更好地提高效率一直以來是袋鼠云數堆疊產品的主要目標之一,當前數堆疊客戶的實時任務都是基于 Per-Job 模式運行的,客戶在進行一些任務引數的修改之后,只能先取消當前任務,再選擇 CheckPoint 恢復或者重新運行,整個程序需要3-5分鐘,比較浪費時間,為了達到提高效率的目的,我們針對 Per-Job 任務的整體流程分析,進行了相關探索,
下文和大家聊聊數堆疊在熱重啟技術方面的探索之路,
熱重啟是什么?
熱重啟技術旨在復用當前 Per-Job 集群的相關資源,減少重新創建集群以及申請資源的耗時,同時通過 CheckPoint 機制保障資料的正確性,
Flink 的 Per-Job 模式是指每個任務都會對應一個獨立的 Flink 集群,在任務提交的時候,會創建一個 Flink 集群進行任務的運行,整個集群只為這一個任務進行服務,同時 Flink 集群不允許繼續提交任務,導致任務修改之后,只能 Cancel 當前任務,重新提交修改后的任務,創建一個新的 Flink 集群進行運行,
經過分析,耗時主要是由于以下兩部分原因造成:
? Client 需要在 Yarn 上啟動一個 Flink 集群,這一部分是客戶端耗時最多的部分,因為這一部分包括上傳 jar,上傳檔案到Hdfs 上,申請資源啟動 Flink 集群,都是比較耗時的步驟
? 集群運行的時候需要申請資源等操作也十分耗時
我們思考如果僅僅是一些任務引數或者 Sql 邏輯的修改,而不涉及代碼上的修改,那么 PerJob 任務是否可以類似 Session 模式進行改造,支持 JobGraph 的重新提交,解決 Client 需要啟動一個 Flink 集群的耗時問題,大大提高提交效率,
同時復用了整個 Flink 集群的資源,如果并行度改變,只需要申請新增加的資源,已有的資源不需要再重復向 Yarn 的 Resourcemanager 申請,
熱重啟改造后的流程
Flink 中 Per-Job 任務運行的整體流程大概如下所示:
客戶端流程
? Client 端創建 JobGraph
? 上傳 JobGraph 到 hdfs 里
? 通過 YarnClient 提交一個 YarnApplication,運行一個 Flink 任務
? 獲取結果
Flink 集群流程
? 啟動 Flink 集群,啟動 WebMonitor,ResourceManager,Dispatcher 組件
? Client 端上傳到遠程檔案服務里的 JobGraph 會被反序列出來由 DIspatcher 持有;
? DIspatcher 會根據此 JobGraph 創建 JobManagerRunner 物件進行運行;
? JobManagerRunner 會交由內部的 ScheduleNg 進行調度運行任務:
a.構建 ScheduleNg 時,會將 JobGraph 轉為ExecutionGraph
b. ScheduleNg 根據 ExecutionGraph 進行調度,運行任務
? 任務運行,等待任務運行結束,進行相應的回呼處理
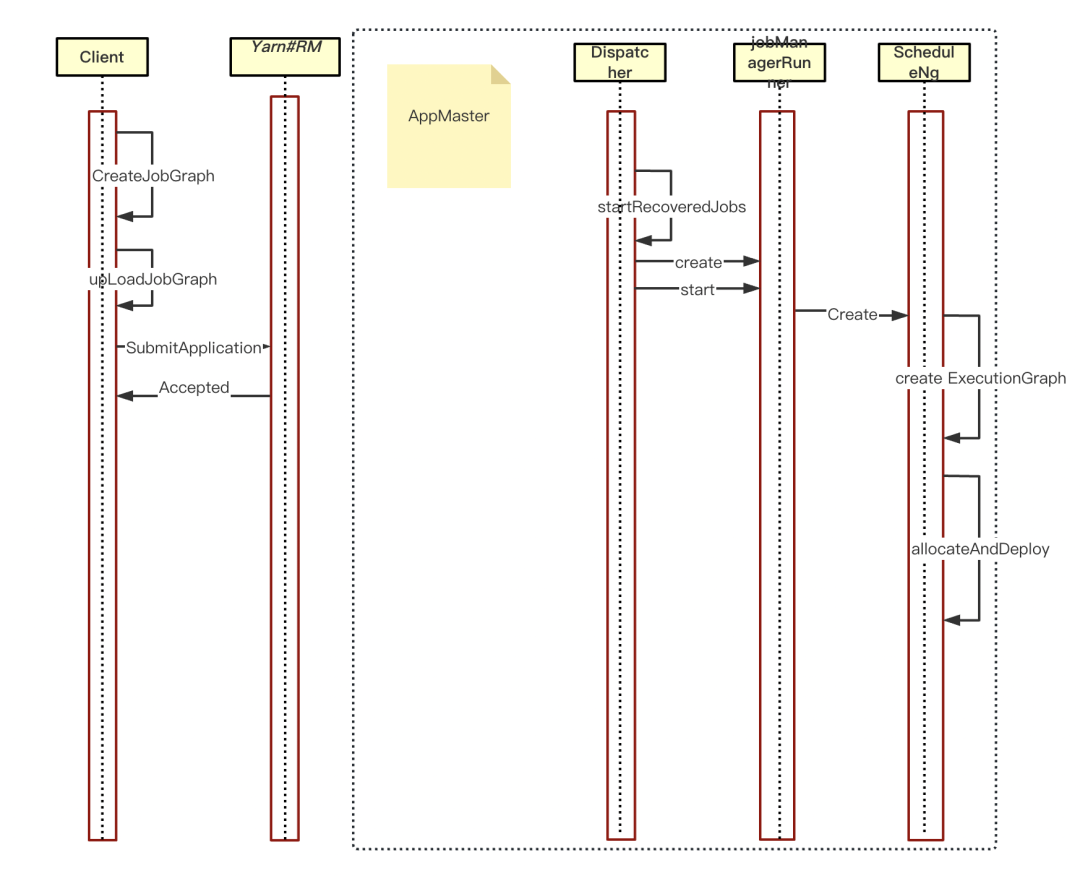
從上圖我們可以看出,一個 Per-Job 任務的運行主要包括兩部分:一部分是客戶端上傳檔案 jar 等操作后,直接上傳任務到 Yarn 上進行 Flink 任務的啟動,第二部分是Flink集群的啟動,然后對客戶端上傳到遠程檔案的 JobGraph 進行處理,因此為了優化 Per-Job 下的效率,我們對這兩部分進行了改造,
想法邏輯是,集群首先改造支持 JobGraph 的重新提交,然后 DIspatcher 處理 JobGraph 的時候,不會創建新的 JobMaster ,而是將當前現有的 JobGraph 里的一些資訊填充到新的 JobGraph 里,比如當前任務的 CheckPoint 資訊等,任務最終的調度運行是 JobMaster 里的 ScheduleNg 物件,因此我們認為只需要將 ScheduleNg 重新構建,其余的組件都可以復用,
下圖即為我們熱重啟技術改造后的一個大致流程:
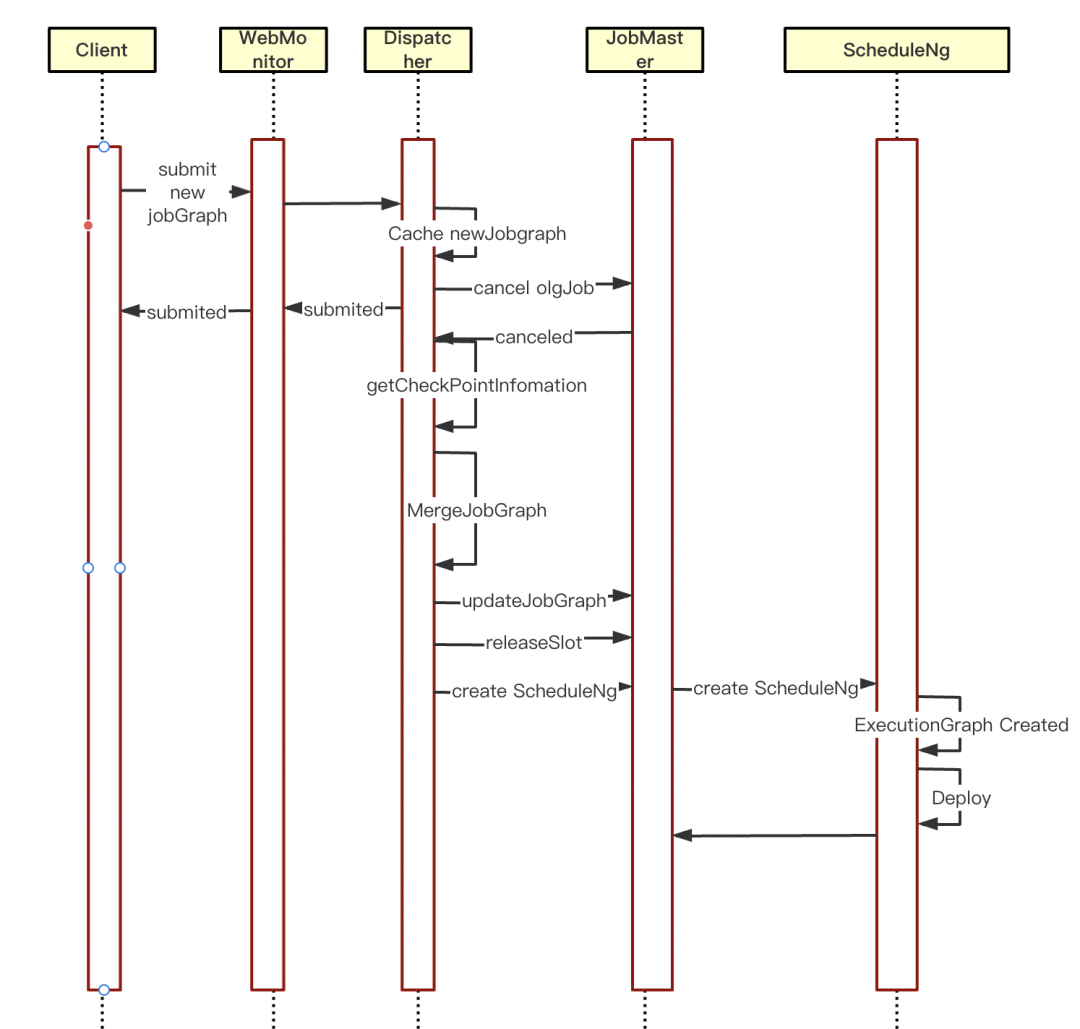
熱重啟技術改造后流程
? WebMonitor 支持任務的提交
? DIspatcher 將新的 JobGraph 快取
? 取消當前任務,等待異步回呼
? 回傳結果給客戶端
? 在任務取消的異步回呼里主要是熱重啟的重點改造部分:
a.判斷當前是否有新的 JobGraph 快取,有的話進入熱重啟邏輯,無則走當前現有邏輯
b.獲取取消任務的 CheckPoint 資訊,填充到新的 JobGraph 里
c.將 jobGrap 更新到 JobMaster 里,清理以前 JobGraph 的快取資訊
d.把 JobMaster 里 SlotPool 管理的資源釋放掉
e.JobMaster 重新創建 ScheduleNg 并調度運行,至此新的 JobGraph 就被成功調度運行了
熱重啟改造部分詳解
JobGraph 介紹
在上述流程中,JobGraph 是整體流轉的主要物件,后續的一切操作都是圍繞著 JobGraph 進行處理,所以這里先對 JobGraph 進行介紹,
JobGraph 是 Flink 作業的內部表示,是一個有向無環圖(DAG),主要是將一些可以優化的算子節點合并為一個節點,從下圖可知,一個完整的 JobGraph 圖包含了 Source Sink Transform 節點,以及節點的輸出 IntermrdiateDataset 和輸入邊 JobEdge ,在除了 Application 模式外,其余的提交模式下,JobGraph 是在 Client 創建的,然后通過 Rest 請求提交給 Flink 集群進行處理,

看完 JobGraph 此類結構,可以得出以下這些資訊:
· taskVertices:上圖中的每個頂點對應一個 jobVertex,taskVertices 維護了 jobGraph 圖里的各個 jobVertex
· snapshotSettings:checkponit 相關的配置資訊,如 CheckPoint 的間隔時間等
· savepointRestoreSettings:任務恢復的 checkpoint 檔案資訊,熱重啟中,新的 jobGraph 會將上一個任務的 checkPoint 位點資訊填充到這個引數里,新的任務會在 CheckPoint 位點處進行恢復運行
· jobConfiguration:整個 job 的相關配置資訊
· userJars & calsspath:任務運行程序中需要的一些 jar 以及 classpath 相關資訊
其中 JobVertex 是 jobGraph 里非常重要的物件,再看下此類結構:JobVertex 主要存盤了JobEdge以及 IntermediateDataSet 和并行度等相關資訊,對于一個 JobVertex 來說,IntermediateDataSet 是作為 JobVertex 的輸出,而 JobEdge 是其輸入,

WebMonitor 改造
WebMonitor 組件是 Flink 的 Web 端點,可以通過 Rest Api 進行 Flink 集群的狀態、任務、指標等資訊的查詢,同時支持任務的提交、取消、觸發 SavePoint 等操作,
Per-Job 模式下 Flink 集群是不支持客戶端繼續提交任務運行的,因此需要對 WebMonitor 進行改造,類似 Session 下支持同一個 Flink 集群能繼續提交 JobGraph 并運行,
從下圖可以看出 WebMonitor 組件啟動時,其本質是 Netty 為核心的一個 Web 端點,啟動時的主要流程如下:
? 創建 Router,管理 http 請求和處理器 handler 的映射關系
? initializeHandlers 初始化所有的 handler,不同的集群對應的 WebMonitor 提供的 API 功能不同,所以 handlers 也是不同的
? 將 handlers 注冊到 router,完成 URL 以及請求方式(GET,POST,DELETE,PUT)和 Handler 的映射關系
? 創建一個 Netty 的 handler,包裝下 router,然后注冊到 Netty 的 pipeline 里

WebMonitor 支持的各種 Rest 請求其實最終是交給一個個的 handler 進行處理,通過 Router 對這些 handler 進行維護,其內部維護了一個 url 以及 Rest 請求方式與 handler 的映射關系,接收 Client 端的 Rest 請求之后,Router 找到對應的處理器 handler,交由 handler 進行最終的處理并回傳結果,
因為 Per-job 集群是不支持 Client 端繼續提交任務的,所以其 initializeHandlers 方法初始化出的 handlers 不包含處理任務提交的 handler,導致 router 找不到對應的 handler 報錯,因此需要在 initializeHandlers 里將處理任務提交的 handler 注冊進去 ,
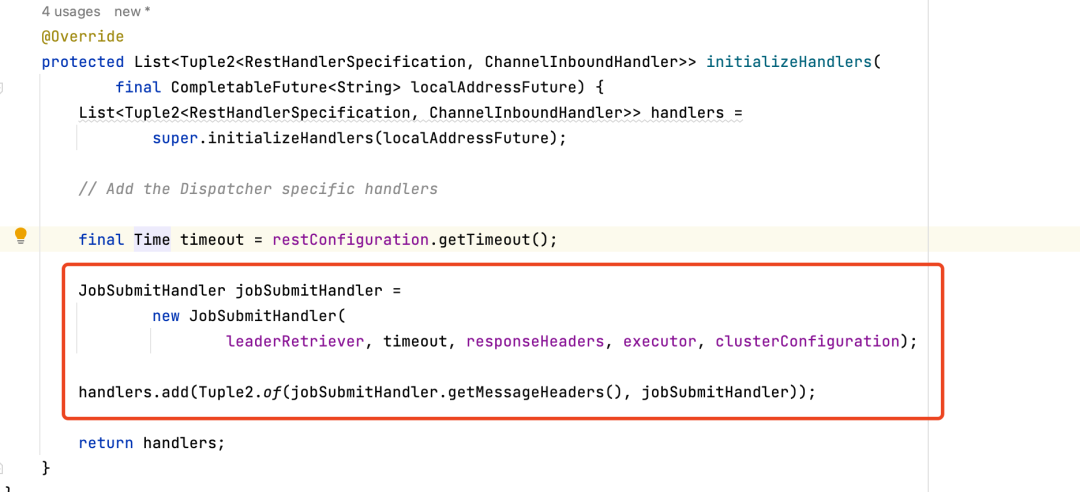
JobSubmitHandler 處理請求的主要邏輯如下圖所示,核心是從 Rest 請求的 Body 里反序列化得到 JobGraph,反序列化獲取的 Jobgraph 通過 DIspatcherGateway 發送給 Dispatcher 進行后續提交處理,

這樣 Client 端只需要重新生成 JobGraph 然后提交即可,避免了重新上傳 jar 到 hdfs,以及避免浪費重新向 yarn 集群申請資源啟動 AppMaster 的時間,
Dispatcher 改造
DisPatcher 顧名思義是一個分發器,其主要功能是 Flink 集群接收到關于 Job 的提交、取消、觸發 SavePoint 等操作,分發到對應的各個 JobMaster 進行處理,或者創建新的 JobMaster 進行任務的運行,
DisPatcher 處理任務提交的核心流程是根據 JobGraph 創建一個 JobManagerRunner 物件并啟動,然后將其包裝成一個 DispatcherJob 快取在內部,任務的具體調度執行交由創建的 JobManagerRunner 進行異步處理,
JobManagerRunner 其內部的具體操作其實是 JobMasterService,主要實作類就是 JobMaster,JobMaster 內部有兩個主要物件分別是:
· ScheduleNg: 負責 JobGraph 轉為 ExecutionGraph,然后對 Job 進行調度運行
· SlotPool:負責 Slot 資源的申請以及管理
以上便是 Dispatcher 處理的主要流程,當前改造之后只是支持了任務的重新提交運行,但是新的任務仍然是對應一個新的 JobMaster,其實就是一個類似 Session 的處理,所以為了達到熱重啟的效果,需要進行以下的改造,
主流程的改造邏輯如下:
? 增加了一個 hotRestartJobGraph 欄位,將新的 JobGraph 物件賦予此欄位
? Dispatcher 將快取的正在運行的任務 cancel,對異步回傳結果進行回呼處理
? 直接回傳 Client 結果
因為 Flink 整體是異步處理的,原始碼里充滿了大量的 CompletableFuture 回呼的處理,主流程僅僅對提交的 JobGraph 進行了一個快取處理,熱重啟的主要步驟在任務取消的回呼里進行處理:
? 判斷 hotRestartJobGraph 是否為空,如果不為空則進行熱重啟處理,為空則用以前的邏輯,整個 Per-job 集群關閉
? 獲取取消任務的最后一個 CheckPoint 位點
? 將 CheckPoint 位點資訊填充到新的 Jobgraph 里
? 反射將上一個 Jobgraph 生成的 JobManagerRunner 和 jobMaster 兩個物件的JobGraph 欄位用新的 JobGraph 替換掉
? jobMaster 物件根據 jobGraph 重新生成 scheduleNg 進行調度運行
? jobMaster 的 slotPool 在心跳周期內,會快取已經釋放掉的 slot,需要把這部分快取清空
? MiniDispatcher 的 close 方法修改下,如果 hotRestartJobGraph 不為空則不進行集群的關閉
? hotRestartJobGraph 置空
注意上述只是主要的一些改造地方,其余一些邊緣的細節處理就不再進行贅述,
所以在熱重啟中,DIspatcher 是不會對每一個 JobGraph 創建新的 JobMaster 物件,通過將新的 JobGraph 更新到 JobMaster 里,內部僅僅 ScheduleNg 進行了重新構建,其余的組件都進行了復用,比如 SlotPool,
ScheduleNg 之所以需要重新構建是因為 JobGraph 轉為 ExecutionGraph 是需要 ScheduleNg 在構建的時候創建的,因此需要重新構建一個 ScheduleNg 進行任務的調度執行,這樣達到了整個資源的復用性,大大提升了效率,
Slot 資源的復用
Flink 中對于資源的抽象主要是 Slot,其各個組件對 Slot 的管理是由不同的組件處理的:
· Flink 的 ResourceManager 里是 SlotManager 管理,主要是任務的資源申請以及管理
· JobMaster 里管理 Slot 是 SlotPool ,主要是對當前任務申請的 slot 進行管理
· TaskExecutor 里則是S lotTable 對 Slot 進行管理,維護 JobId 和 Slot 的關系
在熱重啟中,上一個任務取消之后,JobMaster 里 SlotPool 管理的 Slot 狀態由已分配改為可用,這樣在 JobMaster 通過新的 ScheduleNg 進行重新調度,會復用 SlotPool 里快取的 Slot,這個時候其實是有問題的,在 TaskExecutor 接收到任務的時候會報錯,在其內部的 JobTable 里找不到新任務的 JobId,因為此時 TaskExecutor 維護的 Jobid 還是上一個任務的,
所以 JobMaster 的 SlotPool 需要釋放掉其內部快取資訊,注意只是清理內部快取,此時 TaskManager 的 Slot 槽資源還沒被釋放,仍然被 Resourcemanager 的 SlotManager 管理著,這樣 SlotPool 發現內部沒可用的 Slot 槽就會和 ResourceManager 的 SlotManager 申請資源,SlotManager 就仍然復用了以前的 Slot 槽并且將新的 JobGraph 的 jobId 通過 rpc 請求注冊進了 TaskExecutor,從而達到了 slot 槽資源的復用,減少了 Flink 集群的 ResourceManager 重新向 Yarn 的 ResourceManager 申請資源,
總結
數堆疊在 Per-job 模式下,為了盡快看到任務修改后的效果,在業務允許情況下,通過熱重啟技術復用相關資源,減少了大量時間,極大地提高了效率,在開發驗證中,以前一個任務等待任務結束以及重新提交運行總流程超過4分鐘,但是在熱重啟情況下控制在1分鐘以內就已經可以進行調度執行,
未來我們將會把熱重啟的場景進一步豐富,支持更多場景下的熱重啟技術,如 jar 的代碼修改,如何更新環境里的 jar,支持 k8s 場景等,
袋鼠云一直以來高度重視產品升級和用戶體驗,用誠心傾聽用戶需求,新的一年我們將繼續保持產品升級節奏,以提效為目標滿足不同行業用戶的更多需求,為了更好的產品,更佳的用戶體驗,數堆疊一直在路上,
《資料治理行業實踐白皮書》下載地址:https://fs80.cn/380a4b
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/archive/2023/03/09/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/546382.html
標籤:其他