前提:任意手機號經過設備,設備都會記錄下 經過的時間,手機號碼存入到資料庫
頁面傳來 陣列device(至少2個以上): device001 device002 device003 3臺設備,以及采集時間的范圍 開始時間startTime 結束時間 endTime
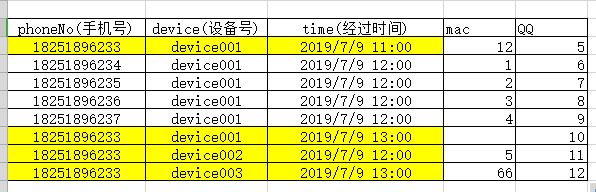
如何獲取到 手機號 先經過 device001 再經過 device002 最后經過 device003的次數以及其他詳細資訊,sql 怎么寫 圖中233的號碼應該是一次
uj5u.com熱心網友回復:
sqlserver?uj5u.com熱心網友回復:
是rdb的資料庫 就是普通的sql語法uj5u.com熱心網友回復:
同一個手機號,同一天,在一個設備里面是否會存在 2條資料?uj5u.com熱心網友回復:
會的,同一天有好多條
uj5u.com熱心網友回復:
我寫了一個二維的呈現sql,你看看與你的差異有多少;SELECT a.phoneNo,a.device device001,a.`time` AS time001,a.mac mac001,a.qq qq001 ,
b.device device002,b.`time` AS time002,b.mac mac002,b.qq qq003 ,c.device device003,
c.`time` AS time003,c.mac mac003,c.qq qq003
FROM
(SELECT phoneNo,device,`time`,DATE(`time`) data_date,mac,qq FROM table_test WHERE `time` >= '2019-07-09' AND `time` < DATE_ADD('2019-07-09',INTERVAL 1 DAY)
AND device = 'device001') a,
(SELECT phoneNo,device,`time`,DATE(`time`) data_date,mac,qq FROM table_test WHERE `time` >= '2019-07-09' AND `time` < DATE_ADD('2019-07-09',INTERVAL 1 DAY)
AND device = 'device002') b,
(SELECT phoneNo,device,`time`,DATE(`time`) data_date,mac,qq FROM table_test WHERE `time` >= '2019-07-09' AND `time` < DATE_ADD('2019-07-09',INTERVAL 1 DAY)
AND device = 'device003') c
WHERE a.phoneNo = b.phoneNo AND b.phoneNo = c.phoneNo AND a.phoneNo = c.phoneNo
AND a.data_date = b.data_date AND b.data_date = c.data_date AND a.data_date = c.data_date;
uj5u.com熱心網友回復:
當天多條資料,需要在子表里面加 GROUP BY phoneNo, DATE(`time`)uj5u.com熱心網友回復:
你可能理解錯了,現在以三個設備為例,我要的結果是所有手機號碼先經過設備1,再經過設備2,最后經過設備3的次數。不是按照這個順序的都不算。
uj5u.com熱心網友回復:
如果記錄是233 device01 2019-7-10 01:00:00
233 device02 2019-7-10 02:00:00
233 device03 2019-7-10 03:00:00
233 device02 2019-7-10 04:00:00
233 device03 2019-7-10 05:00:00
233 device02 2019-7-10 04:30:00
233 device03 2019-7-10 05:30:00
怎么算??
uj5u.com熱心網友回復:
我按照第幾行來說就是 123 125 127 145 147 167 6次記錄uj5u.com熱心網友回復:
剛剛說的不對,應該是只要存在設備1到設備2再到設備3的就算出現的總次數,你說的應該算7次
uj5u.com熱心網友回復:
思路 應該是這樣的,
首先拿出所有手機號 在設備1 當中的 資料,
去關聯所有手機號 在設備2 當中的 資料
然后 使用case when 打標 如果 設備2的時間>設備1 的時間 并且 使用substr截取 是同一天 1 其他 為 0
這里 有一點就是 設備2的時間必須有
然后用取標為1的資料關聯 設備3所有的資料
跟上面一樣 使用case when 打標 同一天并且設備2時間<小于設備3 為1 其他為0
最后 你再拿出所有上面打標為1 的資料 按照手機號 分組統計
uj5u.com熱心網友回復:
不想寫sql啊 ,思路給你了 ,有問題再找我uj5u.com熱心網友回復:
select distinct n.DiscoverMacAddr,m.cnt from
(select t1.DiscoverMacAddr,
(case when t1.StartTime< t2.StartTime and t2.StartTime< t3.StartTime then 1 ELSE 0 end ) flag
from
( select * from wifiuserdata where StartTime between '2019-05-28 08:20:22' and '2020-03-22 04:22:40'
and DeviceID ='ipcarma176' )t1,
( select * from wifiuserdata where StartTime between '2019-05-28 08:20:22' and '2020-03-22 04:22:40'
and DeviceID ='ipcarma177' )t2,
( select * from wifiuserdata where StartTime between '2019-05-28 08:20:22' and '2020-03-22 04:22:40'
and DeviceID ='ipcarma178' )t3
where t1.DiscoverMacAddr=t2.DiscoverMacAddr and t2.DiscoverMacAddr=t3.DiscoverMacAddr )n
left join
(select DiscoverMacAddr,count(1) cnt from wifiuserdata where StartTime between '2019-05-28 08:20:22' and '2020-03-22 04:22:40'
and DeviceID in('ipcarma176','ipcarma177','ipcarma178') group by DiscoverMacAddr) m
on m.DiscoverMacAddr=n.DiscoverMacAddr where n.flag=1 ;
sql 的話大致是這么寫。但是發現用的資料庫不支持子查詢,只能查詢出來去代碼中計算,
Map<String,List<DeviceInfo>> listMap = list.stream().collect(Collectors.groupingBy(DeviceInfo:: getPhone));
分解成 手機號 和 List的形式,接下去怎么通過 deviceId 的順序 判斷是否存在相應的采集時間。
uj5u.com熱心網友回復:
create table database.tmp_a as
select
t.*
from
(select
t1.*,
t2.StartTime time_2,
case when t2.StartTime>t1.StartTime and substr(t2.StartTime,0,10)=substr(t1.StartTime,0,10) then '1'
else '0'
end is_order
from
( select * from wifiuserdata where StartTime between '2019-05-28 08:20:22' and '2020-03-22 04:22:40'
and DeviceID ='ipcarma176' )t1
left join
( select * from wifiuserdata where StartTime between '2019-05-28 08:20:22' and '2020-03-22 04:22:40'
and DeviceID ='ipcarma177' )t2
on t1.DiscoverMacAddr=t2.DiscoverMacAddr
) t
where t.is_order='1';
select
t.DiscoverMacAddr,
count(1)
from
(select
t1.*,
case when t1.time_2>t3.StartTime and substr(t1.time_2,0,10)=substr(t3.StartTime,0,10) then '1'
else '0'
end is_order_1
database.tmp_a t1
left join
( select * from wifiuserdata where StartTime between '2019-05-28 08:20:22' and '2020-03-22 04:22:40'
and DeviceID ='ipcarma178' )t3
on t1.DiscoverMacAddr=t3.DiscoverMacAddr
) t
where t.is_order_1='1'
;
兄弟 ,你打算用mr還是 spark進行
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/55752.html
標籤:其他數據庫