
一、背景
知乎業務中存在哪些問題需要解決?
為什么要建立 DMP 平臺來解決這些問題?
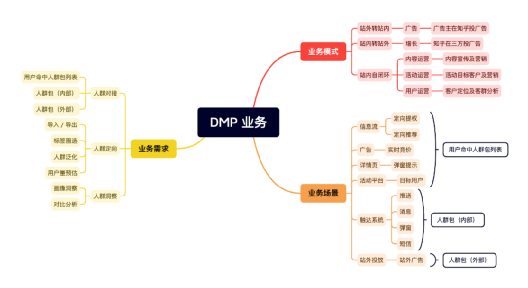
2、DMP 業務流程
當前這些業務的運營流程是怎樣的?
DMP 如何與業務結合并賦能?
其中運營模式包含如下 3 類:
1)站內運營自倍訓
-
內容運營,拿內容找用戶,定向消費用戶,站內投放,分析效果和人群成分等,
-
活動運營,拿活動找用戶,定向消費用戶,站內投放,分析效果和人群成分等,
-
用戶運營,洞察用戶,分析,
2)站內向站外投放倍訓
-
增長投放,定向合適的人群,并在站外投放廣告,資料回收,效果分析,
3)站外向站內廣告倍訓
-
廣告投放,站外用戶匯入,定向投放,或基于對目標群體的理解圈選定向投放,
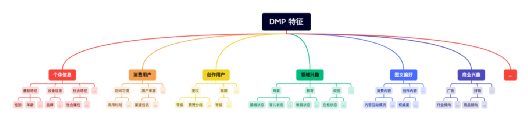
3、DMP 畫像特征
當前有哪些畫像特征?
這些特征是如何分層分類的?
量級如何?
3 層級特征分類:
一級分類 (8 組)
二級分類 (40 組)
標簽組(120 個)
性別、手機品牌、話題興趣…
標簽(250 萬)
男|女、 HUAWEI|Apple、對影視內容感興趣程度高…
二、架構與實作
1、DMP 功能梳理
DMP 通過設計哪些功能模塊,支持相應的業務流程?
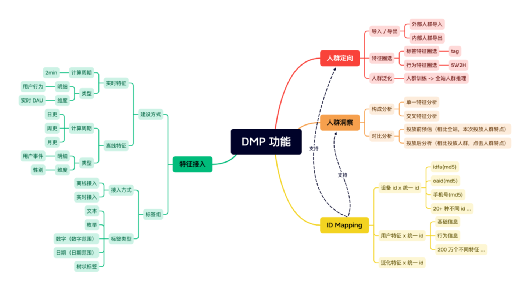
2、DMP 架構
DMP 通過設計哪些功能模塊,支持相應的業務流程?
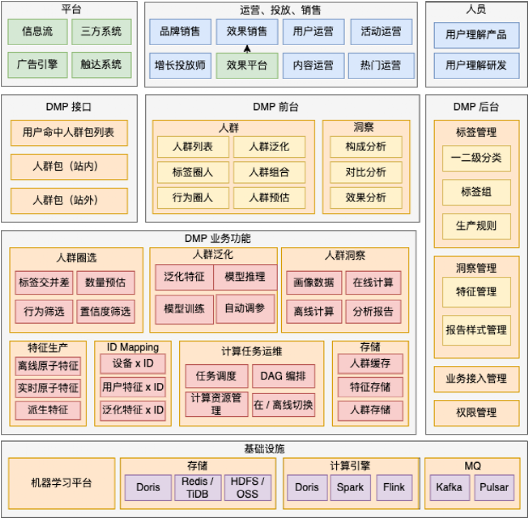
架構設計重點是解決業務功能的實作復雜度,同時架構設計也是明確模塊重心和設計目標的一種重要手段,拆分后,不同模塊都有不同的設計重心:
1)對外模塊,針對使用方定制設計,
-
DMP 介面:高穩定性、高并發高吞吐
-
DMP 前臺:操作簡單,低運營使用成本
-
DMP 后臺:日常開發作業配置化,降低開發成本
2)業務模塊,以可擴展為第一要務,
-
人群圈選:可擴展,新增特征 0 成本,新增規則低成本,
-
人群洞察:可擴展,新增特征 0 成本,新增洞察方式低成本,
-
人群泛化:可擴展,新增泛化方式低成本,
3)業務支持模塊,線性水平擴展及屏蔽內部邏輯,
-
特征生產:擴展成本低,原子特征低成本生產,派生特征通過后臺可配置
-
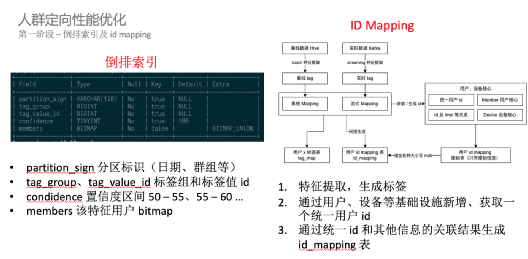
ID Mapping:屏蔽 ID 打通邏輯
-
計算任務運維:屏蔽機器資源和任務依賴的邏輯
-
存盤:可擴展可持續,不因業務成長而導致成本大幅增加
3、DMP 平臺功能盤點
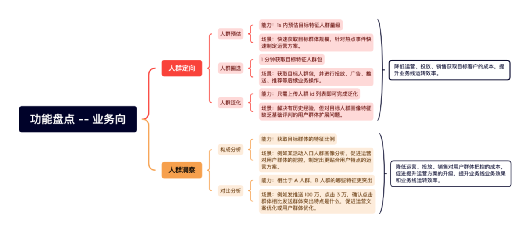
DMP 上線至今支持了:
-
5+ 萬人群定向
-
400+ 次人群洞察
-
60+ 次人群泛化
資料量級:
-
120 個標簽組
-
250 萬個標簽
-
1100 億條用戶 x 標簽的資料
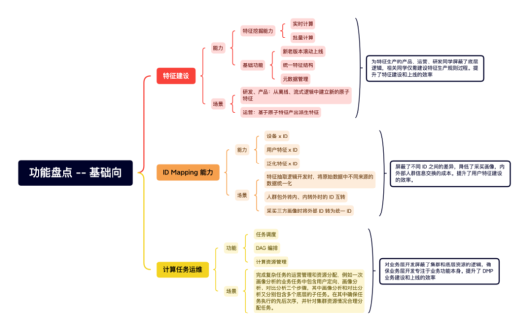
資料量級:
-
每日 2.x TB 共 5 日 11 TB(離線、實時)特征(Doris)
-
120 個離線生產任務和 5 個實時生產任務
-
每日 6100 次人群預估,300 個人群圈選,1-2 個人群洞察,1 個人群泛化任務
4、特征資料鏈路及存盤
DMP 的批量、流式特征如何建設并落地到相應的存盤?
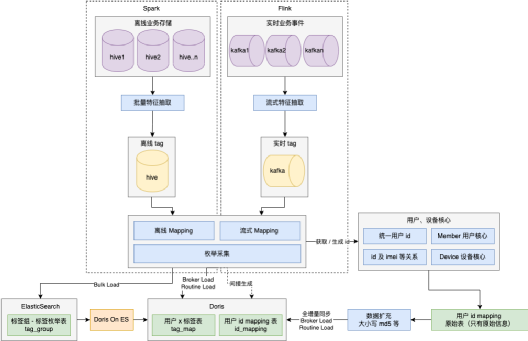
資料量級:
1)特征鏈路
-
離線 Spark:Hive -> 特征抽取 -> 離線標簽 -> mapping -> Doris / ES / HDFS
-
實時 Flink:Kafka -> 特征抽取 -> 實時標簽 -> mapping -> Doris / ES / HDFS
2)存盤
① Doris
-
用戶 x 標簽:用戶有哪些標簽(1100 億)
-
id mapping:id 轉化寬表(8.5 億)
② ElasticSearch
-
標簽列舉表:標簽中文資訊及搜索(250 萬)
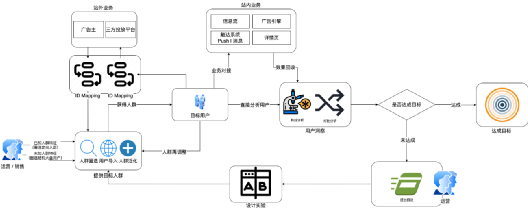
5、人群定向流程
人群定向分哪幾個程序?怎么做的?
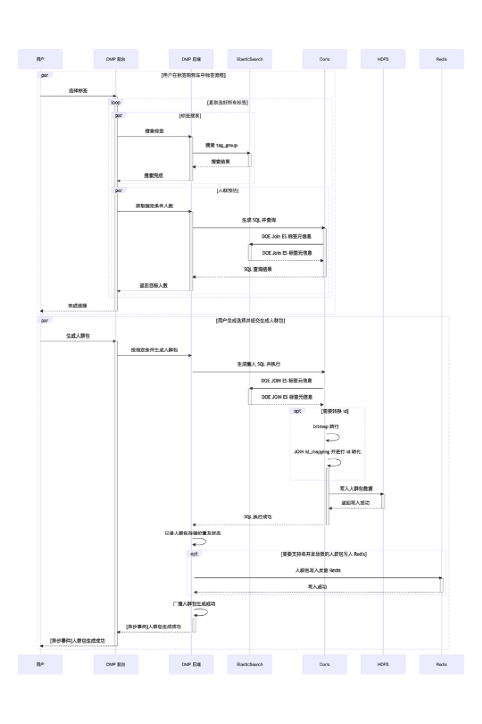
子流程:標簽搜索、標簽選擇、人群預估、人群圈選
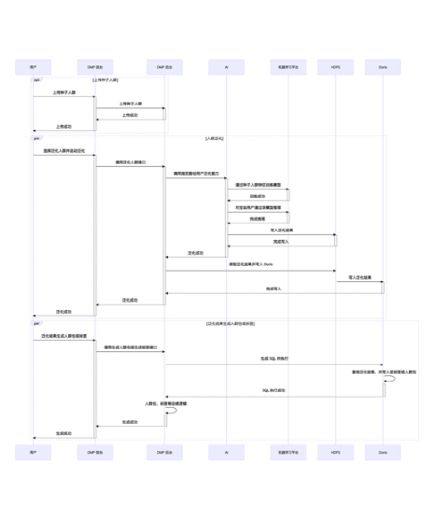
子流程:種子人群上傳、人群泛化
流程圖中主要介紹了:標簽搜索、標簽選擇、人群預估、人群圈選、種子人群上傳、人群泛化幾個子流程的執行程序,具體在業務上執行的人群定向流程很多,以下說幾種典型的:
-
標簽加購物車 -> 圈選,
-
傳種子人群 -> 泛化,
-
歷史效果人群 -> 泛化 -> 疊加本次運營特點 -> 圈選,
-
歷史效果人群 -> 洞察 -> 重新生成標簽關系 -> 圈選 -> 疊加歷史正向人群 -> 泛化 -> 限制分發條件 -> 圈選,
-
對標簽、歷史人群進行組合、泛化、再限制條件再圈選、洞察,最后再調整等等,
三、難題及解決方案
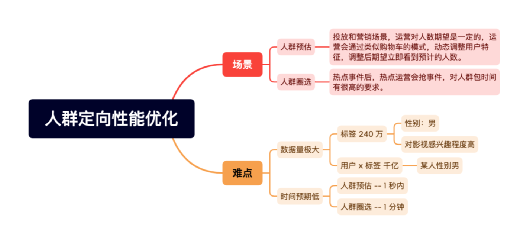
在 DMP 業務中,我們主要遇到了人群定向方面的難題,難題的原因主要有:1、人群特征數量大(1200 億);2、時間要求低(人群預估 1 秒,圈選 1 分鐘),
1、優化第一版
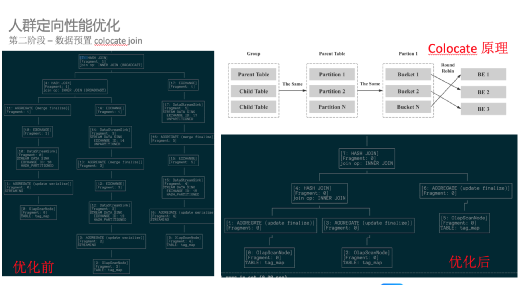
倒排、id mapping 以及查詢邏輯優化
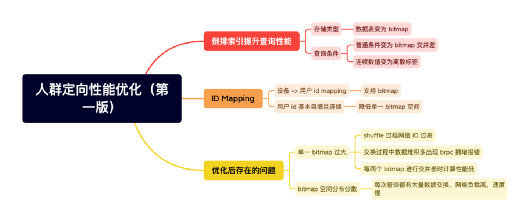

2、優化第二版
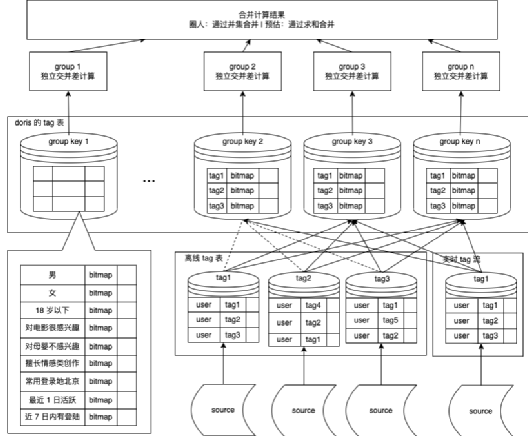
分而治之
-
將連續一塊的用戶 id 的不同 tag 的資料,都增加統一的 group 欄位進行分組,
-
在 group 內完成交并差后,最后進行資料匯總,
-
同時開啟多執行緒模式,提升每組的計算效率,
四、未來及展望
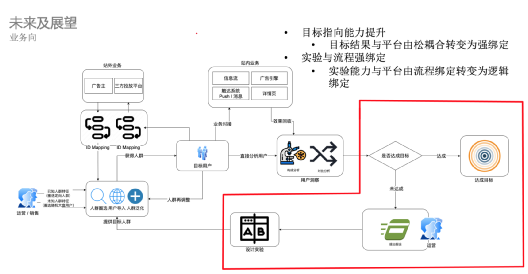
1、業務向
2、技術向
1)提升查詢效率
-
自動探測 SQL 復雜查詢條件預先合并成一個派生特征的 bitmap,預測和圈人時對復雜條件 SQL 重寫為派生特征,
2)提升匯入速度
-
Spark 直接寫 Doris Tablet 檔案,并掛載到 FE,
-
針對大匯入場景與 Doris 團隊共建,提升寫入效率,
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/Easy-storage-of-billions-of-data-Zhihu-DMP-system-architecture-practice-based-on-Doris.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/551399.html
標籤:其他
上一篇:CloudCanal x OceanBase 資料遷移同步優化
下一篇:返回列表