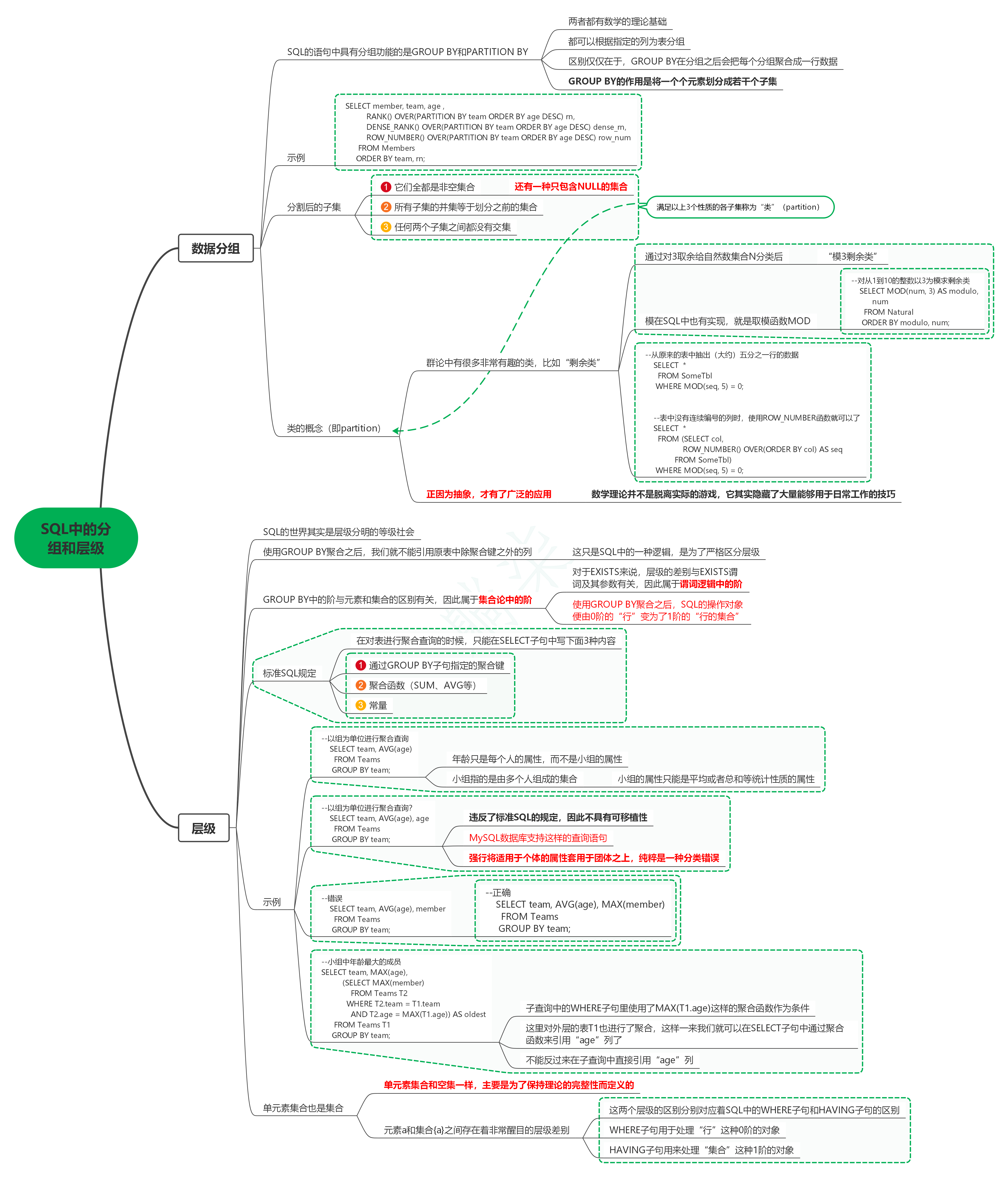
1. 資料分組
1.1. SQL的陳述句中具有分組功能的是GROUP BY和PARTITION BY
1.1.1. 兩者都有數學的理論基礎
1.1.2. 都可以根據指定的列為表分組
1.1.3. 區別僅僅在于,GROUP BY在分組之后會把每個分組聚合成一行資料
1.1.4. GROUP BY的作用是將一個個元素劃分成若干個子集
1.2. 示例
1.2.1.
SELECT member, team, age ,
RANK() OVER(PARTITION BY team ORDER BY age DESC) rn,
DENSE_RANK() OVER(PARTITION BY team ORDER BY age DESC) dense_rn,
ROW_NUMBER() OVER(PARTITION BY team ORDER BY age DESC) row_num
FROM Members
ORDER BY team, rn;
1.3. 分割后的子集
1.3.1. 它們全都是非空集合
1.3.1.1. 還有一種只包含NULL的集合
1.3.2. 所有子集的并集等于劃分之前的集合
1.3.3. 任何兩個子集之間都沒有交集
1.3.4. 滿足以上3個性質的各子集稱為“類”(partition)
1.4. 類的概念(即partition)
1.4.1. 群論中有很多非常有趣的類,比如“剩余類”
1.4.1.1. 通過對3取余給自然數集合N分類后
1.4.1.1.1. “模3剩余類”
1.4.1.2. 模在SQL中也有實作,就是取模函式MOD
1.4.1.2.1. --對從1到10的整數以3為模求剩余類
SELECT MOD(num, 3) AS modulo,
num
FROM Natural
ORDER BY modulo, num;
1.4.1.3. --從原來的表中抽出(大約)五分之一行的資料
SELECT *
FROM SomeTbl
WHERE MOD(seq, 5) = 0;
--表中沒有連續編號的列時,使用ROW_NUMBER函式就可以了
SELECT *
FROM (SELECT col,
ROW_NUMBER() OVER(ORDER BY col) AS seq
FROM SomeTbl)
WHERE MOD(seq, 5) = 0;
1.4.2. 正因為抽象,才有了廣泛的應用
1.4.2.1. 數學理論并不是脫離實際的游戲,它其實隱藏了大量能夠用于日常作業的技巧
2. 層級
2.1. SQL的世界其實是層級分明的等級社會
2.2. 使用GROUP BY聚合之后,我們就不能參考原表中除聚合鍵之外的列
2.2.1. 這只是SQL中的一種邏輯,是為了嚴格區分層級
2.3. GROUP BY中的階與元素和集合的區別有關,因此屬于集合論中的階
2.3.1. 對于EXISTS來說,層級的差別與EXISTS謂詞及其引數有關,因此屬于謂詞邏輯中的階
2.3.2. 使用GROUP BY聚合之后,SQL的操作物件便由0階的“行”變為了1階的“行的集合”
2.4. 標準SQL規定
2.4.1. 在對表進行聚合查詢的時候,只能在SELECT子句中寫下面3種內容
2.4.2. 通過GROUP BY子句指定的聚合鍵
2.4.3. 聚合函式(SUM、AVG等)
2.4.4. 常量
2.5. 示例
2.5.1. --以組為單位進行聚合查詢
SELECT team, AVG(age)
FROM Teams
GROUP BY team;
2.5.1.1. 年齡只是每個人的屬性,而不是小組的屬性
2.5.1.2. 小組指的是由多個人組成的集合
2.5.1.2.1. 小組的屬性只能是平均或者總和等統計性質的屬性
2.5.2. --以組為單位進行聚合查詢?
SELECT team, AVG(age), age
FROM Teams
GROUP BY team;
2.5.2.1. 違反了標準SQL的規定,因此不具有可移植性
2.5.2.2. MySQL資料庫支持這樣的查詢陳述句
2.5.2.3. 強行將適用于個體的屬性套用于團體之上,純粹是一種分類錯誤
2.5.3. --錯誤
SELECT team, AVG(age), member
FROM Teams
GROUP BY team;
2.5.3.1. --正確
SELECT team, AVG(age), MAX(member)
FROM Teams
GROUP BY team;
2.5.4. --小組中年齡最大的成員
SELECT team, MAX(age),
(SELECT MAX(member)
FROM Teams T2
WHERE T2.team = T1.team
AND T2.age = MAX(T1.age)) AS oldest
FROM Teams T1
GROUP BY team;
2.5.4.1. 子查詢中的WHERE子句里使用了MAX(T1.age)這樣的聚合函式作為條件
2.5.4.2. 這里對外層的表T1也進行了聚合,這樣一來我們就可以在SELECT子句中通過聚合函式來參考“age”列了
2.5.4.3. 不能反過來在子查詢中直接參考“age”列
2.6. 單元素集合也是集合
2.6.1. 單元素集合和空集一樣,主要是為了保持理論的完整性而定義的
2.6.2. 元素a和集合{a}之間存在著非常醒目的層級差別
2.6.2.1. 這兩個層級的區別分別對應著SQL中的WHERE子句和HAVING子句的區別
2.6.2.2. WHERE子句用于處理“行”這種0階的物件
2.6.2.3. HAVING子句用來處理“集合”這種1階的物件
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/550722.html
標籤:MySQL
下一篇:返回列表