1 引言
在日常作業中,我們會遇見一些慢SQL,在分析這些慢SQL時,我們通常會看下SQL的執行計劃,驗證SQL執行程序中有沒有走索引,通常我們會調整一些查詢條件,增加必要的索引,SQL執行效率就會提升幾個數量級,我們有沒有思考過,為什么加了索引就會能提高SQL的查詢效率,為什么有時候加了索引SQL執行反而會沒有變化,本文就從MySQL索引的底層資料結構和演算法來進行詳細分析,
2 索引資料結構對比
索引的定義:索引(Index)是幫助MySQL高效獲取資料的排好序的資料結構,
索引中常見的資料結構有以下幾種:
- Hash表
- 二叉樹
- 紅黑樹
- B-Tree
- B+Tree
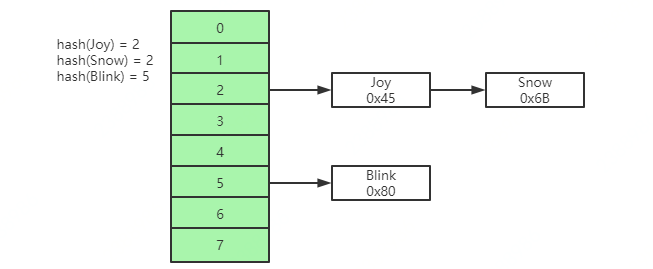
Hash表
通過索引的key進行一次hash計算,就可以快速獲取磁盤檔案指標,對于指定索引查找檔案非常快,但是對于范圍查找沒法支持,有時候也會出現Hash沖突的情況,
二叉樹
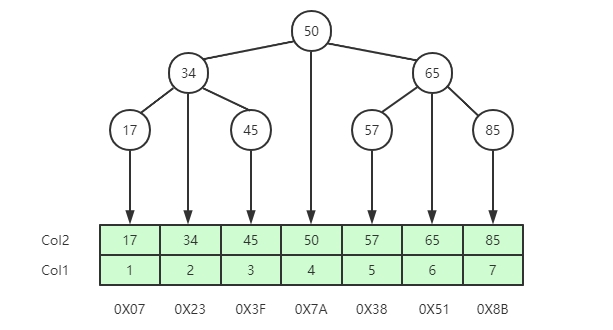
二叉樹的特點:左邊子節點的資料小于父節點資料,右邊子節點的資料大于父節點資料,如下圖所示,如果col2是索引,查找索引為65的行元素,只需要查找兩次,就可以獲取到行元素所在的磁盤指標地址,
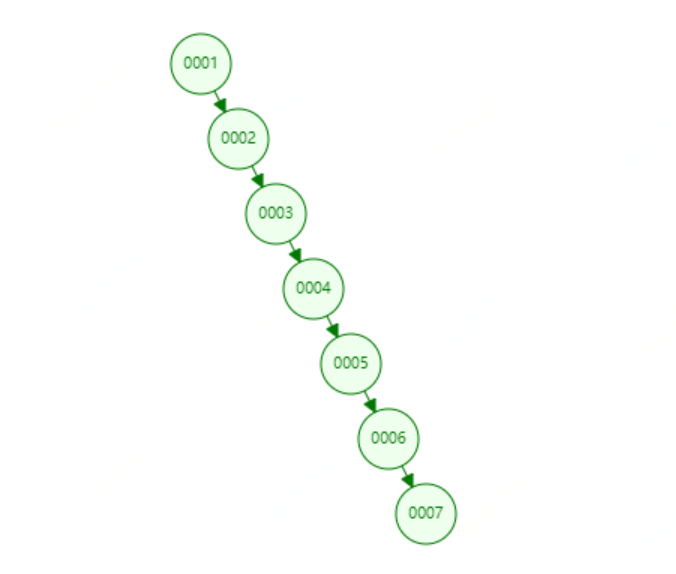
但如果是一個按照順序遞增的值,例如為col1建立索引,不再適合使用二叉樹建立索引,因為此時使用二叉樹建立索引將會變成一個鏈式索引,此時的索引結構如下圖所示,如果查找6節點需要6次遍歷才能找到,
紅黑樹
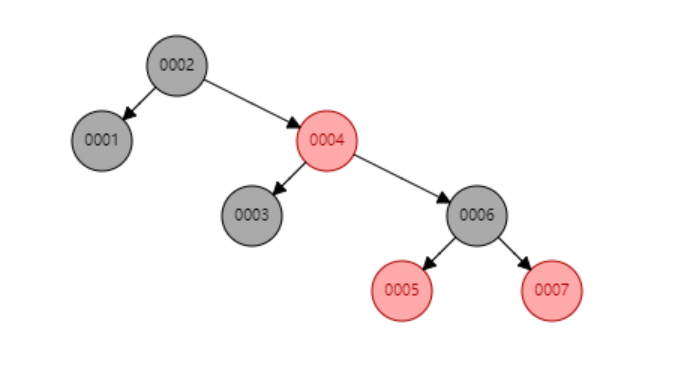
紅黑樹是一種二叉平衡樹,可以提高查詢效率,此時若再查找6節點只需要遍歷3次就能找到了,但紅黑樹也有缺點,當存盤大資料量時,樹的高度就會變的不可控, 數量越大,樹的高度越高,查詢的效率將會大大降低,
B-Tree
B-Tree是一種多路二叉樹,所具有的特點:1 葉節點具有相同的深度,葉節點的指標為空;2 所有索引元素不重復;3 節點中的資料索引從左到右遞增排列,
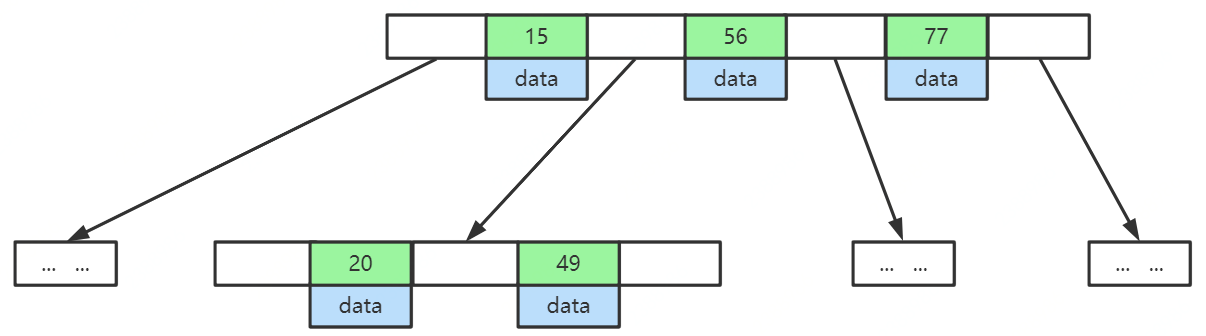
B+Tree
B+Tree是B-Tree的變種,所具有的特點:1 非葉子節點不存盤data,只存盤索引(冗余),可以放更多的索引;2 葉子節點包含所有索引欄位;3 葉子節點用指標連接,提高區間訪問的性能,
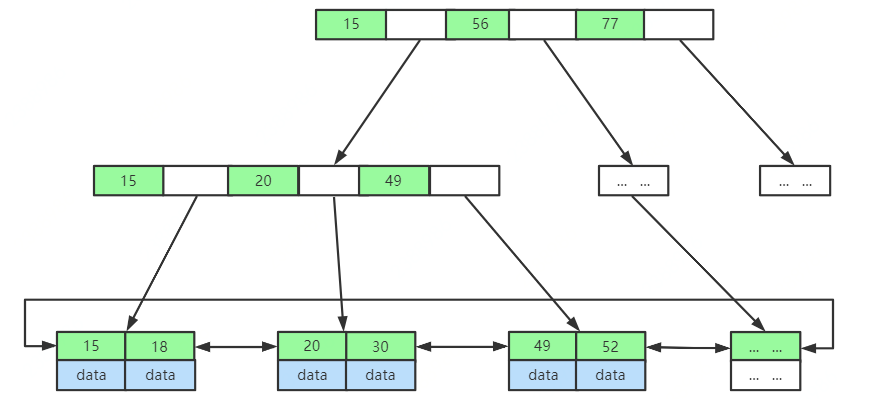
與紅黑樹相比,B-Tree和B+Tree兩種資料結構都更加矮胖,存盤相同數量級的索引資料時,層級更低,
B-Tree和B+Tree之間一個很大的不同,是B+Tree的節點上不儲存value,只儲存key,而葉子節點上儲存了所有key-value集合,并且節點之間都是有序的,這樣的好處是每一次磁盤IO能夠讀取的節點更多,也就是樹的度(Max.Degree)可以設定的更大一些,因為每次磁盤IO讀取的磁盤頁數是一定的,例如,每次磁盤IO能夠讀取1頁=4kb,那么省去value的情況下同樣一頁資料能夠讀取更多的key,這樣就大大減少了磁盤的IO次數,
此外,B+Tree也是排好序的資料結構,資料庫中><或者order by等都可以直接依賴這一特性,
MySQL中對于索引使用的主要資料結構也是B+Tree,目的也是在讀取資料時能夠減少磁盤IO,
3 千萬級資料如何用B+樹索引快速查找
MySQL 官方對非葉子節點(如最上層 h = 1的節點,B+Tree高度為3) 的大小是有限制的,最大的大小是16K,可以通過以下SQL陳述句查詢到,當然這個值是可以調的,既然官方給出這個閾值說明再大的話會影響磁盤IO效率,
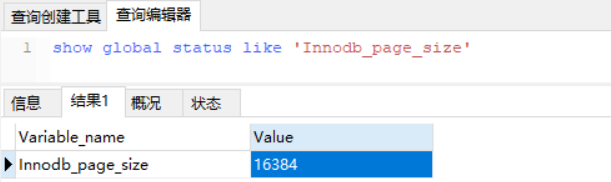
從執行結果,可以看到大小為 16384,即 16K大小,
假如:B+Tree的表都存滿了,主鍵索引的型別為BigInt,大小為8B,指標存盤了下個節點的檔案地址,大小為6B,最后一層,假如 存放的資料data為1K 大小,那么
- 第一層最大節點數為: 16k / (8B + 6B) ≈ 1170 (個);
- 第二層最大節點數也應為:1170個;
- 第三層最大節點數為:16K / 1K = 16 (個),
則,一張B+Tree的表最多存放 1170_1170_16 ≈ 2千萬,
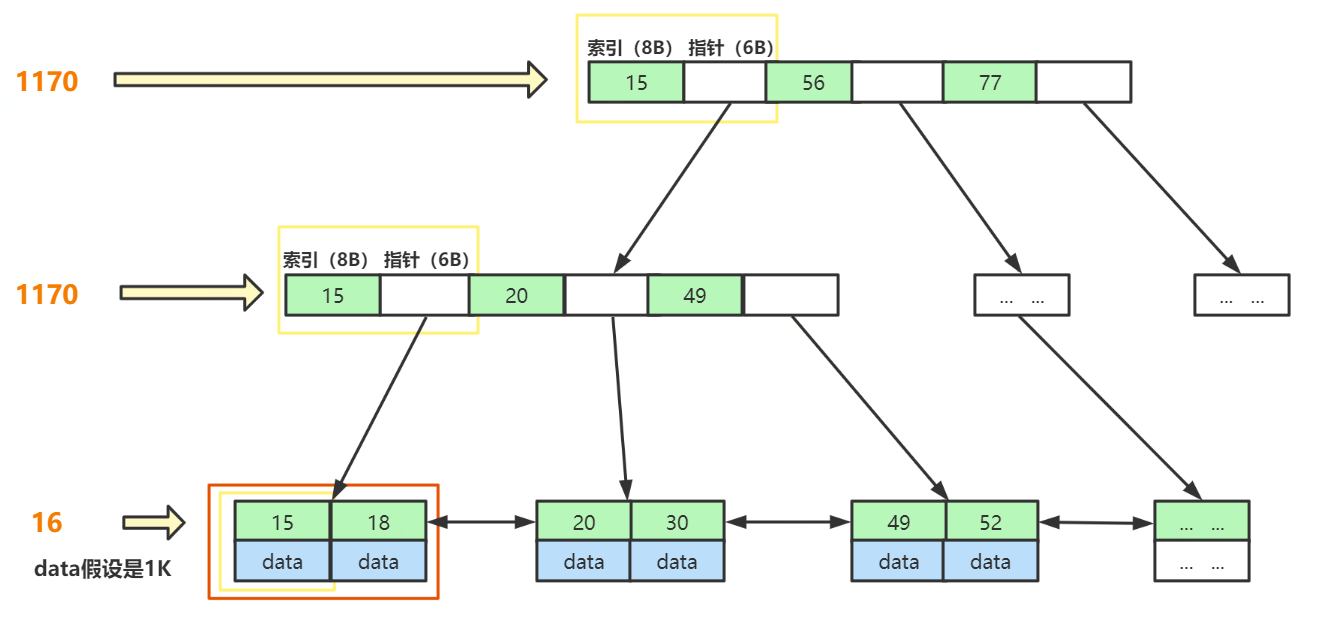
所以,通過分析,我們可以得出,B+Tree結構的表可以容納千萬資料量的查詢,而且一般來說,MySQL會把 B+Tree 根節點放在記憶體中,那只需要兩次磁盤IO就行,
4 存盤引擎索引實作
MySQL中索引儲存在哪里呢?和資料一樣,索引以檔案形式儲存在硬碟上,
在MyISAM儲存引擎中,資料和索引檔案試試分開儲存的,資料存在.MYD結尾的檔案中,索引單獨存在.MYI結尾的檔案中,

在InnoDB中,資料和索引檔案是合起來儲存的,注意下圖中沒有了.MYI結尾的檔案,只有一個.ibd結尾的檔案,

MyISAM索引檔案和資料檔案是分離的(非聚集),并且主鍵索引和輔助索引(二級索引)的儲存方式是一樣的,
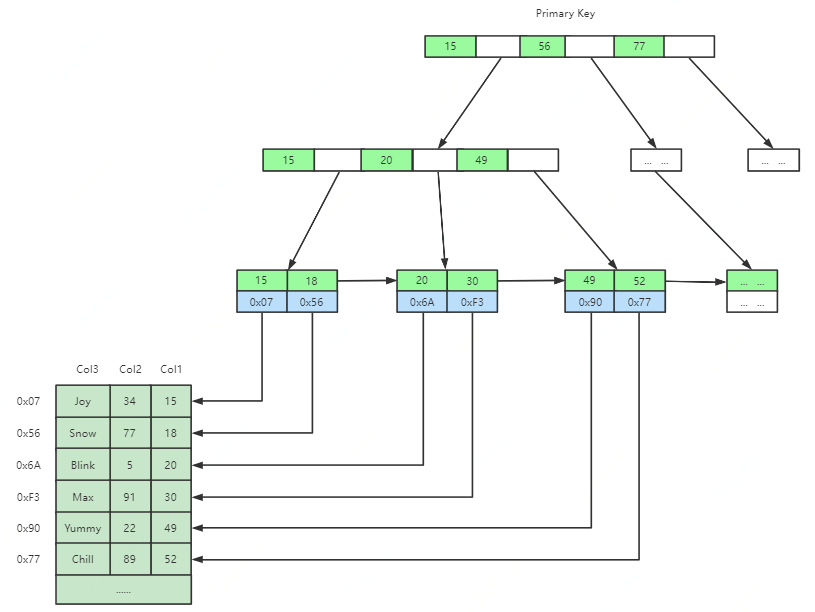
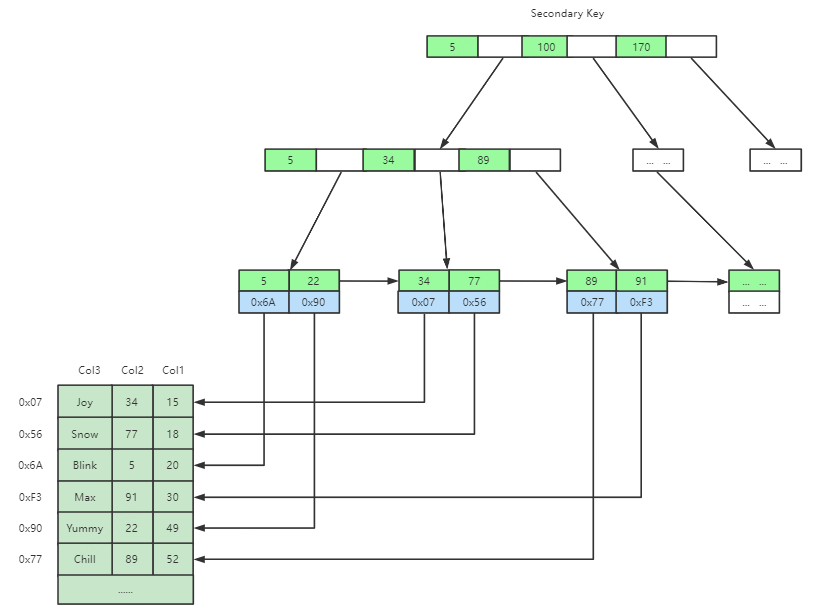
InnoDB中索引檔案和資料檔案是同一個檔案(聚集),并且主鍵索引和二級索引儲存方式有所不同,如圖所示,二級索引的葉子節點不儲存資料,僅儲存主鍵ID,
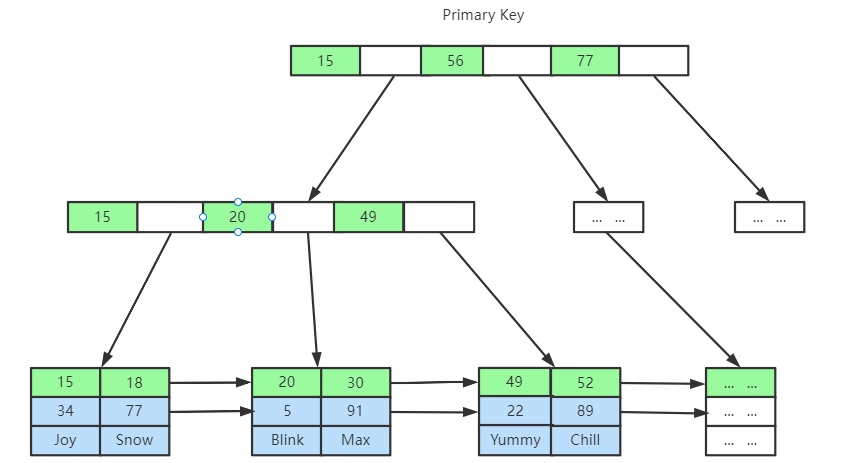
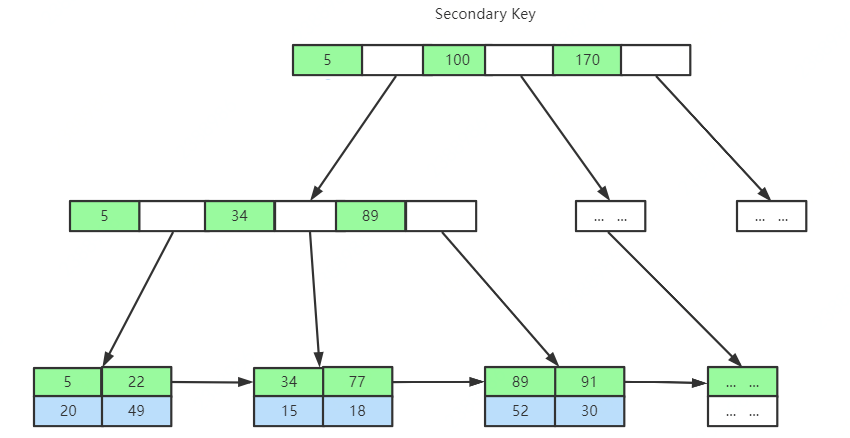
這里思考幾個問題:
- 為什么建議InnoDB表必須建主鍵,并且推薦使用整型的自增主鍵?
- 為什么非主鍵索引結構葉子節點存盤的是主鍵值?
如果我們在創建表時不設定主鍵,InnoDB會自動幫我們從第一列開始篩選一列資料不重復的列做為主鍵,如果找不到這樣的列,就會創建一個隱藏的列(rowid)做為主鍵,這會增加很多MySQL的作業,所以建議我們在創建InnoDB表時一定要設定主鍵,
整型的欄位做為主鍵,一方面在資料比較時不需要進行轉換,另一方面存盤也比較節省空間,那為什么要強調主鍵自增呢?如果主鍵id是無序的,那么很有可能新插入的值會導致當前節點分裂,此時MySQL不得不為了將新記錄插到合適位置而移動資料,甚至目標頁面可能已經被回寫到磁盤上而從快取中清掉,此時又要從磁盤上讀回來,這增加了很多開銷,同時頻繁的移動、分頁操作造成了大量的碎片,得到了不夠緊湊的索引結構,后續不得不通過OPTIMIZE TABLE來重建表并優化填充頁面,反之,如果每次插入有序,那就會在當前頁后面連續寫入,寫不下就會重新分配一個節點,記憶體都是連續的,這樣效率自然也就最高了,
非主鍵索引的葉子節點存盤主鍵值而非全部資料,主要也是為了一致性和節省空間,如果二級索引儲存的也是資料,那么每次插入MySQL都不得不更新每棵索引樹,這樣就加劇了新增編輯時的性能損耗,并且這樣一來空間利用率也不高,必然產生了大量冗余資料,
5 聯合索引底層資料結構又是怎樣的
聯合索引又叫復合索引,例如下表:
CREATE TABLE `test` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL,
`age` int NOT NULL,
`position` varchar(32) NOT NULL,
`address` varchar(128) NOT NULL,
`birthday` date NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
如下索引就是一個聯合索引,
`idx_name_age_position` (`name`,`age`,`position`) USING BTREE
聯合索引底層資料結構長什么樣?
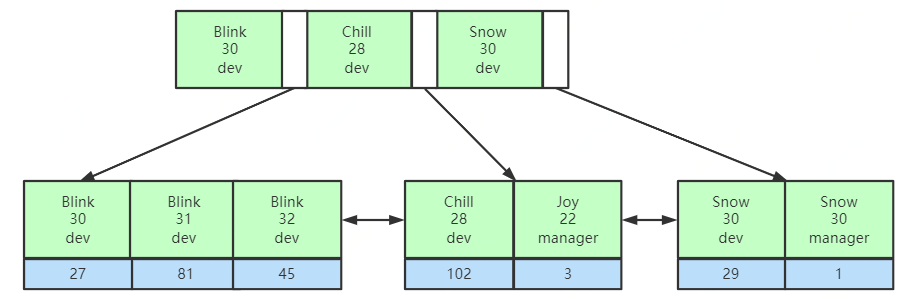
比較相等時,先比較第一列的值,如果相等,再繼續比較第二列,以此類推,
了解了聯合索引的存盤結構,我們就知道了索引最左前綴優化原則是怎么回事了,在使用聯合索引時,對于索引列的定義順序將會影響到最終查詢時索引的使用情況,例如聯合索引(name,age,position),MySQL會從最左邊的列優先匹配,如果最左邊的帶頭大哥name沒有使用到,在未使用覆寫索引的情況下,就只能全表掃描,
聯合底層資料結構思考:MySQL會優先以聯合索引第一列匹配,此后才會匹配下一列,如果不指定第一列匹配的值,也就無法得知下一步查詢哪個節點,
6 總結
索引本質上是一種排好序的資料結構,了解了MySQL索引的底層資料結構及存盤原理,可以幫助我們更好地進行SQL優化,其實資料庫索引調優是一項技識訓,不能僅僅靠理論,因為實際情況千變萬化,而且MySQL本身存在很復雜的機制,如查詢優化策略和各種引擎的實作差異等都會使情況變得更加復雜,但同時這些理論是索引調優的基礎,只有在明白理論的基礎上,才能對調優策略進行合理推斷并了解其背后的機制,然后結合實踐中不斷的實驗和摸索,從而真正達到高效使用MySQL索引的目的,
最后,如果大家想再溫習一下資料結構的知識,這個資料結構網站(https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)不可錯過,可以很好地幫助我們演示資料結構的存盤程序,
作者:京東物流 于朔
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/549373.html
標籤:其他
上一篇:navicat15安裝破解教程
下一篇:spark 流處理的幾個實體