代碼如下:
MERGE INTO T_PA_CITEM_KIND t_pa
USING CCIC.PRPCITEMKIND t_p
ON (t_pa.POLICYNO = t_p.POLICYNO
AND t_pa.SEQNO = t_p.ITEMKINDNO )
WHEN MATCHED THEN
UPDATE
SET t_pa.RISKCODE = t_p.RISKCODE
, t_pa.CLAUSENAME = t_p.KINDNAME
, t_pa.KINDNAME = t_p.ItemDetailName
, t_pa.STARTDATE = t_p.STARTDATE
, t_pa.STARTHOUR = t_p.STARTHOUR
, t_pa.ENDDATE = t_p.ENDDATE
, t_pa.ENDHOUR = t_p.ENDHOUR
, t_pa.CURRENCY = t_p.CURRENCY
, t_pa.CALCULATEFLAG = t_p.CALCULATEFLAG
, t_pa.UNITAMOUNT = t_p.UNITAMOUNT
, t_pa.QUANTITY = t_p.QUANTITY
, t_pa.RATE = t_p.RATE
, t_pa.SHORTRATE = t_p.SHORTRATE
, t_pa.SHORTRATEFLAG = t_p.SHORTRATEFLAG
, t_pa.AMOUNT = t_p.AMOUNT
, t_pa.PREMIUM = t_p.PREMIUM
, t_pa.KINDVAT = t_p.KINDVAT
, t_pa.TNIPREMIUM = t_p.TNIPREMIUM
, t_pa.VATRATETYPE = t_p.VATRATETYPE
, t_pa.FLAG = t_p.FLAG
WHEN NOT MATCHED THEN
INSERT (POLICYNO, SEQNO, ITEMTYPE, REL_REF_SEQNO, RISKCODE, CLAUSECODE, CLAUSENAME, KINDCODE
, KINDNAME, STARTDATE, STARTHOUR, ENDDATE, ENDHOUR, CURRENCY, CALCULATEFLAG, UNITAMOUNT
, UNITPREMIUM, QUANTITY, RATE, SHORTRATE, SHORTRATEFLAG, AMOUNT, PREMIUM, KINDVAT
, TNIPREMIUM, VATRATETYPE, FLAG, ORIGININPUTFLAG)
VALUES( t_p.POLICYNO
, t_p.ITEMKINDNO
, NULL
, NULL
, t_p.RISKCODE
, null
, t_p.KINDNAME
, null
, t_p.ItemDetailName
, t_p.STARTDATE
, t_p.STARTHOUR
, t_p.ENDDATE
, t_p.ENDHOUR
, t_p.CURRENCY
, t_p.CALCULATEFLAG
, t_p.UNITAMOUNT
, NULL
, t_p.QUANTITY
, t_p.RATE
, t_p.SHORTRATE
, t_p.SHORTRATEFLAG
, t_p.AMOUNT
, t_p.PREMIUM
, t_p.KINDVAT
, t_p.TNIPREMIUM
, t_p.VATRATETYPE
, t_p.FLAG
, 'Y'
)
執行計劃如下:
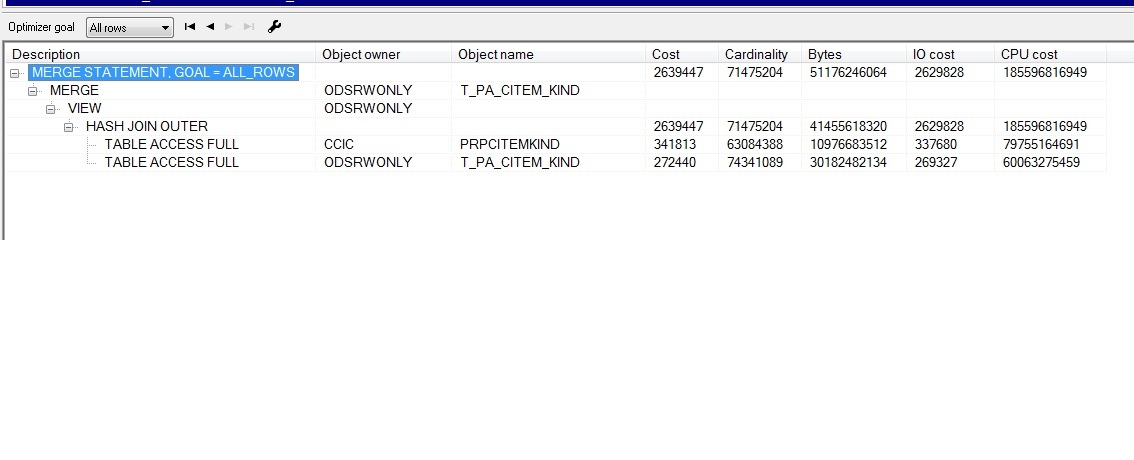
這兩個表資料量都是4千萬以上的。更新和插入的資料量都挺大的。實際執行程序還有一個時間標志,目前沒有,所以沒加。
執行時間太長,請問有什么優化的辦法。兩個都有主鍵,關聯也是用主鍵關聯的。
在線等,謝謝!
uj5u.com熱心網友回復:
如果你用的關聯欄位就是目標表的主鍵欄位,那么可能有幾個改進措施:1、看看兩表連接欄位是否型別不一致?如果不一致,那么轉化臨時表的欄位型別與目標表保持一致,要么修改表定義,要么使用對應函式修改臨時表連接條件;
2、如果不是1的原因,那么可以收集兩表統計資訊試試:exec dbms_stats.gather_table_stats('用戶名',‘表名',cascade=>true,method_opt=>'for all indexed columns repeat')
3、如果經過以上調整都速度很慢,無法調整執行計劃中的HASH JOIN成為NESTED LOOPS,那么就添加提示,加在merge關鍵字后面:merge /*+use_nl_with_index(t_pa)*/
4、如果經過3還不行,那么繼續發添加提示后的陳述句和執行計劃上來
uj5u.com熱心網友回復:
補充:如果你的臨時表4千萬資料全部參與merge,那么現在這個SQL慢是正常的,執行計劃也可以說是合理的,但是如果實際跑的時候會有時間條件落到這張臨時表上,過濾出少量記錄,那么上貼發的建議才有實施的價值。
uj5u.com熱心網友回復:
兩個 4000W 都 要計算嗎 ? 那最好分批更新,比如嘗試原表每 10W 行一次。看看時間。uj5u.com熱心網友回復:
1.先確認update的資料量有多大?2.update的資料量多的話要檢查T_PA_CITEM_KIND t_pa 表索引,一般都會把索引禁用后重新rebuilt,因為修改資料會產生大量的日志。
3.CCIC.PRPCITEMKIND t_p獲取新增和修改的保單,并不需要做全量保單資料同步
uj5u.com熱心網友回復:
兄弟,資料庫要是都像你這么干,天河一號早晚也要跑死這種千萬級別的資料,肯定要做大事務分割,無論什么業務邏輯,量少的時間都要簡單。量大的時候都不簡單,就算是一個簡單的SQL都可以完成的東西,也不能就一個簡單的SQL就去做
uj5u.com熱心網友回復:
請添加索引聯合索引或者parallel解決試試uj5u.com熱心網友回復:
1、t_pa.POLICYNO , t_p.POLICYNO , t_pa.SEQNO , t_p.ITEMKINDNO 建立索引(資料型別要一致)2、索引沒用上的話可以指定使用索引。
3、marge Into 后增加 /*+parallel(t_pa,5) parallel(t_p,5) use_hash(t_pa,t_p)*/ 此陳述句為并發陳述句,你的cpu和記憶體要足夠,否則可能會拖垮你的cpu,5可以自定義,相應減少。
3、如果整體表資料較多,分段執行,即10w一次執行,回圈。
4、最后,merge Into 實際上也可使用以下方式進行。T_PA_CITEM_KIND 表上增加 iscurrent (默認為1,有效),
先update T_PA_CITEM_KIND set iscurrent=0 where exists (select 1 from PRPCITEMKIND f where f...=t... and f....=t....)
在 insert into T_PA_CITEM_KIND(欄位,iscurrent) (select 欄位,1 from PRPCITEMKIND)
每次取iscurrent=1的,此為資料倉庫的做法,可以保留原始資料。具體看你是用。
uj5u.com熱心網友回復:
這種大事務處理肯定要分成N個小事務來處理,比如用游標每10000行提交一次的方法更新,而且資源允許的話可以加上并行。你陳述句并不復雜只是單單的表體量把事務搞復雜化了轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/55462.html
標籤:高級技術
上一篇:python