2.1 InnoDB存盤引擎概述
InnoDB存盤引擎是第一個完整支持ACID事務的MySQL存盤引擎,其特點是行鎖設計、支持MVCC、支持外鍵、提供一致性非鎖定讀,同時被設計用來最有效的利用記憶體和CPU,
2.2 InnoDB存盤引擎版本
從MySQL5.1 版本時,MySQL資料庫允許存盤引擎開發商以動態方式加載引擎,這樣存盤引擎的更新可以不受MySQL資料庫版本的限制,
2.3 InnoDB體系架構
InnoDB存盤引擎有多個記憶體塊,可以認為這些記憶體塊組成了一個大的記憶體池,負責如下作業:
- 維護所有行程、執行緒需要訪問的多個內部資料結構
- 快取磁盤上的資料,方便快速的讀取,同時在對磁盤檔案的資料修改之前在這里快取,
- 重做日志緩沖(redo log)
- ……
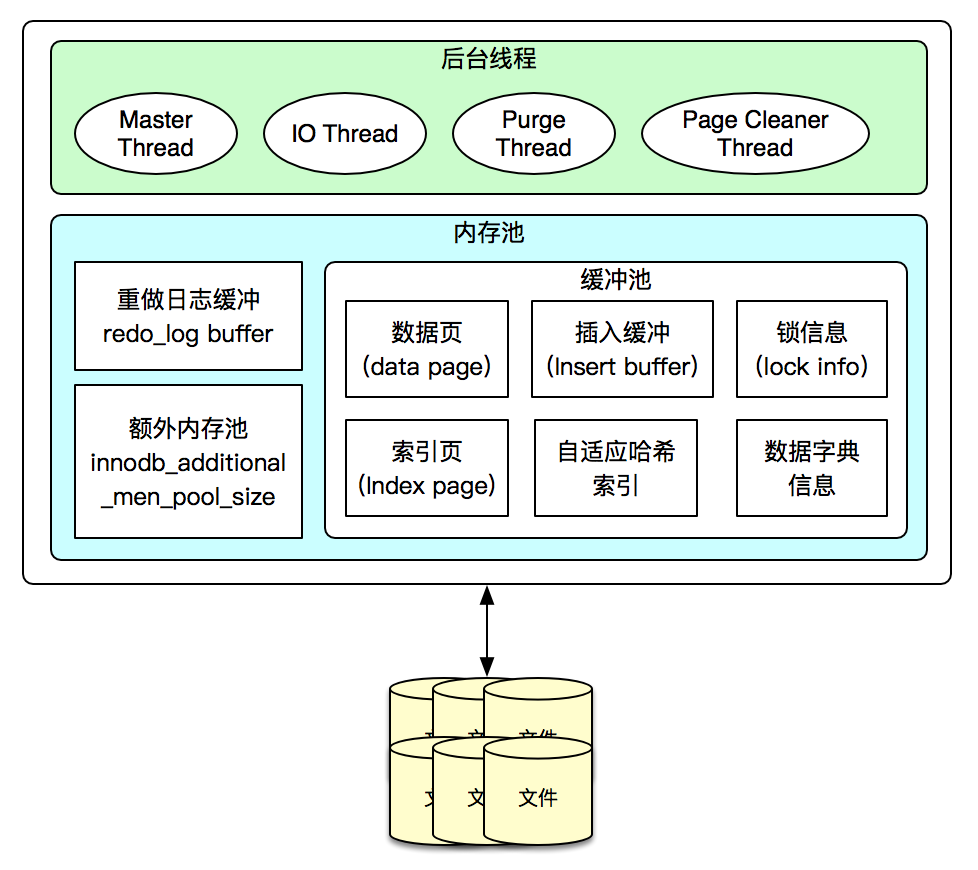
后臺執行緒的主要作用是負責重繪記憶體池中的資料,保證緩沖池中的記憶體快取的是最新的資料,此外將已修改的資料檔案重繪到磁盤檔案,同時,保證在資料庫發生例外的情況下,InnODB能恢復到正常狀態,
2.3.1 后臺執行緒
InnoDB是多執行緒的模型 ,不同執行緒負責不同的任務
2.3.1.1 Master Thread
負責將緩沖池中的資料異步重繪到磁盤,保證資料的一致性,其中包括臟頁的重繪、合并插入緩沖、UNDO頁的回收等
2.3.1.2 IO Thread
InnoDB 大量使用 AIO(Async IO)來處理寫 IO 請求,這樣可以提高資料庫的性能,IO Thread主要負責這些IO請求的回呼處理,
2.3.1.3 Purge Thread(清除執行緒)
事務被提交后,其使用的undo log 可能不再需要,因此需要 Purge Thread 回收應使用并分配的undo頁,在 InnoDB 1.1 之前,該操作在Master Thread 中,1.1 之后,獨立到單獨的執行緒中,提高CPU的利用率以及提升INnoDB的性能,InnoDB 1.2 開始,InnoDB 支持多個 Purge Thread,進一步加快了undo頁的回收,同時由于 Purge Thread 需要離散的讀取undo頁,這樣可以進一步利用磁盤隨機讀取性能,
2.3.1.4 Page Cleaner Thread
該執行緒是在InnoDB 1.2.x版本引入的,作用是將之前版本中臟頁的重繪操作都放入單獨的執行緒中完成,目的是減輕原 Master Thread 的作業以及對用戶查詢執行緒的阻塞,進一步提高InnoDB的性能,
2.3.2 記憶體
1. 緩沖池
InnoDB 存盤引擎是基于磁盤存盤的,并將其中的記錄按照頁的方式進行管理,因此可將其視為基于磁盤的資料庫系統,在資料庫系統中,由于 CPU 與 磁盤之間的鴻溝,通常使用緩沖池技術來提高資料庫的整體性能,
簡單來說,緩沖池就是一塊記憶體區域,通過記憶體來彌補磁盤速度較慢對資料庫性能的影響,
讀取操作,首先將從磁盤讀取到的頁存放到緩沖池中,下次讀取相同的頁時,首先判斷該頁是否在緩沖池中,若在,稱該頁在緩沖池中被命中,直接讀取緩沖池的該頁,否則,讀取磁盤,
修改操作,先修改緩沖池中的頁,然后以一定的頻率重繪到磁盤,而頁的重繪操作不是每次修改時觸發,而是通過 CheckPoint 的機制重繪回磁盤,
從 InnoDB 1.0.x版本開始,允許有多個緩沖池實體,每個頁根據哈希值平均分配到不同緩沖池實體中,這樣做的好處是減少資料庫內部的資源競爭,增加系統的并發處理能力,
2. LRU List、Free List和 Flush List
從上一節得知,緩沖池是一個很大的記憶體區域,其中存放各種型別的頁,那么InnoDB是怎么管理這么大的記憶體區域呢?
通常來說,資料庫中的緩沖池是通過 LRU 演算法管理的,即最頻繁最近使用的頁在 LRU 串列的前端,而最少使用的頁在 LRU 串列的尾端,當緩沖池中不能存放新讀取到的頁時,將釋放LRU串列尾端的頁,
InnoDB 對傳統的LRU演算法做了一些優化,在 LRU 串列中加入了 midpoint 位置,新讀取的頁,雖然是最近訪問的頁,但并不是直接放入到 LRU 串列的首部,而是放入到 LRU串列的midpoint位置,默認情況下是在 LRU串列長度的 5/8 處,這個演算法在InnoDB存盤引擎下稱為 midpoint insertion strategy,
在 InnoDB中,把midpoint 之后的串列稱為 old 串列,之前的稱為 new 串列,即最為活躍的熱點資料,
為什么不采用樸素的LRU演算法呢?
因為某些SQL 操作(比如索引或資料的掃描操作)需要訪問表中的許多頁,甚至是全部的頁,而這些頁僅在這次查詢操作中需要,并不是活躍資料,如果將其放入串列首部,那么可能將真正的熱點資料從 LRU 串列移除,而在下次讀取該頁時,InnoDB再次訪問磁盤,
LRU 串列用于管理已經讀取的頁,但資料庫剛剛啟動時,LRU串列是空的,這時,頁都在Free 串列中,當需要從緩沖池中分頁時,先從Free List 中查找是否有可用的空閑頁,若有,將該頁從 Free List中洗掉,放入 LRU 串列中,否則,根據LRU,淘汰LRU末尾的頁,將該記憶體空間分配給新的頁,
在 LRU 串列中的頁被修改后,稱為臟頁,即緩沖池中的頁和磁盤的頁資料產生了不一致,這時,資料庫會通過 Checkpoint機制將臟頁重繪回磁盤,而 Flush 串列中的頁即為臟頁串列,需要注意的是,臟頁既存在于 LRU 串列中,也存在于 Flush 串列,LRU 串列用來管理緩沖池中頁的可用性,Flush用來管理將頁重繪回磁盤,二者不影響,
3. 重做日志緩沖
InnoDB 的記憶體區域除了緩沖池,還有重做日志緩沖,InnoDB首先將重做日志先放入到這個緩沖區,然后按照一定的頻率將其重繪到磁盤上的重做日志檔案,默認大小為 8 MB.以下三種情況,會對重做日志進行重繪,
- Master Thread 每秒對重做日志緩沖重繪
- 每個事務提交時,對重做日志緩沖重繪
- 當重做日志緩沖池剩余空間小于 1/2 時
4. 額外的記憶體池
在 InnoDB 中,對記憶體的管理是通過一種稱為 記憶體堆 的方式進行的,在對一些資料結構本身的記憶體進行分配時,需要從額外的記憶體池中進行申請,當該區域的記憶體不足時,會從緩沖池中進行申請,因此,在申請了很大的InnoDB 緩沖池時,應考慮相應的增加這個值,
2.4 Checkpoint 技術
為了避免發生資料丟失的問題,當前事務資料庫普遍采用了 Write Ahead Log 策略,即當事務提交時,先寫重做日志,再修改頁,當由于宕機導致資料丟失時,通過重做日志完成資料的恢復,也是事務持久性的要求,
Checkpoint 技術目的是解決一下幾個問題:
- 縮短資料庫的恢復時間
- 緩沖池不夠用時,將臟頁重繪回磁盤
- 重做日志不可用時,重繪臟頁
當資料庫發生宕機時,資料庫不需要重做所有的日志,因為 checkpoint 之前的頁都已經重繪回磁盤,只需要對checkpoint之后的頁進行恢復,大大縮短了恢復時間,
此外,當緩沖池不夠用時,根據 LRU 演算法會移除最近最少使用的頁,若此頁是臟頁,那么需要強制執行 checkpoint,將臟頁刷回磁盤,
重做日志出現不可用是因為當前事務資料庫對重做日志的設計都是回圈使用的,這從成本及管理上是比較困難的,重做日志可以被重用的部分是這些日志已經不再需要,即當資料庫發生宕機時,不需要恢復這部分的日志,因此這部分可以被覆寫重用,若此時重做日志還需要使用,那么必須強制產生 checkpoint,將緩沖池中的頁重繪到當前重做日志的位置,
checkpoint的目的是將緩沖池中的臟頁刷回到磁盤,不同之處在于重繪多少到磁盤,每次從哪里讀取臟頁,什么時間觸發checkpoint,InnoDB 中有兩種 checkpoint:
- Sharp Checkpoint
- Fuzzy Checkpoint
Sharp Checkpoint 發生在資料庫關閉時將所有的臟頁重繪回磁盤,這是默認的作業方式,但如果資料庫運行時也使用 Sharp Checkpoint,那么資料庫的可用性會受到很大影響,因此,InnoDB內部使用 Fuzzy Checkpoint進行頁的重繪,即只重繪一部分臟頁,而不是重繪所有的臟頁回磁盤,
InnoDB發生 Fuzzy Checkpoint 的情況分為以下幾種:
- Master Thread Checkpoint
- FLUSH_LRU_LIST Checkpoint
- Async/Sync Flush Checkpoint
- Dirty Page too much Checkpoint
Master Thread差不多以每秒或每十秒的速度從緩沖池中的臟頁串列中重繪一定比例的頁回磁盤,這個程序是異步的,不阻塞用戶查詢線程,
FLUSH_LRU_LIST Checkpoint 是因為InnoDB存盤引擎需要保證 LRU 串列有差不多100個空閑頁可使用,InnoDB1.1.x 版本之前,需要檢查LRU串列是否有足夠的可用空間操作發生在用戶查詢執行緒中,會阻塞用戶查詢操作,如果空閑頁小于100,那么將LRU串列尾部的頁移除,如果這些頁中有臟頁,那么需要 Checkpoint,而這些頁來自 LRU串列,因此稱為 FLUSH_LRU_LIST Checkpoint;在 MySQL 5.6之后,也就是 InnoDB 1.2.x 版本后,這個檢查被放在了單獨的 Page Cleaner執行緒中進行,
Async/Sync Flush Checkpoint 指的是重做日志不可用的情況,而此時臟頁是從臟頁串列中選取的,若將已經寫入到重做日志的LSN記為 redo_lsn,將已經刷回磁盤最新頁的lsn記為 Checkpoint_lsn,則可定義 Checkpoint_age = redo_lsn - checkpoint_lsn,之后會詳細說明該部分,總之,Async/Sync Checkpoint 是為了保證重做日志的回圈使用的可用性,從 InnoDB 1.2.x 開始,該部分的重繪操作同樣放到了單獨的 Page Cleaner Thread 中,
Dirty Page too much,導致InnoDB 存盤引擎強制 Checkpoint,目的是為了保證緩沖池有足夠可用的頁,默認為 75%
2.5 Master Thread 作業方式
2.5.1 InnoDB 1.0.x版本之前的 Master Thread
Master Thread 有最高的執行緒優先級,內部有多個回圈(loop)組成:主回圈、后臺回圈、重繪回圈(flush loop)、暫停回圈(suspend loop),Master Thread會根據資料庫運行的狀態在多個回圈之前進行切換,
主回圈(loop)
主回圈中包含大多數的操作,其中有兩大部分的操作——每秒的操作和每十秒的操作,loop 回圈是通過 Thread sleep 來實作的,意味著時間不精確,在負載大的情況下,可能會有延遲,
每秒的操作包括:
- 重做日志緩沖重繪到磁盤(重做日志檔案),即使這個事務還沒有提交(總是)
- 合并插入緩沖(可能):前一秒內IO次數少于5次,IO壓力較小時發生
- 至多重繪100個InnoDB的緩沖池中的臟頁到磁盤(可能):當前緩沖池中的臟頁比例超過90%(默認值)發生
- 如果當前沒有用戶活動,則切換到后臺回圈(background loop 可能)
每十秒的操作包括:
- 重繪100個臟頁到磁盤(可能):當過去10秒內的IO次數小于200,IO壓力較小時發生
- 合并至多5個插入緩沖(總是)
- 將重做日志緩沖重繪到磁盤(總是)
- 執行 full purge 操作,洗掉無用的undo頁(總是)
- 重繪100個或10個臟頁到磁盤(總是):當緩沖池中臟頁比例超過70%,重繪100個臟頁到磁盤;小于70%,重繪10個臟頁到磁盤
后臺回圈(background loop)
若當前沒有用戶活動(資料庫空閑或關閉)時,切換到該回圈,后臺回圈會執行以下操作:
- 洗掉無用的undo頁(總是)
- 合并20個插入緩沖(總是)
- 跳回到主回圈(總是)
- 不斷重繪100個頁直到符合條件(可能,跳轉到flush loop中完成)
重繪回圈(flush loop)
若重繪回圈中沒有什么事情可做,則切換到 suspend loop中,將Master Thread 掛起,等待事件發生,若用戶啟用了InnoDB存盤引擎,但卻沒有使用任何InnoDB 存盤引擎的表,那么Master Thread總是處于掛起的狀態,
2.5.2 InnoDB 1.2.x版本之前的 Master Thread
從上一節發現,InnoDB對IO是有限制的,在緩沖池向磁盤重繪時都做了一定的硬編碼,在技術飛速發展的今天,當固態硬碟出現時,這種規定很大程度上限制了 InnoDB存盤引擎對磁盤IO的性能,尤其是寫入性能,
從上一節來看,無論何時,InnoDB最大知會重繪100個臟頁到磁盤,合并20個插入緩沖,如果是在寫密集的應用中,每秒可能會產生大于100個臟頁,如果是產生大于20個插入緩沖的情況,Master Thread 似憾訓忙不過來,即使磁盤可以在1秒內處理多余100個頁的寫入和20個插入緩沖的合并,但由于 hard coding,Master Thread 只能寫100個臟頁和20個合并緩沖,同時,當宕機發生要恢復時,由于很多資料還沒有重繪回磁盤,會導致恢復時間過長,尤其是 insert buffer.
因此,InnoDB plugin(1.0.x)開始提供了引數 InnoDB_io_capacity,用來表示磁盤IO的吞吐量,默認200,若用戶使用了SSD類的磁盤,存盤設備擁有更高的IO速度時,可將 InnoDB_io_capacity 調高,直到符合磁盤IO的吞吐量,
除此之外,InnoDB 1.0.x還對其他的引數進行了調整,用以提高資料庫系統的性能,
2.5.3 InnoDB 1.2.x版本的 Master Thread
對重繪臟頁的操作,從 Master Thread 執行緒分離一個單獨的Page Cleaner Thread,從而減輕 Master Thread 的作業,進一步提高系統的并發性,
2.6 InnoDB的關鍵特性
InnoDB的關鍵特性包括:
- 插入緩沖
- 兩次寫(double write)
- 自適應哈希索引(Adaptive Hash Index,AHI)
- 異步IO
- 重繪鄰接頁(Flush Neighbor Page)
2.6.1 插入緩沖
1. Insert buffer
InnoDB 緩沖池中有 insert buffer的資訊,但 insert buffer 和資料頁一樣,是物理頁的一個組成部分,
由于每張表不可能只有一個聚集索引,更多情況下,一張表有多個非聚集(且不唯一)的輔助索引,這種情況下,在進行插入操作時,資料頁的存放還是按照主鍵進行順序存放,但對于非聚集的索引葉子節點的插入不再是順序的,這時需要離散的訪問輔助索引頁,由于隨機讀取的存在導致了插入操作的性能下降,這是由于B+樹的特性決定了非聚集索引插入的離散性,
InnoDB存盤引擎開創性的設計了Insert Buffer,對于非聚集索引的插入或更新操作,不是每一次直接插入到索引頁中,而是先判斷插入的索引頁是否在緩沖池中,若在,則直接插入,若不在,則先放到一個insert buffer 物件中,好似欺騙,資料庫這個非聚集索引已經插入到葉子節點,而實際沒有,只是存放在另一個位置,然后以一定的頻率和情況進行insert buffer 和輔助索引頁子節點的merge操作,這時通常能將多個插入合并到一個操作中(因為在同一個索引頁中),這大大提高了對于非聚集索引插入的性能,
然而insert buffer 需要同時滿足兩個條件
- 索引必須是輔助索引
- 索引不是唯一的:因為在插入緩沖時,資料庫并不去查找索引頁來判斷插入記錄的唯一性,如果去查找的話,又會涉及到離散讀的情況,insert buffer失去意義
正如前面所說的,目前 insert buffer 存在一個問題:在寫密集的情況下,插入緩沖會占用過多的緩沖池記憶體,默認最大可以占用1/2 的緩沖池記憶體,該值可修改
2.Change buffer
InnoDB 從 1.0.x 版本開始引入了 change buffer,可以將其視為 insert buffer 的升級,從這個版本開始,InnoDB存盤引擎可以對DML操作-insert、delete、update都進行緩沖,他們分別是 insert buffer、delete buffer、purge buffer,
同樣,change buffer 適用的物件是非唯一的輔助索引,
對一條記錄的update操作可能分為兩個步驟:
- 將記錄標記為洗掉
- 真正將記錄洗掉
delete buffer 對應 update 操作的第一個程序,將記錄標記為洗掉,purge buffer 對應update 的第二個程序,即真正的洗掉,同時 InnoDB提供了引數用來開啟各種buffer 的選項,changes 標識insert 和 delete,all標識所有,none標識都不啟用,該引數默認為all
3. insert buffer 的內部實作
insert buffer的資料結構是一棵B+樹,之前的版本每個表都有一個B+樹,現有版本中,全域只有一個 Insert buffer B+樹,負責所有表的輔助索引進行 insert buffer,而這棵樹存放在共享表空間中,默認也就是ibdata1,因此,試圖通過獨立表空間ibd檔案恢復表中資料時,往往會導致 check table失敗,因為表的輔助索引的資料可能還在 insert buffer 中,也就是共享表空間里,所以通過ibd檔案進行恢復后,還需要進行 repair table 操作來重建表上所有的輔助索引,
insert buffer是一棵B+樹,因此其也由葉子節點和非葉子節點組成,非葉子節點存放的是 search key(鍵值),其構造如圖所示:
![]()
search key 一共有9個位元組,其中space標識待插入記錄所在的表空間id,在 InnoDB存盤引擎中,每個表都有一個 space id,通過space id 可知是哪張表,space占用四個位元組,marker一個位元組,用來兼容老版本的insert buffer,offset 標識頁所在的偏移量,占用四個位元組,
當一個輔助索引要插入到頁(space,offset)時,如果這個頁不再緩沖池中,那么InnoDB會先根據上述負責構造一個 search key,接下來查詢 insert buffer這棵B+ 樹,然后再將這條記錄插入到樹中的葉子節點,
對于插入到insert buffer B+樹葉子節點的記錄,并不是將待插入的記錄直接插入,而是根據如下的規則行程構造:
![]()
space、marker、offset和之前非葉子節點的含義相同,一共占用九個位元組,metadata占用4個位元組,用來排序每個記錄進入insert buffer的順序,通過這個順序回放才能得到記錄的正確值,
從 insert buffer葉子節點的第五列開始,就是實際插入記錄的各個欄位了,因此,insert buffer B+樹的葉子節點記錄需要額外13位元組的開銷,
因為啟用 insert buffer索引后,輔助索引頁(space,page no)中的記錄可能被插入到insert buffer B+樹中,所以為了保證每次merge insert buffer 頁必須成功,還需要有一個特殊的頁來標記每個輔助索引頁(space,page_no)的可用空間,這個頁的型別為 insert buffer bitmap,
4. Merge Insert Buffer
insert buffer 中的記錄何時合并到真正的輔助索引頁呢?概括的說,Merge insert buffer操作可能發生在以下幾種情況下:
- 輔助索引頁被讀取到緩沖池時
- insert buffer bitmap頁追蹤到該輔助索引頁無可用空間時
- Master Thread
第一種情況是當輔助索引頁被讀取到緩沖池時,例如這時正在執行 select 操作,需要檢查insert buffer bitmap頁,然后確認該輔助索引頁是否有記錄在insert bufferB+ 樹中,若有,則將insert buffer B+樹中該頁的記錄插入到該輔助索引頁中,可以看到對該頁多次的記錄操作通過一次操作合并到了原有的輔助索引頁中,性能得到很大提高
insert buffer bitmap頁用來追蹤每個輔助索引頁的可用空間,并至少有1/32頁的空間,如果小于 1/32,則會強制執行一個合并操作,即強制讀取輔助索引頁,將insert buffer B+樹中該頁的記錄及待插入的記錄插入到輔助索引頁中,
最后是Master Thread中每秒或每十秒會進行一次 merge 操作,不同的是每次merge操作的頁的數量不同
那么,InnoDB又是根據怎樣的演算法來得知需要合并的輔助索引頁呢?在insert buffer B+樹中,輔助索引頁根據(space,offset)都已排好序,故可以根據(space,offset)的排序順序進行頁的選擇,然而,對于insert buffer 頁的選擇,InnoDB并非采用該方式,它隨機的選擇 insert buffer B+ 樹中的一個頁,讀取該頁中的space及之后所需要數量的頁,該演算法在復雜情況下,有更好的公平性,同時,若merge時,要進行merge的表已經被洗掉,此時可以直接丟棄已經被 insert/change buffer 的資料記錄,
2.6.2 兩次寫
兩次寫可提高InnoDB存盤引擎資料頁的可靠性,當資料庫發生宕機時,可能InnoDB正在寫入某個頁到表中,而這個頁只寫了一部分,之后就發生了宕機,這種情況被稱為部分寫失效(partial page write),有經驗的DBA也許會想,如果發生寫失效,可以通過重做日志進行恢復,但需要知道的是,重做日志中記錄的是對頁的物理操作,如偏移量800寫’qqq‘記錄,如果這個頁本身發生了損壞,再對其進行重做是沒有意義的,
這就是說,在應用重做日志前,用戶需要一個頁的副本,當寫入失效發生時,先通過頁的副本來還原該頁,再進行重做,這就是 double write,
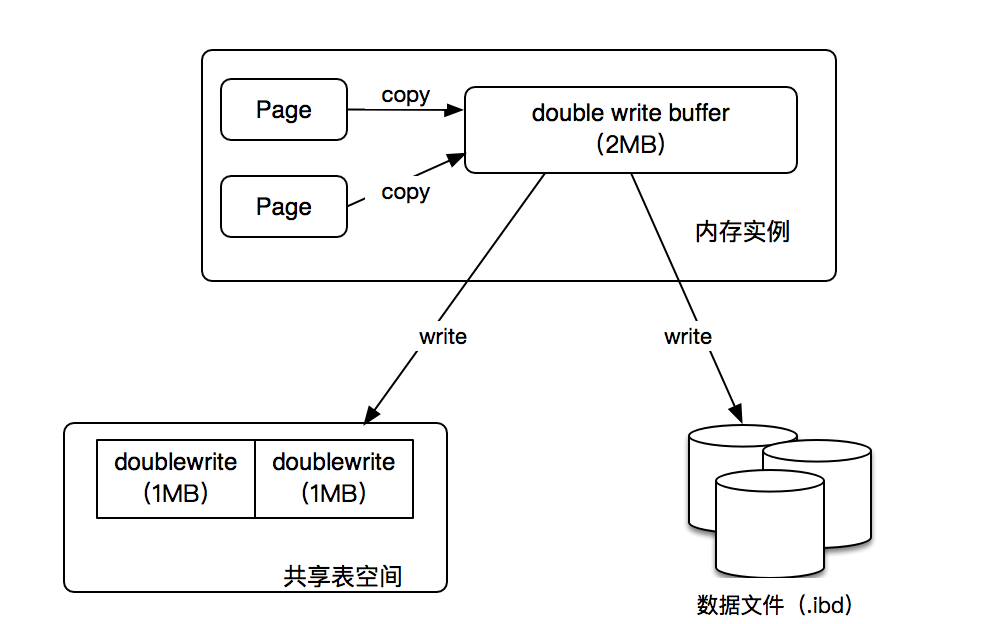
以上是doublewrite的架構圖,doublewrite有兩部分構成,一部分是記憶體中的 doublewrite buffer,大小為 2MB,另一部分是物理磁盤上共享表空間中連續的128個頁,即兩個區(extent),大小同樣為 2MB,在對緩沖池的臟頁進行重繪時,并不直接寫磁盤,而是會通過 memcpy 函式將臟頁先復制到記憶體的 doublewrite buffer,然后通過 doublewrite buffer 再分兩次,每次 1MB 順序寫入共享表空間的物理磁盤上,然后馬上呼叫fsync函式,同步磁盤,避免緩沖寫帶來的問題,
在以上的程序中,因為doublewrite是連續的,因此這個程序是順序寫,開銷不是很大,完成doublewrite頁的寫入后,再將doublewrite buffer 中的頁寫入各個表空間檔案中,此時的寫是離散的,
2.6.3 自適應哈希索引
InnoDB 會監控對表上各個索引頁的查詢,如果觀察到建立哈希索引可以帶來速度提升,則建立哈希索引,稱之為自適應哈希索引,
AHI有一個要求,對這個頁的連續訪問模式必須是一樣的,例如對(a,b)這樣的聯合索引,其訪問模式可以是以下情況:
- where a= xxx
- where a= xxx and b = xxx
訪問模式一樣意味著查詢條件一樣,若交替進行以上兩種查詢,那么InnoDB不會建立哈希索引,
AHI還有兩個要求:
- 以該模式訪問了100次
- 頁通過該模式訪問了N次,其中N= 頁中記錄 /16
2.6.4 異步IO
為了提高磁盤性能,當前資料庫系統都采用異步IO的方式來處理磁盤操作,InnoDB也是如此,
用戶可以在發出一個IO請求后,立即發出另一個,當全部IO請求發送完畢后,等待所有IO操作的完成,這就是AIO,
AIO的另一個優勢就是可以進行IO merge,也就是將多個IO合并為1個IO,這樣可以提高IOPS的性能,
2.6.5 重繪鄰接頁
InnoDB還提供了Flush Neighbor Page(重繪鄰接頁)的特性,其作業原理為:當重繪一個臟頁時,InnoDB存盤引擎會檢測該頁所在區(extent)的所有頁,如果是臟頁,那么一起進行重繪,這樣做的好處,是通過AIO可以將多個IO合并為一個IO操作,故該作業機制在傳統機械磁盤下有明顯優勢,但考慮到以下問題:
- 是不是可能將不怎么臟的頁進行了寫入,而該頁之后又很快變成臟頁,
- 固態硬碟有較高的IOPS,是否需要這個特性
InnoDB 從 1.2.x開始提供了引數用來控制是否啟用該特性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/56211.html
標籤:MySQL