預告: 《MySQL實戰》即將出版,敬請關注!
有過線上 MySQL 維護經驗的童鞋都知道,主從延遲往往是一個讓人頭疼不已的問題,
不僅僅是其造成的潛在問題比較嚴重,而且主從延遲原因的定位尤其考量 DBA 的綜合能力:既要熟悉復制的內部原理,又能解讀主機層面的資源使用情況,甚至還要會分析 binlog,
導致主從延遲的一個常見原因是,對于 binlog 中的事務,從庫上只有一個 SQL 執行緒進行重放,而這些事務在主庫中是并發寫入的,
就好比你多個人(多執行緒)挖坑,我一個人(單執行緒)來填,本來就雙拳難敵四手,在你挖坑速度不快的情況下,我尚能應付,一旦你稍微加速,我則力有不逮,只能眼睜睜地看著你挖的坑越來越深,
具體在 MySQL 中,則意味著 Seconds_Behind_Master 的值越來越大,
本文主要包括以下幾部分:
1、主從延遲的危害,
2、并行復制方案簡介,
3、MySQL 5.7 基于組提交的并行復制方案,包括 Commit-Parent-Based 方案和 Lock-Based 方案,
4、MySQL 8.0 基于 WRITESET 的并行復制方案,
5、對 COMMIT_ORDER,WRITESET_SESSION,WRITESET 這三種方案的壓測結果,
6、如何開啟并行復制,
一、主從延遲的危害
主從延遲帶來的問題,主要體現在以下兩個方面:
1、對于讀寫分離的業務,主從延遲意味著業務會讀到舊資料,
2、主從延遲過大,會影響資料庫的高可用切換,這一點尤其需要注意,
-
如果等待從庫應用完差異的 binlog 才做高可用切換,無疑會影響資料庫服務的可用性,
-
如果不等待,直接切換,則意味著沒應用完的這部分 binlog 的資料會丟失,業務不一定能接受這種情況,
二、并行復制方案簡介
MySQL官方先后提出了多個不同的并行復制方案,具體如下,
1、MySQL 5.6 基于庫級別的并行復制方案,
2、MySQL 5.7 基于組提交的并行復制方案,
3、MySQL 8.0 基于 WRITESET 的并行復制方案,
因為線上大部分環境都是單庫多表的,所以基于庫級別的并行復制實際上用得并不多,
下面,重點看看后兩個方案的實作原理,
三、基于組提交的并行復制方案
MySQL 5.7 基于組提交的并行復制方案,先后經歷了兩個版本的迭代:Commit-Parent-Based 方案和 Lock-Based 方案,
3.1 Commit-Parent-Based 方案
MySQL 會將一個事務拆分為兩個階段進行處理:Prepare 階段和 Commit 階段,
另外,InnoDB 使用的鎖機制是悲觀鎖,在悲觀鎖中,事務是在操作之初執行加鎖操作,如果鎖資源被其它事務占用了,則該事務會被阻塞,
基于這兩點,我們不難推斷出,兩個事務如果都進入了 Prepare 階段,則意味著它們之間是沒有鎖沖突的,在從庫重放時可并行執行,這就是 Commit-Parent-Based 方案的核心思想,
具體實作上:
1、主庫有個全域計數器(global counter),每次在事務存盤引擎層提交之前,都會增加這個計數器,
2、在事務進入 Prepare 階段之前,會將全域計數器的當前值記錄在事務中,這個值稱為事務的 commit-parent,
3、這個 commit-parent 會寫入 binlog,記錄在事務的頭部,
4、從庫重放時,如果發現兩個事務的 commit-parent 相同,會并行執行這兩個事務,
以下面這 7 個事務為例,看看這 7 個事務在從庫的并行執行情況,
Trx1 ------------P----------C-------------------------------->
|
Trx2 ----------------P------+---C---------------------------->
| |
Trx3 -------------------P---+---+-----C---------------------->
| | |
Trx4 -----------------------+-P-+-----+----C----------------->
| | | |
Trx5 -----------------------+---+-P---+----+---C------------->
| | | | |
Trx6 -----------------------+---+---P-+----+---+---C---------->
| | | | | |
Trx7 -----------------------+---+-----+----+---+-P-+--C------->
| | | | | | |
示例中的 Trx 指的是事務,P 指的是事務在進行 Prepare 階段之前,讀取 commit-parent 的時間點,C 指的是事務在進行 Commit 階段之前,增加全域計數器的時間點,
下面看看這 7 個事務的并行執行情況,
-
Trx1、Trx2、Trx3 并行執行,
-
Trx4 串行執行,
-
Trx5、Trx6 并行執行,
-
Trx7 串行執行,
這在很大程度上實作了并行,但還不夠完美,
實際上,Trx4、Trx5、Trx6 可并行執行,因為它們同時進入了 Prepare 階段,同理,Trx6、Trx7 也可并行執行,
基于此,官方迭代了并行復制方案,推出了新的 Lock-Based 方案,
3.2 Lock-Based 方案
該方案引入了鎖區間(locking interval)的概念,鎖區間定義了一個事務持有鎖的時間范圍,具體來說,
1、將 Prepare 階段,最后一個 DML 陳述句獲取鎖的時間點,定義為鎖區間的開始點,
2、將存盤引擎層提交之前,鎖釋放的時間點,定義為鎖區間的結束點,
如果兩個事務的鎖區間存在交集,則意味著這兩個事務沒有鎖沖突,可并行重放,例如,
Trx1 -----L---------C------------>
Trx2 ----------L---------C------->
反之,則不可并行重放,例如,
Trx1 -----L----C----------------->
Trx2 ---------------L----C------->
這里的 L 代表鎖區間的開始點,C 代表鎖區間的結束點,
在具體實作上,主庫引入了以下 4 個變數:
1、global.transaction_counter:事務計數器,
2、transaction.sequence_number:事務序列號,
在事務進入 Prepare 階段之前,會將 global.transaction_counter 自增加 1 并賦值給 transaction.sequence_number,
transaction.sequence_number = ++global.transaction_counter
序列號不是一直遞增的,每切換一個 binlog,都會將 transaction.sequence_number 重置為 1,
3、global.max_committed_transaction:當前已提交事務的最大序列號,
在事務進行存盤引擎層提交之前,會取 global.max_committed_transaction 和當前事務的 sequence_number 的最大值,賦值給 global.max_committed_transaction,
global.max_committed_transaction = max(global.max_committed_transaction,
transaction.sequence_number)
4、transaction.last_committed:在事務進入 Prepare 階段之前,已提交事務的最大序列號,
transaction.last_committed = global.max_committed_transaction
在這 4 個變數中,transaction.sequence_number 和 transaction.last_committed 會寫入 binlog,
具體來說,對于 GTID 復制,它們會寫入 GTID_LOG_EVENT;對于非 GTID 復制,則寫入 ANONYMOUS_GTID_LOG_EVENT ,
對于示例中的 7 個事務,記錄在 binlog 中的 last_committed、sequence_number 如下所示:
Trx1: last_committed=0 sequence_number=1
Trx2: last_committed=0 sequence_number=2
Trx3: last_committed=0 sequence_number=3
Trx4: last_committed=1 sequence_number=4
Trx5: last_committed=2 sequence_number=5
Trx6: last_committed=2 sequence_number=6
Trx7: last_committed=5 sequence_number=7
3.3 從庫并行重放的邏輯
下面說說從庫并行重放的邏輯,
從庫引入了一個事務佇列( transaction_sequence ),包含了當前正在執行的事務,
該佇列是有序的,按照事務的 sequence_number 從小到大排列,這個佇列中的事務可并行執行,
一個新的事務能否插入這個佇列,唯一的判斷標準是,事務的 last_committed 是否小于佇列中第一個事務的 sequence_number,只有小于才允許插入,
transaction.last_committed < transaction_sequence[0].sequence_number
最后,回到示例中的 7 個事務,結合 binlog 中的 last_committed 和 sequence_number,我們看看這 7 個事務的并行執行情況,
-
Trx1、Trx2、Trx3 并行執行,
-
Trx1 執行完畢后,Trx4 可加入佇列,
-
Trx2 執行完畢后,Trx5、Trx6 可加入佇列,
-
Trx5 執行完畢后,Trx7 可加入佇列,
不難發現,相對于 Commit-Parent-Based 方案,Lock-Based 方案的并行度確實大大提高了,
3.4 組提交方案小結
無論是 Commit-Parent-Based 方案,還是 Lock-Based 方案,依賴的都是組提交(Group Commit),
組提交方案有以下兩個特點:
1、適用于高并發場景,因為只有在高并發場景下,才會有更多的事務放到一個組(Group)中提交,
2、在級聯復制中,層級越深,并行度越低,
針對低并發場景,如果要提升從庫的并行效率,可調整以下兩個引數:
binlog_group_commit_sync_delay
binlog 刷盤(fsync)之前等待的時間,單位微秒,默認為 0,不等待,
該值越大,一個組內的事務就越多,相應地,從庫的并行度也就越高,但該值越大,客戶端的回應時間也會越長,
binlog_group_commit_sync_no_delay_count
在 binlog_group_commit_sync_delay 時間內,允許等待的最大事務數,
如果 binlog_group_commit_sync_delay 設定為 0,則此引數無效,
四、WRITESET 方案
MySQL 8.0 推出了 WRITESET 方案,該方案推出的初衷實際上是為 Group Replication 服務的,主要是用于認證階段(Certification)的沖突檢測,
WRITESET 方案的核心思想是,兩個來自不同節點的并發事務,只要沒修改同一行,就不存在沖突,對于沒有沖突的并發事務,在寫入relay log 中時,可以共享一個 last_committed,
這里的沖突檢測,實際上比較的是兩個事務之間的寫集合(writeset),
注意,writeset 和 WRITESET 兩者的區別,前者指的是事務的寫集合,后者則特指 WRITESET 方案,
4.1 事務寫集合的生成程序
下面來看看事務 writeset 的生成程序,具體步驟如下:
1、首先提取被修改行的主鍵、唯一索引、外鍵資訊,一張表,如果有主鍵和一個唯一索引,則每修改一行,會提取兩條約束資訊:一條針對主鍵,另一條針對唯一索引,針對主鍵的,提取的資訊包括主鍵名、庫名、表名、主鍵值,這些資訊會拼湊為一個字串,
2、計算該字串的哈希值,具體的哈希演算法由 transaction_write_set_extraction 引數指定,
3、將計算后的哈希值插入當前事務的寫集合,
4.2 WRITESET 方案的實作原理
接下來,結合原始碼看看 WRITESET 方案的實作原理,
void Writeset_trx_dependency_tracker::get_dependency(THD *thd,
int64 &sequence_number,
int64 &commit_parent) {
Rpl_transaction_write_set_ctx *write_set_ctx =
thd->get_transaction()->get_transaction_write_set_ctx();
std::vector<uint64> *writeset = write_set_ctx->get_write_set();
#ifndef NDEBUG
/* 空事務的寫集合必須為空 */
if (is_empty_transaction_in_binlog_cache(thd)) assert(writeset->size() == 0);
#endif
/*
判斷一個事務能否使用 WRITESET 方案
*/
bool can_use_writesets =
// 事務寫集合的大小不為 0 或者事務為空事務
(writeset->size() != 0 || write_set_ctx->get_has_missing_keys() ||
is_empty_transaction_in_binlog_cache(thd)) &&
// 事務的 transaction_write_set_extraction 必須與全域設定一致
(global_system_variables.transaction_write_set_extraction ==
thd->variables.transaction_write_set_extraction) &&
// 不能被其它表外鍵關聯
!write_set_ctx->get_has_related_foreign_keys() &&
// 事務寫集合的大小不能超過 binlog_transaction_dependency_history_size
!write_set_ctx->was_write_set_limit_reached();
bool exceeds_capacity = false;
if (can_use_writesets) {
/*
檢查 m_writeset_history 加上事務寫集合的大小是否超過 m_writeset_history 的上限,
m_writeset_history 的上限由引數 binlog_transaction_dependency_history_size 決定
*/
exceeds_capacity =
m_writeset_history.size() + writeset->size() > m_opt_max_history_size;
/*
計算所有沖突行中最大的 sequence_number,并將被修改行的哈希值插入 m_writeset_history
*/
int64 last_parent = m_writeset_history_start;
for (std::vector<uint64>::iterator it = writeset->begin();
it != writeset->end(); ++it) {
Writeset_history::iterator hst = m_writeset_history.find(*it);
if (hst != m_writeset_history.end()) {
if (hst->second > last_parent && hst->second < sequence_number)
last_parent = hst->second;
hst->second = sequence_number;
} else {
if (!exceeds_capacity)
m_writeset_history.insert(
std::pair<uint64, int64>(*it, sequence_number));
}
}
// 如果表上都存在主鍵,則會取 last_parent 和 commit_parent 的較小值作為事務的 commit_parent,
if (!write_set_ctx->get_has_missing_keys()) {
commit_parent = std::min(last_parent, commit_parent);
}
}
if (exceeds_capacity || !can_use_writesets) {
m_writeset_history_start = sequence_number;
m_writeset_history.clear();
}
}
該函式的處理流程如下:
1、呼叫函式時,會傳入事務的 sequence_number,commit_parent(last_committed),這兩個值是基于 Lock-Based 方案生成的,
2、獲取事務的寫集合,可以看到,事務的寫集合是陣列型別,
3、判斷一個事務能否使用 WRITESET 方案,
以下場景不能使用 WRITESET 方案,此時,只能使用 Lock-Based 方案生成的 last_committed,
- 事務沒有寫集合,常見的原因是表上沒有主鍵,
- 當前事務 transaction_write_set_extraction 的設定與全域不一致,
- 表被其它表外鍵關聯,
- 事務寫集合的大小超過 binlog_transaction_dependency_history_size,
4、如果能使用 WRITESET 方案,
4.1、首先判斷 m_writeset_history 的容量是否超標,
具體來說,m_writeset_history + writeset 的大小是否超過 binlog_transaction_dependency_history_size 的設定,
4.2、將 m_writeset_history_start 賦值給變數 last_parent,
m_writeset_history_start 代表不在 m_writeset_history 中最后一個事務的 sequence_number,其初始值為 0,
當引數 binlog_transaction_dependency_tracking 發生變化或清空 m_writeset_history 時,會更新 m_writeset_history_start,
4.3、回圈遍歷事務的寫集合,判斷被修改行對應的哈希值是否在 m_writeset_history 存在,
若存在,則意味著 m_writeset_history 存在同一行的操作,既然是同一行的不同操作,自然就不能并行重放,這個時候,會將 m_writeset_history 中該行的 sequence_number 賦值給 last_parent,
需要注意的是,這里會回圈遍歷完事務的寫集合,畢竟這個事務中可能有多條記錄在 m_writeset_history 中存在,
在遍歷的程序中,會判斷 m_writeset_history 中沖突行的 sequence_number 是否大于 last_parent,只有大于才會賦值,換言之,這里會取所有沖突行中最大的 sequence_number,賦值給 last_parent,
若不存在,則判斷 m_writeset_history 的容量是否超標,若不超標,則會將被修改行的哈希值插入 m_writeset_history,
可以看到,m_writeset_history 是個字典型別,其中 key 存盤的是被修改行的哈希值,value 存盤的是事務的 sequence_number,
5、判斷被操作的表上是否都存在主鍵,
若存在,才會取 last_parent 和 commit_parent 的較小值作為事務的 commit_parent,否則,使用的還是 Lock-Based 方案生成的commit_parent,
6、如果 m_writeset_history 容量超標或者事務不能使用 WRITESET 方案,則會將當前事務的 sequence_number 賦值給m_writeset_history_start,同時清空 m_writeset_history,
4.3 WRITESET 方案的相關引數
下面看看 WRITESET 方案的三個引數,
binlog_transaction_dependency_tracking
指定基于何種方案決定事務的依賴關系,對于同一個事務,不同的方案可生成不同的 last_committed,
該引數有以下取值:
-
COMMIT_ORDER:基于 Lock-Based 方案決定事務的依賴關系,默認值,
-
WRITESET:基于 WRITESET 方案決定事務的依賴關系,
-
WRITESET_SESSION:同 WRITESET 類似,只不過同一個會話中的事務不能并行執行,
transaction_write_set_extraction
指定事務寫集合的哈希演算法,可設定的值有:OFF,MURMUR32,XXHASH64(默認值),
對于 Group Replication,該引數必須設定為 XXHASH64,
注意,若要將 binlog_transaction_dependency_tracking 設定為 WRITESET 或 WRITESET_SESSION,則該引數不能設定為 OFF,
binlog_transaction_dependency_history_size
m_writeset_history 的上限,默認 25000,
一般來說,binlog_transaction_dependency_history_size 越大,m_writeset_history 能存盤的行的資訊就越多,在不出現行沖突的情況下,m_writeset_history_start 也會越小,相應地,新事務的 last_committed 也會越小,在從庫重放的并發度也會越高,
五、壓測結果
接下來,看看 MySQL 官方對于 COMMIT_ORDER,WRITESET_SESSION,WRITESET 這三種方案的壓測結果,
主庫環境:16 核,SSD,1個資料庫,16 張表,共 800w 條資料,
壓測場景:OLTP Read/Write, Update Indexed Column 和 Write-only,
壓測方案:在關閉復制的情況下,在不同的執行緒數下,注入 100w 個事務,開啟復制,觀察不同執行緒數下,不同方案的從庫重放速度,
三個場景下的壓測結果如圖所示,
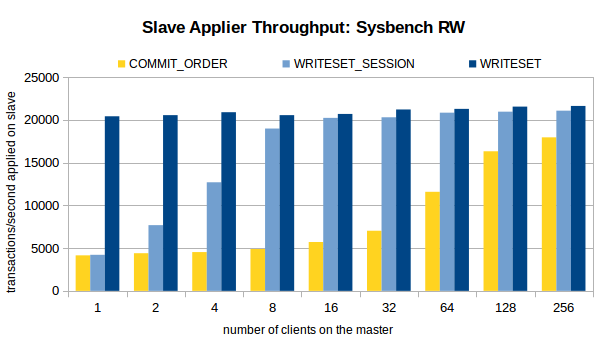
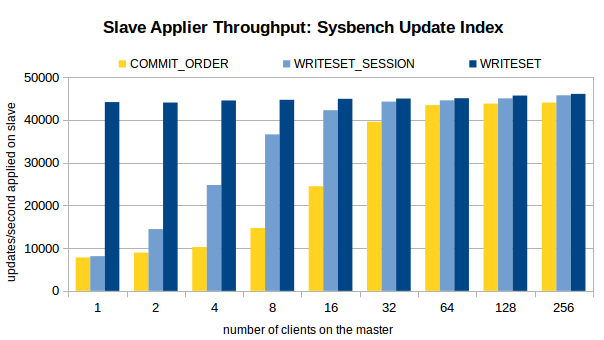
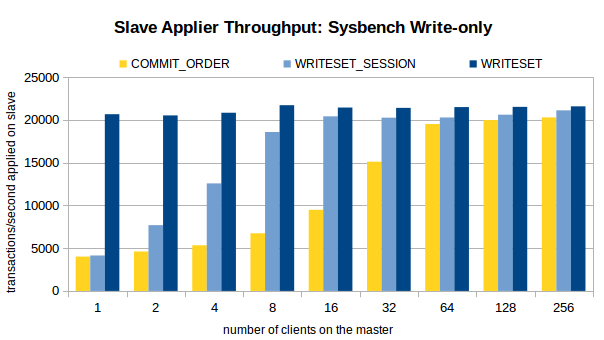
分析壓測結果,我們可以得出以下結論,
1、對于 COMMIT_ORDER 方案,主庫并發度越高,從庫的重放速度越快,
2、對于 WRITESET 方案,主庫的并發執行緒數對其幾乎沒有影響,甚至,單執行緒下 WRITESET 的重放速度都超過了 256 執行緒下的COMMIT_ORDER,
3、與 COMMIT_ORDER 一樣,WRITESET_SESSION 也依賴于主庫并發,只不過,在主庫并發執行緒數較低(4 執行緒、8 執行緒)的情況下,WRITESET_SESSION 也能實作較高的吞吐量,
六、如何開啟并行復制
在從庫上設定以下三個引數,
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 16
slave_preserve_commit_order = ON
下面看看這三個引數的的具體含義,
slave_parallel_type
設定從庫并行復制的型別,該引數有以下取值:
- DATABASE:基于庫級別的并行復制,MySQL 8.0.27 之前的默認值,
- LOGICAL_CLOCK:基于組提交的并行復制,
slave_parallel_workers
設定 Worker 執行緒的數量,開啟了多執行緒復制,原來的 SQL 執行緒將演變為 1 個 Coordinator 執行緒和多個 Worker 執行緒,
slave_preserve_commit_order
事務在從庫上的提交順序是否與主庫保持一致,建議開啟,
需要注意的是,調整這三個引數,需要重啟復制才能生效,
從 MySQL 5.7.22、MySQL 8.0 開始,可使用 WRITESET 方案進一步提升并行復制的效率,此時,需在主庫上設定以下引數,
binlog_transaction_dependency_tracking = WRITESET_SESSION
transaction_write_set_extraction = XXHASH64
binlog_transaction_dependency_history_size = 25000
binlog_format = ROW
注意,基于 WRITESET 的并行復制方案,只在 binlog 格式為 ROW 的情況下才生效,
七、參考資料
1、WL#6314: MTS: Prepared transactions slave parallel applier:https://dev.mysql.com/worklog/task/?id=6314
2、WL#6813: MTS: ordered commits (sequential consistency):https://dev.mysql.com/worklog/task/?id=6813
3、WL#7165: MTS: Optimizing MTS scheduling by increasing the parallelization window on master:https://dev.mysql.com/worklog/task/?id=7165
4、WL#8440: Group Replication: Parallel applier support:https://dev.mysql.com/worklog/task/?id=8440
5、WL#9556: Writeset-based MTS dependency tracking on master:https://dev.mysql.com/worklog/task/?id=9556
6、WriteSet并行復制:https://www.jianshu.com/p/616703533310
7、Improving the Parallel Applier with Writeset-based Dependency Tracking:https://mysqlhighavailability.com/improving-the-parallel-applier-with-writeset-based-dependency-tracking/
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/545994.html
標籤:MySQL