目錄
- 上節回顧
- 本節前言
- 檔案的搜索
- URL引數條件搜索
- 請求體條件搜索
- 語法與示例:
- 補充:
- 小節總結:
- 檔案的過濾filter
- 語法與舉例:
- filter與bool
- constant_score
- cache
- 小節總結:
- 檔案的聚合分析
- 準備資料
- 語法與舉例:
- 其他語法:
- 補充:
- 小節總結:
- 檔案的分頁、排序
- 分頁
- 排序
- deep paging
- 補充:
- 小節總結:
發表日期:2019年9月20日
上節回顧
1.講了如何對索引CRUD
2.重新解釋了type,只是元資料的效果
3.講了如何對檔案CRUD
本節前言
1.ElasticSearch的主要功能是搜索,這節也將會主要講搜索,將會涉及到如何使用關鍵字進行全文搜索
2.除了講搜索,也會講到搜索相關的“分頁”、“排序”、“聚合分析”等內容,
3.還會補充一些與搜索相關的知識,
檔案的搜索
測驗資料:請先插入以下資料,以便練習搜索功能
【突然看了一下之前的博文,發現我后面去準備資料的時候寫錯格式了,所以導致id為1,2,3的檔案和后面的檔案的欄位不一樣,你可以僅僅基于以下的資料來測驗】
PUT /douban/book/5
{
"book_id":5,
"book_name":"A Boy's Own Story",
"book_author":"Edmund White",
"book_pages":217,
"book_express":"Vintage",
"publish_date":"1994-02-01",
"book_summary":"""
An instant classic upon its original publication, A Boy's Own Story is the first of Edmund White's highly acclaimed trilogy of autobiographical novels that brilliantly evoke a young man's coming of age and document American gay life through the last forty years.
The nameless narrator in this deeply affecting work reminisces about growing up in the 1950s with emotionally aloof, divorced parents, an unrelenting sister, and the schoolmates who taunt him. He finds consolation in literature and his fantastic imagination. Eager to cultivate intimate, enduring friendships, he becomes aware of his yearning to be loved by men, and struggles with the guilt and shame of accepting who he is. Written with lyrical delicacy and extraordinary power, A Boy's Own Story is a triumph."""
}
PUT /douban/book/6
{
"book_id":6,
"book_name":"The Lost Language of Cranes",
"book_author":"David Leavitt",
"book_pages":352,
"book_express":"Bloomsbury Publishing PLC",
"publish_date":"2005-05-02",
"book_summary":"""David Leavitt's extraordinary first novel, now reissued in paperback, is a seminal work about family, sexual identity, home, and loss. Set in the 1980s against the backdrop of a swiftly gentrifying Manhattan, The Lost Language of Cranes tells the story of twenty-five-year-old Philip, who realizes he must come out to his parents after falling in love for the first time with a man. Philip's parents are facing their own crisis: pressure from developers and the loss of their longtime home. But the real threat to this family is Philip's father's own struggle with his latent homosexuality, realized only in his Sunday afternoon visits to gay porn theaters. Philip's admission to his parents and his father's hidden life provoke changes that forever alter the landscape of their worlds."""
}
PUT /douban/book/7
{
"book_id":7,
"book_name":"Immortality",
"book_author":"Milan Kundera",
"book_pages":400,
"book_express":"Faber and Faber",
"publish_date":"2000-08-21",
"book_summary":"""Milan Kundera's sixth novel springs from a casual gesture of a woman to her swimming instructor, a gesture that creates a character in the mind of a writer named Kundera. Like Flaubert's Emma or Tolstoy's Anna, Kundera's Agnes becomes an object of fascination, of indefinable longing. From that character springs a novel, a gesture of the imagination that both embodies and articulates Milan Kundera's supreme mastery of the novel and its purpose: to explore thoroughly the great themes of existence."""
}
搜索的方式主要有兩種,URL搜索和請求體搜索,一個是將搜索的條件寫在URL中,一個是將請求寫在請求體中,
URL引數條件搜索
語法:GET /index/type/_search?引數
引數決議:
- q:使用某個欄位來進行查詢,例如q:book_name=book,就是根據book_name中是否有book來進行搜索,
- sort:使用某個欄位來進行排序,例如sort=cost:desc,就是根據cost欄位來進行降序desc排序,
- 其他:fileds,timeout,analyzer【這些引數留在請求體搜索中講】
- 不帶引數時,為“全搜索”
- 多個引數使用&&拼接
示例:
GET /douban/book/_search?q=book_summary:character
GET /douban/book/_search?q=book_author:Milan
GET /douban/book/_search?q=book_summary:a
GET /douban/book/_search?q=book_summary:a&&sort=book_pages:desc
GET /douban/book/_search?q=book_summary:a&&q=book_author:Milan
【值得注意的是,請先不要對text型別的資料進行排序,這會影響搜索,對整數排序即可,后面會再細講】
查詢結果決議:
【考慮到資料太長的問題,所以我給了另一個搜索結果的回傳截圖】

補充:把搜索條件寫在url中的搜索方式比較少用,因為查詢引數拼接到URL中會比較麻煩,
請求體條件搜索
語法與示例:
//全搜索
GET /index/type/_search
GET /douban/book/_search
//全搜索
GET /index/type/_search
{
"query": {
"match_all": {}
}
}
GET /douban/book/_search
{
"query": {
"match_all": {}
}
}
// 查詢指定欄位的資料(全文搜索,如果搜索值有多個詞,僅匹配一個詞的結果也可以查詢出來):
GET /index/type/_search
{
"query": {
"match": {
"欄位名": "搜索值"
}
}
}
GET /douban/book/_search
{
"query": {
"match": {
"book_name": "A The"
}
}
}
// 使用同一搜索值搜索多個欄位:
GET /index/type/_search
{
"query": {
"multi_match": {
"query": "搜索值",
"fields": [
"搜索的欄位1","搜索的欄位2"]
}
}
}
GET /douban/book/_search
{
"query": {
"multi_match": {
"query": "A",
"fields": [
"book_name","book_summary"]
}
}
}
// 短語查詢:【搜索值必須完全匹配,不會把搜索值拆分來搜索】
GET /index/type/_search
{
"query": {
"match_phrase": {
"欄位": "搜索值"
}
}
}
GET /douban/book/_search
{
"query": {
"match_phrase": {
"book_summary": "a character"
}
}
}
// 欄位過濾,查詢的結果只顯示指定欄位
GET /product/book/_search
{
"query": {
"查詢條件"
},
"_source": [
"顯示的欄位1",
"顯示的欄位2"
]
}
GET /douban/book/_search
{
"query": {
"match": {
"book_name": "Story"
}
},
"_source": [
"book_name",
"book_id"
]
}
// 高亮查詢:【根據查詢的關鍵字來進行高亮,高亮的結果會顯示在回傳結果的會自動在回傳結果中的highlight中,關鍵字會被加上<em>標簽】
// 如果想要多欄位高亮,也需要進行多欄位搜索
GET /index/book/_search
{
"query": {
"查詢條件"
},
"highlight": {
"fields": {
"高亮的欄位名1": {}
}
}
}
GET /douban/book/_search
{
"query": {
"match": {
"book_summary": "Story"
}
},
"highlight": {
"fields": {
"book_summary":{}
}
}
}
GET /douban/book/_search
{
"query": {
"multi_match": {
"query": "Story",
"fields": [
"book_name","book_summary"]
}
},
"highlight": {
"fields": {
"book_summary":{},
"book_name":{}
}
}
}
上面展示了關于全搜索、單欄位值全文搜索、多欄位單一搜索值全文搜索、短語搜索、欄位過濾、高亮搜索的代碼,
由于對多個欄位使用不同搜索值涉及條件拼接,所以單獨講,
前置知識講解:對于條件拼接,在SQL中有and,or,not,在ElasticSearch不太一樣,下面逐一講解:
bool:用來表明里面的陳述句是多條件的組合,用來包裹多個條件,should:里面可以有多個條件,查詢結果必須符合查詢條件中的一個或多個,must:里面的多個條件都必須成立must_not:里面的多個條件必須不成立
示例:
// 書名必須包含Story的
GET /douban/book/_search
{
"query": {
"bool": {
"must": [
{
"match":{
"book_name":"Story"
}
}
]
}
}
}
// 書名必須不包含Story的
GET /douban/book/_search
{
"query": {
"bool": {
"must_not": [
{
"match":{
"book_name":"Story"
}
}
]
}
}
}
// 書名必須不包含Story,書名包含Adventures或Immortality的
GET /douban/book/_search
{
"query": {
"bool": {
"must_not": [
{
"match":{
"book_name":"Story"
}
}
],
"should": [
{
"match": {
"book_name": "Adventures"
}
},
{
"match": {
"book_name": "Immortality"
}
}
]
}
}
}
// 在should、must、must_not這些里面都可以放多個條件
GET /douban/book/_search
{
"query": {
"bool": {
"must_not": [
{
"match":{
"book_name":"Story"
}
},
{
"match": {
"book_name": "Adventures"
}
}
]
}
}
}
// 如果是單個條件的時候,還可以這樣寫,省去[]:
GET /douban/book/_search
{
"query": {
"bool": {
"must_not": {
"match":{
"book_name":"Story"
}
}
}
}
}
// 還可以條件嵌套,也就是再嵌套一層bool,不過要注意邏輯,例如:
// 查詢出(書名有story)或者(書名有The而且作者名有David)的,第二個是可成立可不成立的,
GET /douban/book/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"book_name": "Story"
}
},
{
"bool": {
"must": [
{
"match": {
"book_name": "The"
}
},
{
"match": {
"book_author": "David"
}
}
]
}
}
]
}
}
}
補充:
- 上面講了URL引數條件搜索和請求體條件搜索,講了
全搜索、單欄位值全文搜索、多欄位單一搜索值全文搜索、短語搜索、欄位過濾、高亮搜索的使用方法,還講了基于bool、should、must、must_not的多條件搜索,上面的知識已經能基礎地實作一些搜索功能了,但還是有一些知識由于比較晦澀,所以留到后面章節講,比如給搜索指定分詞器、給多條件指定匹配數量、滾動查詢等等,
小節總結:
上面講了URL引數條件搜索和請求體條件搜索,URL引數條件寫在URL里面,用?來附帶引數,q用來指定搜索欄位,請求體引數把條件寫在請求體中,query是最外層的包裹,match_all用于查詢所有,match用來使用指定搜索值搜索某一欄位,match_phrase用來搜索連續的搜索,_source用來欄位過濾(與query同級,[]里面是欄位名),highlight用來高亮搜索(與query同級,里面是{field:{欄位名1:{},欄位名2:{}}}),bool、should、must、must_not用來多條件搜索,
檔案的過濾filter
過濾的效果其實有點像條件搜索,不過條件搜索會考慮相關度分數和考慮分詞,而過濾是不考慮這些的,過濾對相關度沒有影響,過濾一般用于結構化的資料上,也就是通常不用于使用了分詞的資料上,通常都會用在數值型別和日期型別的資料上,
在搜索的時候,如果你不希望要搜索的條件會影響到相關度,那么就把它放在過濾中,如果希望影響相關度,那么就放在條件搜索中,
使用過濾時,由于不考慮相關度,所以score固定為1,
檔案的過濾filter里面主要有五種欄位,range,term,terms,exist,missing,range用于欄位資料比較大小;term主要用于比較字符型別的和數值型別的資料是否相等;terms是term的復數版,里面可以有多個用于比較相等的值;exist和missing用于判斷檔案中是否包含指定欄位或沒有某個欄位(僅適用于2.0+版本,目前已經移除)
語法與舉例:
// range,gte是不小于,lte是不大于,eq是等于,gt是大于,lt是小于
GET / index/type/_search
{
"query": {
"range": {
"欄位名": {
"gte": 比較值
[,"lte": 比較值]
}
}
}
}
GET /douban/book/_search
{
"query": {
"range": {
"book_pages": {
"gte": 352,
"lt":400
}
}
}
}
// term用于匹配字串和數值型型別的資料(解決了range中沒有eq的問題),但不能直接用于分詞的欄位,
//【這個并沒有那么簡單,會后續再講,直接匹配一些會分詞的欄位時,會匹配失敗,
//因為這時候這個欄位拿來匹配的都是散亂的值,不是完整的原本的欄位資料,所以下面用了不分詞的數值型的欄位來演示】
GET /douban/book/_search
{
"query": {
"term": {
"欄位": "搜索值"
}
}
}
GET /douban/book/_search
{
"query": {
"term": {
"book_pages": 352
}
}
}
//terms
GET /douban/book/_search
{
"query": {
"terms": {
"欄位": ["搜索值1","搜索值2"]
}
}
}
GET /douban/book/_search
{
"query": {
"terms": {
"book_pages": [
"352",
"400"
]
}
}
}
term的問題:
- 首先,提一下的是,在搜索的時候,你并不直接面向原始檔案資料,而是面向倒排索引,這意思是什么呢?比如你要進行全文搜索,那么你的搜索值并不是與資料檔案比對的,而是與倒排索引匹配的,也就是在我們與資料檔案之間有一個專門用于搜索的層次,
- 對于match和match_all,這些都是全文搜索,就不說了,直接就是通過索引詞在索引檔案中找到對應的檔案;比較不同的是match_phrase這個會匹配一段詞的搜索,他是怎么查詢的呢?他實際上也會去查索引檔案中包括了搜索值中所有詞并且詞的在檔案中的位置順序也一致的記錄,所以這個短語匹配其實也是通過倒排索引來搜索的,
- 而倒排索引中其實包含了所有欄位的標識,對于分詞的欄位,會存盤索引詞;對于不分詞的,會存盤整個資料,【對于分詞的欄位可以加一個keyword來保留完整的資料,這個后面再講,】
- 而term的搜索主要面向不分詞的資料,所以無法直接用于分詞的欄位,除非加keyword,
官方檔案中關于term
filter與bool
filter也可以用于多條件拼接,例如:
GET /douban/book/_search
{
"query": {
"bool": {
"must": [
{
"match":{
"book_name":"Story"
}
},
{
"range": {
"book_pages": {
"lte":300
}
}
}
]
}
}
}
GET /douban/book/_search
{
"query": {
"bool": {
"must": [
{
"match":{
"book_name":"Story"
}
},
{
"range": {
"book_pages": {
"lte":300
}
}
},
{
"term": {
"publish_date": "1994-02-01"
}
}
]
}
}
}
在這樣條件搜索和過濾一起用的情況下,要注意filter過濾是不計算相關度的,在上面中,假設只有match,那么某個檔案相關度為0.2,加上filter后,會變成1.2,因為filter默認提供的相關度為1,
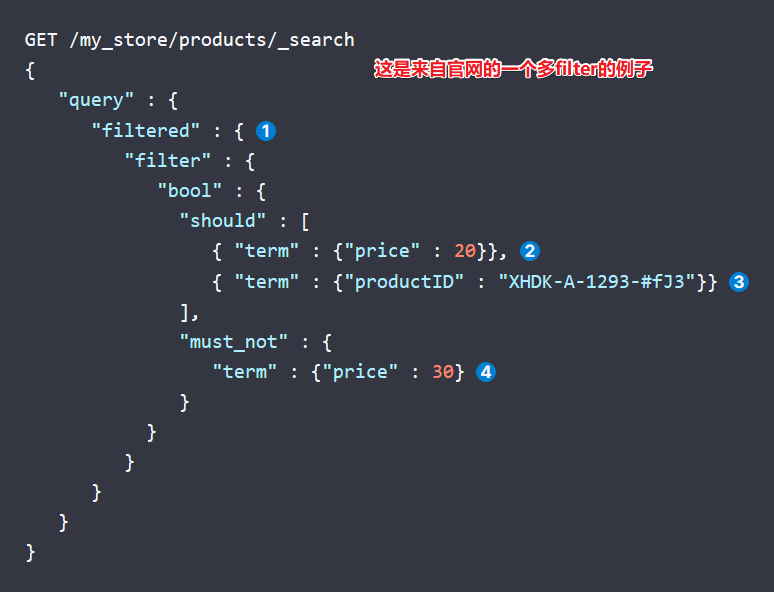
constant_score
過濾還可以這樣寫:
GET /douban/book/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"book_pages": {
"gte": 352,
"lt": 400
}
}
}
}
}
}
// boost設定filter提供的相關度score值
GET /douban/book/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"book_pages": {
"gte": 352,
"lt": 400
}
}
},
"boost": 1.2
}
}
}
cache
對于過濾,elasticsearch會臨時快取它的結果,以便可能下次仍需使用它,因為過濾是不關心相關度的,
官方檔案--過濾快取
小節總結:
這節介紹了不影響相關度的搜索--過濾,過濾通常用于過濾結構化資料,也就是那些不分詞的資料,其中range用于數值范圍過濾,term用于字符型別的資料或數值型別的資料的值是否相等,terms是term的復數版,過濾也支持bool拼接多個條件,過濾提供的相關度分數是一個常數,默認是1,
檔案的聚合分析
準備資料
先準備一批測驗資料:
PUT /people/test/1
{
"name":"lilei1",
"age":18,
"gender":1
}
PUT /people/test/2
{
"name":"lilei2",
"age":17,
"gender":0
}
PUT /people/test/3
{
"name":"lilei4",
"age":21,
"gender":1
}
PUT /people/test/4
{
"name":"lilei4",
"age":15,
"gender":0
}
PUT /people/test/5
{
"name":"lilei1 2",
"age":15,
"gender":0
}
像在SQL中會需要SUM(),MAX().AVG()函式,ElasticSearch也提供了關于聚合分析的函式,
ElasticSearch中常見的聚合分析函式有terms(分組函式)、avg(平均數)、range(區間分組)、max(求最大值)、min(求最小值)、cardinality(獲取唯一值的數量)、value_count(獲取值的數量,不去重,可以得出多少個值參與了聚合),
語法與舉例:
語法:
GET /index/type/_search
{
"aggs": {
"自定義聚合名稱": {
"聚合函式": {
聚合引數
}
}
}
}
舉例:
// 按性別分組
GET /douban/book/_search
{
"aggs": {
"groud_by_express": {
"terms": {
"field": "book_id",
"size": 10
}
}
}
}
//求年齡的平均數
GET /people/test/_search
{
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
// 求年齡的最大值:
GET /people/test/_search
{
"aggs": {
"max_of_age": {
"max": {
"field": "age"
}
}
}
}
// 把年齡[15,17]的分成一組,把年齡[18,25]的分成一組
GET /people/test/_search
{
"aggs": {
"range_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 15,
"to": 17
},
{
"from": 18,
"to": 25
}
]
}
}
}
}
// 獲取不同的年齡數:,比如有年齡[1,2,3,3,4,5],得到的結果是5,因為3只算一次
GET /people/test/_search
{
"aggs": {
"get_diff_age_count": {
"cardinality": {
"field": "age"
}
}
}
}
回傳結果決議:

其他語法:
先查詢后聚合:
GET /people/test/_search
{
"query": {
"match": {
"name": "lilei1"
}
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
先過濾后聚合:
// 先獲取年齡大于15的,再求平均值
GET /people/test/_search
{
"query": {
"range": {
"age": {
"gt":15
}
}
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
聚合函式嵌套:
// 先按性別分組,再獲取年齡平均值
GET /people/test/_search
{
"aggs": {
"groud_by_express": {
"terms": {
"field": "gender"
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
聚合+排序:
// 先按性別分組,再按分組的年齡平均值降序排序,order中的avg_of_age就是下面的聚合函式的自定義名稱
GET /people/test/_search
{
"aggs": {
"groud_by_express": {
"terms": {
"field": "gender",
"order": {
"avg_of_age": "desc"
}
},
"aggs": {
"avg_of_age": {
"avg": {
"field": "age"
}
}
}
}
}
}
補充:
上面只講了一些基礎的聚合,聚合分析是一個比較重要的內容,會在后面的再講,
小節總結:
本節主要講了ElasticSearch中關于資料聚合的使用方法,aggs是與query同級的,使用聚合函式需要自己定義一個外層的聚合函式名稱,avg用于求平均值,max用于求最大值,range用于范圍分組,term用于資料分組,分組可以與條件搜索和過濾一起使用,aggs是與query同級的,聚合函式也可以嵌套使用,
檔案的分頁、排序
【使用一下上一節準備的資料】
分頁
// 從第一條開始,獲取兩條資料
GET /people/test/_search
{
"from": 0,
"size": 2
}
// 可以先查詢,再分頁
GET /people/test/_search
{
"query": {
"match": {
"name": "lilei1"
}
},
"from": 0,
"size": 1
}
排序
【請注意,下面的結果中你可以看到score為null,因為這時候你使用了age欄位來排序,而不是相關性,所以此時相關性意義不大,則不計算,】
排序處理:【sort與query同級別,是一個陣列,里面可以有多個排序引數,引數以{"FIELD":{"order":"desc/asc"}}為格式】
GET /people/test/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
deep paging
對于分頁和排序,需要共同面對一個問題:
-
首先,你要想到一個索引中的資料是散落在多個分片上的,你如何確定另一個分片上的資料與其他分片上的順序問題?,比如可能A分片上的有數值為1和數值為3的資料,而B分片上有數值為2和數值為4的資料,所以B分片的部分資料與A分片資料的大小是不確定的,那么排序的時候怎么處理這些散落的資料呢?(就算是依據相對度來排序,這個時候散落的資料的相關度也是不太好確定的)
-
分頁需要面對的問題也同樣是因為資料散落的而不好排序的問題,因為分頁也是要排序的,默認是按相關度排序,因為散落的資料的值的大小不確定,所以就需要把所有可能的資料取出來排完序再分頁,這就會導致需要取出遠遠超出“頁數”的資料來計算,
- 有兩個primary shard(命名為A和B),現在要取第1000頁的資料,假設每一頁10條記錄,那么理論上是只需要取第10000到第10010條記錄出來即可,
- 但這時候我們并不知道A和B中的_score的大小如何,可能A中的最小的_score要比B中的最大的_score都要大,反過來也有可能,(所以我們并不能說僅僅從A和B中分別取10000到10010出來進行比較即可,我們需要對前面的資料都進行比較,以避免最小的_score都比另一個shard上的_score大的情況),為了確保資料的正確性,我們需要從A和B中都取出1到10010的資料來進行排序比較,然后再取出里面的10000到10010條,
- 所以,你看到了,我們只是為了拿十條資料,竟然要查10010資料出來,這就是deep paging了,
補充:
- 除了上述的內容,一個沒講的而且比較重要的內容應該是滾動查詢,滾動查詢有點類似分頁查詢,但它會提前準備好資料,我暫時沒想好放在哪里講合適,可能會在后面寫,也有可能某一天補充在這里,
小節總結:
上面講了怎么進行資料的分頁獲取和資料的排序,使用from和size分頁,使用sort排序;還講了一個如果查詢時頁數太深而可能導致的deep paging問題,問題的原因是多個分片上的資料大小不確定,不方便排序,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/5523.html
標籤:其它