1. 按照現在的SQL標準來說,HAVING子句是可以單獨使用的
1.1. 就不能在SELECT子句里參考原來的表里的列了
1.1.1. 使用常量
1.1.2. 使用聚合函式
1.2. WHERE子句用來調查集合元素的性質,而HAVING子句用來調查集合本身的性質
2. 表不是檔案,記錄也沒有順序,所以SQL不進行排序
3. GROUP BY子句可以用來生成子集
3.1. SQL通過不斷生成子集來求得目標集合
3.2. SQL不是面向程序語言,沒有回圈、條件分支、賦值操作
3.3. SQL通過不斷生成子集來求得目標集合
3.4. SQL不像面向程序語言那樣通過畫流程圖來思考問題,而是通過畫集合的關系圖來思考
4. 示例
4.1. -- 查詢缺失編號的最小值
SELECT MIN(seq + 1) AS gap
FROM SeqTbl
WHERE (seq+ 1) NOT IN ( SELECT seq FROM SeqTbl);
5. 求眾數
5.1. 在群體中出現次數最多的值
5.2. 示例
5.2.1.
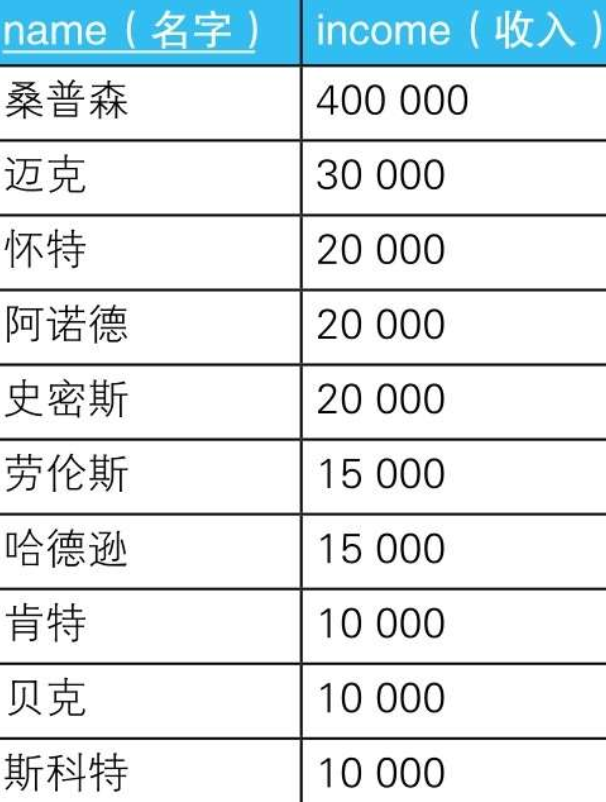
5.2.1.1. --求眾數的SQL陳述句(1):使用謂詞
SELECT income, COUNT(*) AS cnt
FROM Graduates
GROUP BY income
HAVING COUNT(*) >= ALL ( SELECT COUNT(*)
FROM Graduates
GROUP BY income);
5.2.1.1.1. ALL謂詞用于NULL或空集時會出現問題
5.2.1.2. --求眾數的SQL陳述句(2):使用極值函式
SELECT income, COUNT(*) AS cnt
FROM Graduates
GROUP BY income
HAVING COUNT(*) >= ( SELECT MAX(cnt)
FROM ( SELECT COUNT(*) AS cnt
FROM Graduates
GROUP BY income) TMP ) ;
5.2.1.2.1. 用極值函式來代替
6. 求中位數
6.1. 將集合中的元素按升序排列后恰好位于正中間的元素
6.2. 如果集合的元素個數為偶數,則取中間兩個元素的平均值作為中位數
6.3. 示例
6.3.1. --求中位數的SQL陳述句:在HAVING子句中使用非等值自連接
SELECT AVG(DISTINCT income)
FROM (SELECT T1.income
FROM Graduates T1, Graduates T2
GROUP BY T1.income
--S1的條件
HAVING SUM(CASE WHEN T2.income >= T1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2
--S2的條件
AND SUM(CASE WHEN T2.income <= T1.income THEN 1 ELSE 0 END)
>= COUNT(*) / 2 ) TMP;
6.3.1.1. 加上等號并不是為了清晰地分開子集S1和S2,而是為了讓這2個子集擁有共同部分
6.3.1.2. 如果去掉等號,將條件改成“>COUNT(*)/2”,那么當元素個數為偶數時,S1和S2就沒有共同的元素了,也就無法求出中位數了
6.3.1.3. 如果事先知道集合的元素個數是奇數,那么因為FROM子句里的子查詢結果只有一條資料,所以外層的AVG函式可以去掉
7. 查詢不包含NULL的集合
7.1. COUNT(*)和COUNT(列名)
7.1.1. 性能上的區別
7.1.2. COUNT(*)可以用于NULL
7.1.3. COUNT(列名)與其他聚合函式一樣,要先排除掉NULL的行再進行統計
7.1.4. COUNT(*)查詢的是所有行的數目,而COUNT(列名)查詢的則不一定是
7.2. 示例1
7.2.1. --在對包含NULL的列使用時,COUNT(*)和COUNT(列名)的查詢結果是不同的
SELECT COUNT(*), COUNT(col_1)
FROM NullTbl;
7.3. 示例2
7.3.1.
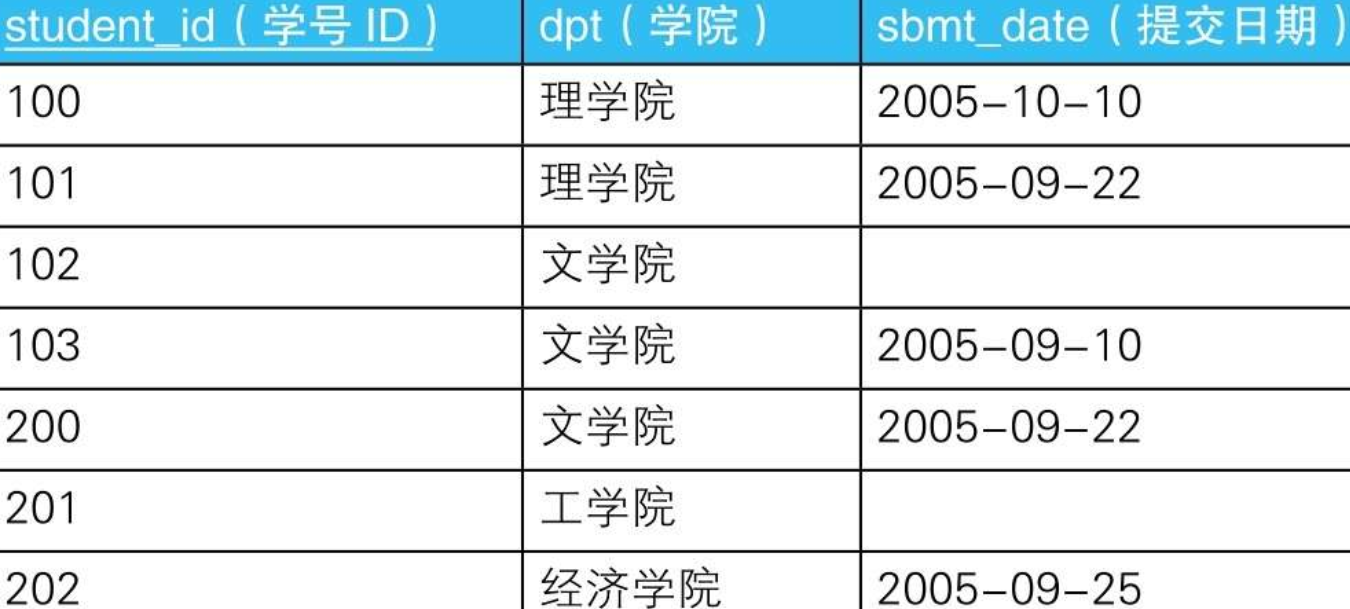
7.3.1.1. --查詢“提交日期”列內不包含NULL的學院(1):使用COUNT函式
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*) = COUNT(sbmt_date);
7.3.1.2. --查詢“提交日期”列內不包含NULL的學院(2):使用CASE運算式
SELECT dpt
FROM Students
GROUP BY dpt
HAVING COUNT(*) = SUM(CASE WHEN sbmt_date IS NOT NULL
THEN 1
ELSE 0 END);
7.3.1.2.1. CASE運算式的作用相當于進行判斷的函式,用來判斷各個元素(=行)是否屬于滿足了某種條件的集合
7.3.1.2.1.1. 特征函式(characteristic function)
8. 關系除法運算
8.1. 示例1
8.1.1.
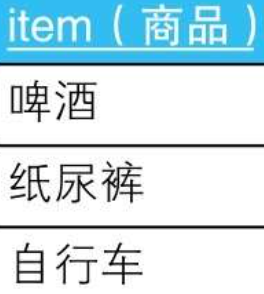
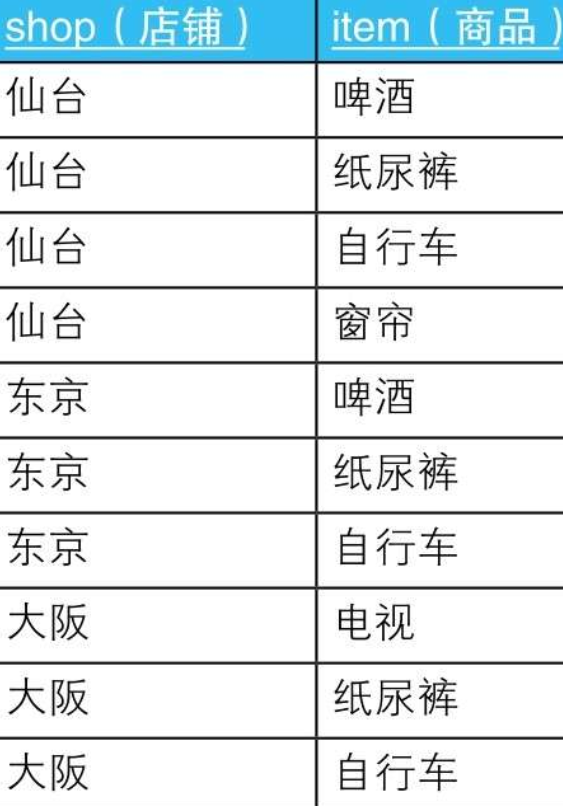
8.1.2. --查詢啤酒、紙尿褲和自行車同時在庫的店鋪:錯誤的SQL陳述句
SELECT DISTINCT shop
FROM ShopItems
WHERE item IN (SELECT item FROM Items);
8.1.2.1. --查詢啤酒、紙尿褲和自行車同時在庫的店鋪:正確的SQL陳述句
SELECT SI.shop
FROM ShopItems SI, Items I
WHERE SI.item = I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items);
8.1.2.1.1. HAVING子句的子查詢(SELECT COUNT(item) FROM Items)的回傳值是常量3
8.1.3. 帶余除法”(division with a remainder)
8.2. 示例2
8.2.1. “精確關系除法”(exact relational division)
8.2.2. --精確關系除法運算:使用外連接和COUNT函式
SELECT SI.shop
FROM ShopItems SI LEFT OUTER JOIN Items I
ON SI.item=I.item
GROUP BY SI.shop
HAVING COUNT(SI.item) = (SELECT COUNT(item) FROM Items) --條件1
AND COUNT(I.item) = (SELECT COUNT(item) FROM Items); --條件2
8.3. 在SQL里,交叉連接相當于乘法運算
8.3.1. 關系除法運算是關系代數中知名度最低的運算
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/549256.html
標籤:其他