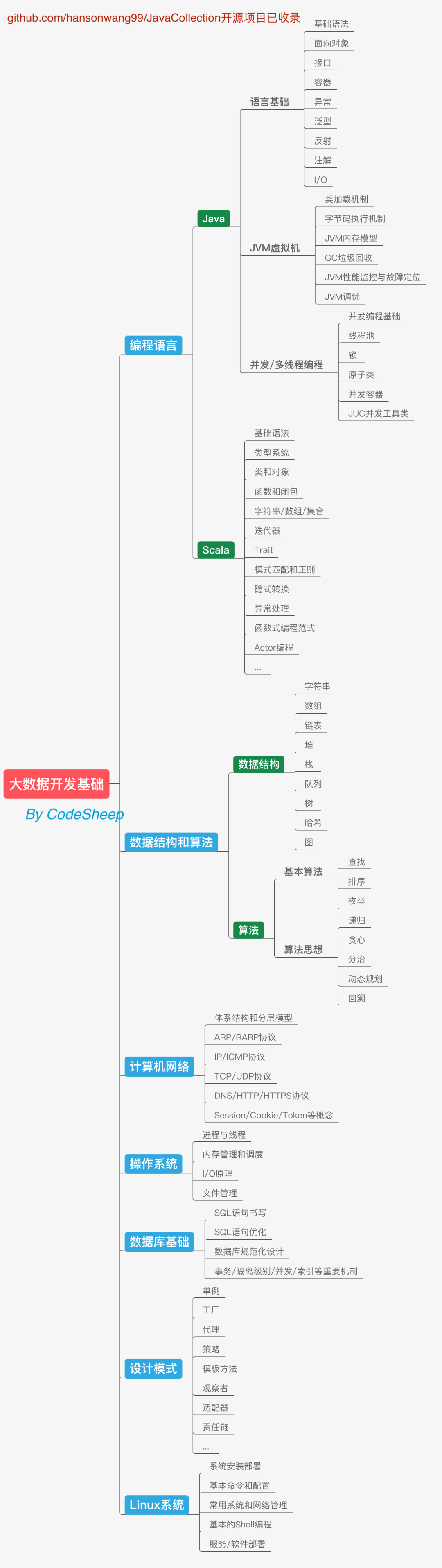
# 大資料開發基礎
學習編程語言往往是我們開啟學習之路的第一大步,大資料領域的很多框架都是基于Java語言開發的,而且各種框架也都提供了Java API來提供使用和操作介面,所以Java語言的學習逃不掉,除此之外Scala在必要時也可以學一下,在大資料開發領域里用得還是挺多的,Scala語言的表達能力很強,代碼信噪比很高,而且很多大資料框架也都提供了Scala語言的開發介面,況且Scala也可以運行于Java平臺(JVM),并且兼容Java程式,所以也可以和大資料相關系統進行很好的集成,
除此之外,老生常談的資料結構和演算法、計算機網路、作業系統、資料庫、設計模式也是程式員必備的通用計算機基礎,不光是搞大資料的需要具備,搞后端開發的也是掌握這些基礎,而且這些東西在求職面試時也是必備的,這部分應該大量花時間給坐實,
最后還要提一下對Linux作業系統的要求,當然我們這里主要還是著眼于Linux系統使用的角度,因為大資料系統的開發、部署基本都是基于Linux環境進行的,掌握常用的命令、配置、網路和系統管理、基本的Shell編程等等,對學習都大有裨益,
---
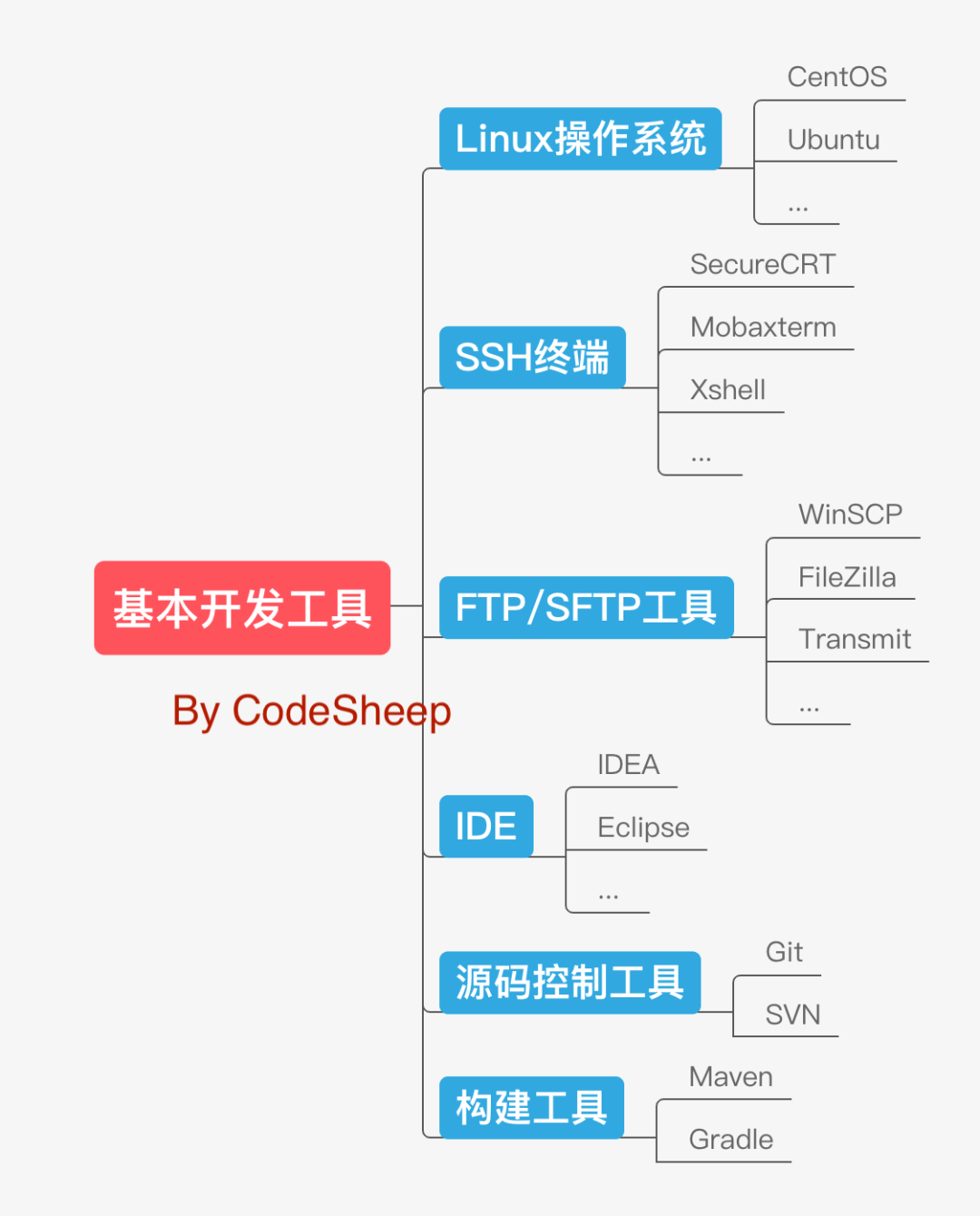
# 基本開發工具
大資料領域的常見開發工具和軟體和后端開發基本差不多,比如:選一個常見的Linux作業系統,一套好用的SSH工具和FTP/SFTP工具,一個稱手的集成開發環境,以及主流的原始碼控制工具和構建工具等等,
接下來就進入到大資料開發的具體流程,分幾大塊捋一遍,首先就是資料采集,
---
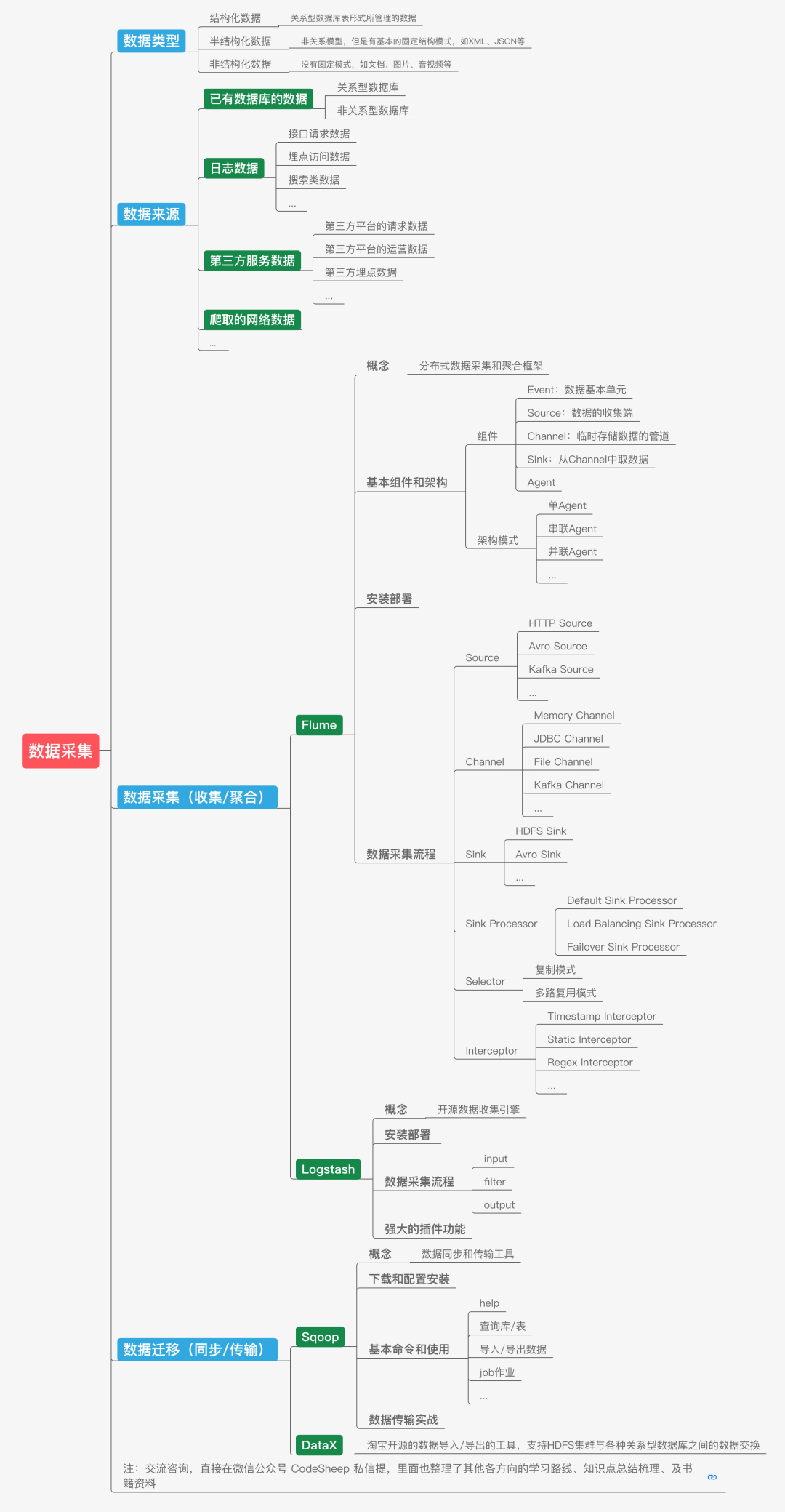
# 資料采集
既然大資料系統是處理海量資料的,那么第一個問題,這個海量資料到底是什么型別?從哪里來呢?
可以說,輸入大資料系統的資料型別種類繁多,形式結構也有所不同,有傳統的結構化資料,也有XML、Json等這類的半結構化資料,甚至還有檔案、音視頻這類非結構化資料,

資料的來源更是五花八門,有直接來自后端已有資料庫的資料,有來自后端日志系統的資料,有來自第三方服務的各種資料,甚至還有從網上爬取的各種資料,

找到了資料源,接下來的資料采集和資料傳輸作業就很重要了,
我們就以后臺最常見的日志資料為例,由于現在的服務系統采用集群部署方式的很多,那分布式集群上海量日志資料的采集和傳輸就是一個大問題,Flume是一個較常使用的分布式資料采集和聚合框架,最典型的應用就是日志資料的收集,它可以定制各類資料發送方并聚合資料,同時提供對資料的簡單處理,并寫到各種資料接受方,完成資料傳輸,
與此同時,還有一個叫做Logstash的開源資料收集引擎可能大家也聽過,也比較常用的,
當然還有一種場景也是資料采集這一步通常需要考慮的,那就是在不同的存盤系統(或資料庫)之間進行資料的遷移(如:匯入/匯出),比如我們經常需要在傳統關系型資料庫(如MySQL)和大資料系統的資料倉庫(如Hive)之間進行資料遷移(交換),這時候一個叫Sqoop的資料采集和傳輸工具就非常常用了,除此之外,淘寶開源的DataX也是同型別工具,
---
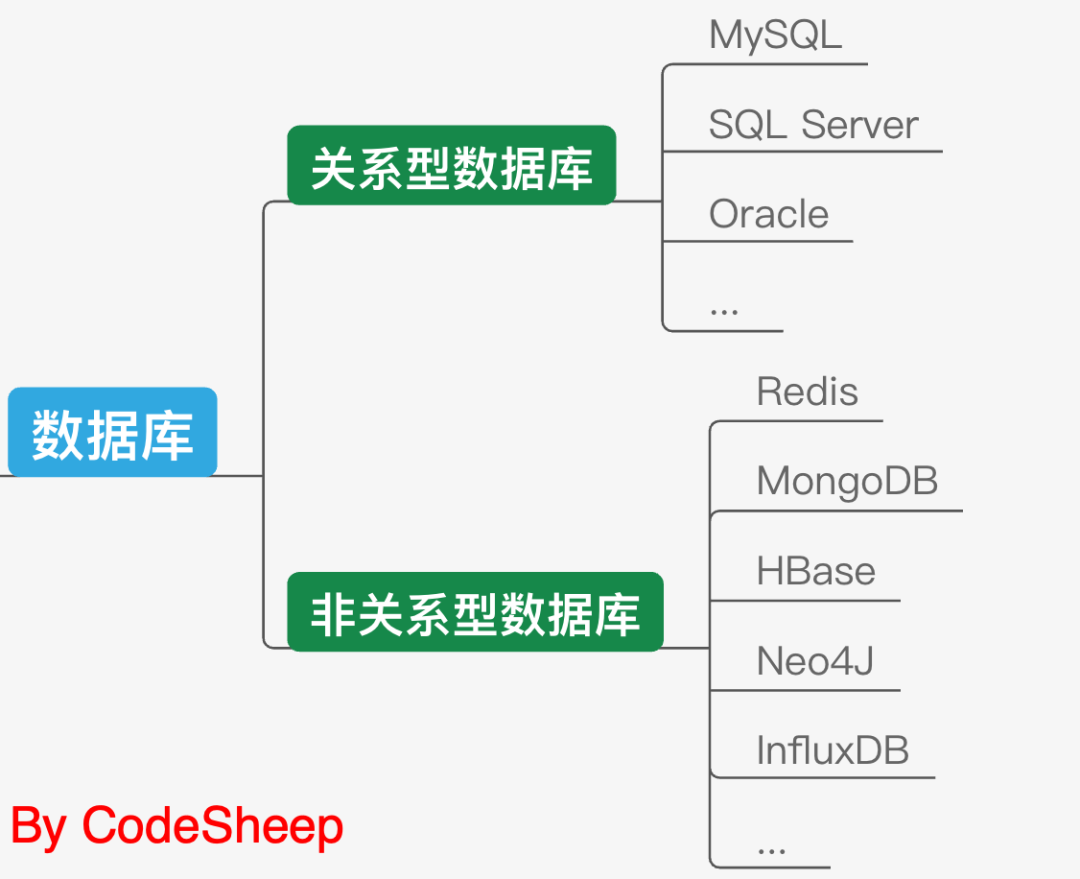
# 資料存盤
資料采集完成,接下來需要對其進行存盤,這也是非常清晰的思路和流程,
說到資料存盤,我們首先想到的當然是資料庫存盤,包括MySQL、Sql Server等等這種最常見的關系型資料庫,以及Redis、MongoDB、HBase等這類非關系型資料庫,
我們這里將ElasticSearch單獨提出來聊,因為雖然它某一程度上也可以視為資料庫,但是它更主要的身份還是一個優秀的全文搜索引擎,它的出現,解決了一部分傳統關系型資料庫和NoSQL非關系型資料庫所沒有辦法高效完成的一些作業,比如高效的全文檢索,結構化檢索,甚至是資料分析,所以現在用的公司也越來越多,
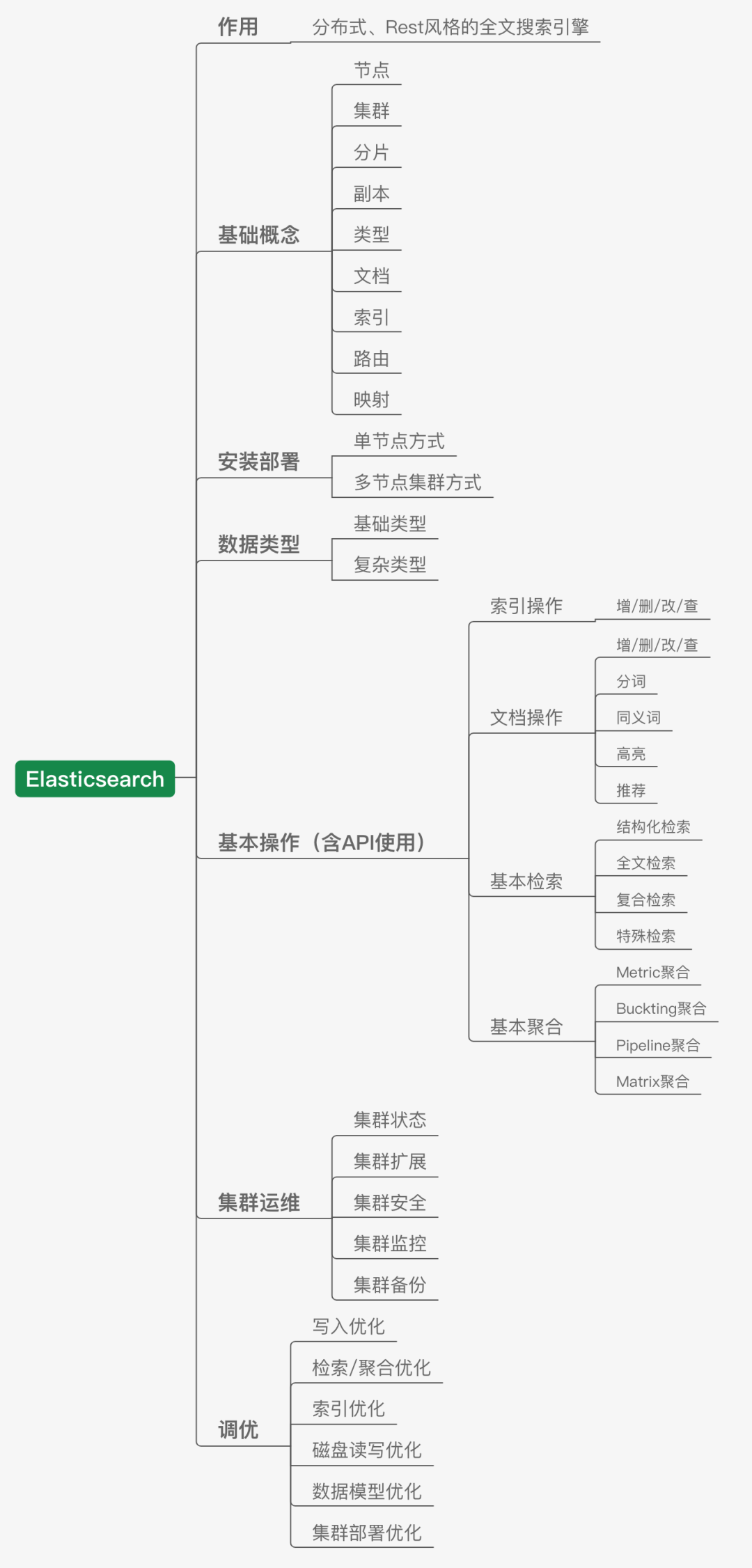
除了傳統的資料庫,在大資料領域,應用非常廣泛的存盤技識訓包括分布式檔案系統和分布式資料庫,說到分布式檔案系統,大名鼎鼎的HDFS就是一個使用非常廣泛的大資料分布式檔案系統,它既是基本的資料存盤平臺,也是大資料系統基礎平臺設施;而后者的代表性技術HBase則是一個構建在HDFS之上的分布式資料庫,適合海量資料的存盤,
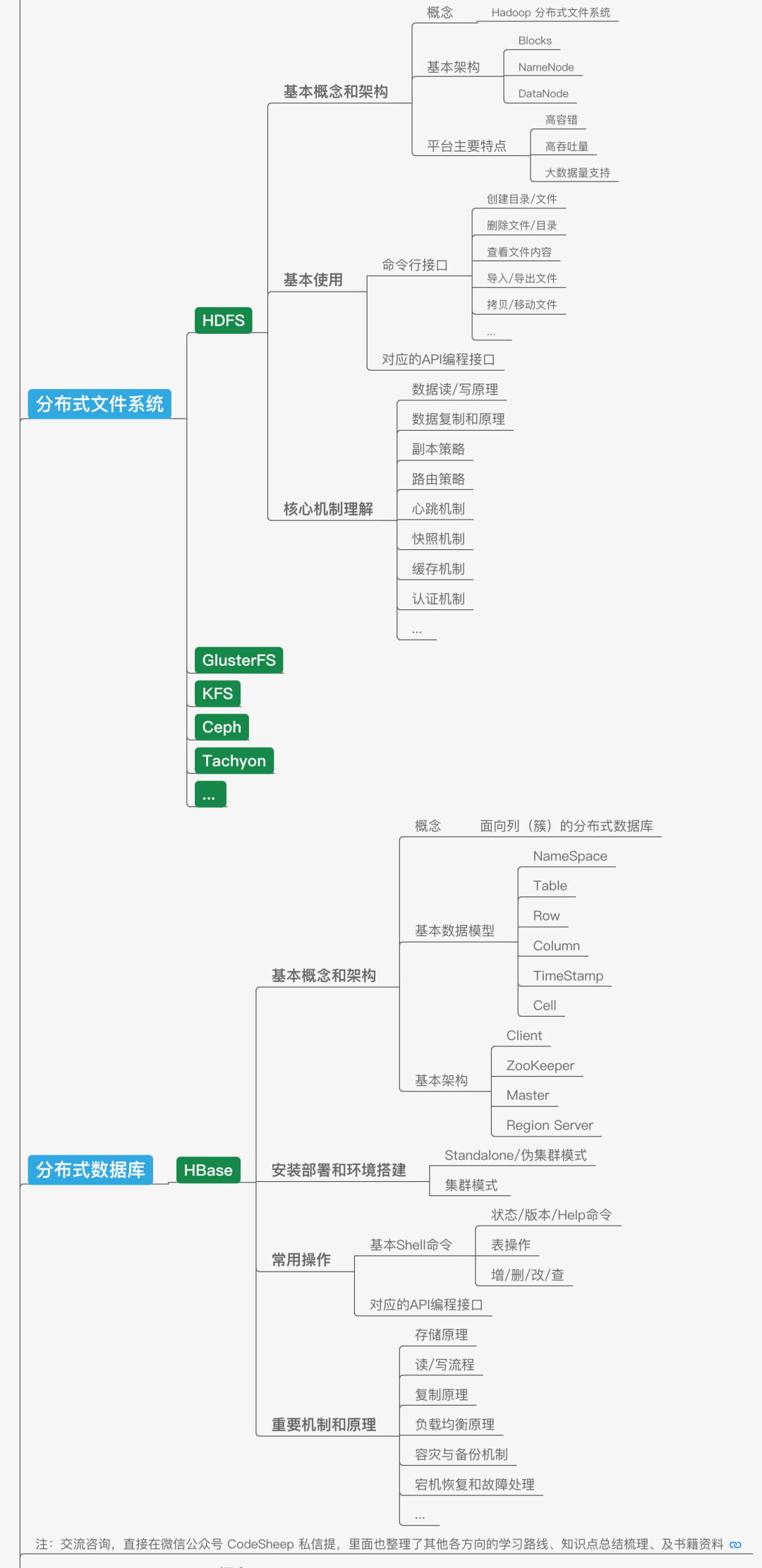
在大資料領域,除了分布式檔案系統和分布式資料庫,還有一個經常聽到的就是以Hive為代表的資料倉庫,我們可以將資料倉庫理解為一個邏輯上的概念,其底層往往是基于檔案系統打造的,還以Hive為例,它的出現主要就是可以讓開發人員能夠通過SQL的方式來方便地操作和處理HDFS上的資料,適用于離線批量資料的處理,上手友好,使用門檻降低,

所以將這部分內容做一個階段性總結,可以如下所示:

---
# 資料處理
資料有著落了,接下來干啥?當然是充分挖掘資料所蘊含的價值,更直白一些說就是對其進行各種查詢、分析和計算,這樣才能為資料賦能,產生價值,
最早期的MapReduce就是Hadoop提供的分布式計算框架,可以用來統計和分析HDFS上的海量資料,適合于速度不敏感的離線批處理;后來出現的記憶體計算框架Spark則更加適合做迭代運算,因此也備受青睞,在一些不需要實時計算的場景,這些框架應用得十分廣泛,但是在一些離線資料分析無法滿足需求的場景下,比如金融風控、實時推薦等,這時候在線計算或者說流式計算就變得十分有必要了,這也成了現如今諸如Storm、Flink等一大批優秀的實時計算框架的主陣地,尤其是Flink,這幾年的火熱程度不用多說,基于它構建的處理引擎也鱗次櫛比,

---
# 資料價值和應用
大資料系統最終的任務還是得服務于業務,為生產創造出實際價值,這種價值應用場景包括但不限于提供各種統計報表,商品推薦,資料可視化展現,商業分析,輔助決策等等,

---
# 大資料周邊技術
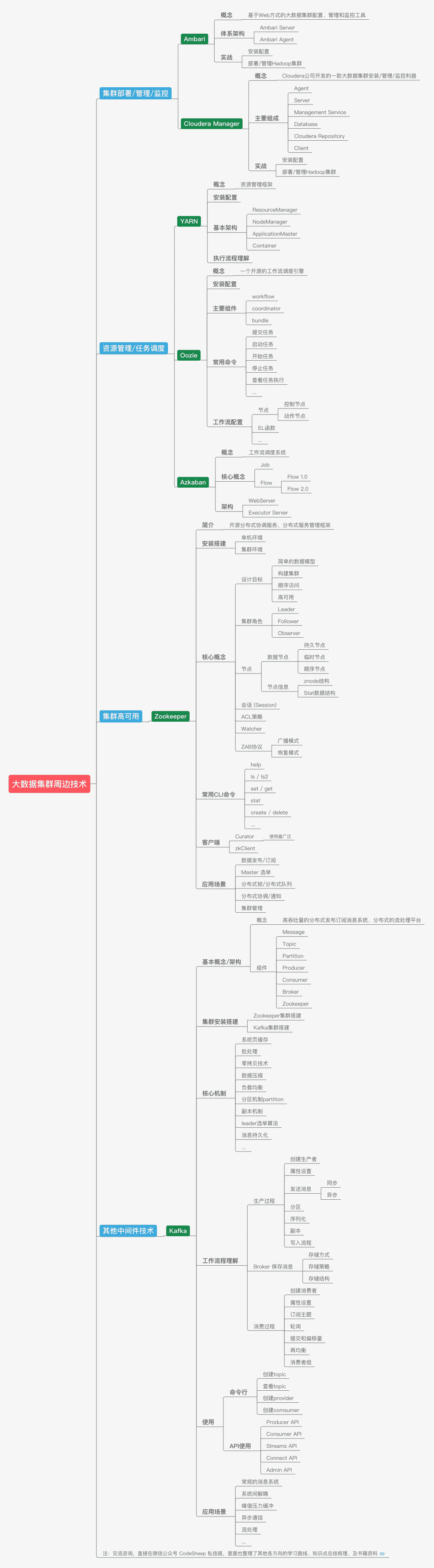
聊到這里,應該說上面的內容已經基本將一個大資料引擎的主流程走完了,然而實際的大資料系統還需要諸多周邊技術的支持,因此還衍生了很多附加框架和技術,
由于單機性能的局限和瓶頸,所以大資料系統的很多框架組件都是集群部署的,這時候針對集群系統的部署、管理以及監控工具就不可或缺了,比如使用廣泛的Ambari和Cloudera Manager等,
有了集群之后,集群平臺上各種資源的管理以及各種任務的調度就成了一個復雜且棘手的問題,這時候資源管理框架YARN,任務作業流調度框架Azkaban和Oozie等就有了用武之地,
同時為了保證分布式集群的高可用,像ZooKeeper這種分布式協調服務框架簡直幫了大忙,像Master選舉、集群管理、分布式協調通知等任務統統不在話下,
最后,還必須要提的一個大名鼎鼎的中間件框架,那就是Kafka,它不僅僅是一個高吞吐量的訊息系統,有了它之后,系統解耦、峰值壓力緩沖、高效流處理等等都使得它成為后端開發和大資料開發人員眼里那個最靚的崽,
---
# 總結
最后我們也將上述所有內容的完整版思維導圖給貼在這里,由于這個圖實在太大,上傳后可能被壓縮,如需無損版源檔案的,可長按或微信掃碼關注下方公眾號CodeSheep二維碼,回復「大資料」三個字自取吧:

(長按或掃碼識別)

---
# 幾個要討論的話題
## 大資料開發和后端開發關系大嗎?
應該說很多技術點和框架都是有交集的,比如通用編程基礎部分完全一致,再者常用的像Redis、Zookeeper、Kafka、Elasticsearch等等這些主流得不能再主流的框架,在以前咱們梳理Java后端路線時也都有,所以二者的交集很大,甚至很多做大資料的,以前就是從后端轉過來的,非常自然,因為很多技術都相通甚至完全一樣,
## 這么多框架都得學嗎?
大資料領域框架這么多,睡不著覺的可以大致數一數,僅剛才那個腦圖里面所提及的最起碼就有三四十個,是每個都需要學習嗎?我們在梳理時,同型別的主流框架都列舉了不止一個,一般來說,我們只要學明白其中一個,上手同型別其他技術就都不難了,舉一反三很重要,另外我們盡量學主流經典的框架,一般就沒啥問題,比如分布式檔案系統HDFS很經典用得很多,流處理里面Flink現在火得一腿,自學對應部分時就可以考慮學一下,
## 具體框架(技術)到底怎么學?
最后還是得落實到具體某一個技術(框架)到底怎么學的問題,我覺得學習思路倒也清晰,首先第一步,搞清楚這個框架是干什么的,解決了什么問題和痛點,同類“競品”還有哪些,這一步在上面的詳細思維導圖里,我們已經幫你完成了;第二大步,把這個技術(框架)用起來,獲得成就感很重要,那具體又怎么用呢,思路也很明了,首先是把對應環境安裝部署好,跑起來,然后基于準備好的環境做實驗,跑Demo,自己寫東西拿上去跑,由簡單到復雜,慢慢上手直至熟練,該程序中肯定會踩坑,所以做好記錄、輸出、筆記,寫下自己的踩坑程序和解決思路非常重要,步步為營;最后一大步才是針對里面的關鍵機制深入研究其原理,學到就是賺到,所以總體也就這三大步,
本文來自博客園,作者:原力星球,轉載請注明原文鏈接:https://www.cnblogs.com/cheng020406/p/17294793.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/549462.html
標籤:大數據
下一篇:hadoop學習記錄