匹配到【alex,alexk】 select * from tb1 where name like "ale%" # 查詢表中以ale開頭的所有用戶 _表示后面只能有一個字符,比如【alex】可以匹配到但是【alexxxx】就不可以匹配到 select * from tb1 where name like "ale_"
?7.5、limit以及order by陳述句
將上面知識是先看下面的圖:
在我們瀏覽器搜素想要的內容時,回傳的結果通常是很多的,如果一次將結果全部顯示給你,那么電腦可能會崩潰,這時瀏覽器就會默認回傳結果的前幾十條,這種對想要查詢結果的條數的限制我們在資料庫中也可以使用limit來實作??7.5.1、limit【限制】的用法
# 查看表中的前十條資料 select * from tb1 limit 10; # 從0行開始后面取十條資料 select * from tb1 limit 0,10; select * from tb1 limit 10,10; # 從20行開始后面取十條資料 select * from tb1 limit 20,10; # 從第20行開始讀取,讀取10行; select * from tb1 limit 10 offset 20;??7.5.2、order by【排序陳述句】
# 將表tb1按id列從大到小排 select * from tb1 order by id desc; 大到小 【口訣先d后c,d在c后面所以是從大到小】 select * from tb1 order by id asc; 小到大 【口訣先a后c,c在a后面所以是從小到大】 # 將表tb1按age列從大到小排,如果id數值相同就按id列大小從小到大排 select * from tb1 order by age desc,id desc;拓展要點:取后十條資料
# 實作原理:將tb1表逆序,然后在取前十條資料,這樣就相當于取了原表的最后十條資料 select * from tb1 order by id desc limit 10;

??八、MySQL分組操作知識點
關鍵陳述句:
group by首先我們按如下的方式創建兩張表【department表】【userinfo表】
department表 CREATE table department( id int auto_increment primary key, title varchar(32) )engine=innodb default charset=utf8; userinfo表 CREATE table userinfo( id int auto_increment primary key, name varchar(32), age int, depart_id int, CONSTRAINT fk_usrt_depart FOREIGN key (depart_id) REFERENCES department(id) )engine=innodb default charset=utf8; # 給兩張表加資料 # department表 +----+-------+ | id | title | +----+-------+ | 1 | 財務 | | 2 | 公關 | | 3 | 測驗 | | 4 | 運維 | +----+-------+ # userinfo表 +----+------+------+-----------+ | id | name | age | depart_id | +----+------+------+-----------+ | 1 | 小費 | 6 | 1 | | 2 | 小港 | 6 | 3 | | 3 | 小干 | 6 | 2 | | 4 | 小剛 | 6 | 4 | | 5 | 小強 | 6 | 4 | | 6 | 小美 | 6 | 4 | | 7 | 小亮 | 6 | 2 | | 8 | 小每 | 6 | 1 | +----+------+------+-----------+對于陳述句我就不多解釋了,主要看結果就可以了
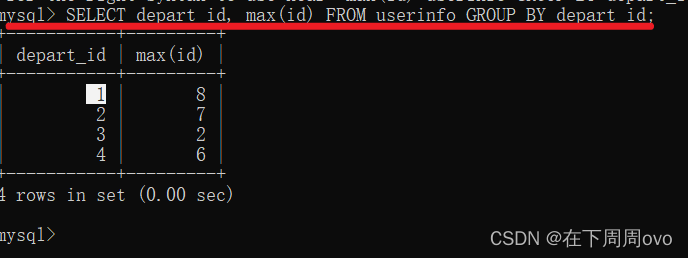
1、將同一個部門的人放在一起,并且用戶部門相同取id值大的用戶
SELECT depart_id, max(id) FROM userinfo GROUP BY depart_id;輸出結果:
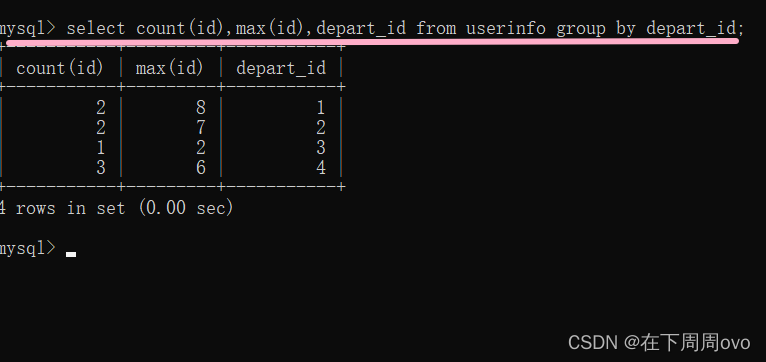
2、在上面操作的基礎上顯示各個部門的人數select count(id),max(id),depart_id from userinfo group by depart_id;輸出結果:
3、如果對于聚合函式結果進行二次篩選時?必須使用havingselect count(id),depart_id from userinfo group by depart_id having count(id) > 1;
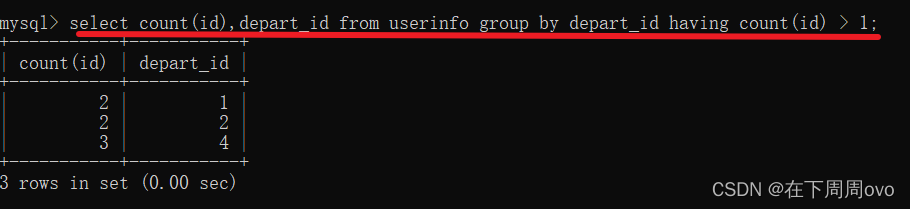
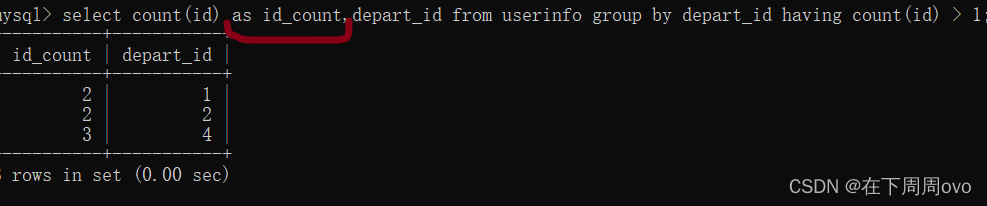
4、上面的列名為count(id),這是看著有點不舒服的,我們可以使用as關鍵字改名
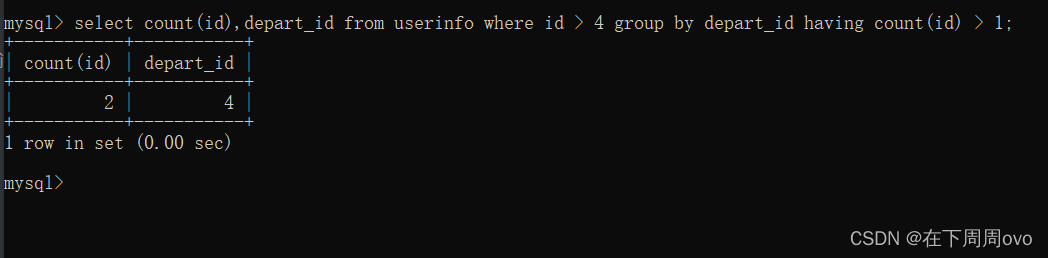
5、進一步的進階方式select count(id),depart_id from userinfo where id > 4 group by depart_id having count(id) > 1;
??九、MySQL連表操作
?9.1、連表操作概念
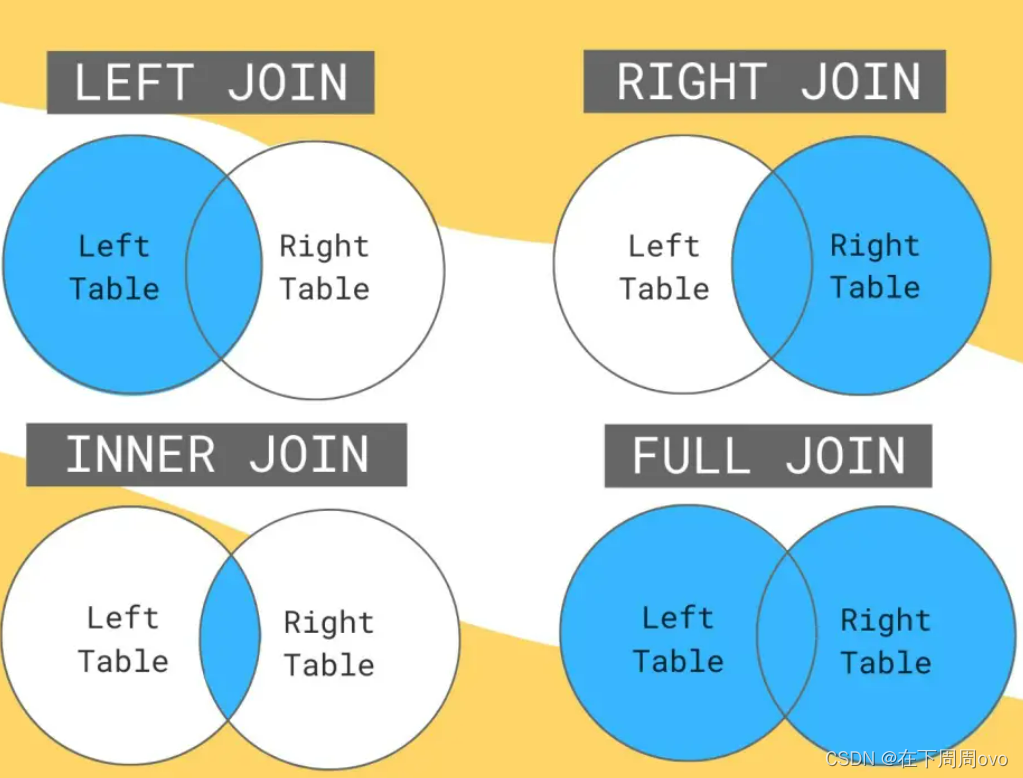
連表顧名思義就是將兩張表連在一起查看的操作,操作大的分為兩種內連接和外連接,而外連接又分為左連接、右連接和全連接,
內連接(inner join):只包含匹配的記錄,
外連接(outer join):除了包含匹配的記錄還包含不匹配的記錄,{
? 1. 左連接(left join):回傳匹配的記錄,以及表 A 多余的記錄,
? 2. 右連接(right join):回傳匹配的記錄,以及表 B 多余的記錄,
? 3. 全連接(full join):回傳匹配的記錄,以及表 A 和表 B 各自的多余記錄,
}
用網上一張圖比較好的圖可以更加方便理解如下:
下面我們都用【department表】【user_mess表】來舉例:# department表 +----+-------+ | id | title | +----+-------+ | 1 | 財務 | | 2 | 公關 | | 3 | 測驗 | | 4 | 運維 | +----+-------+ # user_mess表 +----+------+-----------+ | id | name | depart_id | +----+------+-----------+ | 1 | 小費 | 1 | | 2 | 小港 | 1 | | 3 | 小干 | 2 | | 4 | 小剛 | 4 | +----+------+-----------+執行如下陳述句可以連接兩張表:
select * from user_mess,department where user_mess.depart_id = department.id; 輸出結果: +----+------+-----------+----+-------+ | id | name | depart_id | id | title | +----+------+-----------+----+-------+ | 1 | 小費 | 1 | 1 | 財務 | | 2 | 小港 | 1 | 1 | 財務 | | 3 | 小干 | 2 | 2 | 公關 | | 4 | 小剛 | 4 | 4 | 運維 | +----+------+-----------+----+-------+ 4 rows in set (0.00 sec)
?9.2、內連接
內連接 語法: a inner join b ,但是一般 inner 可以省略不寫,也就是如下形式
select * from a join b ;執行下面陳述句:
select * from user_mess join department; 輸出結果: +----+------+-----------+----+-------+ | id | name | depart_id | id | title | +----+------+-----------+----+-------+ | 4 | 小剛 | 4 | 1 | 財務 | | 3 | 小干 | 2 | 1 | 財務 | | 2 | 小港 | 1 | 1 | 財務 | | 1 | 小費 | 1 | 1 | 財務 | | 4 | 小剛 | 4 | 2 | 公關 | | 3 | 小干 | 2 | 2 | 公關 | | 2 | 小港 | 1 | 2 | 公關 | | 1 | 小費 | 1 | 2 | 公關 | | 4 | 小剛 | 4 | 3 | 測驗 | | 3 | 小干 | 2 | 3 | 測驗 | | 2 | 小港 | 1 | 3 | 測驗 | | 1 | 小費 | 1 | 3 | 測驗 | | 4 | 小剛 | 4 | 4 | 運維 | | 3 | 小干 | 2 | 4 | 運維 | | 2 | 小港 | 1 | 4 | 運維 | | 1 | 小費 | 1 | 4 | 運維 | +----+------+-----------+----+-------+說明:像這樣不加查詢條件會形成 笛卡爾積 ,笛卡爾積的意思是:是指包含兩個集合中任意取出兩個元素構成的組合的集合,// 兩表分別交叉查詢了一遍;也可以加上條件查詢條件 on 或者 using ,兩者的區別在于 都是查詢出符合條件的結果集 ,但是using會優化掉相同的欄位,
下面來舉個栗子更好理解:
# 使用on陳述句添加條件 select * from user_mess join department on user_mess.depart_id = department.id; 輸出結果: +----+------+-----------+----+-------+ | id | name | depart_id | id | title | +----+------+-----------+----+-------+ | 1 | 小費 | 1 | 1 | 財務 | | 2 | 小港 | 1 | 1 | 財務 | | 3 | 小干 | 2 | 2 | 公關 | | 4 | 小剛 | 4 | 4 | 運維 | +----+------+-----------+----+-------+ 4 rows in set (0.00 sec)這時我們可以發現這與上面的
select * from user_mess,department where user_mess.depart_id = department.id;陳述句輸出結果是相同的
?9.3、外連接
??9.3.1、左連接
語法:
# 左連接既 左邊 tb_left 表作為基表(主表)顯示所有行, tb_right 表作為外表 條件匹配上的就顯示,沒匹配上的就用 Null 填充 select * from tb_left left join tb_right on tb_left.id = tb_left.id ;栗子:
select * from user_mess left join department on user_mess.depart_id = department.id; 輸出結果: +----+------+-----------+------+-------+ | id | name | depart_id | id | title | +----+------+-----------+------+-------+ | 1 | 小費 | 1 | 1 | 財務 | | 2 | 小港 | 1 | 1 | 財務 | | 3 | 小干 | 2 | 2 | 公關 | | 4 | 小剛 | 4 | 4 | 運維 | +----+------+-----------+------+-------+ 4 rows in set (0.00 sec)
??9.3.1、右連接
語法:
# 右連接即 右邊 tb_right 表作為基表(主表)顯示所有行, tb_left 表作為外表 條件匹配上的就顯示,沒匹配上的就用 Null 填充; 和左連接相反, select * from tb_left right join tb_right on tb_left.id = tb_left.id ;栗子:
select * from user_mess right join department on user_mess.depart_id = department.id; 輸出結果: +------+------+-----------+----+-------+ | id | name | depart_id | id | title | +------+------+-----------+----+-------+ | 2 | 小港 | 1 | 1 | 財務 | | 1 | 小費 | 1 | 1 | 財務 | | 3 | 小干 | 2 | 2 | 公關 | | NULL | NULL | NULL | 3 | 測驗 | | 4 | 小剛 | 4 | 4 | 運維 | +------+------+-----------+----+-------+ 5 rows in set (0.00 sec)
??9.3.1、全外連接
語法:
# 經查找發現 MySQL 是不支持所謂 tb_left full join tb_right 語作為 全外連接查詢的,想要實作全外連接查詢可以通過 union 實作,union 運算子用于合并兩個或多個 SELECT 陳述句的結果集,陳述句如下: select * from tb_left left join tb_right on tb_left.id = tb_right.id union select * from tb_left right join tb_right on tb_left.id = tb_right.id ;栗子:
select * from user_mess left join department on user_mess.depart_id = department.id union select * from user_mess right join department on user_mess.depart_id = department.id; 輸出結果: +------+------+-----------+------+-------+ | id | name | depart_id | id | title | +------+------+-----------+------+-------+ | 1 | 小費 | 1 | 1 | 財務 | | 2 | 小港 | 1 | 1 | 財務 | | 3 | 小干 | 2 | 2 | 公關 | | 4 | 小剛 | 4 | 4 | 運維 | | NULL | NULL | NULL | 3 | 測驗 | +------+------+-----------+------+-------+ 5 rows in set (0.00 sec)值得注意的是:注:當 union 和 all 一起使用時(即 union all ),重復的行不會去除,
栗子:
select * from user_mess left join department on user_mess.depart_id = department.id union all select * from user_mess right join department on user_mess.depart_id = department.id; 輸出結果: +------+------+-----------+------+-------+ | id | name | depart_id | id | title | +------+------+-----------+------+-------+ | 1 | 小費 | 1 | 1 | 財務 | | 2 | 小港 | 1 | 1 | 財務 | | 3 | 小干 | 2 | 2 | 公關 | | 4 | 小剛 | 4 | 4 | 運維 | | 2 | 小港 | 1 | 1 | 財務 | | 1 | 小費 | 1 | 1 | 財務 | | 3 | 小干 | 2 | 2 | 公關 | | NULL | NULL | NULL | 3 | 測驗 | | 4 | 小剛 | 4 | 4 | 運維 | +------+------+-----------+------+-------+ 9 rows in set (0.00 sec)
?9.4、交叉連接
概念:
交錯連接 語法:tb1 cross join tb2 ;交錯連接可以加查詢條件,也可以不加查詢條件,如果不加查詢條件會形成 笛卡爾積,類似內連接效果,同樣可以使用 using 陳述句優化欄位,
栗子:
select * from user_mess cross join department; 輸出結果: +----+------+-----------+----+-------+ | id | name | depart_id | id | title | +----+------+-----------+----+-------+ | 4 | 小剛 | 4 | 1 | 財務 | | 3 | 小干 | 2 | 1 | 財務 | | 2 | 小港 | 1 | 1 | 財務 | | 1 | 小費 | 1 | 1 | 財務 | | 4 | 小剛 | 4 | 2 | 公關 | | 3 | 小干 | 2 | 2 | 公關 | | 2 | 小港 | 1 | 2 | 公關 | | 1 | 小費 | 1 | 2 | 公關 | | 4 | 小剛 | 4 | 3 | 測驗 | | 3 | 小干 | 2 | 3 | 測驗 | | 2 | 小港 | 1 | 3 | 測驗 | | 1 | 小費 | 1 | 3 | 測驗 | | 4 | 小剛 | 4 | 4 | 運維 | | 3 | 小干 | 2 | 4 | 運維 | | 2 | 小港 | 1 | 4 | 運維 | | 1 | 小費 | 1 | 4 | 運維 | +----+------+-----------+----+-------+ 16 rows in set (0.00 sec)
?9.5、總結各種連表操作
1、內連接和交叉連接是十分相似的,只是陳述句語法有所不同,但最后查詢出來的結果集的效果都是一樣的,添加條件查詢就只查詢匹配條件的行,不添加條件查詢則形成 笛卡爾積(生成重復多行) 而降低效率,
2、左連接以左邊表為基礎表 顯示所有行 ,右邊表條件匹配的行顯示,不匹配的則有 Null 代替,
3、右連接以右邊表為基礎表 顯示所有行 ,左邊表條件匹配的行顯示,不匹配的則有 Null 代替,
??十、小結
恭喜你看到了最后,現在看了這么多,不如趕快網上找些題目自己動手實踐一波撒??,
不知道在哪找?放心我幫你找好了??,
?? 【MySQL練習題】復制鏈接打開阿里云盤就行了:https://www.aliyundrive.com/s/D24NKjfNpTW
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/545780.html
標籤:其他
上一篇:flink-綜合練習