摘要:HyG圖計算引擎采用CSR格式來存盤圖的拓撲資訊,CSR格式可以將稀疏矩陣的存盤空間壓縮,進而大大降低圖的存盤開銷,同時具備訪問效率高、格式易轉化等優點,
本文分享自華為云社區《CSR格式如何更新? GES圖計算引擎HyG揭秘之資料更新》,作者: π ,
HyG圖計算引擎采用CSR格式來存盤圖的拓撲資訊,CSR格式可以將稀疏矩陣的存盤空間壓縮,進而大大降低圖的存盤開銷,同時具備訪問效率高、格式易轉化等優點,利用CSR + 列存(parquet格式)的組合,HyG獲得了很高的圖訪問性能,但是,對于資料需要增量更新的場景,CSR的更新非常困難,可能會導致大量的資料復制和移動,進而影響系統性能,HyG對傳統CSR更新進行了一系列優化,實作了高效的資料更新,
什么是CSR格式?
CSR格式是一種常用的稀疏矩陣存盤格式,它將稀疏矩陣以三個陣列的形式存盤,具體來說,CSR格式使用 values、column indices和row offsets三個陣列來表示稀疏矩陣,
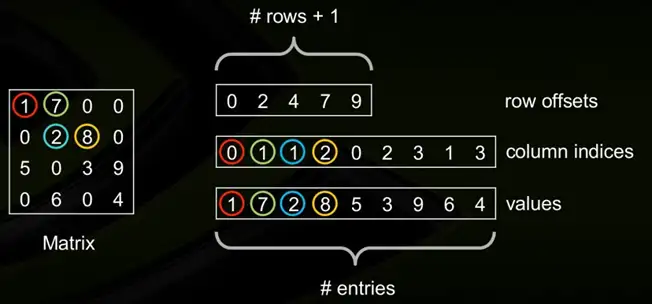
定義NNZ(Num-non-zero)為矩陣M中非0元素的個數,
第一個陣列為values陣列,其中,values陣列的長度為NNZ,分別從左到右從上到下的非零元素的值,
第二個陣列為column陣列,其中,column陣列的長度為NNZ,其對應于values陣列中的元素的column_index(例如元素8排列在所在行的第3個位置,因此其column index為2),
第三個陣列為row offsets,其中row offsets的陣列大小為m+1,其前m個元素分別代表這每一行中第一個非零元素在Values陣列的下標,(例如元素2是第二行的第二個元素,其在values陣列中的下標為2.),
CSC和CSR類似,只不過和CSR行列互換,values陣列里是按列存的數值,row offsets變成了col offsets,column陣列變成了row陣列,
CSR格式由于其緊湊的存盤方式和高效的計算方式,已經成為了處理稀疏矩陣的標準格式之一,具體來說,CSR格式可以利用連續的記憶體塊來存盤非零元素,這使得計算機在處理稀疏矩陣時可以跳過大量的零元素,從而提高了計算效率,此外,CSR格式所需要的存盤空間相對于其他格式,如COO格式(Coordinate)等,也更為緊湊,這在處理大型稀疏矩陣時非常有利,
如何更新CSR格式資料?
傳統方案:
更新圖資料需要對三個陣列進行操作:values、columns和row offset,
更新
要更新矩陣中某個位置(i,j)的值,需要找到該位置在CSR格式中對應的行(第i行)在values和columns陣列中的起始和結束索引,具體而言,該行的非零元素在values陣列中的起始位置是row offset [i],結束位置是row offset [i+1]-1,然后,在columns陣列中找到對應的列(第j列)的索引位置,
接下來,可以直接更新values陣列中對應位置的值,即values[row offset[i]+k],其中k是columns陣列中第j列的索引位置,
插入
如果要插入一個新的非零元素,可以按照以下步驟進行:
1、找到要插入的元素在CSR格式中對應的行(第i行)在values和columns陣列中的起始和結束索引,方法同上,
2、在columns陣列中找到新元素應該插入的位置,即找到插入元素后columns陣列中第j列的索引位置,
3、將新元素的值插入到values陣列中正確的位置,并將columns陣列中對應位置以及后面的元素向后移動一個位置,
4、更新row offset陣列中第i行及其后面所有行的元素起始位置,因為在第i行插入了一個新的非零元素,
洗掉
如果要洗掉一個非零元素,可以按照以下步驟進行:
1、找到要洗掉的元素在CSR格式中對應的行(第i行)在values和columns陣列中的起始和結束索引,方法同上,
2、在columns陣列中找到要洗掉的元素的位置,
3、從values和columns陣列中洗掉該元素,并將后面的元素向前移動一個位置,
4、更新row offset陣列中第i行及其后面所有行的元素起始位置,因為在第i行洗掉了一個非零元素,
需要注意的是,更新CSR格式中的元素可能會導致陣列長度的變化,因此需要動態分配和釋放記憶體空間,此外,在進行插入和洗掉操作時,可能需要對row offset陣列中的元素進行更新,這可能會影響CSR格式的性能,
總之,CSR格式的更新操作相對復雜,需要對三個陣列進行操作,并需要考慮記憶體分配和陣列長度的變化等問題,這十分不利于實時分批式的增量更新,
HyG資料更新策略
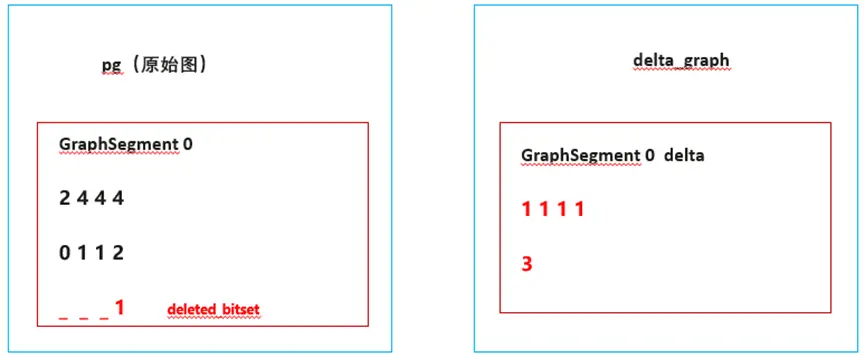
- 每次更新都會生成一個子圖(delta_graph),這個子圖是CSR格式,描述了增量資訊,
- 引入deleted_biset陣列,記錄被洗掉的點、邊資訊,
- 按順序加載 MergedPG = pg + [delta_graph]
- 對各點、邊按照所屬的pg/ delta_graph進行本地訪問和增、刪,
因為HyG考慮了分布式切分圖的場景,我們將場景簡化,接下來描述一下資料更新的流程,
圖原始資料如下圖所示,圖中包含4個點,4條邊,4條邊上的值分別為1、7、2、8,
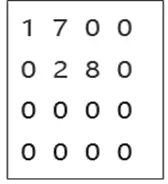
圖對應的CSR格式如下圖所示,這個是原始的拓撲資料,

我們對資料進行更新,基于原始圖新增了邊0(src)->3(dst),邊的值為3,洗掉了邊1(src)->2(dst),邊的值為8,
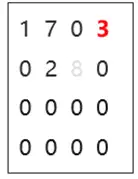
新增了1條邊,邊的src是0,dst是3,因此CSR的row offset為[1 1 1 1],column為[3],value為[3],進而得到了右側的delta graph,
洗掉了1條邊,這條邊是屬于pg(原始圖),所以,我們會對pg的deleted_bitset置位,因為洗掉是column陣列的最后一個,因此,我們會將最后一個bit置為1,表示這個邊已被洗掉,
到此,我們就完成了一次增、刪操作,生成了一個新的delta graph,這個delta graph跟歷史資料沒有任何關系,它只表示了本次增量的資料,因此,對于超大規模的圖,更新資料不再需要大量的資料拷貝和移動,只需要生成一個很小的delta graph就可以了,
圖訪問
經過增量更新,全量圖的資訊就會被分解為一個原始圖和一個增量圖,HyG設計了一種同時讀取到兩個圖資訊的訪問迭代器(以下簡稱“二級迭代器”),這種迭代器會將這多個子圖視為一個全量圖訪問,可以在不同的子圖間游走,
HyG增量圖迭代性能優化
HyG增量圖會產生多個快照,每個快照是一個子圖,對應著一次commit,演算法讀取增量圖需要依賴HyG的二級迭代器,迭代器會在不同的快照間游走,校驗點、邊是否已被洗掉,最侄訓傳給演算法結果,因此,迭代器需要維護很多資訊,遠遠大于pg(原始圖)的輕量級迭代器,進而使增量圖迭代的性能很低,快照數量越多性能下降越劇烈,
優化方案
HyG引入基于頁的快照索引技術來緩解由于存在大量快照導致的性能下降問題,
為每個快斬訓分虛擬頁,比如頁的大小是4K,那么一個頁對應著4K個點以及這4k點對應的邊,
索引表記錄了每個頁最近被更新的快照,因此,如果這個頁沒有被更新,那么利用索引表可以直接跳過對應的快照,
索引表采用copy on write的方式更新,每生成一個新快照,會把上一個快照的全部索引資訊copy一份,然后把修改資訊更新到對應的索引上,得到最新快照的索引表,
同時,對于二級迭代器的構造,我們也進行了優化,盡量減少資料成員的數量,當迭代器在不同快照間切換時,去更新該快照的背景關系資訊,而不會維護所有快照的資訊,
利用快照索引技術,我們可以快速的定位到點、邊對應的最新修改的快照,進而可以跳過很多無效的訪問,但是,隨著快照數量的增多,圖遍歷的性能還是會不斷下降,被洗掉的點、邊不但浪費了大量的存盤空間,還會增加無效的訪問延時,因此,設計一套有效的自動化合并方案,當快照數量過多或者洗掉點、邊過多時,觸發合并,提升系統性能,如果大家感興趣,我們后面會接著介紹HyG是如何實作快照合并的,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/555728.html
標籤:其他
下一篇:返回列表