在企業級應用中,資料的安全性和隱私保護是極其重要的,Spark 作為數堆疊底層計算引擎之一,必須確保資料只能被授權的人員訪問,避免出現資料泄露和濫用的情況,為了實作Spark SQL 對資料的精細化管理及提高資料的安全性和可控性,數堆疊基于 Apache Ranger 實作了 Spark SQL 對資料處理的權限控制,
本文基于 Apahce Spark 2.4.8 和 Apache Ranger 2.2 進行原理講解,和大家聊聊「袋鼠云一站式大資料基礎軟體數堆疊」基于 Ranger 在 Spark SQL 權限控制上的實踐探索之路,
基于Ranger實作Spark SQL權限控制
Apache Ranger 是一個開源的權限管理框架,可以提供對 Hadoop 生態系統的安全訪問控制,Ranger 為開發者提供了一種可擴展的框架,可以進行統一的資料安全管理,內置包括對 Hadoop、Hive、HBase、Kafka 等多個組件的訪問控制,
Ranger 內置并沒有提供 Spark 的權限控制插件,需要開發者自己實作,基于 Ranger 數堆疊實作了 Spark SQL 對庫、表、列和 UDF 的訪問權限控制、行級別權限控制和資料脫敏三方面的權限管理與控制,接下來我們分兩部分對其實作原理進行講解,分別是自定義 Ranger 插件和 Spark SQL Extensions 機制,
自定義 Ranger 插件
在 Ranger 中添加一個新服務的權限校驗可分為兩部分:第一部分是為 Ranger 增加新服務模塊;第二部分是在新服務中增加 Ranger 權限校驗插件,
● Ranger 增加新服務模塊
Ranger 增加新服務模塊是在 Ranger Admin Web UI 界面增加對應服務模塊,用來為對應服務添加對應資源的授權策略,新服務模塊增加可以分為以下三個步驟:
? 為新服務定義描述檔案,檔案名為 ranger-servicedef-< serviceName>.json,在描述檔案中定義了服務的名字、在 ranger admin web 界面中顯示的名稱、新服務訪問類定義、需要用來進行權限校驗的資源串列和需要進行校驗的訪問型別串列等,
ranger-servicedef-< serviceName>.json 內容主要部分引數決議如下:
{
"id":"服務id,需要保證唯一",
"name":"服務名",
"displayName":"在Ranger Admin Web UI上顯示的服務名",
"implClass":"在Ranger Admin內部用于訪問新服務的實作類",
// 定義新服務用于權限校驗的資源串列,如Hive中的database、table
"resources":[
{
"itemId": "資源id, 從1開始遞增",
"name": "資源名",
"type": "資源型別,通常為string和path",
"level": "資源層級,同一層級的會在一個下拉框展示",
"mandatory": "是否為必選",
"lookupSupported": "是否支持檢索",
"recursiveSupported": false,
"excludesSupported": true,
"matcher": "org.apache.ranger.plugin.resourcematcher.RangerDefaultResourceMatcher",
"validationRegEx":"",
"validationMessage": "",
"uiHint":"提示資訊",
"label": "Hive Database",
"description": "資源描述資訊"
}
],
// 定義資源需要進行校驗的訪問型別串列,如select、create
"accessTypes":[
{
"itemId": "訪問型別id, 從1開始遞增",
"name": "訪問型別名稱",
"label": "訪問型別在Web界面上的顯示名稱"
}
],
"configs":[
{
"itemId": "配置引數id, 從1開始遞增",
"name": "配置引數名稱",
"type": "引數型別",
"mandatory": "是否必填",
"validationRegEx":"",
"validationMessage": "",
"uiHint":"提示資訊",
"label": "在Web界面上的顯示名稱"
}
]
}
? 開發 Ranger 中新服務模塊對應的實作類,并將該類名填寫到 ranger-servicedef-< serviceName>.json 中 implClass 欄位上,新服務模塊的實作類需要繼承抽象類 RangerBaseService,RangerBaseService 是 Ranger 中所有服務的基類,它定義了一組公共方法和屬性,以便所有服務都可以共享和繼承,RangerBaseService 提供了基本功能,如訪問控制,資源管理和審計跟蹤等,
開發新服務模塊的實作類是比較容易的,通過繼承 RangerBaseService 并實作 validateConfig 和 lookupResource 兩個方法即可,validateConfig 方法是用來驗證服務的配置是否正確,lookupResource 方法定義了加載資源的方法,
? 第一步和第二部完成后分別將組態檔 ranger-servicedef-< serviceName>.json 和新服務模塊對應的實作類 jar 包放到 Ranger Admin 的 CLASSPATH 中,并使用 Ranger Admin 提供的 REST API 向 Ranger 注冊定義的服務型別,這樣就能在 Ranger Admin UI 界面看到新服務的模塊并能通過界面配置對應權限控制,
● 新服務中增加 Ranger 權限校驗插件
新服務中要實作 Ranger 的權限校驗需要開發對應的權限控制插件并注冊到新服務中,該插件實作的時候需要在服務中找到一個切入點來攔截資源的訪問請求并呼叫 Ranger API 來授權訪問,接下來介紹一下 Ranger 權限校驗插件開發中比較重要的4個類:
? RangerBasePlugin:Ranger 權限校驗的核心類,主要負責拉取策略、策略快取更新及完成資源訪問的權限校驗
? RangerAccessResourceImpl:對鑒權資源進行封裝的實作類,呼叫鑒權介面時需要構造這么一個類
? RangerAccessRequestImpl:請求資源訪問的實作類,包含鑒權資源的封裝物件、用戶、用戶組、訪問型別等資訊,呼叫鑒權介面 isAccessAllowed 時需要將 RangerAccessRequestImpl 作為引數傳入
? RangerDefaultAuditHandler:審計日志的處理類
實作 Ranger 權限校驗插件分為以下步驟:
? 撰寫目標類繼承 RangerBasePlugin,通常只需要在目標類實作的構造方法中呼叫父類的建構式并填入對應的服務型別名稱和重寫 RangerBasePlugin 的 init 方法并在重寫的 init 方法中呼叫父類的 init 方法,
RangerBasePlugin 的 init 方法中實作了策略的拉取并會啟動一個后臺執行緒定時更新本地快取的策略,
? 撰寫承上啟下的類,用于配置在目標服務中能夠攔截目標服務所有的資源請求并能呼叫 RangerBasePlugin 的 isAccessAllowed 方法進行資源請求鑒權,對于 Spark SQL 實作 Ranger 的權限校驗來說我們基于 Spark SQL 的 Extensions 機制(后文會進行講解),通過自定義一個 Spark Extensions 注冊到 Spark 中來在 SQL 語法決議階段通過遍歷生成的抽象語法樹完成資源訪問的權限校驗,
Spark SQL Extensions 機制
Spark SQL Extensions 是在 SPARK-18127 中被引入,提供了一種靈活的機制,使得 Spark 用戶可以在 SQL 決議的 Parser、Analyzer、Optimizer 以及 Planner 等階段進行自定義擴展,包括自定義 SQL 語法決議、新增資料源等等,
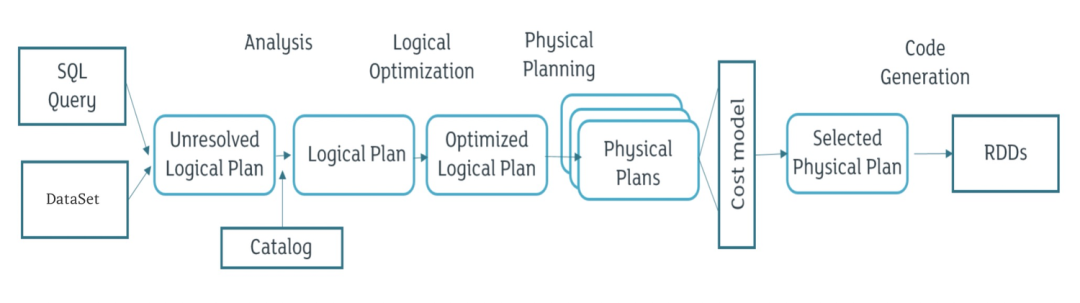
SparkSessionExtensions 為 Spark SQL Extensions 機制的核心類,SparkSessionExtensions 保存了用戶自定義的擴展規則,包含以下方法:
? buildResolutionRules:構建擴展規則添加到 Analyzer 的 resolution 階段
? injectResolutionRule:向 Analyzer 的 resolution 階段注冊擴展規則生成器
? buildPostHocResolutionRules:構建擴展規則添加到 Analyzer 的 post-hoc resolution 階段
? injectPostHocResolutionRule:向 Analyzer 的 post-hoc resolution 階段注冊擴展規則生成器
? buildCheckRules:構建擴展檢查規則,該規則將會在 analysis 階段之后運行,用于檢查 LogicalPlan 是否存在問題
? injectCheckRule:注冊擴展檢查規則生成器
? buildOptimizerRules:構建擴展優化規則,將在 optimizer 階段被呼叫執行
? injectOptimizerRule:注冊擴展優化規則生成器
? buildPlannerStrategies:構建擴展物理執行計劃策略,用于將 LogicalPlan 轉換為可執行檔案
? injectPlannerStrategy:注冊擴展物理執行計劃策略生成器
? buildParser:構建擴展決議規則
? injectParser:注冊擴展決議規則生成器
基于 Spark SQL Extensions 機制實作自定義規則會很容易,首先撰寫類實作 Function1[SparkSessionExtensions, Unit] ,SparkSessionExtensions 作為函式入參,呼叫 SparkSessionExtensions 對應方法將自定義的決議規則注冊到對應的 SQL 決議階段執行,然后將撰寫的類通過引數 spark.sql.extensions 指定注冊到 Spark 中,
Spark SQL權限控制在數堆疊中的實踐
Spark 在數堆疊中主要應用于離線數倉的場景,對離線資料進行批處理,大多數場景下資料大多都是存在業務庫中的如 MySQL、Oracle 等,在數堆疊上會先使用 ChunJun 進行資料采集將資料從業務庫同步到 Hive 庫的 ODS 層,然后通過 Hive 或者 Spark 引擎進行資料的批處理計算,最后再通過 ChunJun 將結果資料同步到對應業務庫中,
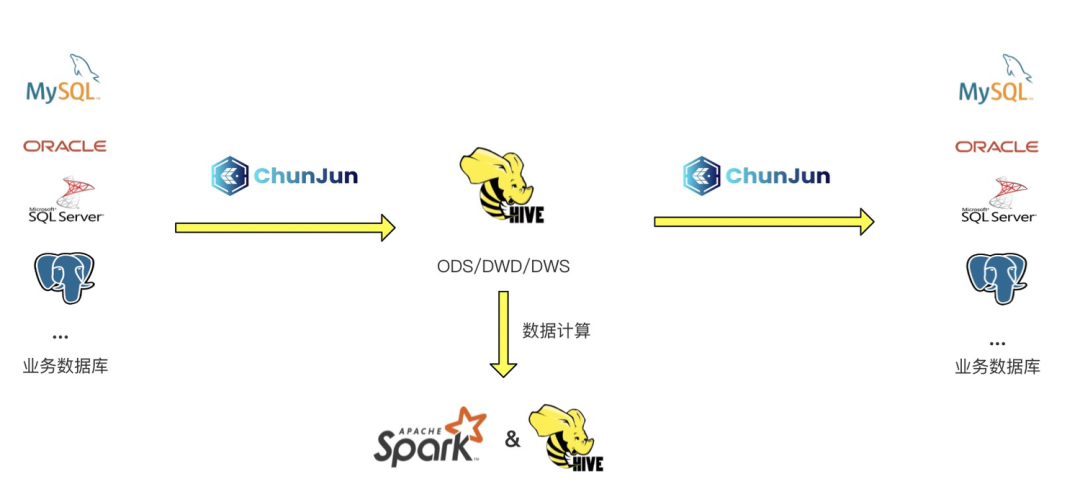
對應的業務庫大多都是關系型資料庫,每個關系型資料庫也都已經具有非常完善的權限管理機制,在早期的數堆疊中是缺少對 Hive 上資料的安全管控的,這也就導致 Hive 上的資料可以被每個用戶獲取查看,缺少了資料隱私保護,
為了解決 Hive 資料安全的問題,我們選擇了使用 Ranger 來對 Hive 進行權限控制,
Ranger 是一個非常全面的資料安全管理框架,它提供了 Web UI 供用戶進行權限策略設定,使得 Ranger 更加易用,Ranger 安全相關的功能也十分豐富,管控力度更細,支持資料庫表級別權限管理,也支持行級別過濾和資料脫敏等非常實用的功能,對 Ranger 進行擴展也比較靈活,在 Ranger 上能夠很輕松實作一個新服務的權限管控,
在數堆疊上 Spark 用來處理 Hive 中的資料,Hive 使用 Ranger 進行了資料的權限管控,所以為了保證資料安全數堆疊基于 Ranger 自研了 Spark SQL 的權限管控插件,
上文我們提到為一個新服務自定義 Ranger 權限管控插件分為兩部分來完成,第一部分是在 Ranger Admin Web UI 界面增加對應的服務模塊,考慮到 Spark 只用來處理 Hive 中的資料所以在權限策略這個地方應該要和 Hive 保持一致,所以在 Spark SQL 基于 Ranger 實作權限控制插件時沒有重復造輪子而是直接復用 HADOOP SQL 服務模塊,和 Hive 共同使用同一套策略,所以我們只需要在 Spark 端開發 Ranger 的權限管理插件,
基于 Spark SQL Extensions 機制,我們撰寫了類 RangerSparkSQLExtension,并在該類中將實作好的鑒權 Rule、行級過濾 Rule 和資料脫敏 Rule 通過呼叫 SparkSessionExtensions.injectOptimizerRule 方法注冊將到 SQL 決議的 Optimizer 階段,
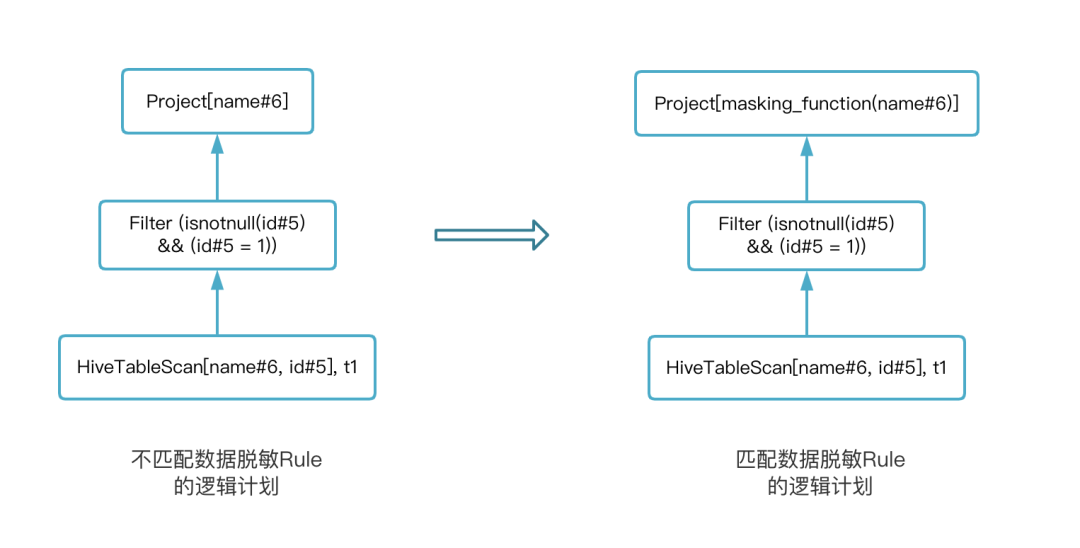
以資料脫敏 Rule 為例,當匹配到資料脫敏的 Rule 后,該 Rule 會為 Logical Plan 增加一個 Project 節點并增加 masking_function 函式呼叫的邏輯,通過下圖展示匹配資料脫敏 Rule 前后的變化,以 select name from t1 where id = 1 為例:
總結
數堆疊一直致力于資料的安全和隱私保護,實作 Spark SQL 基于 Ranger 的權限控制是數堆疊在資料安全探索的其中一點,本文講述了基于 Ranger 實作 Spark SQL 權限校驗的原理,基于 Ranger 賦予了 Spark SQL 在權限管控方面,更強的管控力度、更豐富的能力,
未來在保證安全的前提下數堆疊將對性能進行進一步的優化,比如將權限校驗 Rule 注冊到 SQL 優化器上,可能會被執行多次增加,這樣就會增加一些不必要的鑒權,期待大家對數堆疊的持續關注,
《數堆疊產品白皮書》:https://www.dtstack.com/resources/1004?src=https://www.cnblogs.com/DTinsight/p/szsm
《資料治理行業實踐白皮書》下載地址:https://www.dtstack.com/resources/1001?src=https://www.cnblogs.com/DTinsight/p/szsm
想了解或咨詢更多有關袋鼠云大資料產品、行業解決方案、客戶案例的朋友,瀏覽袋鼠云官網:https://www.dtstack.com/?src=https://www.cnblogs.com/DTinsight/p/szbky
同時,歡迎對大資料開源專案有興趣的同學加入「袋鼠云開源框架釘釘技術qun」,交流最新開源技術資訊,qun號碼:30537511,專案地址:https://github.com/DTStack
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/552743.html
標籤:大數據
上一篇:單表查詢
下一篇:返回列表