
一、背景
提起分庫分表,對于大部分服務器開發來說,其實并不是一個新鮮的名詞,隨著業務的發展,我們表中的資料量會變的越來越大,欄位也可能隨著業務復雜度的升高而逐漸增多,我們為了解決單表的查詢性能問題,一般會進行分表操作,
同時我們業務的用戶活躍度也會越來越高,并發量級不斷加大,那么可能會達到單個資料庫的處理能力上限,此時我們為了解決資料庫的處理性能瓶頸,一般會進行分庫操作,不管是分庫操作還是分表操作,我們一般都有兩種方式應對,一種是垂直拆分,一種是水平拆分,
關于兩種拆分方式的區別和特點,互聯網上參考資料眾多,很多人都寫過相關內容,這里就不再進行詳細贅述,有興趣的讀者可以自行檢索,
此文主要詳細聊一聊,我們最實用最常見的水平分庫分表方式中的一些特殊細節,希望能幫助大家避免走彎路,找到最合適自身業務的分庫分表設計,
【注1】本文中的案例均基于Mysql資料庫,下文中的分庫分表統指水平分庫分表,
【注2】后文中提到到M庫N表,均指共M個資料庫,每個資料庫共N個分表,即總表個數其實為M*N,
二、什么是一個好的分庫分表方案?
前期業務資料量級不大,流量較低的時候,我們無需分庫分表,也不建議分庫分表,但是一旦我們要對業務進行分庫分表設計時,就一定要考慮到分庫分表方案的可持續性,
那何為可持續性?其實就是:業務資料量級和業務流量未來進一步升高達到新的量級的時候,我們的分庫分表方案可以持續使用,
一個通俗的案例,假定當前我們分庫分表的方案為10庫100表,那么未來某個時間點,若10個庫仍然無法應對用戶的流量壓力,或者10個庫的磁盤使用即將達到物理上限時,我們的方案能夠進行平滑擴容,
在后文中我們將介紹下目前業界常用的翻倍擴容法和一致性Hash擴容法,
一個良好的分庫分表方案,它的資料應該是需要比較均勻的分散在各個庫表中的,如果我們進行一個拍腦袋式的分庫分表設計,很容易會遇到以下類似問題:
a、某個資料庫實體中,部分表的資料很多,而其他表中的資料卻寥寥無幾,業務上的表現經常是延遲忽高忽低,飄忽不定,
b、資料庫集群中,部分集群的磁盤使用增長特別塊,而部分集群的磁盤增長卻很緩慢,每個庫的增長步調不一致,這種情況會給后續的擴容帶來步調不一致,無法統一操作的問題,
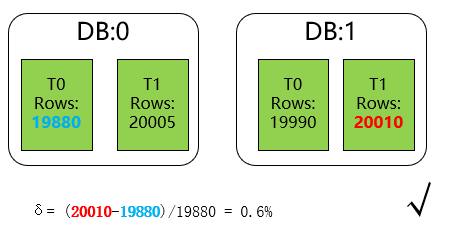
這邊我們定義分庫分表最大資料偏斜率為 :(資料量最大樣本 - 資料量最小樣本)/ 資料量最小樣本,一般來說,如果我們的最大資料偏斜率在5%以內是可以接受的,
三、常見的分庫分表方案
顧名思義,該方案根據資料范圍劃分資料的存放位置,
舉個最簡單例子,我們可以把訂單表按照年份為單位,每年的資料存放在單獨的庫(或者表)中,如下圖所示:
/**
* 通過年份分表
*
* @param orderId
* @return
*/
public static String rangeShardByYear(String orderId) {
int year = Integer.parseInt(orderId.substring(0, 4));
return "t_order_" + year;
}
通過資料的范圍進行分庫分表,該方案是最樸實的一種分庫方案,它也可以和其他分庫分表方案靈活結合使用,時下非常流行的分布式資料庫:TiDB資料庫,針對TiKV中資料的打散,也是基于Range的方式進行,將不同范圍內的[StartKey,EndKey)分配到不同的Region上,
下面我們看看該方案的缺點:
-
a、最明顯的就是資料熱點問題,例如上面案例中的訂單表,很明顯當前年度所在的庫表屬于熱點資料,需要承載大部分的IO和計算資源,
-
b、新庫和新表的追加問題,一般我們線上運行的應用程式是沒有資料庫的建庫建表權限的,故我們需要提前將新的庫表提前建立,防止線上故障,
這點非常容易被遺忘,尤其是穩定跑了幾年沒有迭代任務,或者人員又交替頻繁的模塊,
-
c、業務上的交叉范圍內資料的處理,舉個例子,訂單模塊無法避免一些中間狀態的資料補償邏輯,即需要通過定時任務到訂單表中掃描那些長時間處于待支付確認等狀態的訂單,
這里就需要注意了,因為是通過年份進行分庫分表,那么元旦的那一天,你的定時任務很有可能會漏掉上一年的最后一天的資料掃描,
雖然分庫分表的方案眾多,但是Hash分庫分表是最大眾最普遍的方案,也是本文花最大篇幅描述的部分,
針對Hash分庫分表的細節部分,相關的資料并不多,大部分都是闡述一下概念舉幾個示例,而細節部分并沒有特別多的深入,如果未結合自身業務貿然參考參考,后期非常容易出現各種問題,
在正式介紹這種分庫分表方式之前,我們先看幾個常見的錯誤案例,
常見錯誤案例一:非互質關系導致的資料偏斜問題
public static ShardCfg shard(String userId) {
int hash = userId.hashCode();
// 對庫數量取余結果為庫序號
int dbIdx = Math.abs(hash % DB_CNT);
// 對表數量取余結果為表序號
int tblIdx = Math.abs(hash % TBL_CNT);
return new ShardCfg(dbIdx, tblIdx);
}
上述方案是初次使用者特別容易進入的誤區,用Hash值分別對分庫數和分表數取余,得到庫序號和表序號,其實稍微思索一下,我們就會發現,以10庫100表為例,如果一個Hash值對100取余為0,那么它對10取余也必然為0,
這就意味著只有0庫里面的0表才可能有資料,而其他庫中的0表永遠為空!
類似的我們還能推導到,0庫里面的共100張表,只有10張表中(個位數為0的表序號)才可能有資料,這就帶來了非常嚴重的資料偏斜問題,因為某些表中永遠不可能有資料,最大資料偏斜率達到了無窮大,
那么很明顯,該方案是一個未達到預期效果的錯誤方案,資料的散落情況大致示意圖如下:
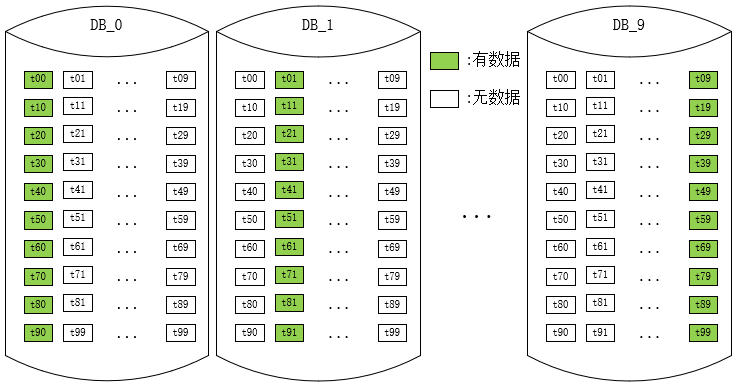
事實上,只要庫數量和表數量非互質關系,都會出現某些表中無資料的問題,
證明如下:

那么是不是只要庫數量和表數量互質就可用用這種分庫分表方案呢?比如我用11庫100表的方案,是不是就合理了呢?
答案是否定的,我們除了要考慮資料偏斜的問題,還需要考慮可持續性擴容的問題,一般這種Hash分庫分表的方案后期的擴容方式都是通過翻倍擴容法,那11庫翻倍后,和100又不再互質,
當然,如果分庫數和分表數不僅互質,而且分表數為奇數(例如10庫101表),則理論上可以使用該方案,但是我想大部分人可能都會覺得使用奇數的分表數比較奇怪吧,
常見錯誤案例二:擴容難以持續
如果避開了上述案例一的陷阱,那么我們又很容易一頭扎進另一個陷阱,大概思路如下;
我們把10庫100表看成總共1000個邏輯表,將求得的Hash值對1000取余,得到一個介于[0,999)中的數,然后再將這個數二次均分到每個庫和每個表中,大概邏輯代碼如下:
public static ShardCfg shard(String userId) {
// ① 算Hash
int hash = userId.hashCode();
// ② 總分片數
int sumSlot = DB_CNT * TBL_CNT;
// ③ 分片序號
int slot = Math.abs(hash % sumSlot);
// ④ 計算庫序號和表序號的錯誤案例
int dbIdx = slot % DB_CNT ;
int tblIdx = slot / DB_CNT ;
return new ShardCfg(dbIdx, tblIdx);
}
該方案確實很巧妙的解決了資料偏斜的問題,只要Hash值足夠均勻,那么理論上分配序號也會足夠平均,于是每個庫和表中的資料量也能保持較均衡的狀態,
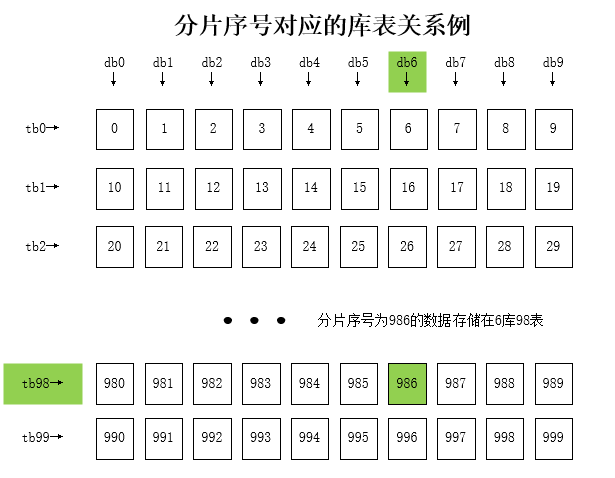
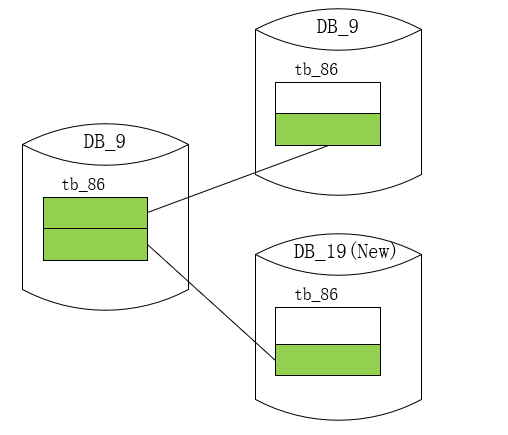
但是該方案有個比較大的問題,那就是在計算表序號的時候,依賴了總庫的數量,那么后續翻倍擴容法進行擴容時,會出現擴容前后資料不在同一個表中,從而無法實施,
如上圖中,例如擴容前Hash為1986的資料應該存放在6庫98表,但是翻倍擴容成20庫100表后,它分配到了6庫99表,表序號發生了偏移,這樣的話,我們在后續在擴容的時候,不僅要基于庫遷移資料,還要基于表遷移資料,非常麻煩且易錯,
看完了上面的幾種典型的錯誤案例,那么我們有哪些比較正確的方案呢?下面將結合一些實際場景案例介紹幾種Hash分庫分表的方案,
常用姿勢一:標準的二次分片法
上述錯誤案例二中,整體思路完全正確,只是最后計算庫序號和表序號的時候,使用了庫數量作為影響表序號的因子,導致擴容時表序號偏移而無法進行,
事實上,我們只需要換種寫法,就能得出一個比較大眾化的分庫分表方案,
public static ShardCfg shard2(String userId) {
// ① 算Hash
int hash = userId.hashCode();
// ② 總分片數
int sumSlot = DB_CNT * TBL_CNT;
// ③ 分片序號
int slot = Math.abs(hash % sumSlot);
// ④ 重新修改二次求值方案
int dbIdx = slot / TBL_CNT ;
int tblIdx = slot % TBL_CNT ;
return new ShardCfg(dbIdx, tblIdx);
}
大家可以注意到,和錯誤案例二中的區別就是通過分配序號重新計算庫序號和表序號的邏輯發生了變化,它的分配情況如下:
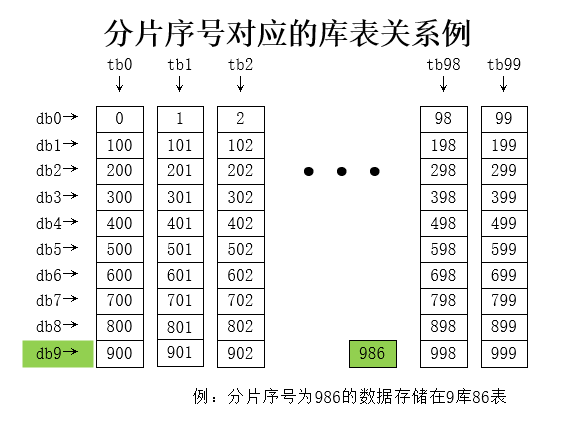
那為何使用這種方案就能夠有很好的擴展持久性呢?我們進行一個簡短的證明:

通過上面結論我們知道,通過翻倍擴容后,我們的表序號一定維持不變,庫序號可能還是在原來庫,也可能平移到了新庫中(原庫序號加上原分庫數),完全符合我們需要的擴容持久性方案,
【方案缺點】
1、翻倍擴容法前期操作性高,但是后續如果分庫數已經是大幾十的時候,每次擴容都非常耗費資源,
2、連續的分片鍵Hash值大概率會散落在相同的庫中,某些業務可能容易存在庫熱點(例如新生成的用戶Hash相鄰且遞增,且新增用戶又是高概率的活躍用戶,那么一段時間內生成的新用戶都會集中在相鄰的幾個庫中),
常用姿勢二:關系表冗余
我們可以將分片鍵對應庫的關系通過關系表記錄下來,我們把這張關系表稱為"路由關系表",
public static ShardCfg shard(String userId) {
int tblIdx = Math.abs(userId.hashCode() % TBL_CNT);
// 從快取獲取
Integer dbIdx = loadFromCache(userId);
if (null == dbIdx) {
// 從路由表獲取
dbIdx = loadFromRouteTable(userId);
if (null != dbIdx) {
// 保存到快取
saveRouteCache(userId, dbIdx);
}
}
if (null == dbIdx) {
// 此處可以自由實作計算庫的邏輯
dbIdx = selectRandomDbIdx();
saveToRouteTable(userId, dbIdx);
saveRouteCache(userId, dbIdx);
}
return new ShardCfg(dbIdx, tblIdx);
}
該方案還是通過常規的Hash演算法計算表序號,而計算庫序號時,則從路由表讀取資料,因為在每次資料查詢時,都需要讀取路由表,故我們需要將分片鍵和庫序號的對應關系記錄同時維護在快取中以提升性能,
上述實體中selectRandomDbIdx方法作用為生成該分片鍵對應的存盤庫序號,這邊可以非常靈活的動態配置,例如可以為每個庫指定一個權重,權重大的被選中的概率更高,權重配置成0則可以將關閉某些庫的分配,當發現資料存在偏斜時,也可以調整權重使得各個庫的使用量調整趨向接近,
該方案還有個優點,就是理論上后續進行擴容的時候,僅需要掛載上新的資料庫節點,將權重配置成較大值即可,無需進行任何的資料遷移即可完成,
如下圖所示:最開始我們為4個資料庫分配了相同的權重,理論上落在每個庫的資料概率均等,但是由于用戶也有高頻低頻之分,可能某些庫的資料增長會比較快,當掛載新的資料庫節點后,我們靈活的調整了每個庫的新權重,

該方案似乎解決了很多問題,那么它有沒有什么不適合的場景呢?當然有,該方案在很多場景下其實并不太適合,以下舉例說明,
a、每次讀取資料需要訪問路由表,雖然使用了快取,但是還是有一定的性能損耗,
b、路由關系表的存盤方面,有些場景并不合適,例如上述案例中用戶id的規模大概是在10億以內,我們用單庫百表存盤該關系表即可,但如果例如要用檔案MD5摘要值作為分片鍵,因為樣本集過大,無法為每個md5值都去指定關系(當然我們也可以使用md5前N位來存盤關系),
c、饑餓占位問題,如下詳敘:
我們知道,該方案的特點是后續無需擴容,可以隨時修改權重調整每個庫的存盤增長速度,但是這個愿景是比較縹緲,并且很難實施的,我們選取一個簡單的業務場景考慮以下幾個問題,
【業務場景】:以用戶存放檔案到云端的云盤業務為例,需要對用戶的檔案資訊進行分庫分表設計,有以下假定場景:
①假定有2億理論用戶,假設當前有3000W有效用戶,
②平均每個用戶檔案量級在2000個以內
③用戶id為隨機16位字串
④初期為10庫,每個庫100張表,
我們使用路由表記錄每個用戶所在的庫序號資訊,那么該方案會有以下問題:
第一、我們總共有2億個用戶,只有3000W個產生過事務的用戶,若程式不加處理,用戶發起任何請求則創建路由表資料,會導致為大量實際沒有事務資料的用戶提前創建路由表,
筆者最初存盤云盤用戶資料的時候便遇到了這個問題,客戶端app會在首頁查詢用戶空間使用情況,這樣導致幾乎一開始就為每個使用者分配好了路由,隨著時間的推移,這部分沒有資料的"靜默"的用戶,隨時可能開始他的云盤使用之旅而“復蘇”,從而導致它所在的庫迅速增長并超過單個庫的空間容量極限,從而被迫拆分擴容,
解決這個問題的方案,其實就是只針對事務操作(例如購買空間,上傳資料,創建檔案夾等等)才進行路由的分配,這樣對代碼層面便有了一些傾入,
第二、按照前面描述的業務場景,一個用戶最終平均有2000條資料,假定每行大小為1K,為了保證B+數的層級在3層,我們限制每張表的資料量在2000W,分表數為100的話,可以得到理論上每個庫的用戶數不能超過100W個用戶,
也就是如果是3000W個產生過事務的用戶,我們需要為其分配30個庫,這樣會在業務前期,用戶平均資料量相對較少的時候,存在非常大的資料庫資源的浪費,
解決第二個問題,我們一般可以將很多資料庫放在一個實體上,后續隨著增長情況進行拆分,也可以后續針對將滿的庫,使用常規手段進行拆分和遷移,
常用姿勢三:基因法
還是由錯誤案例一啟發,我們發現案例一不合理的主要原因,就是因為庫序號和表序號的計算邏輯中,有公約數這個因子在影響庫表的獨立性,
那么我們是否可以換一種思路呢?我們使用相對獨立的Hash值來計算庫序號和表序號,
public static ShardCfg shard(String userId) {
int dbIdx = Math.abs(userId.substring(0, 4).hashCode() % DB_CNT );
int tblIdx = Math.abs(userId.hashCode() % TBL_CNT);
return new ShardCfg(dbIdx, tblIdx);
}
如上所示,我們計算庫序號的時候做了部分改動,我們使用分片鍵的前四位作為Hash值來計算庫序號,
這也是一種常用的方案,我們稱為基因法,即使用原分片鍵中的某些基因(例如前四位)作為庫的計算因子,而使用另外一些基因作為表的計算因子,該方案也是網上不少的實踐方案或者是其變種,看起來非常巧妙的解決了問題,然而在實際生成程序中還是需要慎重,
筆者曾在云盤的空間模塊的分庫分表實踐中采用了該方案,使用16庫100表拆分資料,上線初期資料正常,然而當資料量級增長起來后,發現每個庫的用戶數量嚴重不均等,故猜測該方案存在一定的資料偏斜,
為了驗證觀點,進行如下測驗,隨機2億個用戶id(16位的隨機字串),針對不同的M庫N表方案,重復若干次后求平均值得到結論如下:
8庫100表
min=248305(dbIdx=2, tblIdx=64), max=251419(dbIdx=7, tblIdx=8), rate= 1.25% √
16庫100表
min=95560(dbIdx=8, tblIdx=42), max=154476(dbIdx=0, tblIdx=87), rate= 61.65% ×
20庫100表
min=98351(dbIdx=14, tblIdx=78), max=101228(dbIdx=6, tblIdx=71), rate= 2.93%
我們發現該方案中,分庫數為16,分表數為100,數量最小行數僅為10W不到,但是最多的已經達到了15W+,最大資料偏斜率高達61%,按這個趨勢發展下去,后期很可能出現一臺資料庫容量已經使用滿,而另一臺還剩下30%+的容量,
該方案并不是一定不行,而是我們在采用的時候,要綜合分片鍵的樣本規則,選取的分片鍵前綴位數,庫數量,表數量,四個變數對最終的偏斜率都有影響,
例如上述例子中,如果不是16庫100表,而是8庫100表,或者20庫100表,資料偏斜率都能降低到了5%以下的可接受范圍,所以該方案的隱藏的"坑"較多,我們不僅要估算上線初期的偏斜率,還需要測算若干次翻倍擴容后的資料偏斜率,
例如你用著初期比較完美的8庫100表的方案,后期擴容成16庫100表的時候,麻煩就接踵而至,
常用姿勢四:剔除公因數法
還是基于錯誤案例一啟發,在很多場景下我們還是希望相鄰的Hash能分到不同的庫中,就像N庫單表的時候,我們計算庫序號一般直接用Hash值對庫數量取余,
那么我們是不是可以有辦法去除掉公因數的影響呢?下面為一個可以考慮的實作案例:
public static ShardCfg shard(String userId) {
int dbIdx = Math.abs(userId.hashCode() % DB_CNT);
// 計算表序號時先剔除掉公約數的影響
int tblIdx = Math.abs((userId.hashCode() / TBL_CNT) % TBL_CNT);
return new ShardCfg(dbIdx, tblIdx);
}
經過測算,該方案的最大資料偏斜度也比較小,針對不少業務從N庫1表升級到N庫M表下,需要維護庫序號不變的場景下可以考慮,
常用姿勢五:一致性Hash法
一致性Hash演算法也是一種比較流行的集群資料磁區演算法,比如RedisCluster即是通過一致性Hash演算法,使用16384個虛擬槽節點進行每個分片資料的管理,關于一致性Hash的具體原理這邊不再重復描述,讀者可以自行翻閱資料,
這邊詳細介紹如何使用一致性Hash進行分庫分表的設計,
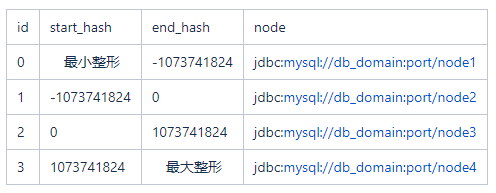
我們通常會將每個實際節點的配置持久化在一個配置項或者是資料庫中,應用啟動時或者是進行切換操作的時候會去加載配置,配置一般包括一個[StartKey,Endkey)的左閉右開區間和一個資料庫節點資訊,例如:
示例代碼:
private TreeMap<Long, Integer> nodeTreeMap = new TreeMap<>();
@Override
public void afterPropertiesSet() {
// 啟動時加載磁區配置
List<HashCfg> cfgList = fetchCfgFromDb();
for (HashCfg cfg : cfgList) {
nodeTreeMap.put(cfg.endKey, cfg.nodeIdx);
}
}
public ShardCfg shard(String userId) {
int hash = userId.hashCode();
int dbIdx = nodeTreeMap.tailMap((long) hash, false).firstEntry().getValue();
int tblIdx = Math.abs(hash % 100);
return new ShardCfg(dbIdx, tblIdx);
}
我們可以看到,這種形式和上文描述的Range分表非常相似,Range分庫分表方式針對分片鍵本身劃分范圍,而一致性Hash是針對分片鍵的Hash值進行范圍配置,
正規的一致性Hash演算法會引入虛擬節點,每個虛擬節點會指向一個真實的物理節點,這樣設計方案主要是能夠在加入新節點后的時候,可以有方案保證每個節點遷移的資料量級和遷移后每個節點的壓力保持幾乎均等,
但是用在分庫分表上,一般大部分都只用實際節點,引入虛擬節點的案例不多,主要有以下原因:
-
a、應用程式需要花費額外的耗時和記憶體來加載虛擬節點的配置資訊,如果虛擬節點較多,記憶體的占用也會有些不太樂觀,
-
b、由于mysql有非常完善的主從復制方案,與其通過從各個虛擬節點中篩選需要遷移的范圍資料進行遷移,不如通過從庫升級方式處理后再洗掉冗余資料簡單可控,
-
c、虛擬節點主要解決的痛點是節點資料搬遷程序中各個節點的負載不均衡問題,通過虛擬節點打散到各個節點中均攤壓力進行處理,
而作為OLTP資料庫,我們很少需要突然將某個資料庫下線,新增節點后一般也不會從0開始從其他節點搬遷資料,而是前置準備好大部分資料的方式,故一般來說沒有必要引入虛擬節點來增加復雜度,
四、常見擴容方案
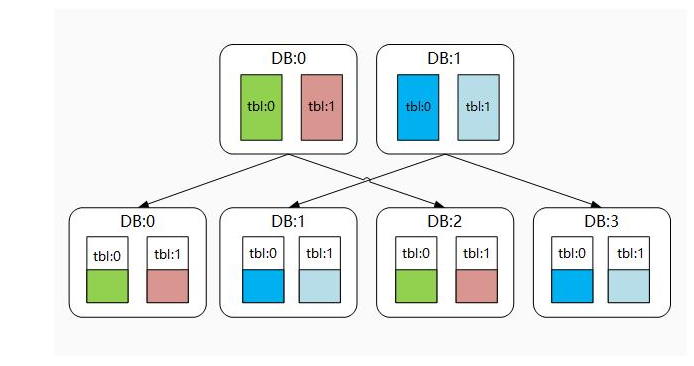
翻倍擴容法的主要思維是每次擴容,庫的數量均翻倍處理,而翻倍的資料源通常是由原資料源通過主從復制方式得到的從庫升級成主庫提供服務的方式,故有些檔案將其稱作"從庫升級法",
理論上,經過翻倍擴容法后,我們會多一倍的資料庫用來存盤資料和應對流量,原先資料庫的磁盤使用量也將得到一半空間的釋放,如下圖所示:
具體的流程大致如下:
①、時間點t1:為每個節點都新增從庫,開啟主從同步進行資料同步,
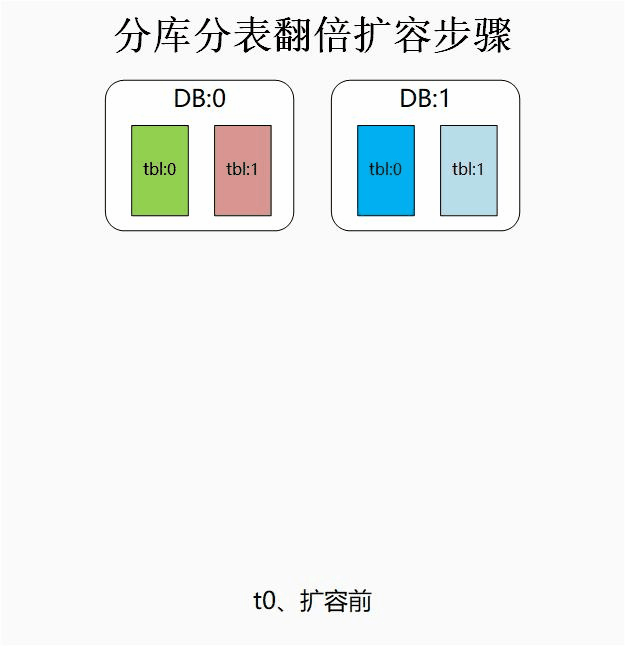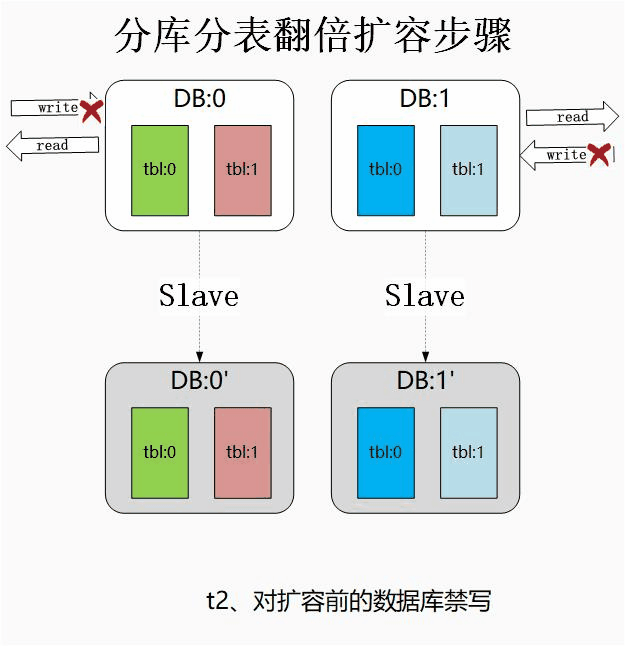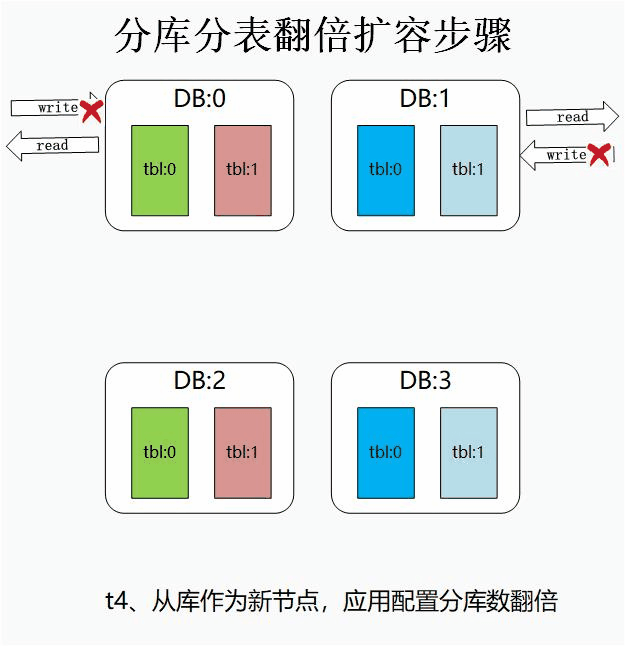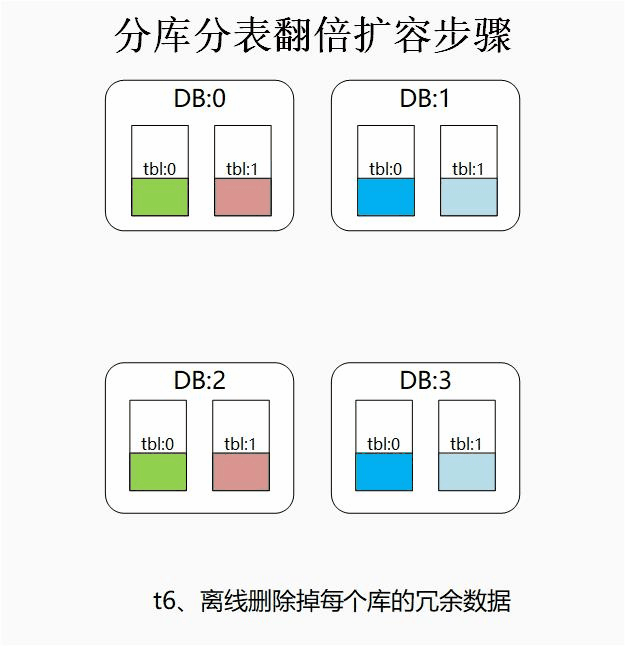
②、時間點t2:主從同步完成后,對主庫進行禁寫,
此處禁寫主要是為了保證資料的正確性,若不進行禁寫操作,在以下兩個時間視窗期內將出現資料不一致的問題:
-
a、斷開主從后,若主庫不禁寫,主庫若還有資料寫入,這部分資料將無法同步到從庫中,
-
b、應用集群識別到分庫數翻倍的時間點無法嚴格一致,在某個時間點可能兩臺應用使用不同的分庫數,運算到不同的庫序號,導致錯誤寫入,
③、時間點t3:同步完全完成后,斷開主從關系,理論上此時從庫和主庫有著完全一樣的資料集,
④、時間點t4:從庫升級為集群節點,業務應用識別到新的分庫數后,將應用新的路由演算法,
一般情況下,我們將分庫數的配置放到配置中心中,當上述三個步驟完成后,我們修改分庫數進行翻倍,應用生效后,應用服務將使用新的配置,這里需要注意的是,業務應用接收到新的配置的時間點不一定一致,所以必定存在一個時間視窗期,該期間部分機器使用原分庫數,部分節點使用新分庫數,這也正是我們的禁寫操作一定要在此步完成后才能放開的原因,
⑤、時間點t5:確定所有的應用均接受到庫總數的配置后,放開原主庫的禁寫操作,此時應用完全恢復服務,
⑥、啟動離線的定時任務,清除各庫中的約一半冗余資料,
為了節省磁盤的使用率,我們可以選擇離線定時任務清除冗余的資料,也可以在業務初期表結構設計的時候,將索引鍵的Hash值存為一個欄位,
那么以上述常用姿勢四為例,我們離線的清除任務可以簡單的通過sql即可實作(需要防止鎖住全表,可以拆分成若干個id范圍的子sql執行):
delete from db0.tbl0 where hash_val mod 4 <> 0;
delete from db1.tbl0 where hash_val mod 4 <> 1;
delete from db2.tbl0 where hash_val mod 4 <> 2;
delete from db3.tbl0 where hash_val mod 4 <> 3;
具體的擴容步驟可參考下圖:
總結:通過上述遷移方案可以看出,從時間點t2到t5時間視窗呢內,需要對資料庫禁寫,相當于是該時間范圍內服務器是部分有損的,該階段整體耗時差不多是在分鐘級范圍內,若業務可以接受,可以在業務低峰期進行該操作,
當然也會有不少應用無法容忍分鐘級寫入不可用,例如寫操作遠遠大于讀操作的應用,此時可以結合canel開源框架進行視窗期內資料雙寫操作以保證資料的一致性,
該方案主要借助于mysql強大完善的主從同步機制,能在事前提前準備好新的節點中大部分需要的資料,節省大量的人為資料遷移操作,
但是缺點也很明顯,一是程序中整個服務可能需要以有損為代價,二是每次擴容均需要對庫數量進行翻倍,會提前浪費不少的資料庫資源,
我們主要還是看下不帶虛擬槽的一致性Hash擴容方法,假如當前資料庫節點DB0負載或磁盤使用過大需要擴容,我們通過擴容可以達到例如下圖的效果,
下圖中,擴容前配置了三個Hash分段,發現[-Inf,-10000)范圍內的的資料量過大或者壓力過高時,需要對其進行擴容,
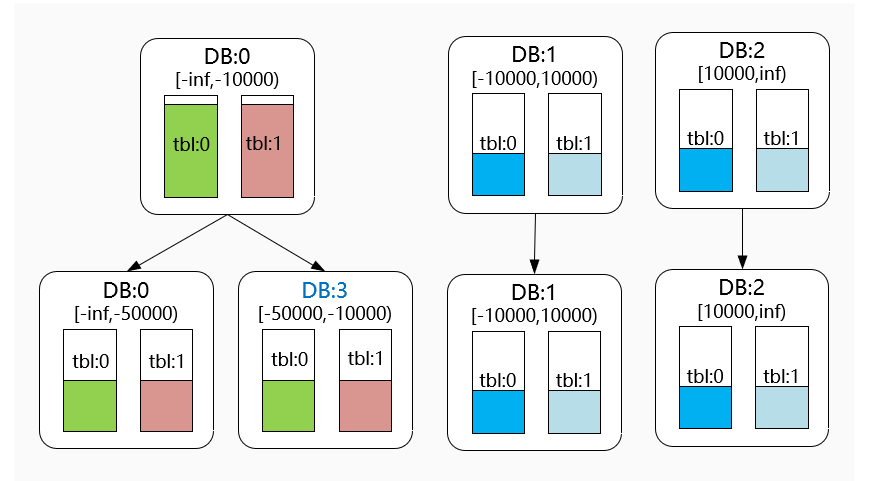
主要步驟如下:
①、時間點t1:針對需要擴容的資料庫節點增加從節點,開啟主從同步進行資料同步,
②、時間點t2:完成主從同步后,對原主庫進行禁寫,
此處原因和翻倍擴容法類似,需要保證新的從庫和原來主庫中資料的一致性,
③、時間點t3:同步完全完成后,斷開主從關系,理論上此時從庫和主庫有著完全一樣的資料集,
④、時間點t4:修改一致性Hash范圍的配置,并使應用服務重新讀取并生效,
⑤、時間點t5:確定所有的應用均接受到新的一致性Hash范圍配置后,放開原主庫的禁寫操作,此時應用完全恢復服務,
⑥、啟動離線的定時任務,清除冗余資料,
可以看到,該方案和翻倍擴容法的方案比較類似,但是它更加靈活,可以根據當前集群每個節點的壓力情況選擇性擴容,而無需整個集群同時翻倍進行擴容,
五、小結
本文主要描述了我們進行水平分庫分表設計時的一些常見方案,
我們在進行分庫分表設計時,可以選擇例如范圍分表,Hash分表,路由表,或者一致性Hash分表等各種方案,進行選擇時需要充分考慮到后續的擴容可持續性,最大資料偏斜率等因素,
文中也列舉了一些常見的錯誤示例,例如庫表計算邏輯中公約數的影響,使用前若干位計算庫序號常見的資料傾斜因素等等,
我們在實際進行選擇時,一定要考慮自身的業務特點,充分驗證分片鍵在各個引數因子下的資料偏斜程度,并提前規劃考慮好后續擴容的方案,
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/Detailed-explanation-of-horizontal-database-and-table-division-technology.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/551792.html
標籤:其他
上一篇:水平分庫分表排雷帖
下一篇:返回列表