
向量資料庫和 Embedding 是當前 AI 領域的熱門話題,
Pinecone 是一家向量資料庫公司,剛剛以約 10 億美元的估值籌集了 1 億美元,
Shopify、Brex、Hubspot 等公司都在他們的 AI 應用程式中使用向量資料庫和 Embedding,那么,它們究竟是什么,它們是如何作業的,以及為什么它們在 AI 中如此重要呢?讓我們一探究竟,
我們先看第一個問題,什么是 Embedding?你可能在 Twitter 上已經看到這個詞被無數次提及,
簡單來說,Embedding 就是一個多維向量陣列,由系列數字組成,它們能夠代表任何東西,比如文本、音樂、視頻等等,我們這里將主要關注文本,

創建 Embedding 的程序非常簡單,這主要依靠 Embedding 模型(例如:OpenAI 的 Ada),
你將你的文本發送給模型,模型會為你生成該資料的向量結果,這可以被存盤并在之后使用,
Embedding 之所以重要,是因為它們賦予我們進行語意搜索的能力,也就是通過相似性進行搜索,比如通過文本的含義,
因此,在這個例子中,我們可以在一個向量空間上表示“男人”“國王”“女人”和“王后”,你可以非常容易地看到它們在向量空間之間的關系,
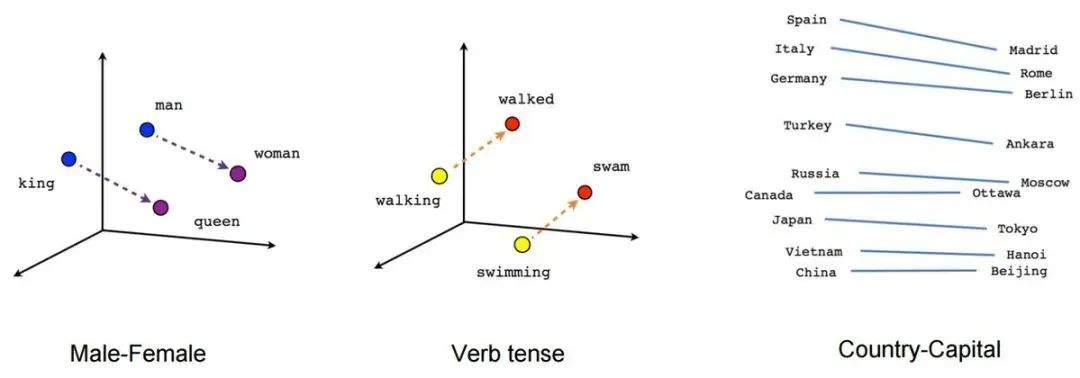
來看一個更直觀的例子:
假設你是一個有一大箱玩具的小孩,現在,你想找出一些類似的玩具,比如一個玩具汽車和一個玩具巴士,它們都是交通工具,因此它們是相似的,
這就是所謂的 “語意相似性”—— 表示某種程度上事物具有相似的含義或想法,
現在假設你有兩個相關聯但并不完全相同的玩具,比如一個玩具汽車和一個玩具公路,它們并不完全相同,但因為汽車通常在公路上行駛,所以它們是相互關聯的,
那么,Embedding 為何如此重要呢?主要是由于大語言模型(LLM)存在背景關系限制,在一個理想的世界中,我們可以在一個 LLM 提示中放入無限數量的詞語,但是,正如許多人所知,目前我們還做不到,以 OpenAI 的 GPT 為例,它限制在大約在 4096 - 32k 個 token,
因此,由于其 “記憶體”(即我們可以填充到其 token 的詞語的數量),我們與 LLM 的互動方式受到了嚴重限制,這就是為什么你不能將一個 PDF 檔案復制粘貼到 ChatGPT 中并要求它進行總結的原因,(當然,現在由于有了 gpt4-32k,你可能可以做到這一點了)
那么,怎么把 Embedding 和 LLM 關聯起來解決 token 長度限制的問題呢?實際上,我們可以利用 Embedding,只將相關的文本注入到 LLM 的背景關系視窗中,
讓我們來看一個具體的例子:
假設你有一個龐大的 PDF 檔案,可能是一份國會聽證會的記錄(呵呵),你有點懶,不想閱讀整個檔案,而且由于其頁數眾多,你無法復制粘貼整個內容,這就是一個 Embedding 的典型使用場景,
所以你將 PDF 的文本內容先分成塊,然后借助 Embedding 將文本塊變成向量陣列,并將其存盤在資料庫中,
在存盤分塊的向量陣列時,通常還需要把向量陣列和文本塊之間的關系一起存盤,這樣后面我們按照向量檢索出相似的向量陣列后,能找出對應的文本塊,一個參考的資料結構類似于這樣:
{
[1,2,3,34]: '文本塊1',
[2,3,4,56]: '文本塊2',
[4,5,8,23]: '文本塊3',
……
}
現在你提出一個問題:“他們對 xyz 說了什么?”我們先把問題“他們對 xyz 說了什么?”借助 Embedding 變成向量陣列,比如[1,2,3],
現在我們有兩個向量:你的問題 [1,2,3] 和 PDF [1,2,3,34],然后,我們利用相似性搜索,將問題向量與我們龐大的 PDF 向量進行比較,OpenAI 的 Embedding 推薦使用的是余弦相似度,
好了,現在我們有最相關的三個 Embedding 及其文本,我們現在可以利用這三個輸出,并配合一些提示工程將其輸入到 LLM 中,例如:
已知我們有背景關系:文本塊 1,文本塊 2,文本塊 3,
現在有用戶的問題:他們對 xyz 說了什么?
請根據給定的背景關系,如實回答用戶的問題,
如果你不能回答,那么如實告訴用戶“我無法回答這個問題”,
就這樣,LLM 會從你的 PDF 中獲取相關的文本部分,然后嘗試如實回答你的問題,
這就簡單的闡述了 Embedding 和 LLM 如何為任何形式的資料提供相當強大的類似聊天的能力,這也是所有那些“與你的網站/PDF/等等進行對話” 的功能如何作業的!
請注意 Embedding 并非 FINE-TUNING,
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/How-does-a-vector-database-work.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/555138.html
標籤:其它
下一篇:返回列表