摘要:多跳查詢能力也是一個衡量產品性能非常重要的指標,
本文分享自華為云社區《聊聊超級快的圖上多跳過濾查詢》,作者:弓乙,
在圖資料庫/圖計算領域,多跳查詢是一個非常常用的查詢,通常來說以下型別的查詢都可以算作是多跳過濾查詢:
1.查詢某個用戶的朋友認識的朋友 --二跳指定點label的查詢 2.查詢某個公司的上下游對外投資關系 --N跳指定方向過濾查詢 3.查詢某個公司實際持股股東 --N跳內帶過濾查詢 4.搜索可提供某個零部件的供貨商 --N跳內帶過濾的until查詢 5.局點變更影響分析 --N跳內帶過濾查詢
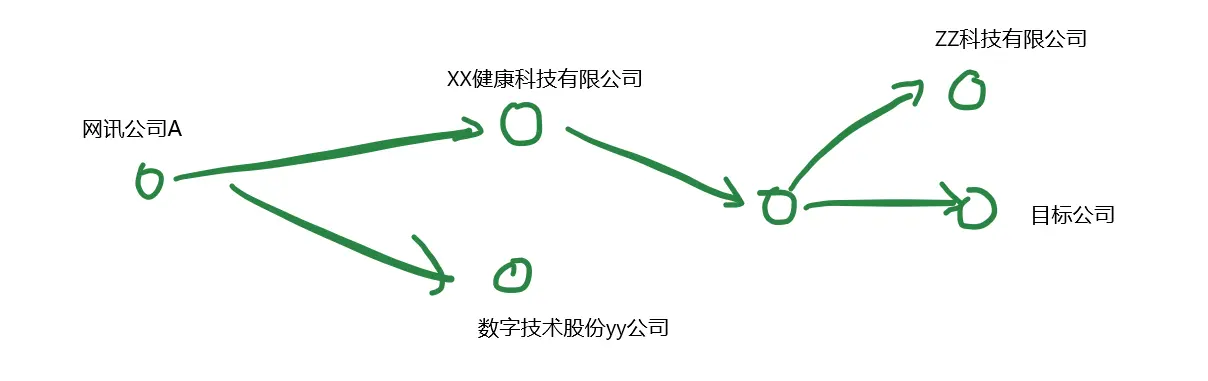
如下圖,可用3跳查詢得到網訊公司A所有的對外投資機構,
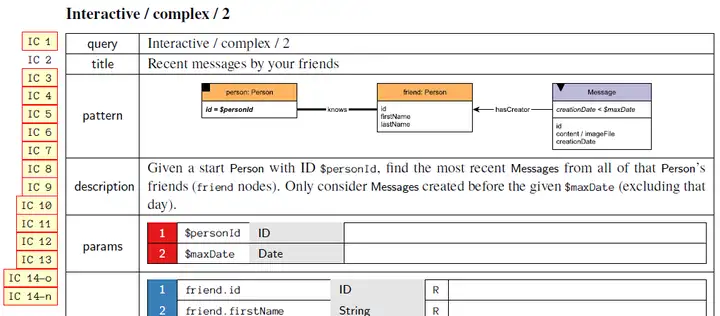
與此同時,多跳查詢能力也是一個衡量產品性能非常重要的指標,比如LDBC(Linked Data Benchmark Council)的互動式查詢場景下就設計了多個考察圖資料庫系統多跳查詢能力的測驗用例,互動式查詢Interactive的Complex Query中有多個用例均為多跳查詢,如下圖是一個查朋友最近發送的訊息的IC2用例,是一個經典的圖上2-hop查詢,
在圖計算的尺度里,多跳過濾某些情況下被稱為k-hop演算法,BFS,DFS演算法,區別僅在于traversal的策略是深度優先還是廣度優先,
而在圖資料庫中一般將多跳過濾看做是需要特殊優化的模式匹配查詢(cypher)或可組合的復合查詢(gremlin),
以下展示常用的圖查詢語言gremlin/cypher的二跳查詢的寫法,結果均為回傳李雷朋友的朋友:
gremlin: g.V('李雷').out('朋友').out('朋友')
cypher: match (n)-->(m1:朋友)-->(s1)-->(m2:朋友)-->(s2) where id(n)='李雷' return s2
這兩個陳述句輕盈又直觀,看起來一切都被解決地如此優雅,
但事實真的如此嗎?
很遺憾,當我們興致勃勃地構圖,將資料匯入圖資料,再使用類似上述陳述句查詢實際業務場景時,你也許會驚訝地發現,也許結果與我們所期待的并不一致,
接下來,我將展開說說為什么使用多跳過濾查詢會比我們想象中的更復雜,了解了圖上遍歷的概念后,我們能把而基于多跳過濾這一特性,我們又能怎么做使得這個重要的查詢又快又流程呢?
功能那些事兒
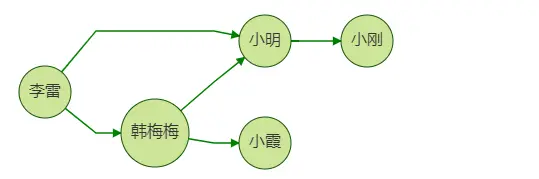
上面我們介紹了查詢一個用戶朋友的朋友的例子,這里我們假設業務場景是向李雷推薦好友,思路是:向他推薦其好友的好友,但是推薦的好友中不應包含李雷本身的好友,比如圖中小明同時是李雷的一跳好友和二跳好友,這時我們不應向李雷推薦小明,因為她已經是李雷的好友了,
僅僅增加了一個回傳的二跳鄰居不包含一跳鄰居這個條件,讓我們來看下與上面單純的2跳查詢的gremlin和cypher變成什么樣了?
gremlin: g.V("李雷").repeat(out("朋友").simplePath().where(without('1hop')).store('1hop')). times(2)
cypher: match (a)-[:朋友]->(d) where id(a)='李雷' with a, collect(d) as neighbor match (a)-[:朋友]-(b)-[:friend]-(c) where not (c in neighbor) return c
不知道各位有什么感覺?如果是不熟悉圖查詢語言的朋友們看到這里一定兩眼發黑了吧哈哈,
不用擔心,如果我們靈活使用一些特性,也許事情會變得簡單,比如這是一個GES原生API多跳過濾查詢Path Query的json請求:
{ "repeat": [{"operator": "outV"}], "times": 2, "vertices": ["李雷"], "strategy":"ShortestPath" }
假如我們可以把它翻譯為gremlin的寫法的話,它大概是:
g.V('李雷').repeat(out()).times(2).strategy('ShortestPath')
以上的寫法除了strategy('ShortestPath')其他本身就是gremlin已經支持的語法,意為-查詢從李雷出發以ShortestPath為遍歷策略的二跳鄰居,
遍歷策略是什么?
理解遍歷策略是了解多跳過濾的基石,我們這里從圖論里幾個定義展開:
A walk is a finite or infinite sequence of edges which joins a sequence of vertices.[2] Let G = (V, E, ?) be a graph. A finite walk is a sequence of edges (e1, e2, …, en ? 1) for which there is a sequence of vertices (v1, v2, …, vn) such that ?(ei) = {vi, vi + 1} for i = 1, 2, …, n ? 1. (v1, v2, …, vn) is the vertex sequence of the walk. The walk is closed if v1 = vn, and it is open otherwise. An infinite walk is a sequence of edges of the same type described here, but with no first or last vertex, and a semi-infinite walk (or ray) has a first vertex but no last vertex. A trail is a walk in which all edges are distinct.[2] A path is a trail in which all vertices (and therefore also all edges) are distinct
以上應用wiki中對于圖上不同的點集組成的邊集說明,詳情見Path (graph theory) - Wikipedia,
以下,我將幾個相似又不同的概念用四個維度區分開,
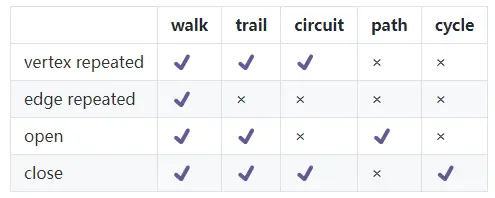
以上5個概念均指代在G=(V,E,φ)中,由點V,邊E組成的序列,
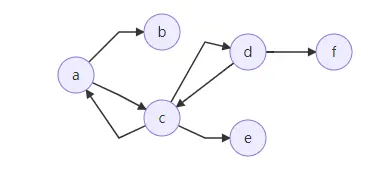
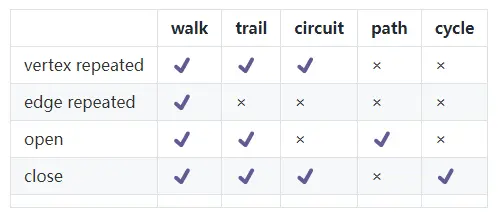
上圖中,對于序列a->c->d->f,我們可以將它稱為walk, trail, path,三者都可以,因為該序列的起點a與終點f不同,不屬于對序列要求close狀態circuit和cycle,
而序列a->c->a->c, 我們只能將其歸為walk,因為其不閉合不屬于circuit和cycle,且點有重復(a,c兩個都有重復)不屬于path,邊集有重復(a->c的邊有重復)不屬于trail,
遍歷策略對最終的結果和遍歷效率都有決定性的影響,

這里簡單說明下新增的shortestPath策略:
- Walk:以圖論中劃定的walk進行圖遍歷:即在traversal的程序中允許經過重復的點和重復的邊,
- ShortestPath:以shortestPath的規則進行圖遍歷:即在BFS traversal的程序不會遍歷在前面跳數出現過的點,在這種模式下的路徑每個終點到起點都是最短路徑,
BFS與DFS
影響遍歷順序的另一個角度一般我們分為:
- BFS - Breadth-first search 廣度優先搜索
- DFS - Depth-first search 深度優先搜索
BFS在圖遍歷時會優先遍歷一個點的所有鄰居,再遍歷其鄰居的鄰居,而DFS會優先遍歷點的鄰居的鄰居,直到到達最深的節點,
我們可以設定一個batchSize,表示在進行BFS時不遍歷全部的鄰居,而是每層以batchSize的數量進行遍歷,然后再以batchSize的個數遍歷下一層鄰居,
可以推斷出,當batchSize=1時,該BFS約等于DFS的遍歷策略,
性能那些事兒
多跳過濾的性能受很多因素影響,以下總結一些會影響到性能的因素以供參考:

而對于不同規模的圖,多跳過濾查詢的TPS大部分情況下并不取決于圖的點邊規模,而是與圖的密度密切相關,
比如一個二跳查詢,那么TPS就與該圖的二跳鄰居分布強相關,
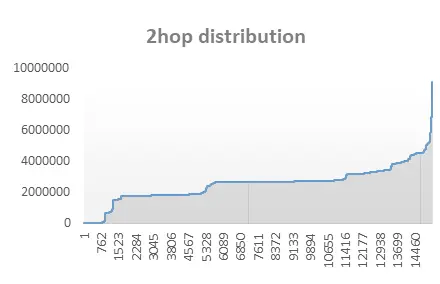
簡單來講,多跳過濾最終的性能主要受遍歷程序中觸達節點的個數影響,同樣規模的圖,其多跳過濾tps可能相差很大,大部分情況下基準測驗僅提供橫向比較,考驗的是圖資料庫/圖引擎本身的性能指標,有一定參考價值,但仍以實際業務圖表現為主,
經驗上,稀疏的圖性能表現大大好于稠密的圖,
多跳查詢的使用
為了簡化多跳過濾查詢的表達,我們用一些引數來表達查詢程序,如前面章節介紹過的遍歷策略,batchSize等,
本章我們將一一介紹以下特性引數:

接下來我們以GES的path query(filterquery version2版本)介面來舉例介紹多跳過濾查詢的使用,
該介面支持對多跳過濾查詢,回圈執行遍歷查詢進行加速,可以看做是gremlin的repeat陳述句的擴充表達,例如以下gremlin陳述句:
g.V('1','2').repeat(out()).times(2).emit().dedup()
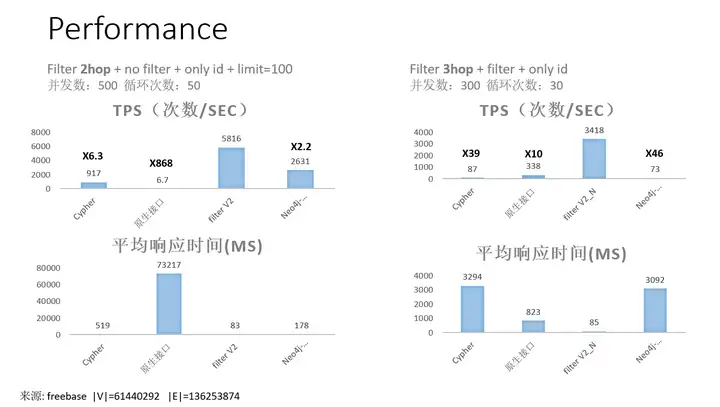
以下為該介面的2跳/3跳查詢在1億規模圖上的測驗情況,
其中,
- filterV2 - GES的多跳程序查詢原生介面,該API性能最佳,TPS與延遲表現優異,
- Cypher - GES的cypher查詢(較老版本),
- Neo4j - Neo4j community 4.2.3版本cypher,
- gremlin - GES的gremlin,未在圖中體現,實際性能最差,故未做對比,
請求樣例1
POST /ges/v1.0/{projectId}/graphs/{graphName}/action?action_id=path-query { "repeat": [{"operator": "outV"} ], "emit": true, "times": 2, "vertices": [ "1","2" ] }
以上請求等價于gremlin陳述句:
g.V('1','2').repeat(out()).times(2).emit().dedup()####
特性引數簡要說明
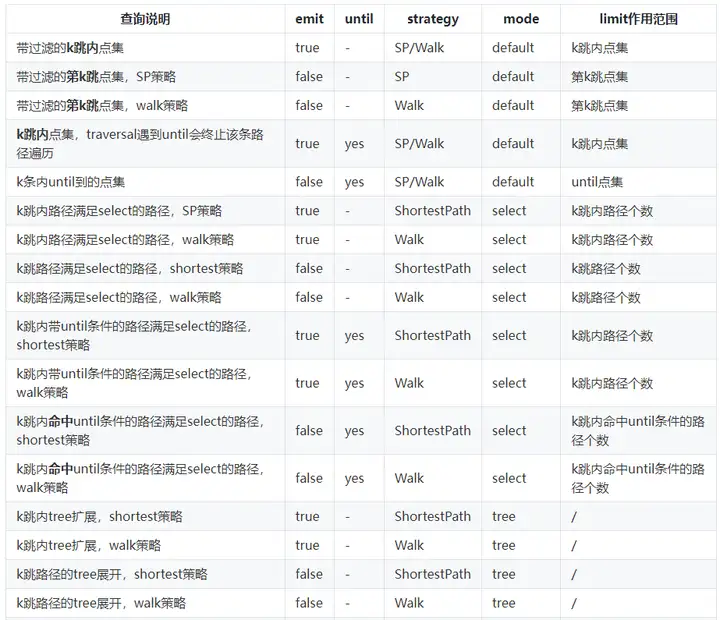
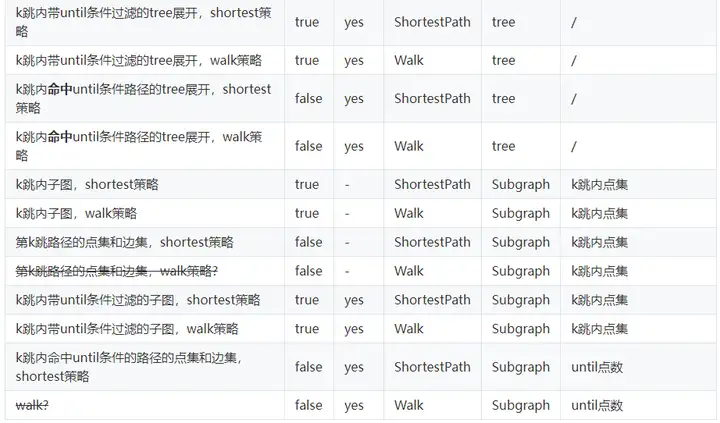
速查引數表
filterV2的引數過于復雜,需要花一定的時間去理解?請看下面總結出的速查表,幫助您快速使用repeat模式:
PS:strategy策略的說明查看下方
emit模式
emit是一個filtered query引數中對其他各個引數影響最大的引數,我們將其定義為,是否輸出query程序中的點,其含義也與gremlin中的emit一致,
下面將介紹,在不同模式下emit的表現形式:
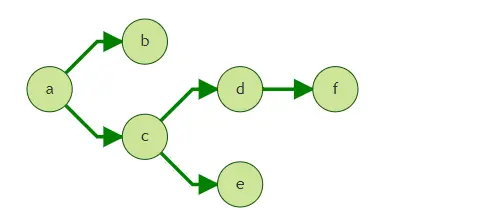
上圖中,假定我們從點a出發,執行filtered khop query的查詢,
strategy
圖遍歷程序中使用的策略,目前可選:ShortestPath和Walk,
- Walk:以圖論中劃定的walk進行圖遍歷:即在traversal的程序中允許經過重復的點和重復的邊,
- ShortestPath:以shortestPath的規則進行圖遍歷:即在BFS traversal的程序不會遍歷在前面跳數出現過的點,在這種模式下的路徑每個終點到起點都是最短路徑,
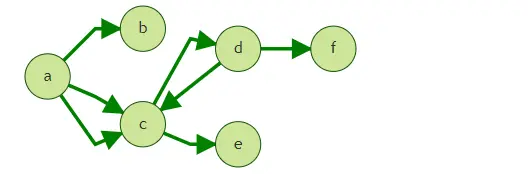
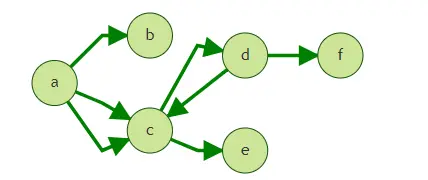
上圖中,假定我們從點a出發,執行query的4跳查詢,
Walk: a->c->a->b, a->c->a->c, a->c->d->f, a->c->d->c
ShortestPath: a->c->d->f
簡單查詢
1. 查詢從a出發的第三跳鄰居
使用gremlin查詢:
g.V('a').out().out().out() g.V('a').repeat(out()).times(3)
以上兩種寫法是等效的,結果為點f,路徑為a->c->d->f,
對應在API引數為:
{ "repeat": [ { "operator": "outV" } ], "emit": false, "times": 3, "vertices": [ "a" ] }
2. 查詢從a出發的三跳內鄰居
使用gremlin查詢:
g.V('a').repeat(out()).times(3).emit()
結果為b,c,d,e,f,
對應在API引數為:
{ "repeat": [ { "operator": "outV" } ], "emit": true, "times": 3, "vertices": [ "a" ] }
組合模式說明
emit+strategy
1. 查詢第三跳鄰居
在上面的圖中,如果按照[簡單查詢1](#1. 查詢從a出發的第三跳鄰居), 將得到點f, c, b,
路徑為a->c->a->b, a->c->d->f, a->c->d->c,
如果,我們只想得到f, 而不希望取到前兩跳已經出現過的點c和b,則需要使用strategy模式中的ShortestPath,ShortestPath模式保證API在traversal的程序中起始點到各點是最短路徑,該模式能夠有效降低多跳查詢中指數增長的查詢量,
gremlin的寫法為:
g.V("a").repeat(out().simplePath().where(without('hops')).store('hops')).times(3).path()
結果為僅為a->c->d->f,
對應在API引數為:
{ "repeat": [ { "operator": "outV" } ], "emit": false, "strategy": "ShortestPath", "times": 3, "vertices": [ "a" ] }
emit+until
1.提前終止traversal模式說明
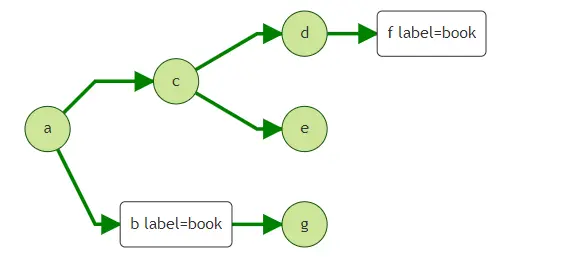
我們以上面的圖來說明該模式,當我們不清楚查詢需要經過多少跳,但希望通過某些條件提前終止遍歷,可以用到until,
如以下兩個問題:
1.得到從a出發N跳內label=book的點, 2.得到從a出發N跳內所有點,停止查詢的條件為遇到label=book的點,
以上問題可以配合emit引數來解決,用gremlin可以寫為:
Q1: g.V('a').repeat(out()).until(hasLabel('book')) Q2: g.V('a').repeat(out()).until(hasLabel('book')).emit()
與之對應的API為:
{ "repeat": [ { "operator": "outV" } ], "until": [ { "vertex_filter": { "property_filter": { "leftvalue": { “label_name": "" }, "predicate": "=", "rightvalue": { "value": "book" } } } } ], "emit": false/true,//這里根據Q1,Q2的情況選擇emit的值, "times": 5, "vertices": [ "a" ], "strategy": "Walk" }
repeat模式說明
repeat+times
可通過引數repeat+times實作多種形式的多跳過濾及repeat模式過濾,
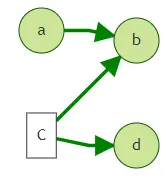
1.僅多跳過濾
gremlin的寫法為:
g.V("a").repeat(out().in()).times() 或 g.V("a").out().in()
對應在API引數為:
{ "repeat": [ { "operator": "outV" }, { "operator": "inV" } ], "strategy": "Walk", "times": 2, "vertices": [ "a" ] }
2.repeat mode
假如我們從點a出發,查詢其帶方向的四跳鄰居,即:
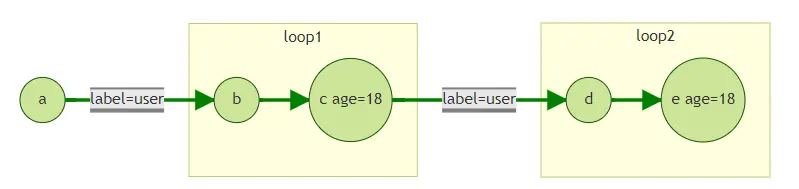
gremlin的寫法為:
g.V('a').repeat(out('user').out().has('age',18)).times(2) 或 g.V('a').out('user').out().has('age',18).out('user').out().has('age',18)
對應在API引數為:
{ "repeat": [ { "operator": "outV", "edge_filter": { "property_filter": { "leftvalue": { "label_name": "" }, "predicate": "=", "rightvalue": { "value": "user" } } } }, { "operator": "outV", "vertex_filter": { "property_filter": { "property_name": { "label_name": "age" }, "predicate": "=", "rightvalue": { "value": "18" } } } } ], "times": 4, "emit": false, "vertices": [ "a" ] }
by模式說明
by模式當前支持兩種形式:
- select+by mode
- by mode
by mode
該模式可針對輸出的點進行輸出格式上的過濾,回傳的格式形如:
{ "data": { "vertices": [ { "id": "47", "label": "user" }, { "id": "51", "label": "user" } ] } }
例如針對二跳鄰居,我們可以通過引數by對id,label,property進行過濾:
g.V("a").repeat(out()).times(2).by(id())
轉化為filtered query V2的形式為:
{ "repeat": [ { "operator": "outV" } ], "times": 2, "vertices": [ "a" ], "by": [{"id": true}] }
select + by mode
該模式可任意選擇traverse路徑上經過的N層,但每層只能在by中指定一個輸出,回傳的格式形如:
{ "select": [ ["李雷", "小明","小智"], ["李雷","韓梅梅", "小智"], ["李雷", "韓梅梅", "小霞"] ] }
下面我們來介紹一下select+by模式,如下圖,我們希望回傳李雷的二跳鄰居的路徑情況,
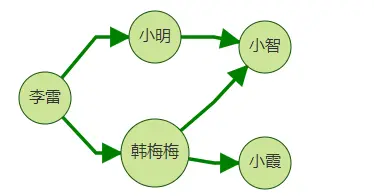
{ "repeat": [ { "operator": "outV" } ], "times": 2, "vertices": [ "李雷" ], "by": [{"id": true},{"id": true},{"id": true}], "select": ["v0", "v1", "v2"] }
g.V('1').as('v0').both().as('v1').both().as('v2').select('v0','v1','v2').by(id()).select(values)
在上面body體中,我們使用select自帶的隱含層數別名v0, v1, v2,其分別表示用戶輸入的點集第0層-v0, K跳中的第1層-v1, K跳中的第2層-v2,
select中選中的別名與by中指定的格式一一對應,
以上案例輸出格式形如:
{ "select": [ ["李雷", "小明","小智"], ["李雷","韓梅梅", "小智"], ["李雷", "韓梅梅", "小霞"] ] }
當然,我們也可以有更多的更豐富的輸出,比如我們希望將輸入點李雷的id和label都展示在路徑中,并且去掉了中間第一跳的好友小明和韓梅梅,直接顯示李雷及其第二跳好友的關系:
{ "repeat": [ { "operator": "outV" } ], "times": 2, "vertices": [ "李雷" ], "by": [{"id": true},{"label": true},{"id": true}], "select": ["v0", "v0", "v2"] }
最終展示結果是對路徑自動去重的,比如在這個例子中,李雷到小智有兩條路徑,中間分別經過好友小明和韓梅梅, 但最終僅顯示了一條,
以上案例輸出格式形如:
{ "select": [ ["李雷", "person", "小智"], ["李雷", "person", "小霞"] ] }
案例
案例一.好友推薦
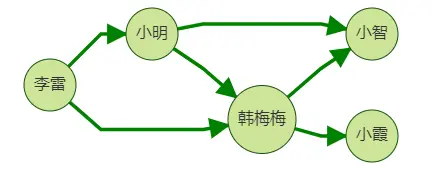
我們向李雷推薦好友,思路是:向他推薦其好友的好友,但是推薦的好友中不應包含李雷本身的好友,比如圖中韓梅梅同時是李雷的一跳好友和二跳好友,這時我們不應向李雷推薦韓梅梅,因為她已經是李雷的好友了,
下面將分別展示使用gremlin,cypher和下一代filter query查詢,回傳均為推薦路徑:李雷->李雷好友->推薦好友,
gremlin
gremlin> g.V("李雷").repeat(out("friend").simplePath().where(without('1hop')).store('1hop')). times(2).path().by("name").limit(100) gremlin> [李雷,小明,小智] [李雷,韓梅梅,小智] [李雷,韓梅梅,小霞]
cypher
match (a)-[:friend]->(d) where id(a)='李雷' with a, collect(d) as neighbor match (a)-[:friend]-(b)-[:friend]-(c) where not (c in neighbor) return a.name, b.name, c.name [ { "row": ["李雷", "小明","小智"], "meta": [null, null, null] }, { "row": ["李雷","韓梅梅", "小智"], "meta": [null, null, null] }, { "row": ["李雷", "韓梅梅", "小霞"], "meta": [null, null, null] } ]
filtered query V2
{ "repeat": [ { "operator": "outV", "edge_filter": { "property_filter": { "leftvalue": { "label_name": "labelName" }, "predicate": "=", "rightvalue": { "value": "friend" } } } } ], "times": 2, "vertices": [ "李雷" ], "by": [{"id": true},{"id": true},{"id": true}], "select": ["v0", "v1", "v2"] } { "select": [ ["李雷", "小明","小智"], ["李雷","韓梅梅", "小智"], ["李雷", "韓梅梅", "小霞"] ] }
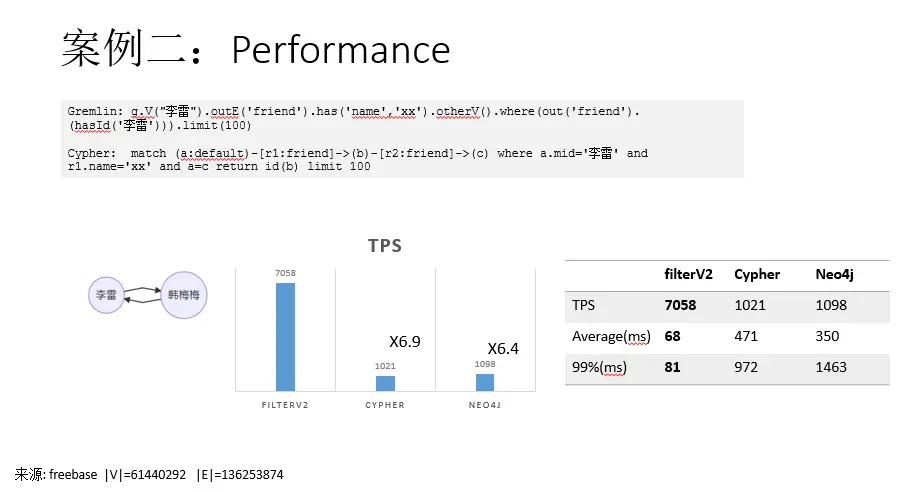
案例二:自環寫法案例
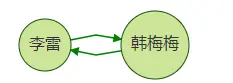
gremlin
gremlin> g.V("李雷").outE('friend').has('name','xx').otherV().where(out('friend'). (hasId('李雷'))).limit(100)
cypher
match (a:default)-[r1:friend]->(b)-[r2:friend]->(c) where a.mid='李雷' and r1.name='xx' and a=c return id(b) limit 100
reference
LDBC Social Network Benchmark (LDBC SNB)
從零開始學Graph Database(1)- 基礎篇-云社區-華為云
Filtered-query V2(2.3.6)_圖引擎服務 GES_API參考_業務面API_華為云
圖引擎服務GES
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/550052.html
標籤:大數據
上一篇:qrtz表初始化腳本_mysql