資料湖作為新一代大資料基礎設施,近年來持續火熱,許多前線的同學都在討論資料湖應該怎么建,許多企業也都在構建或者計劃構建自己的資料湖,基于此,自然引發了許多關于資料湖選型的討論和探究,但是經過搜索之后我們發現,網上現存的很多內容都是基于較早之前的開源資訊做出的結論,在企業調研初期容易造成不準確的印象和理解,
因此帶著這樣的問題,我們計劃推出資料湖選型系列文章,基于最新的開源資訊,從升級資料湖架構的幾個重要緯度幫助大家進行深度對比,希望能拋磚引玉,引起大家一些思考和共鳴,歡迎同學們一起探討,
實踐程序中我們發現,在計劃升級資料湖架構的客戶中,支持資料的事務更新通常是大家的第一基礎訴求,因此,該系列的第一篇內容我們將從需求的誕生背景,以及不同資料湖架構在資料事務上的能力對比,兩個方面幫助大家在資料湖選型之路上做出更好的決定,
需求背景
在傳統的 Hive 離線數倉架構下,資料更新的成本是非常大的,更新一條資料需要重寫整個磁區甚至整張表,因此在真實業務場景中,出于開發成本、資料風險等方面的考慮,大家都不會在 Hive 數倉中更新資料,
不過隨著 Hive 3.0 的推出,Hive 表在事務能力上也向前邁了一大步,官方在推出 3.0 時也重點宣傳了它的事務能力,不過在實際應用中仍然存在非常大的限制,真實投產的用戶寥寥無幾,(僅支持ORC事務內表,這意味著像Spark這類計算引擎,無法直接在Hive事務表上進行ETL/ELT開發,包括像CDH、袋鼠云公司都在Spark兼容上做過投入,但是效果不佳,遠達不到生產級的應用預期)
因此,在資料湖選型程序中,高效的并發更新能力就顯得尤為重要,它能夠改變我們在 Hive 數倉中遇到的資料更新成本高的問題,支持對海量的離線資料做更新洗掉,
資料更新實作的選型
目前市面上核心的資料湖開源產品大致有這么幾個:Apache Iceberg、Apache Hudi和 Delta,
本文將為大家重點介紹 Hudi 和 Iceberg 在資料更新實作方面的表現,
Hudi 的資料更新實作
Hudi(Hadoop Update Delete Incremental),從這個名稱可以看出,它的誕生就是為了解決 Hadoop 體系內資料更新和增量查詢的問題,要想弄明白 Hudi 是如何在 HDFS 這類檔案系統上實作快速 update 操作的,我們需要先了解 Hudi 的幾個特性:
· Hudi 表的檔案組織形式:在每個磁區(Partition)內,資料檔案被切分組織成一個個檔案組(FileGroup),每個檔案組都已 FileID 進行唯一標識,
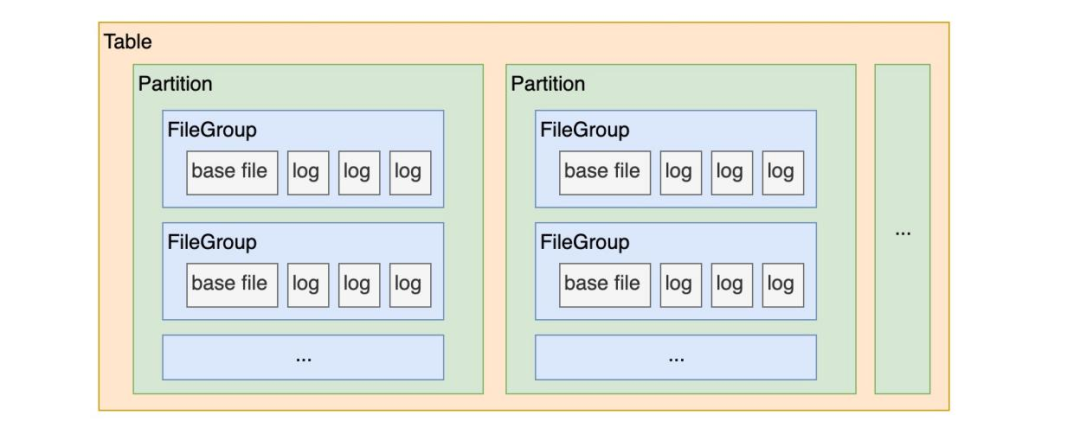
· Hudi 表是有主鍵設計的,每條資料都已主鍵進行唯一標識,
· Hudi 表是有索引設計的,
結合上面的三個特性可以得出,Hudi 表的索引可以幫助我們快速地定位到某一條資料存在于某個磁區的某個檔案組中,然后對其進行 Update 操作,即重寫這部分檔案組,
Iceberg 的資料更新實作
Iceberg 的官方定位是「面向海量資料分析場景的高效存盤格式」,所以它沒有像 Hudi 一樣模擬業務資料庫的設計模式(主鍵+索引)來實作資料更新,而是設計了更強大的檔案組織形式來實作資料的 update 操作,詳見下圖:
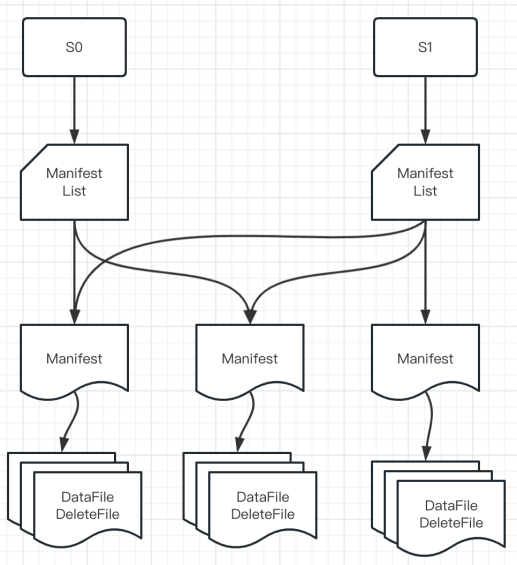
? Snapshot:用戶的每次 commit 會產生一個新的 snapshot
? Manifest List:維護當前 snapshot 中所有的 manifest
? Manifest:維護當前 Manifest 下所有的 data files 和 delete files
? Data File:存盤資料的檔案
? Delete File:存盤「洗掉的資料」的檔案
在上面的檔案組織基礎上,我們可以看出,Iceberg 實作 update 的大致邏輯是:
· 先將要洗掉的資料寫入 Delete File;
· 然后將「Data File」 JOIN 「Delete File」進行資料比對,實作資料更新,
當然,實作這兩步有很多技術細節:比如利用 Sequence Number 保障事務順序;Delete File 根據洗掉時的檔案狀態判斷是走 position delete 還是 equality delete 邏輯;引入 equality_ids 概念模擬主鍵等,
如何選擇
單純從資料更新能力這個角度來看:
· Hudi 憑借檔案組+索引+主鍵的設計模式,能夠有效減少資料檔案的冗余更新,提高資料更新效率,
· Iceberg 通過檔案組織設計也能達到資料更新效果,但是每一次的 commit 都會產生新的檔案,如果寫入/更新頻繁,小檔案問題會比較嚴重,(雖然官方也配套提供了小檔案治理能力,但是這部分的資源消耗、治理難度相對 Hudi 來說會比較大)
如何實踐應用
當我們確定了資料湖選型后,如何在生產環境中進行實踐應用就成為了下一個問題,
這里就需要提前了解表型別這個概念,同一種資料湖表格式也有不同的型別區別,分別適用不同的場景:
? COW(Copy On Write):寫時復制表,在資料寫入/更新時,立即重寫原有資料檔案,生成一份新的資料檔案,
? MOR(Merge On Read):讀時合并表,在資料寫入/更新時,不修改原有檔案,寫入新的日志/檔案,在之后資料被讀取到的時候,重寫資料檔案,
基于這兩種表型別的特性差異,我們給出如下建議:
· 如果你的湖表寫入/更新不頻繁,主要用于支撐資料查詢/分析場景,那建議使用 COW 表,
· 如果你的湖表寫入/更新頻繁(甚至是用于實時開發場景的寫入),那建議使用 MOR 表,
總結
沒有最好的技術架構,只有最適合當前業務的技術架構,
關于資料湖的選型當然也不能簡單從資料更新能力這一單一緯度做出判斷,后續我們將繼續推出不同資料湖架構在 Schema 管理、查詢加速、批流一體等更多緯度的對比內容,歡迎大家和我們一起探討交流,
同時,袋鼠云也有自己的資料湖倉一體化構建平臺 EasyLake,提供面向湖倉一體的資料湖管理分析服務,基于統一的元資料抽象構建一致性的資料訪問,提供海量資料的存盤管理和實時分析處理能力,
《資料治理行業實踐白皮書》下載地址:https://fs80.cn/380a4b
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/archive/2023/03/17/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/547220.html
標籤:其他