摘要:究竟是不是cpu占比高的問題導致redis超時的呢?
本文分享自華為云社區《我又和redis超時杠上了》,作者:藍胖子的編程夢 ,
背景
經過上次redis超時排查,并聯系云服務商解決之后,redis超時的現象好了一陣子,但是最近又有超時現象報出,但與上次不同的是,這次超時的現象發生在業務高峰期,在簡單看過服務器的各項指標以后,發現只有cpu的使用率在高峰期略高,我們是8核cpu,高峰期能達到90%的使用率,其余指標都相對正常,
但究竟是不是cpu占比高的問題導致redis超時的呢?還有待商榷,因為cpu調度程式慢本質上也是個概率性事件,
解決思路
略帶僥幸的聯系云服務商
有了上次的經驗過后,我也是聯系了云服務商那邊也排查下是否還存在上次超時的原因,但其實還是有直覺,這次的原因和上次超時是不一樣的(備注:上次超時是由于云服務商那邊對集群的流量隔離做的不夠好,導致其他企業機器流量影響到了我們的機器,且發生在業務低峰期),這次發生在業務高峰期,
果然,云服務商得出的結論也是之前出問題的機器以及遷移走了,并且他們也和我同時展開排查,
抓包分析
在ecs服務器上進行抓包,當出現超時時,關閉tcpdump進行分析,
tcpdump 漏包了?
在dump下抓包檔案后,經過wireshark分析,并沒有發現丟包資訊,想著應該是tcpdump漏包了,
tcpdump 出現漏包的情況
[webserver@hw-sg1-test-0001 ~]$ sudo tcpdump -i eth0 tcp port 6379 -w p.cap -W 2 -G 3600 -C 2000 tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
可以看到默認的抓包大小262144 bytes,在業務高峰期如果每個包最大長度都在這個值,很可能就導致緩沖區滿了,而之前一次抓包分析為什么就沒有這個問題呢,因為那是在業務低峰期,tcpdump丟包概率比較小,
sudo tcpdump -i eth0 tcp port 6379 -w p5.cap -W 2 -G 3600 -C 2000 tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes ^C147940 packets captured 468554 packets received by filter 318544 packets dropped by kernel
packets dropped by kernel 說明tcpdump丟棄了某些包,因為tcpdump在處理包時,是先將包放到一個緩沖區進行分析,當緩沖區滿的時候會直接進行丟棄,這樣導致我在用wireshark分析包的時候,就會出現有些包找不到的情況,
在縮小抓取的包大小和去掉域名決議后,不再漏包了,
[webserver@hw-sg1-backend-0003 ~]$ sudo tcpdump -i eth0 tcp port 6379 -w p5.cap -W 2 -G 3600 -C 2000 -n -s 1520 tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 1520 bytes ^C21334 packets captured 21454 packets received by filter 0 packets dropped by kernel
抓包分析超時情況
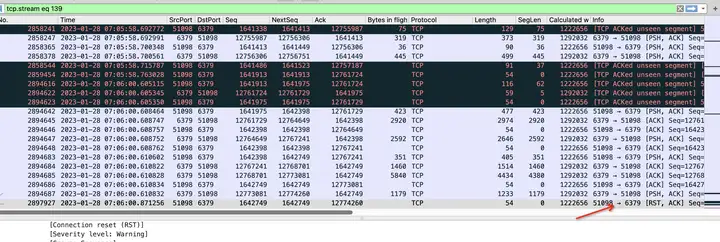
redis客戶端超時時間設定的200ms,可以看到2894687號包是redis服務器發送給客戶端的包,然后2897927是客戶端發送給redis服務端的rst,正常情況客戶端收到redis服務端的psh信號的包應該會回復一個ack的,但是客戶端卻在200ms以后回復了一個rst,說明了什么問題?
我們的客戶端是golang寫的,可以想到的情況是,客戶端程式在讀取包程序協程會有切換背景關系操作,當客戶端發現有可讀包時并切回go協程的時候,會首先判斷當前讀操作是否超時,如果超時,則直接呼叫close方法關閉連接了,
那么close方法是發送rst信號嗎,正常不應該是fin信號?
非也,close方法如果關閉的時候,連接讀緩沖區的資料還有未被應用程式讀取的話,那么此時close方法的呼叫會發送rst信號,
可見,問題的確是出在客戶端了,并且看上去像是客戶端來不及讀取服務端的訊息,看到這里,其實我心里已經百分之八九十確定是cpu的使用率達到瓶頸了,
云服務商來信了
在分析到上一個步驟的時候,云服務商告訴我,他們知道原因了,是ecs服務的磁盤吞吐量達到瞬時上線,說故障點是和超時的故障點是吻合的,
我知道這個后,第一時間的疑惑是,為啥磁盤吞吐會影響到網路傳輸,云服務商給的解釋是磁盤吞吐達到瞬時上線后,對服務整體是有影響的,我又看了下ecs的監控圖示,發現監控圖示顯示的磁盤吞吐遠遠沒有云服務商提到的那么多,


盡管云服務商堅持是磁盤iops達到了上限,但還是不能說服我 磁盤的iops瞬時上限會那么大影響到網路傳輸,
于是有了接下來第二天的抓包分析,
第二天的抓包分析
基于對昨天的分析,我懷疑到了cpu頭上,如果cpu切換行程緩慢,協程調度緩慢,那么的確是有可能發生超時的,由于目前的監控缺少對協程調度延遲的監控,所以決定加上這一指標,
golang1.17后 runtime包提供了協程調度延遲的直方圖統計資訊,而go prometheus的client其實以已經支持將這個資訊轉換為prometheus內置的指標型別,metric名稱是go_sched_latencies_seconds,而我們之前試用prometheus的client包注冊的collector 是兼容到go1.16以及之前的版本,所以沒有當改用到最新的collector后,client如期回傳了go_sched_latencies_seconds 直方圖資訊,
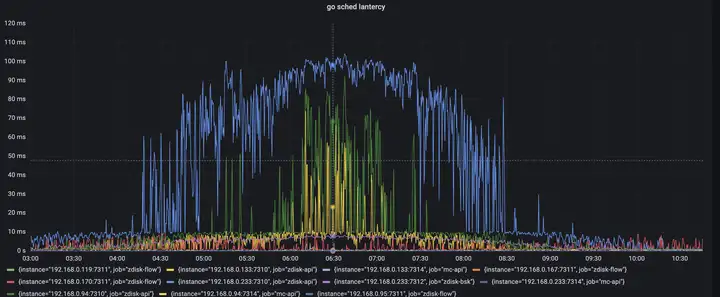
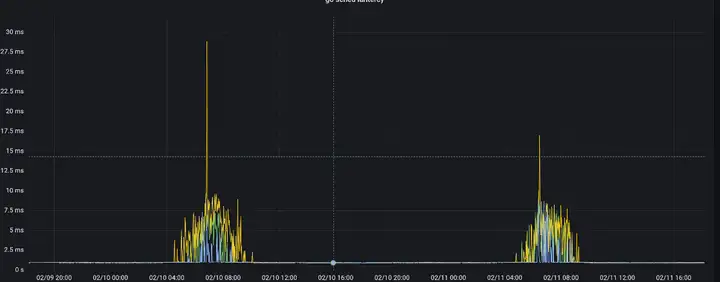
將這個資訊展示在grafana里,于是有了第二天協程調度延遲的資訊,p999在業務高峰期間達到了100ms,也是與超時時間吻合的,協程調度延遲指的是協程變為可運行狀態后到被真正執行這段時間等待被調度的時間,這里都高達100ms了,如果加上cpu執行緒,行程切換背景關系時間,很有可能是超過了redis client端設定的200ms超時上限,
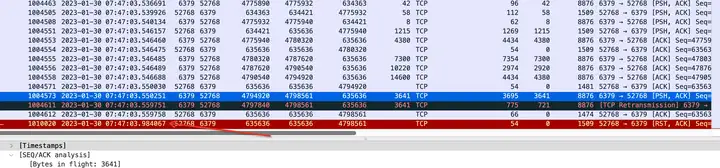
為了排除掉是磁盤原因引起的超時,
我在7點又進行了抓包分析,發現和昨天抓到包的情況是一致的,客戶端最后來不及回應服務端的包最后發送rst了,
然后看了下此時機器磁盤吞吐情況,發現圖中箭頭處也處于高峰期,但是磁盤吞吐量并未上去,而升上去的點正是抓包帶來的,懷疑是抓包寫入檔案導致磁盤吞吐量漲上去了,于是又問了服務商要磁盤達到瞬時峰值的日志,
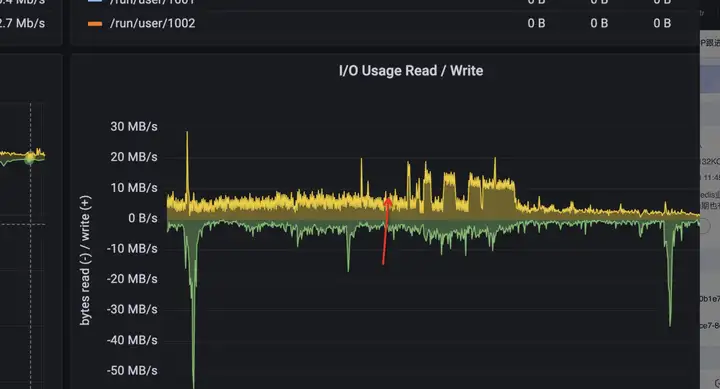

發現報瞬時峰值的日志也和抓包時間吻合,所以已經確認磁盤吞吐達到上限是抓包導致的,網路超時是和磁盤吞吐無關的,反而應該是cpu使用率達到上限了,雖然沒有100%,也是8核,但畢竟cpu某個核達到上限是概率性事件,而對于redis這種時延敏感性應用,一但發生,那么超時是有可能的,
完美解決
于是,在業務低峰期將我們三臺ecs服務進行了cpu配置提升,提升后效果很明顯,超時在高峰期不見了,協程調度延遲也大大減少,
總結
1,對于抓包分析,還是疏忽了,加上包限制大小,能很好的防止tcpdump抓包時丟包的情況,
2,對于任何第三方的說法要有自己的判斷力,像這次如果中途去將磁盤擴容顯然是不能解決問題的,
3,性能問題分析真是像一個偵探破案的程序,不斷列出證據,不斷排除掉干擾因素,不斷論證的程序也是性能分析的魅力所在吧,就像這次看到cpu的確比較高了,但是究竟是不是客戶端問題呢?我又抓包論證了的確是客戶端問題,那究竟是不是協程調度問題呢?我又列出協程調度延遲,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/553900.html
標籤:其他
上一篇:MongoDB學習筆記:組態檔
下一篇:返回列表