本篇內容基于 Redis v7.0 的闡述;官網:https://redis.io/
本篇計劃用 Docker 容器輔助部署,所以需要了解點 Docker 知識;官網:https://www.docker.com
系列目錄:
微服務 - 概念 · 應用 · 通訊 · 授權 · 跨域 · 限流
微服務 - 集群化 · 服務注冊 · 健康檢測 · 服務發現 · 負載均衡
微服務 - Redis快取 · 資料結構 · 持久化 · 分布式 · 高并發
一、分布式解決 Session 的問題
在單站點中,可以將在線用戶資訊存盤在Session中,隨時變更獲取資訊;在多站點分布式集群如何做到Session共享呢?架設一個Session服務,供多服務使用,
頻繁使用的資料存在DB端,頻繁的DB連接,頻繁的IO;資料存于記憶體中更能減少性能的消耗,更能提高使用效率,
集群化分布式時,為解決以上現象,建立快取服務顯得尤為重要,
建立快取服務選擇性很多,如:Redis、MongoDB等,以下以 Redis 為例:
作者:[Sol·wang] - 博客園,原文出處:https://www.cnblogs.com/Sol-wang/
二、記憶體資料庫 Redis
Remote Dictionary Server;
遠程字典服務,Key/Value 存盤系統、列存盤、檔案型存盤等,NoSQL開源記憶體資料庫,最多的使用場景是作為資料快取,存在于應用與DB之間,減少對DB的訪問,提高資料操作的性能,
下圖展示了快取服務在整體架構中的位置: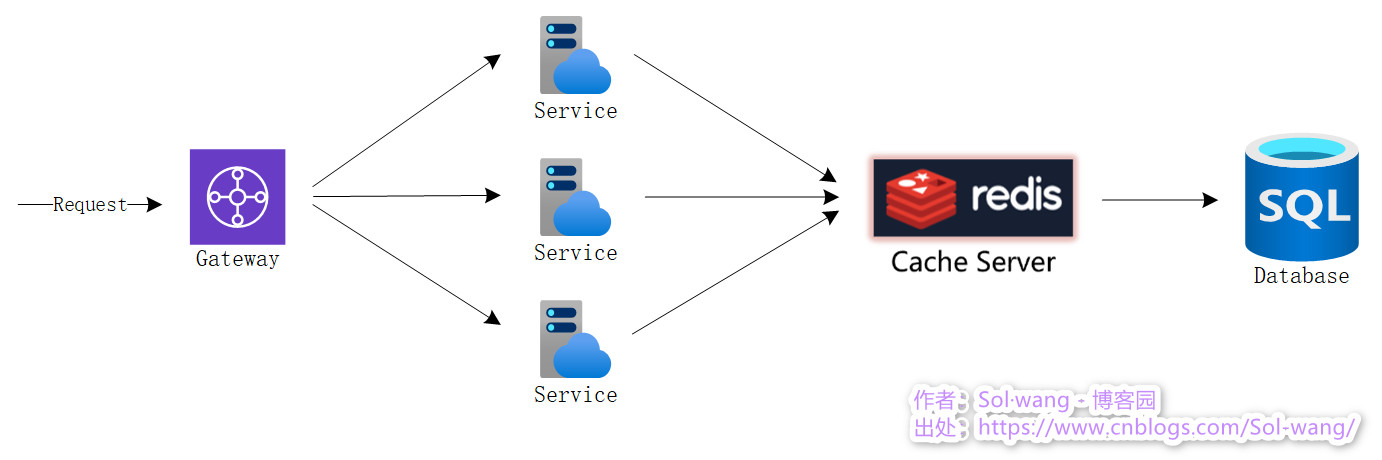
2.1 Redis 特性
高性能 / 高可用 / 持久化 / 集群化,單實體每秒讀寫達10萬次;
豐富的資料型別 :String / Hash / Set / Zset / 佇列 / 訂閱 / 發布;
高性能資料結構:SDS / Intset / ziplist / listpack / quicklist / skiplist;
支持 ACL:Access Control List;精細化的權限管理策略;
單執行緒處理事務:順序執行,容易上鎖;
多執行緒處理輔助功能:連接請求 / 持久化等;
單執行緒處理事務的優缺點
優點:順序執行,不存在臟讀臟寫幻讀等情況,不存在死鎖,不存在執行緒管理的開銷,
缺點:單執行緒的性能瓶頸,多處理器的資源浪費,
2.2 單執行緒IO多路復用
通常情況下,同時連接 Redis 的客戶端有成千上萬的,但 Redis 只有一個主執行緒處理事務,那如何做到多路連接集中到一個執行緒處理呢?
當多個客戶端同時發起連接后,這也是需要一個程序的,也是有連接完成的先后,誰連接完成就會告訴 Redis,這里的告訴用的是回呼方式,Redis就會把他的任務放到單一的佇列中,佇列的另一頭連接著主執行緒,
在這個程序當中,多路的連接匯集到一個有足夠處理能力的佇列中進行傳輸;是不是可以理解為:多路連接重復利用了單個管道;我想...這里也是體現了 Redis 的多路復用技術,當然,單單就多路復用來講,也會是多路集中到一路,然后這一路又分成了多路到各各目標,
多路復用也有不同的演算法:select、poll、epoll,Redis用的是epoll演算法,所以其中有回呼的動作,目前而言,epoll是最高效的;關于每個具體的演算法,有興趣的同學可以繼續研究一下,
2.3 啟動 Redis
用 Docker 啟動 Redis 簡單示例:
1、拉取鏡像docker pull redis
2、運行容器 docker run -d --name=some-redis redis
3、連接到 Redis docker exec -it some-redis redis-cli
Redis Docker版默認是沒有組態檔的,官網說:可以再生成鏡像方式解決...
既然沒有組態檔,那 Redis 啟動完全是按所有配置項的默認值運行的;如下傳參啟動:
# 啟動 redis-server,多引數配置
docker run -d --name some-redis -p 6379:6379 redis redis-server \
--bind 0.0.0.0 \ # 支持任意的連接
--save 60 1 \ # 每60秒 持久化一次
--protected-mode no \ # 取消保護模式
--requirepass 123456 # 登錄密碼 123456;連接后用 auth {passwd} 方式登錄傳參也就是覆寫了配置項的默認值,以下查看覆寫后的配置項效果:config get *列出所有配置項

Redis 啟動后,都包含 redis-server / redis-client;
所以任意 Redis 都可用 redis-client 連接到其它 redis-server:docker exec -it some-redis redis-cli -h {目標IP} -p {目標埠}
2.4 重要配置項
通常配置引數于組態檔中;比如:/etc/redis/redis.conf
| 配置項 | 說明 |
|---|---|
| bind | 可訪問限制,白名單;注釋后不限制 |
| port | 對外埠 |
| timeout | 連接后,沒有通信任務的空閑時間,超出此時長后自動斷開 |
| daemonize | 后臺運行(容器運行時忽略) |
| protected-mode | 只能本地訪問的保護模式 |
| tcp-backlog | 網路連接佇列最大連接數(對應Linux內核引數 net.core.somaxconn,有關命令sysctl) |
| tcp-keepalive | 網路通信檢測間隔,網路是否已斷開(當timeout為0才起效吧) |
| pidfile | 存放ProcessID編號的檔案Pid的存放目錄(后臺運行時才會產生pid檔案,容器時是否忽略) |
| loglevel | 日志級別 |
| logfile | 日志檔案目錄 |
| database | 資料庫個數 |
| requirepass | Client 連接密碼 |
| maxclients | 客戶端同時最大連接數(對應Linux user openfile limit,必設;有關命令ulimit) |
| maxmemory | 記憶體最大使用量,推薦70% |
三、資料型別 / 常用命令
Key/Value 的存盤系統,Key相當于區分的變數名稱,型別區別在于Value;常用資料型別有:
String:字符,基礎型別,過期時長,遞增
SET/GET key value寫入/取值GET key key key取多個值INCR/DECR key遞增1/遞減1
List:佇列,先進先出,先進后出
LPUSH/RPUSH key value頭/尾添加LPOP/RPOP key頭/尾移除LLEN key佇列長度
Set:無序集合,可查詢 交集、并集、差集等
SADD|SREM key member member member插入/移除 元素SISMEMBER key member是否存在成員SINTER key1 key2多集合取交集SCARD key元素個數總數
ZSet:帶排序的Set集合;比Set多出一個專用的score值,又可排出名次列
ZADD key score member score member新增成員及序列數,可覆寫ZRANGE key start stop按序列范圍取集合ZRANK key member取正序排名;從0開始的名次ZREVRANK key member取倒序排名;從0開始的名次
Hash:可同時設定/獲取多個屬性值
HSET key field value field value成對設定多個屬性與值HMGET key field [field field]取多個列的值HINCRBY key field -5指定屬性的值,遞增/遞減
四、資料結構
為什么 Redis 要有自己的資料結構
- 查詢要快:體現在單條Key用了連續性的記憶體空間
- 占用空間少,節約記憶體:體現在了集合的資料壓縮
Redis 中有這么幾種資料結構:sds (動態字串)、hashtable (字典)、linkedlist (鏈表)、intset (整數集合)、ziplist (壓縮串列)、listpack (緊湊串列)、quicklist (混合串列)、skiplist (跳表);它們分別應用于Redis各資料型別中,使得Redis在資源利用和運行效率上有著明顯的效果,
以下列出了資料型別與資料結構的應用關系圖: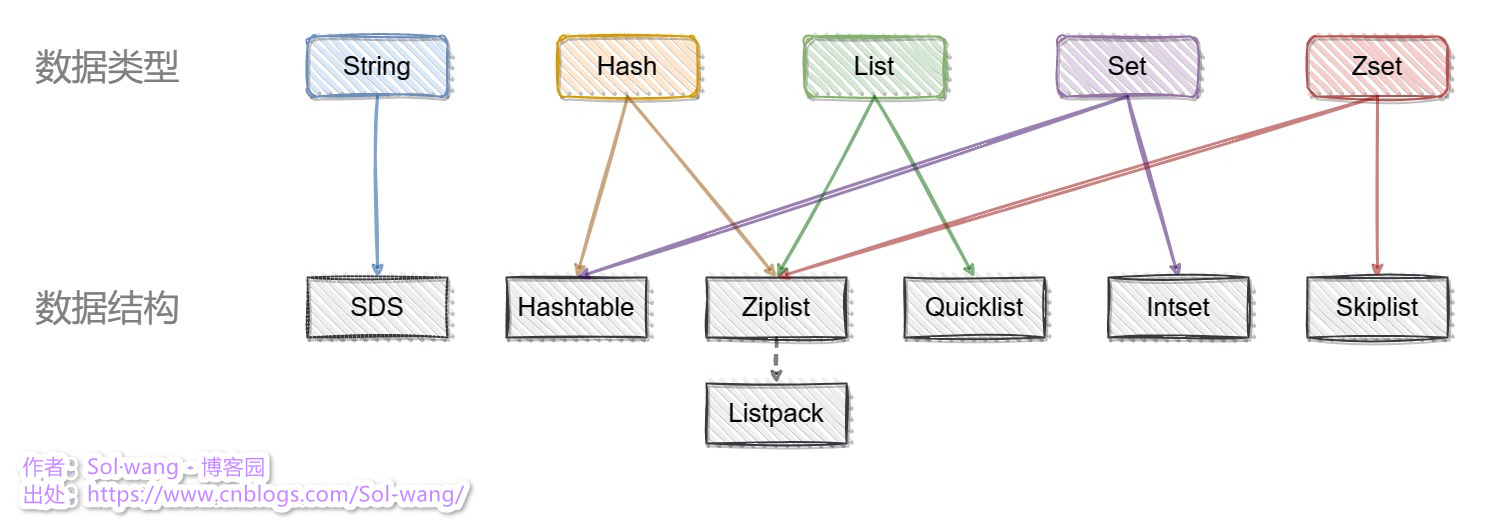
關于 Listpack;未來作為 Ziplist 的升級替代品,v7.0版本也會有 Ziplist 的存在,后續版本中逐漸被替代,
資料結構的自動切換
每種資料型別也會有多種資料結構,至于何種資料型別在什么情況下用何種資料結構,取決于存盤的資料;
比如:List 每元素小于8KB時,自動使用 Ziplist,否則自動切換為 Quicklist;
比如:Set 每元素為數字,元素小于512個時,自動使用 Intset,否則自動切換為 Hashtable;
比如:Hash 元素小于512個,每元素長度小于64位元組,自動使用 Ziplist;否則自動切換為 Hashtable,
影響資料結構轉換的配置項
# 組態檔中 各資料型別中的資料結構
# 能承載的最大長度/個數/容量
# 超出最大限制后,變更為其它資料結構
hash-max-listpack-value 64
hash-max-listpack-entries 512
list-max-listpack-size -2(8KB)
set-max-intset-entries 512
set-max-listpack-value 64
set-max-listpack-entries 128
zset-max-listpack-value 64
zset-max-listpack-entries 128以下主要以 sds / ziplist / listpack / skiplist 為例的闡述,基本涵蓋了重要的資料結構,一些擴展性的資料結構有興趣的同學再深入了解下,
4.1 動態字串 - SDS
很多計算機語言都一樣,Redis 也是基于C語言寫的;對于String型別,當給一個變數拼接一個字串時,都是以一個新物件在記憶體中重新開辟新的更長的連續空間來存盤;重新開辟/釋放舊空間這樣的記憶體損耗,,,所以為什么開發人員會避免strname + "xxx"這樣的拼接方式;字串長度也是底層每次通過遍歷得出的結果,,,Redis為了避免這樣的損耗,于是就有了 Simple Dynamic Strings 這樣的解決方案 SDS,
Redis String 會事先分配好比實際字串更長的記憶體空間,并記錄實際字串的長度,也記錄存盤后剩余的空間長度,
- 取字串長度時,直接回傳記錄的長度值
- 追加字串時,直接使用空閑的剩余空間
預分配空間有多長?總有用完的時候:
- 當實際字串長度<1M時,預分配實際字串兩倍的連續長度,相當于本次只會占用一半
- 當實際字串長度>1M時,每次預分配多出1M的長度空間,便于下次直接存盤
- 當字串減少縮短時,多出的剩余空間保留,便于下次追加,或手動命令清除空閑空間
這種 空間預分配策略 和 惰性洗掉策略 就是SDS的性能優勢,
4.2 壓縮串列 - ziplist
一塊連續性的記憶體空間存放了整個Value,也就是一個ziplist,如何做的呢?一個集合的示例:
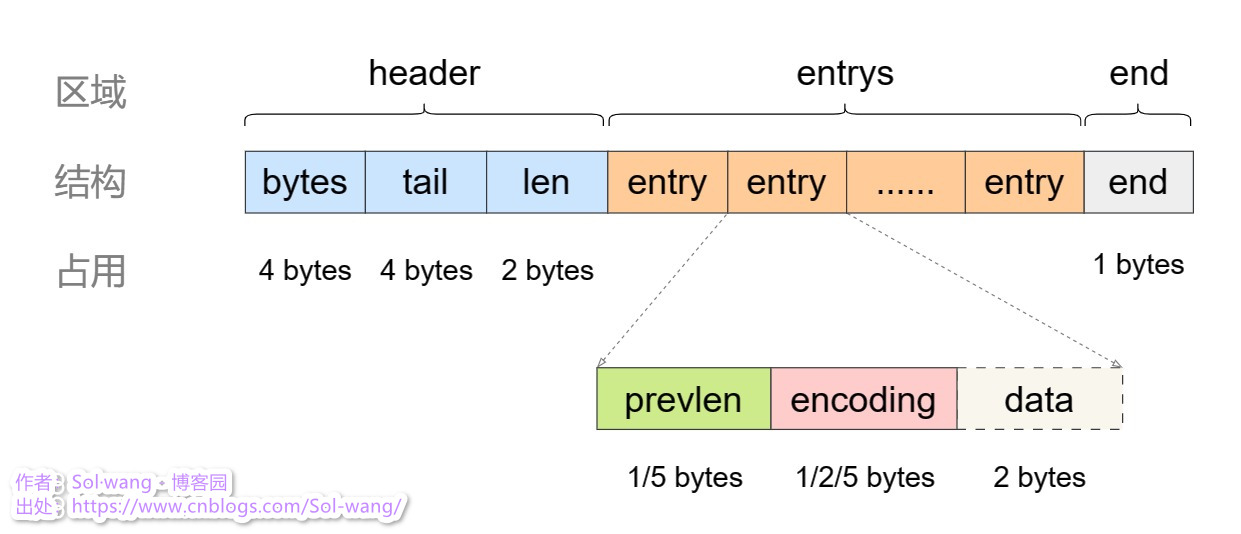
bytes:記錄 ziplist 的總長度
tail:記錄最后一個 entry 的偏移量,便于快速定位
len:記錄 entry 的總個數
entry:串列元素,資料存放的元素
end:單個 ziplist 的結束符
prevlen:記錄上個 entry 的總長度;這里記錄值所占用的空間長度,取決于上個 entry 的長度,所以1-5會自動切換
encoding:記錄 data 的實際資料型別 及長度;如:int時占空間小,可直接存到 encoding,就不用 data 了
data:實際資料;占用空間小的資料型別,可直接放到 encoding 中,所以這時候沒有 data 的存在,省空間,
ziplist 的取值:
結構圖中,有總長/個數/偏移量/結束符/上個元素長度;所以 ziplist 正序倒序是都可以算出每個 entry 具體位置并取出資料,
ziplist 的寫入,插/改/刪 統一為覆寫方式:
1、為新元素找到被覆寫元素的位置,位置之前的元素 + 新元素 + 位置之后的元素 = 新的ziplist的完整結構
2、申請新ziplist所需長度的記憶體連續空間,并存入新空間
3、釋放舊空間
看起來挺不錯的,相比鏈表的非連續性存盤所帶來的性能提升明顯,,那為什么還會有新的改進版本 listpack 的出現?
ZIPLIST 的弊端
ziplist 的問題出在 prevlen;
也就是上面藍色部分的描述,存了相鄰 entry 的長度;如果 entry 長度過長,相鄰的 prevlen 所占空間長度就會從1變為5;也就是說 entry 資料變更,會影響到相鄰的 entry;最嚴重的情況是很多entry長度恰好都在一個臨界值,會導致相鄰prevlen長度的變化,連鎖反應是之后位置上的entry級聯性的連續重復多次變更;
上面提到,變更:就是重新申請新的記憶體連續空間,釋放舊空間;那么級聯性的連鎖反應呢?一個寫操作,引發的惡性災難事件!!!
4.3 緊湊串列 - listpack
listpack 是 ziplist 的升級版于v7.0中,作為替代品都有什么變化,listpack結構如下圖: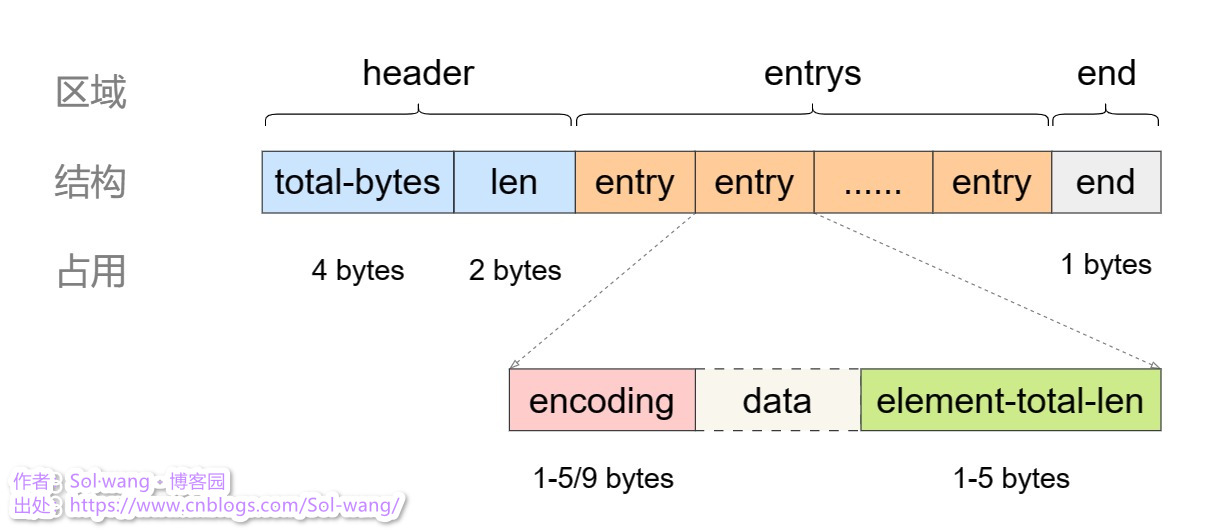
上圖看出,listpack 與 ziplist 的區別在于:
1、header 取消 tail
2、entry 取消 prevlen
3、當前 entry 中增加 encoding + data 的總長度 element-total-len
4、element-total-len 中的首位會標識出左側是否還有值,主要用于逆序讀
element-total-len 編碼
長度 1-5 bytes 是可變的,不固定長度如何讀出整個 element-total-len?這其中0/1標識了左側是否有資料;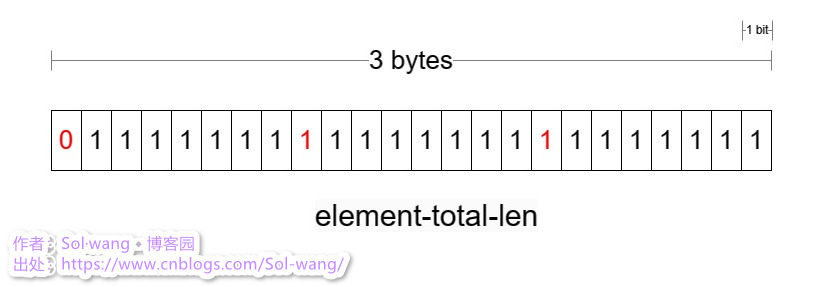
listpack 的讀,假設逆序讀出每個元素的值,已知end固定長度,跳過 1 bytes 到 element-total-len 中讀固定(7)位數,就會知道左側是否有值,這樣會把 element-total-len 整個讀下來,也就知道了當前 entry 長度,那么也就知道了相鄰 entry 的起始位置;繼續這樣按序把每個 entry 讀出來就完成逆序讀資料,
listpack 的寫入,同樣是基于 ziplist 的方式,新元素替換舊元素組成新的長度,存盤到新申請的記憶體連續空間,釋放舊空間;由于未影響到其它元素,申請一次新空間后完成寫入操作,
這樣以來,listpack 任何寫入的操作,entry 都是在變更自己,不會牽連到其它 entry,這就是對 ziplist 改善的地方,
4.4 跳躍串列 - skiplist
跳表是在鏈表的基礎上追加了更多指標的存盤;鏈表的指標指向了相鄰元素的地址,但跳表又追加了指向間隔元素的指標;這使得跳表在查詢元素的效率上更快,
下表 Linkedlist 與 Skiplist 的查詢區別: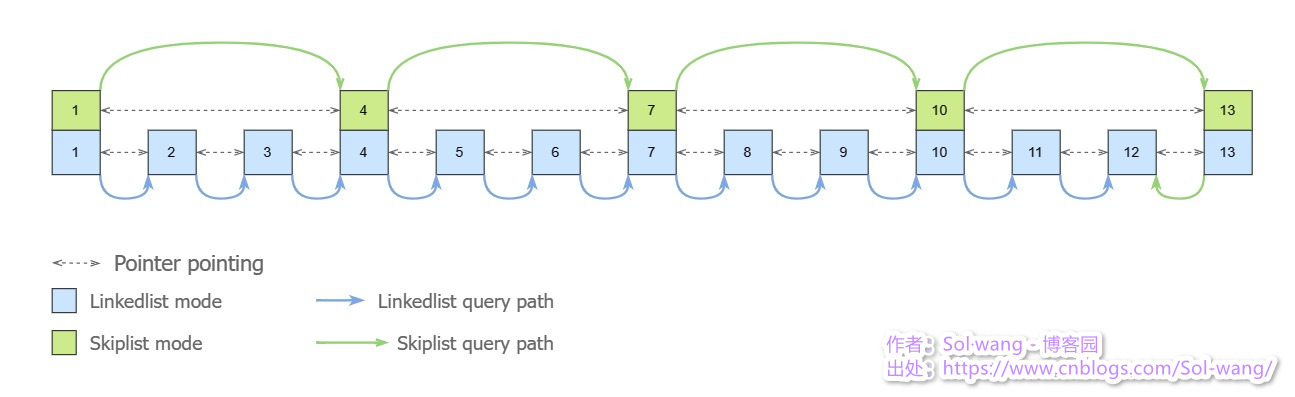
上圖:兩種查詢的路徑不同,影響到的元素數量也不同,鏈表搜了11次才找到指定的元素,而跳表僅搜了5次就找到了指定的元素,
比如:元素1 既存了指向下個元素2 的指標,也存了指向元素4 的指標;所以跳表多存的指標讓其可以跳躍搜索,相對于鏈表減少了搜索次數,這就體現了相比鏈表搜索的高效率,
其它資料結構
除以上幾種資料結構外,Redis也會有Intset、quicklist、Hashtable等,由于基本原理相識,這里簡單描述:
Intset:與ziplist、listpack相似的連續性集合,主要區別在于Intset僅支持數字型;
quicklist:在 ziplist 基礎上擴展的資料結構,其中每個成員是一個ziplist,插入元素時:插入到前個元素ziplist中的末尾、后ziplist的開頭、或獨立的ziplist,
五、持久化
5.1 RDB 模式
Redis Database:持久化以指定的時間間隔執行資料集的時間點的快照整庫備份,
觸發RDB配置:save 36000 1 600 10 30 100
以上從右往左,成對解釋:
??當30秒內寫入了100次,觸發持久化,如果未滿足條件,繼續下一對;
??當600秒內寫入了10次,觸發持久化,如果未滿足條件,繼續下一對;
??當36000秒內寫入了1次,觸發持久化,
持久化程序:記憶體 -> 臨時檔案 -> 磁盤,
影響RDB效率的配置項:
??stop-writes-on-bgsave-error yes當持久化失敗后強制停止寫入
??rdbcompression yes快照資料壓縮,損耗CPU
??rdbchecksum yes是否檢測備份檔案,損耗CPU≈10%
關閉RDB持久化模式:save ""
模式優劣
優勢:體積小,占用磁盤少,
劣勢:當持久化發生例外時,最后一次的持久化有可能失效,不能確保整體資料的絕對完整性,
5.2 AOF 模式
Append Only File:追加記錄服務器接收到的每個寫入命令,增量保存;如果寫入錯誤,Redis 也會具有自動修復受損的AOF檔案;恢復時,重新按序執行指令,從而重建記憶體庫,
配置開啟AOF模式:appendonly yes
持久化頻率策略配置:appendfysnc always|everysec|no
- 每次命令追加:每次寫命令立刻記錄,太頻繁,太耗性能
- 每秒追加一次:每秒集中記錄一次,依然有可觀的性能表現
檔案壓縮 Rewrite
主行程 redis-server 創建出一個子行程 bgrewriteaof 對 AOF檔案的重新整理,先整理出一個臨時檔案,再覆寫原AOF檔案,
Rewrite 的重寫策略:
- 只針對寫入命令的整理
- 相同資料只記錄最后寫入命令
- 過期資料不記錄
- 多命令合并記錄
多命令合并示例:如累加命令 Incrby 的累加總和合并成一次累加;如集合命令 rpush 的多次追加合并成一次追加多個,
手動觸發執行重寫命令:bgrewriteaof,
自動觸發重寫相關配置:no-appendfsync-on-rewrite no重寫開關auto-aof-rewrite-min-size 64mb重寫觸發條件,檔案超過指定大小auto-aof-rewrite-percentage 100重寫觸發條件,檔案超過已使用%
AOF檔案64MB是不是顯得太小了,可適當增加容量如3GB,以防止過多的觸發壓縮重寫后影響性能;也不可過大,影響資料恢復效率,
模式優劣
優勢:丟失率低,資料較完整,
劣勢:AOF占用磁盤空間大;恢復時重新全部執行一遍命令,恢復速度慢了點;持久化失敗時,最后一秒寫入命令可能丟失,
Redis 默認開啟 RDB,可同時開啟 RDB + AOF,恢復資料時以 AOF 為優先,
由于是單執行緒方式,Redis 會創建子執行緒負責持久化處理,不管是哪種持久化方式,在創建子行程的瞬間,都會有阻塞的現象,
六、分布式集群
6.1 虛擬插槽
Redis 分布式給出一個 16384 長度的集合,每個元素稱為一個 Slot,將所有 Slots 分段平均映射到各個 Master 節點上;資料通過對 Key 的演算法映射到各Slot,也就存到了對應的 Master 節點上,所以每個節點實體負責其中一部分的Slot讀寫,
通過控制節點與槽 Slot 的關系,決定每個 Master 節點所承載的資料量;這在集群節點維護的時候非常有用,
6.2 創建集群
集群必須了解的conf配置項:
# 每個節點必須的配置項
cluster-enabled yes
# 節點失去連接超時時間
cluster-node-timeout 15000
# 節點間傳輸效率 默認 no(yes:單次多量發送/no:單次少量多次發送)
tcp-nodelay no
# DOCKER/NAT support
# (地址埠可能被轉發)靜態配置公共地址
cluster-announce-ip <外部訪問IP>
cluster-announce-port <外部訪問埠>
cluster-announce-bus-port <節點互通外部埠>按 Redis 要求的最低 Master 節點數量3實體,多主多從的模式,需要創建6個運行實體:(6371-6376,16371-16376)
# 實體示例1(6371,16371)
docker run -d --name clu-rds-1 \
-p 6371:6371 -p 16371:16371 \ # 容器分別開放 對外連接埠 和 節點間通信埠
redis \
redis-server \ # 啟動 Redis 服務命令
--bind 0.0.0.0 \ # 不限連接的客戶端來源
--port 6371 \ # 實體對外連接埠
--protected-mode no \ # 非保護模式
--cluster-enabled yes \ # 開啟集群
--cluster-announce-ip 13.13.1.16 \ # 對外的訪問IP
--cluster-announce-port 6371 \ # 集群對外的連接埠
--cluster-announce-bus-port 16371 # 集群節點間通訊埠(通常為:10000+Port)Docker 查看6個容器實體:
Docker 3主3從模式 創建集群:
docker exec -it clu-rds-1 \
# 連接到任意實體
redis-cli -p 6371 \
# 創建集群 并指定 1主幾從
--cluster create --cluster-replicas 1 \
# 要包含的所有(6個)運行實體<ip:port>
13.13.1.16:6371 13.13.1.16:6372 13.13.1.16:6373 \
13.13.1.16:6374 13.13.1.16:6375 13.13.1.16:6376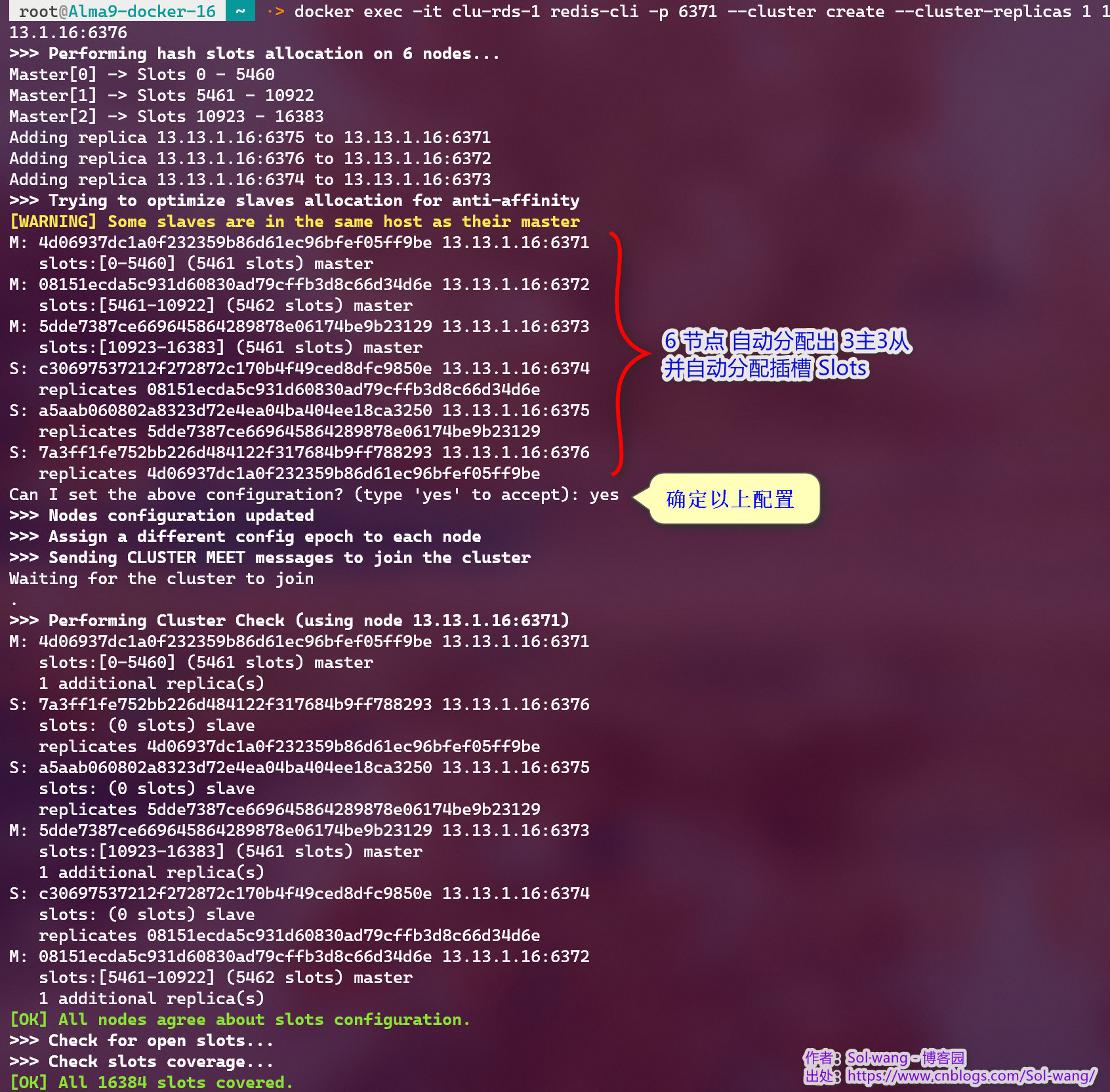
連接到任意容器節點,查看集群成員:docker exec -it <container-name> redis-cli -p <container-port> cluster nodes

6.3 節點管理
# 集群資訊
redis-cli -p <port> cluster info
# 查看現有節點成員
redis-cli -p <port> cluster nodes
# 加入新成員,從節點
redis-cli --cluster add-node <new-node-ip:port> <cluster-member-ip:port> \
--cluster-slave --cluster-master-id <to-master-id>
# 洗掉集群成員節點
redis-cli --cluster del-node <del-ip:port> <del-node-id>
# 重新分配節點與插槽映射
redis-cli --cluster reshard <member-ip:port>
# 查看某節點同步資訊
redis-cli -p <port> info replication
# 停止某節點實體運行
redis-cli -p <port> shutdown分布式帶來的影響
事務支持有限;
跨節點的多Key操作有限;如:SET集合不能計算兩KEY的交集等
6.4 分布式鎖
6.4.1 為什么會需要鎖?
??場景 A:
多用戶對同一產品下單購買,庫存有10個,同一時間進來100個用戶各買一個;
購買前都會看下庫存是否夠買,才會生成訂單,否則提醒無貨;
當前10個用戶還沒有下單成功并未扣庫存完成時,后90個用戶看到有庫存,也繼續生成訂單;
最后賣出100各產品,實際庫存不夠,,,
如何確保有庫存,不超買,
對庫存加鎖,每個用戶按序進來扣庫存,當前用戶扣完庫存后,釋放自己加的鎖,以視完成操作繼續后續用戶,下個用戶再進來看庫存是否能購買,
??場景 B:
當某個用戶下單扣庫存時,倘若發送了例外,導致未能釋放自己加上去的鎖,那么,,,沒人負責釋放此鎖了,后續不能查扣庫存,誰也不能下單了,
如何確保防止不能解鎖,
對庫存鎖加過期時間,時間超出后,自動強制解鎖,
是的,加鎖、過期自動解鎖,是確保以上場景能夠順利進行的必要條件,共享資料被多用戶處理的時候,同一時間點,只能被一個用戶訪問處理,多用戶有序訪問處理,及時更新處理結果,
共享鎖:資料統一放快取中做業務處理,在快取中加鎖,供所有服務利用,
6.4.2 SET NX EX 命令
- SET:String 型別的KV操作
- NX:Key唯一,僅當沒有Key時才能寫入
- EX:Key 的有效時長,到期后自動洗掉
所以完整的命令為:set {business-key} {value} nx ex {過期時長}
回傳失敗,表示上個用戶正使用
回傳成功,表示自己已開始使用
符合分布式鎖的必要條件
1、當 get {business-key} 有值時,表示已有用戶在占用,需要等待
2、當 占用用戶處理完成后,正常釋放自己加的鎖,del {business-key}
3、當 占用用戶處理發生例外退出時,等ex {過期時長}后,系統自動解鎖,后續用戶繼續購買
命令演示案例:(ttl:剩余過期時間秒)
也可以在 Value 中保存用戶的標識,解鎖的時候只能解除自己的鎖,防止某些場景下解鎖錯誤,
分布式Id
由于 Redis Incrment (Incr/Incrby),過期時長等,可以限制用戶短時間內的下單量等場景,也可以生成唯一標識,用到各服務中,
6.4.3 Lua 腳本
持續更新,,,
七、高并發帶來的問題
7.1 快取穿透
現象:
DB沒有查詢結果或為NULL,導致查詢結果沒有進入到快取;當大批量的這種請求時,就會每次“穿透”快取“直抵”DB,引發DB的高并發查詢導致宕機,這種現象就叫快取穿透,
方案:
黑名單策略(IP/用戶名),防止惡意行為
對結果為空的DB查詢,給出默認值于快取中
7.2 快取擊穿
現象:
單個訪問量大的 Key (熱門資料)過期后,快取需要重建該Key,大量的訪問到DB引發高并發查詢,導致DB宕機,這種情況稱為快取擊穿,
方案:
當然也可以使用佇列,就降低了并發的性能;也可以設定過期時間為永不過期;以下的重點是快取重建Key的程序:雙重鎖機制
雙重鎖邏輯闡述:(也常應用于單例模式中)
第一把鎖處理首個請求動作是否已有快取,并擋住了第二或大量的后續請求動作;
當首個請求動作處理完成后結果于快取中,并釋放鎖,處于等待的大量的請求動作會陸續進來,這就不對了,等待的請求動作應該直接用首個請求處理的結果才對;
所以,后續的請求進來后應該再次鎖驗證快取中是否已有資料,也就是第二次的鎖是為了解決并發時被阻塞的請求動作,防止重復查詢DB更新快取,
7.3 快取雪崩
現象:
快取中的熱門 Key 短時間內大批量的同時過期,快取運行正常,導致DB查詢壓力短時間內上升至宕機的現象,
方案:
隨機的過期時間,分散過期時間,避免統一生成過期時間
為熱度追加排名,時時調整熱度資料,自動延長過期時間
鄙人拙見,有不妥望指出,萬分感謝,作者:Sol·wang - 博客園
出處:https://www.cnblogs.com/Sol-wang/p/17329270.html
宣告:本文著作權歸作者和[博客園]共有,未經作者同意,不得轉載,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/550484.html
標籤:NoSQL
上一篇:Redis---哨兵服務
下一篇:Redis---主從復制