摘要:本文簡單介紹sequence的使用場景及如何修改sequence的cache值提高性能,
本文分享自華為云社區《GaussDB(DWS)關于sequence的那些事》,作者:Arrow0lf ,
什么是sequence
sequence,也稱作序列,是用來產生唯一整數的資料庫物件,序列的值按照一定的規則自增/自減,一般常被用作主鍵,GaussDB(DWS)中,創建sequence時會同時創建一張同名的元資料表,用來記錄sequence相關的資訊,例如:
postgres=# create sequence seq; CREATE SEQUENCE postgres=# select * from seq; sequence_name | last_value | start_value | increment_by | max_value | min_value | cache_value | log_cnt | is_cycled | is_called | uuid ---------------+------------+-------------+--------------+---------------------+-----------+-------------+---------+-----------+-----------+--------- seq | -1 | 1 | 1 | 9223372036854775807 | 1 | 1 | 0 | f | f | 1600007 (1 row)
其中,sequence_name表示sequence的名字,last_value當前無意義,start_value表示sequence的初始值,increment_by表示sequence的步長,max_value表示sequence的最大值,min_value表示最小值,cache_value表示為了快速獲取下一個序列值而預先存盤的sequence值個數(定義cache后不能保證sequence值的連續性,會產生空洞,詳見下文),log_cnt表示WAL日志記錄的sequence值個數,由于在DWS中sequence是從GTM獲取和管理,因此log_cnt無實際意義;is_cycled表示sequence在達到最小或最大值后是否回圈繼續,is_called表示該sequence是否已被呼叫(僅表示在當前實體是否被呼叫,例如在cn_5001上呼叫之后,cn_5001上該原資料表的值變為t,cn_5002上該欄位仍為f),uuid代表該sequence的唯一標識,
GaussDB(DWS)中,通過GTM(Global Transaction Manager,名為全域事務管理器)負責生成和維護全域事務ID、事務快照、Sequence等需要全域唯一的資訊,sequence在DWS中的創建流程如下圖所示:
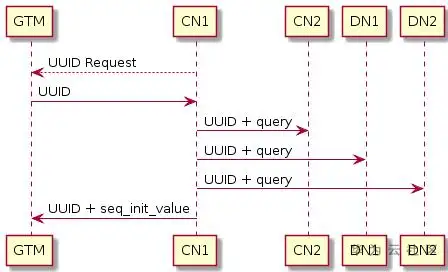
具體程序為:
- 接受SQL命令的CN從GTM申請UUID;
- GTM回傳一個UUID;
- CN將拿到的UUID與用戶創建的sequenceName系結;
- CN將系結關系下發給其他節點上,其他節點同步創建sequence元資料表;
- CN將UUID 和sequence的startID發送到GTM端,在GTM行進行永久保存,
因此,sequence的維護和申請實際是在GTM上完成的,當申請nextval,每個執行nextval呼叫的實體會根據該sequence的uuid到GTM上申請序列值,每次申請的序列值范圍與cache有關,只有當cache消耗完之后才會繼續到GTM上申請,因此,增大sequence的cache有利于減少CN/DN與GTM通信的次數,接下來,將詳細介紹sequence在DWS中的使用場景和注意事項,
如何創建sequence
GaussDB(DWS)中,有兩種創建sequence的方法:
方法一:直接創建sequence,并通過nextval呼叫,舉例:
postgres=# create sequence seq; CREATE SEQUENCE postgres=# insert into t_dest select nextval('seq'),* from t_src; INSERT 0 0
方法二:建表時使用serial型別,會自動創建一個sequence,并且會將該列的默認值設定為nextval,舉例:
postgres=# create table test(a int, b serial) distribute by hash(a); NOTICE: CREATE TABLE will create implicit sequence "test_b_seq" for serial column "test.b" CREATE TABLE postgres=#\d+ test Table "public.test" Column | Type | Modifiers | Storage | Stats target | Description --------+---------+--------------------------------------------------+---------+--------------+------------- a | integer | | plain | | b | integer | not null default nextval('test_b_seq'::regclass) | plain | | Has OIDs: no Distribute By: HASH(a) Location Nodes: ALL DATANODES Options: orientation=row, compression=no
本例中,會自動創建一個名為test_b_seq的sequence,其實嚴格來講,serial型別是一個“偽型別”,本質上,serial其實是int型別,只不過在創建時會同時創建一個sequence,并與該列相關聯,本質上,方法二中的例子與下面的寫法等價:
postgres=# create table test(a int, b int) distribute by hash(a); CREATE TABLE postgres=# create sequence test_b_seq owned by test.b; CREATE SEQUENCE postgres=# alter sequence test_b_seq owner to jerry; --jerry為test表的屬主,如果當前用戶即為屬主,可不執行此陳述句 ALTER SEQUENCE postgres=# alter table test alter b set default nextval('test_b_seq'), alter b set not null; ALTER TABLE postgres=# \d+ test Table "public.test" Column | Type | Modifiers | Storage | Stats target | Description --------+---------+--------------------------------------------------+---------+--------------+------------- a | integer | | plain | | b | integer | not null default nextval('test_b_seq'::regclass) | plain | | Has OIDs: no Distribute By: HASH(a) Location Nodes: ALL DATANODES Options: orientation=row, compression=no
sequence在業務中的常見用法
sequence在業務中常被用作在匯入時生成主鍵或唯一列,常見于資料遷移場景,不同的遷移工具或業務匯入場景使用的入庫方法不同,常見的方法主要可以分為copy和insert,對于seqeunce來講,這兩種場景在處理時略有差別,
場景一:insert下推場景
postgres=# create table test1(a int, b serial) distribute by hash(a); NOTICE: CREATE TABLE will create implicit sequence "test1_b_seq" for serial column "test1.b" CREATE TABLE postgres=# postgres=# create table test2(a int) distribute by hash(a); CREATE TABLE postgres=# postgres=# postgres=# explain verbose insert into test1(a) select a from test2; QUERY PLAN ------------------------------------------------------------------------------------------------ id | operation | E-rows | E-distinct | E-memory | E-width | E-costs ----+------------------------------------+--------+------------+----------+---------+--------- 1 | -> Streaming (type: GATHER) | 1 | | | 4 | 18.41 2 | -> Insert on public.test1 | 40 | | | 4 | 18.25 3 | -> Seq Scan on public.test2 | 40 | | 1MB | 4 | 16.24 Targetlist Information (identified by plan id) --------------------------------------------------------- 1 --Streaming (type: GATHER) Node/s: All datanodes 3 --Seq Scan on public.test2 Output: test2.a, nextval('test1_b_seq'::regclass) Distribute Key: test2.a ====== Query Summary ===== ------------------------------- System available mem: 4669440KB Query Max mem: 4669440KB Query estimated mem: 1024KB Parser runtime: 0.045 ms Planner runtime: 12.622 ms Unique SQL Id: 972921662 (22 rows)
由于在nextval在insert場景下可以下推到DN執行,因此,不管是使用default值的nextval,還是顯示呼叫nextval,nextval都會被下推到DN執行,在上例的執行計劃中也能看出,nextval的呼叫在sequence層,說明是在DN執行的,此時,DN直接向GTM申請序列值,且各DN并行執行,因此效率相對較高,
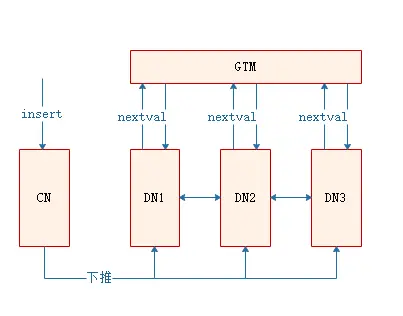
場景二:copy場景
在業務開發程序中,入庫方式除了insert外,還有copy入庫的場景,此類場景多見于將檔案內容copy入庫、使用CopyManager介面入庫等,此外,CDM資料同步工具,其實作方式也是通過copy的方式批量入庫,在copy入庫程序中,如果copy的目標表使用了默認值,且默認值為nextval,處理程序如下:
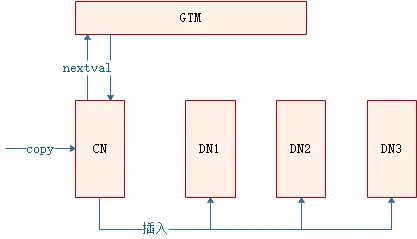
此場景下,由CN負責向GTM申請序列值,因此,當sequence的cache值較小,CN會頻繁和GTM建聯并申請nextval,出現性能瓶頸,下面,將針對此種場景說明業務上的性能表現和優化方法,
sequence相關的典型優化場景
業務場景:某業務場景使用CDM資料同步工具做資料遷移,從源端入庫目標端GaussDB(DWS),匯入速率與經驗值相差較大,業務將CDM并發從1調整為5,同步速率仍無法提升,查看陳述句執行情況,除copy入庫外,其余業務均正常執行,無性能瓶頸,且觀察無資源瓶頸,因此初步判斷為該業務自身存在瓶頸,查看該表copy相關的作業等待視圖情況:
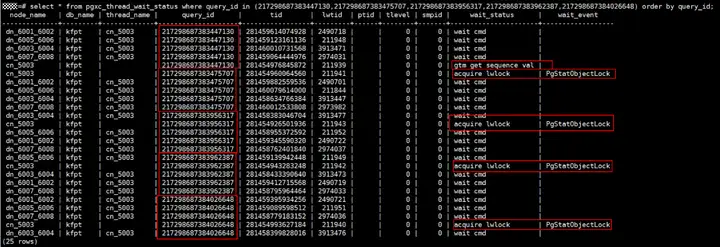
如圖所示,由于CDM作業起了5個并發,因此在活躍視圖中可以看到5個copy陳述句,根據這5個copy陳述句對應的query_id查看等待視圖情況如上圖所示,可以看到,這5個copy中,同一時刻,僅有1個copy在向GTM申請序列值,其余的copy在等待輕量級鎖,因此,即使作業中開啟了5并發在運行,實際效果比1并發并不能帶來明顯提升,
問題原因:目標表在建表時使用了serial型別,默認創建的sequence的cache為1,導致在并發copy入庫時,CN頻繁與GTM建聯,且多個并發之間存在輕量鎖爭搶,導致資料同步效率低,
解決方案:此種場景下可以調大sequence的cache值,防止頻繁GTM建聯帶來的瓶頸,本例中,業務每次同步的資料量在10萬左右,綜合其他適用場景評估,將cache值修改為10000(實際使用時應根據業務設定合理的cache值,既能保證快速訪問,又不會造成序列號浪費),
當前GaussDB(DWS)不支持通過alter sequence的方式修改cache值,那么如何修改已有sequence的cache值呢?已第二節中方法二的test表為例,可以通過如下方式達到修改cache的目的:
-- 解除當前sequence與目標表的關聯關系 alter sequence test_b_seq owned by none; alter table test alter b drop default; -- 記錄當前的seqeunce值并洗掉sequence select nextval('test_b_seq'); --記錄該值,作為新建sequence的start value drop sequence test_b_seq; -- 新建seqeunce并系結目標表 create sequence test_b_seq START with xxx cache 10000 owned by t.b; -- xxx替換為上一步查到的nextval alter sequence test_b_seq owner to jerry; --jerry為test表的屬主,如果當前用戶即為屬主,可不執行此陳述句 alter table test alter b set default nextval('test_b_seq'), alter b set not null;
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/545999.html
標籤:其他