SQL語言
使用Navicate圖形化界面工具
官網地址:http://www.navicat.com.cn/download/direct-download?product=navicat_mysql_cs_x64.exe&location=1&support=Y
網盤地址:
https://pan.baidu.com/s/1_z9TbieMX9Kemnyj5WWrBQ 提取碼:4dgw
字符集
1. 字符集的由來:
- 計算機只能識別二進制代碼無論是計算機程式還是資料,最終都會轉換成二進制,計算機才能認識,
- 為了計算機不只能做科學計算,也能處理文字資訊,
人們想出了給每一個文字符號編碼以便于計算識別處理的辦法,這就是計算機字符集的由來,
2. ASSCII
一套文字符號及其編碼,比較規則 的集合, 20世紀60年代初,美國標準化組織ANSI發布了第一個字符集,ASCII
后來又進一步變成了國際標準ISO-646
- 各大字符集:
自ASCII后,為了處理不同的文字,各大計算機公司,各國,標準化政府,組織先后發明了幾百種字符集,
- ISO-8859
- GB2312-80
- GBK
- BIG5
2. unicode
- 為了統一字符編碼,國際標準化組織ISO的一些成員國于1984年發起制定了新的國際字符集標準,容納全世界各種語言,文字,和 符號,最后這個標準ISO-10646
- ISO-10646發布后,遭到了美國計算機公司的反對,
- 1988年,Xerox公司提議制定了新的以16位編碼人統一字符集,并聯合不Apple,IBM,SUN,Microsoft等公司成立了Unicode技術委員會,專門負責收集,整理,和編碼,于1991年推出了Unicode1.0
- 都是為了字符編碼統一問題,ISO和Unicode協會推出了連個不同人標準,這顯然是不利的,后來雙方開始談判,1991年10月達成協議,ISO將Unicode收編,起了個名BMP
3. UTF-16
- ISO-10646編碼空間足以容納從古自今使用過的文字和字符,但很多文字字符已經很少用了, 超過99%的在用文字字符都編入了BMP.因此,絕大部分情況下,
Unicode雙位元組方式都能滿足需求,而且比雙位元組編碼方式4位元組原始編碼來說,更節省記憶體和處理時間 ,這也是Unicode流行的原因,- 萬一使用了BMP以這后文字怎么辦? Unicode提出了UTF-16的解決辦法,
4. UTF-8
- 雖然UTF-16解決了上面問題,但當時的計算機和網路世界還是ASCII的天下,只能處理單位元組資料流,UTF-16離開了Unicode環境后,在傳輸和處理中,都存在問題,
- 于是又提出了UTF-8的解決文案,
- UTF-8按一定的規則,將一個ISO10646或Unicode轉換成1至4個位元組的編碼
- 其中ASCII轉成單位元組編碼,也就嚴格兼容了ASCII字符集,
- UTF-8的2,3,4位元組用以轉換ISO-10646標準的UCS-4原始碼,
5. 漢字的一些常見字符集
- GB2312
- GB13000
- GBK
- GB18030
什么是SQL
- SQL是Structured Quevy Language(結構化查詢語言)的縮寫,
- SQL是專為資料庫而建立的操作命令集,是一種功能齊全的資料庫語言,
- 在使用它時,只需要發出“做什么”的命令,“怎么做”是不用使用者考慮的,
sql功能分類
1. DDL:資料定義語言
用來定義資料庫物件:創建庫,表,列等,
2. DML:資料操作語言
用來操作資料庫表中的記錄
3. DQL:資料查詢語言
用來查詢資料
4. DCL:資料控制語言
用來定義訪問權限和安全級別
SQL資料型別
MySQL中定義資料欄位的型別對你資料庫的優化是非常重要的,
MySQL支持所有標準SQL數值資料型別,
MySQL支持多種型別,大致可以分為三類:
1. 數值型別
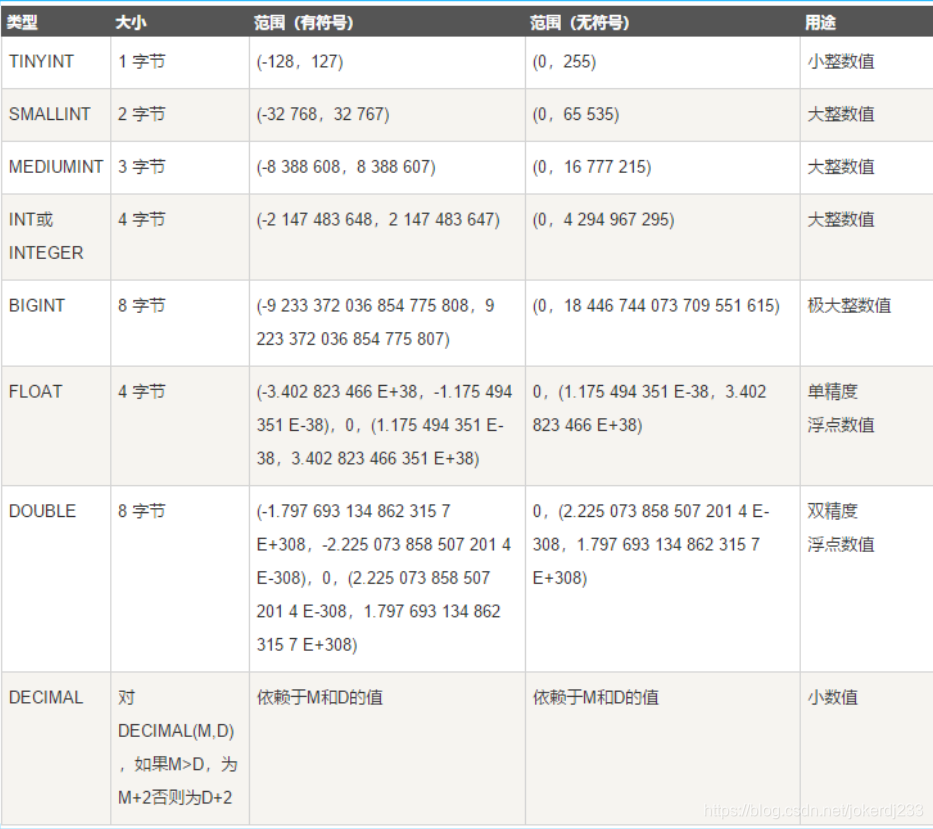
2. 字串型別
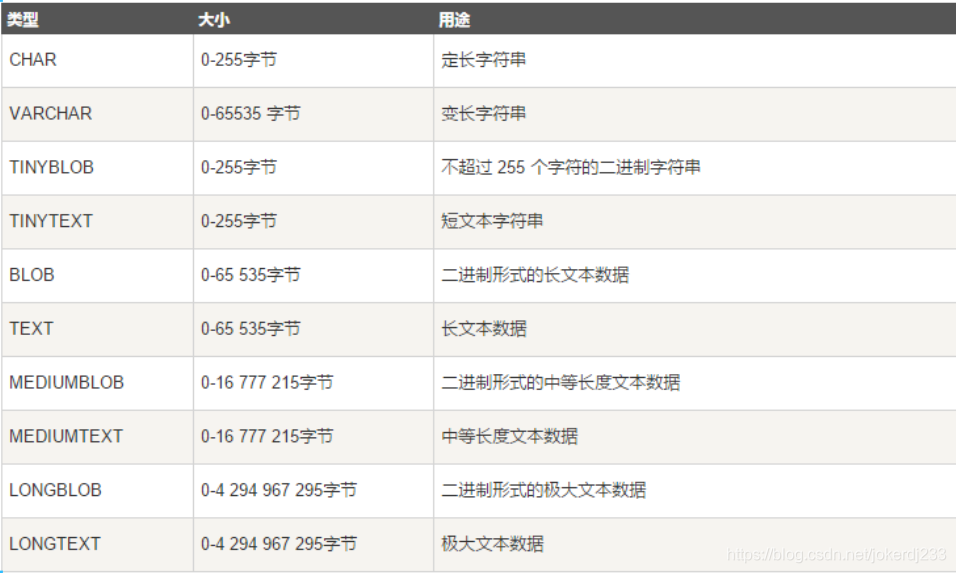
3. 日期和時間型別
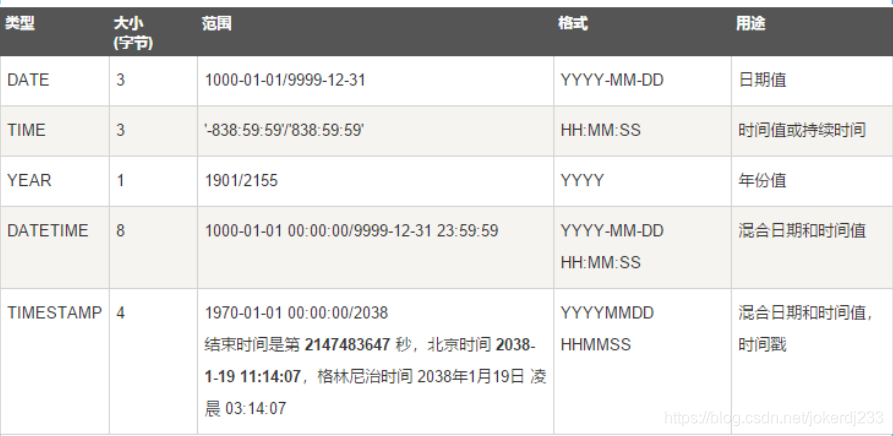
常用資料型別
- double:浮點型,例如double(5,2)表示最多5位,其中必須有2位小數,即最大值為999.99;
- char:固定長度字串型別; char(10) 'abc '
- varchar:可變長度字串型別;varchar(10) 'abc'
- text:字串型別;
- blob:二進制型別;
- date:日期型別,格式為:yyyy-MM-dd;
- time:時間型別,格式為:hh:mm:ss
- datetime:日期時間型別 yyyy-MM-dd hh:mm:ss
在mysql中,字串型別和日期型別都要用單引號括起來,'Joker' '2020-01-01'
SQL陳述句
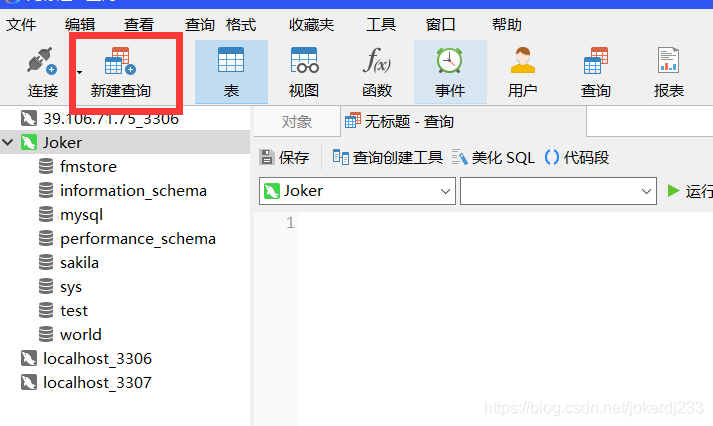
使用Navicate圖形化界面工具
連接資料庫:
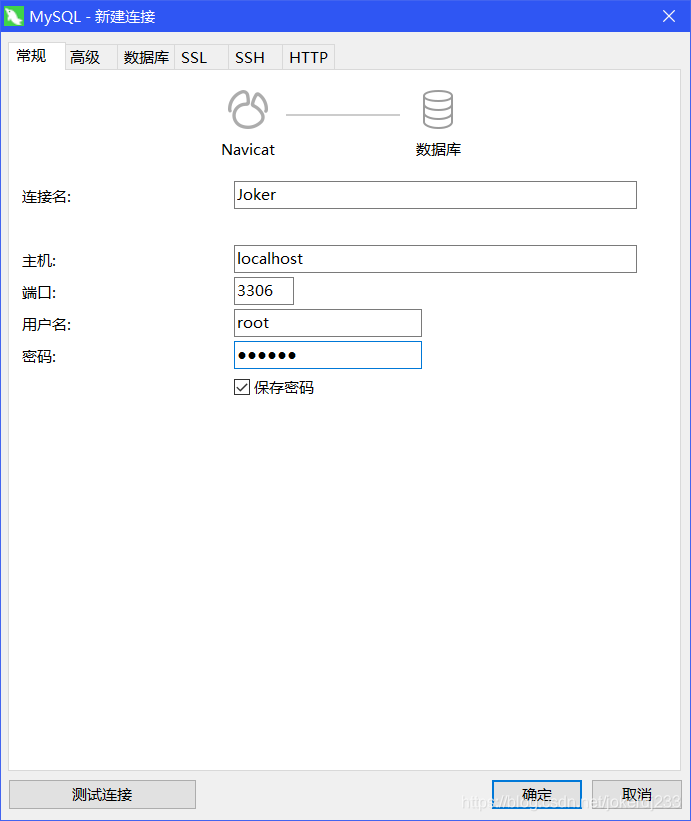
DDL:資料定義語言
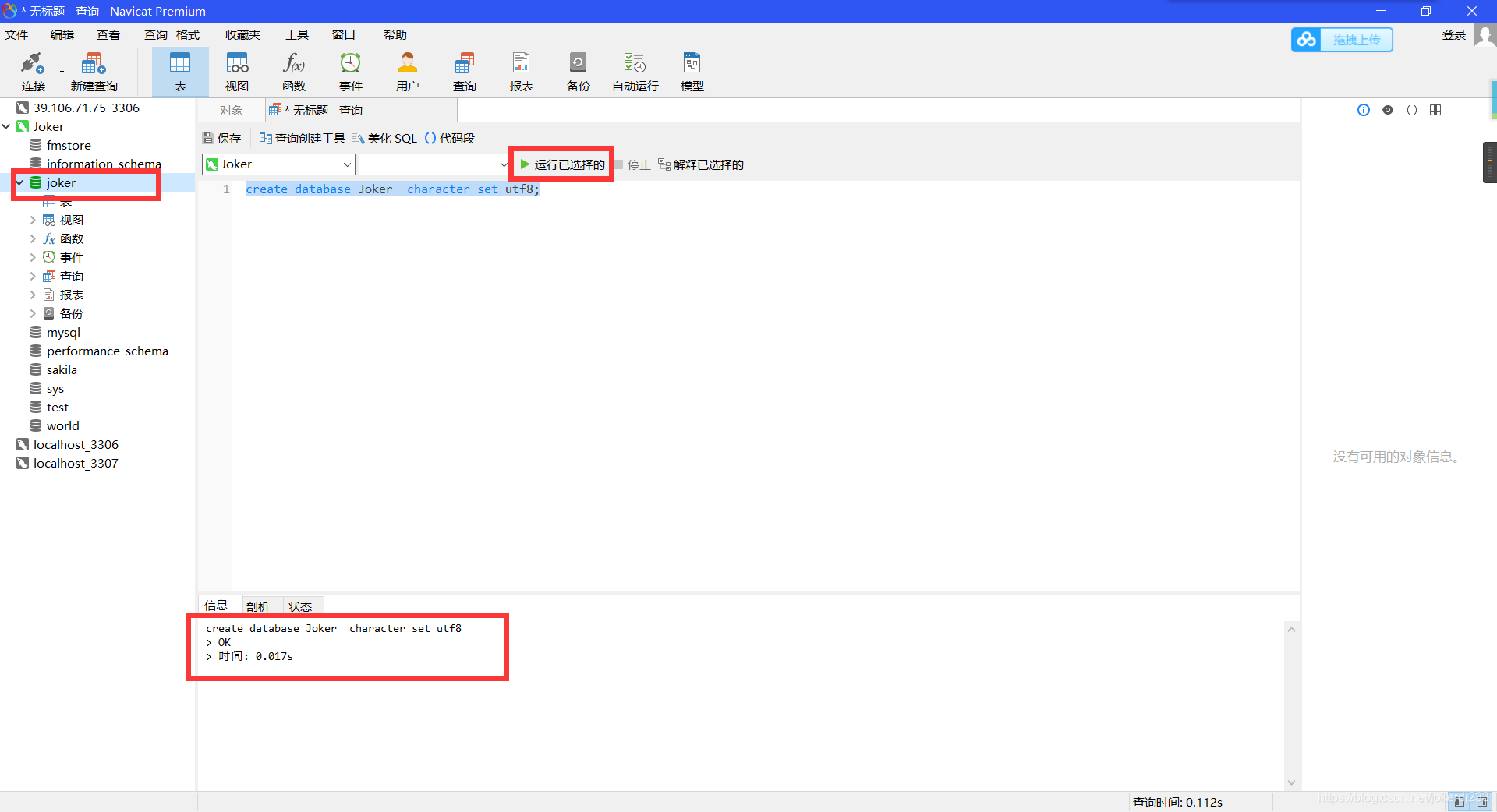
1. 創建資料庫
create database 資料庫名 character set utf8;
2. 創建學生表
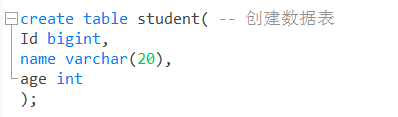
use joker;
create table student( -- 創建資料表
Id bigint,
name varchar(20),
age int
);


3. 添加一列

ALTER TABLE 表名 ADD 列名 資料型別;
4. 查看表的欄位資訊
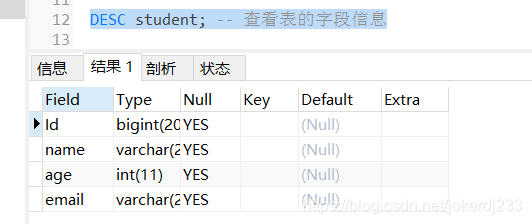
DESC 表名;
5. 修改一個表的欄位型別

ALTER TABLE 表名 MODIFY 欄位名 資料型別;
6. 洗掉一列

ALTER TABLE 表名 DROP 欄位名;
7. 修改表名
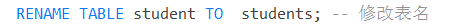
RENAME TABLE 原始表名 TO 要修改的表名;
8. 查看表的創建細節

SHOW CREATE TABLE 表名;
9. 修改表的列名

ALTER TABLE 表名 CHANGE 原始列名 新列名 資料型別;
10. 洗掉表

DROP TABLE 表名;
1. 修改表的字符集為gbk

ALTER TABLE 表名 CHARACTER SET 字符集名稱;
DML:資料操作語言
1. 查詢表中的所有資料

SELECT * FROM 表名;
2. 插入操作

INSERT INTO 表名(列名1,列名2 ...)VALUE (列值1,列值2...);
注意事項:
- 列名與列值的型別、個數、順序要一一對應,
- 值不要超出列定義的長度,
- 插入的日期和字符一樣,都使用引號括起來,
批量插入

INSERT INTO 表名(列名1,列名2 ...)VALUES (列值1,列值2...),(列值1,列值2...);
3. 更新操作
UPDATE 表名 SET 列名1=列值1,列名2=列值2 ... WHERE 列名=值
- 把所有學生的年齡改為20

update students set age=20
- 把姓名為小鍵的年齡改為18

update students set age=18 where name='小鍵';
- 把小吳的年齡在原來基礎上加1歲

update students set age=age+1 where name='小吳';
- 修改資料庫密碼
mysql8之前:
use mysql;
update mysql.user set authentication_string=password('123456') where user='root' and Host = 'localhost';
flush privileges;重繪MySQL的系統權限相關表
mysql8:
ALTER USER 'root'@'localhost' IDENTIFIED BY '新密碼';
使用mysqladmin修改密碼:
mysqladmin -u root -p password 123456
4. 洗掉操作
- 洗掉表
DELETE FROM 表名 【WHERE 列名=值】
TRUNCATE TABLE 表名;
DELETED 與TRUNCATE的區別
- DELETE 洗掉表中的資料,表結構還在;洗掉后的資料可以找回
- TRUNCATE 洗掉是把表直接DROP掉,然后再創建一個同樣的新表,
洗掉的資料不能找回,執行速度比DELETE快,
DQL:資料查詢語言
1. 查詢所有列
SELECT * FROM 表名;
2. 結果集
資料庫執行DQL陳述句不會對資料進行改變,而是讓資料庫發送結果集給客戶端,
結果集:
- 通過查詢陳述句查詢出來的資料以表的形式展示我們稱這個表為虛擬結果集,存放在記憶體中,
- 查詢回傳的結果集是一張虛擬表,
3. 查詢指定列的資料
SELECT 列名1,串列2... FROM 表名;
4. 條件查詢
條件查詢就是在查詢時給出WHERE子句,在WHERE子句中可以使用一些運算子及關鍵字:
- =(等于)、!=(不等于)、<>(不等于)、<(小于)、<=(小于等于)、>(大于)、>=(大于等于);
- BETWEEN…AND;值在什么范圍
- IN(set);固定的范圍值
- IS NULL;(為空) IS NOT NULL(不為空)
- AND;與
- OR;或
- NOT; 非
- 查詢性別為男,并且年齡為20的學生記錄
SELECT * FROM students WHERE gender='男' AND age=20;
- 查詢學號為1001 或者 名為zs的記錄
SELECT * FROM students WHERE id ='1001' OR name='zs';
- 查詢學號為1001,1002,1003的記錄
SELECT * FROM students WHERE id='1001' OR id='1002' OR 1001='1003';
SELECT * FROM students WHERE id IN('1001','1002','1003');
- 查詢年齡為null的記錄
SELECT * FROM students WHERE age IS NULL;
- 查詢年齡在18到20之間的學生記錄
SELECT * FROM students WHERE age>=18 AND age<=20;
SELECT * FROM students WHERE age BETWEEN 18 AND 20;
- 查詢性別非男的學生記錄
SELECT * FROM students WHERE gender !='男';
- 查詢姓名不為null的學生記錄
SELECT * FROM students WHERE name IS NOT NULL;
5. 模糊查詢
根據指定的關鍵進行查詢, 使用LIKE關鍵字后跟通配符
通配符:_ :任意一個字符
%:任意0~n個字符
- 查詢姓名由5個字母構成的學生記錄
SELECT * FROM students WHERE name LIKE '_____';
-- 模糊查詢必須使用LIKE關鍵字,其中 “_”匹配任意一個字母,5個“_”表示5個任意字母,
- 查詢姓名由5個字母構成,并且第5個字母為“s”的學生記錄
SELECT * FROM students WHERE name LIKE '____s';
- 查詢姓名以“m”開頭的學生記錄
SELECT * FROM students WHERE name LIKE 'm%';
-- 其中“%”匹配0~n個任何字母,
- 查詢姓名中第2個字母為“u”的學生記錄
SELECT * FROM students WHERE name LIKE '_u%';
- 查詢姓名中包含“s”字母的學生記錄
SELECT * FROM stu WHERE name LIKE '%s%';
6. 欄位控制查詢
- 去除重復記錄
SELECT DISTINCT name FROM students;
- 把查詢欄位的結果進行運算,必須都要是資料型
SELECT *,欄位1+欄位2 FROM 表名;
列有很多記錄的值為NULL,
因為任何東西與NULL相加結果還是NULL,所以結算結果可能會出現NULL,
下面使用了把NULL轉換成數值0的函式IFNULL:
SELECT *,age+IFNULL(score,0) FROM students;
- 對查詢結果起別名
在上面查詢中出現列名為sx+IFNULL(yw,0),這很不美觀,現在我們給這一列給出一個別名,為total:
SELECT *, yw+IFNULL(sx,0) AS total FROM score;
SELECT *, yw+IFNULL(sx,0) total FROM score; -- 省略 AS
7. 排序
創建表:
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`gender` varchar(1) DEFAULT NULL,
`hire_date` date DEFAULT NULL,
`salary` decimal(10,0) DEFAULT NULL,
`performance` double(255,0) DEFAULT NULL,
`manage` double(255,0) DEFAULT NULL,
`department` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `employee` VALUES (1001, '張三', '男', '1991-7-25', 2000, 200, 500, '營銷部');
INSERT INTO `employee` VALUES (1002, '李四', '男', '2017-7-5', 4000, 500, NULL, '營銷部');
INSERT INTO `employee` VALUES (1003, '王五', '女', '2018-5-1', 6000, 100, 5000, '研發部');
INSERT INTO `employee` VALUES (1004, '趙六', '男', '1991-6-1', 1000, 3000, 4000, '財務部');
INSERT INTO `employee` VALUES (1005, '孫七', '女', '2018-3-23', 8000, 1000, NULL, '研發部');
INSERT INTO `employee` VALUES (1006, '周八', '男', '2010-9-8', 5000, 500, 1000, '人事部');
INSERT INTO `employee` VALUES (1007, '吳九', '女', '2017-7-5', 8000, 601, NULL, '研發部');
INSERT INTO `employee` VALUES (1008, '鄭十', '女', '2014-4-6', 4000, 1801, NULL, '人事部');
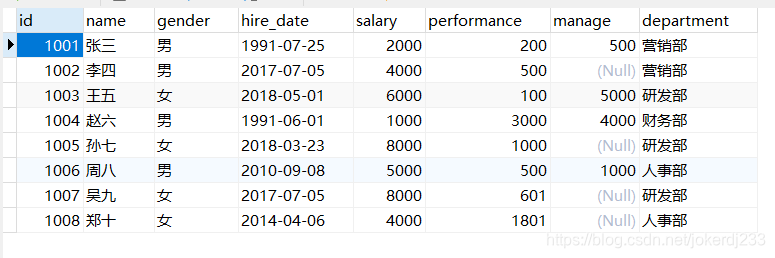
對查詢的結果進行排序
使用關鍵字ORDER BY
排序型別
- 升序ASC 從小到大 默認
- 降序DESC 從大到小
- 對所有員工的薪水進行排序
SELECT *FROM employee ORDER BY salary ASC;
- 查詢所有雇員,按月薪降序排序,如果月薪相同時,按編號升序排序
SELECT * FROM employee ORDER BY salary DESC, id ASC;
8.聚合函式
對查詢的結果進行統計計算
常用聚合函式:
- COUNT():統計指定列不為NULL的記錄行數;
- MAX():計算指定列的最大值,如果指定列是字串型別,那么使用字串排序運算;
- MIN():計算指定列的最小值,如果指定列是字串型別,那么使用字串排序運算;
- SUM():計算指定列的數值和,如果指定列型別不是數值型別,那么計算結果為0;
- AVG():計算指定列的平均值,如果指定列型別不是數值型別,那么計算結果為0;
1. COUNT
- 查詢employee表中記錄數:
SELECT COUNT(*) AS total_record FROM employee;
- 查詢員工表中有績效的人數
SELECT COUNT(performance) FROM employee;
- 查詢員工表中月薪大于2500的人數:
SELECT COUNT(*) FROM employee WHERE salary > 2500;
- 統計月薪與績效之和大于5000元的人數:
SELECT COUNT(*) FROM employee WHERE salary+IFNULL(performance,0) > 5000;
- 查詢有績效的人數,和有管理費的人數:
SELECT COUNT(performance), COUNT(manage) FROM employee;
2. SUM和AVG
- 查詢所有雇員月薪和:
SELECT SUM(salary) FROM employee;
- 查詢所有雇員月薪和,以及所有雇員績效和
SELECT SUM(salary), SUM(performance) FROM employee;
- 查詢所有雇員月薪+績效和:
SELECT SUM(salary+IFNULL(performance,0)) FROM employee;
- 統計所有員工平均工資:
SELECT AVG(salary) FROM employee;
3. MAX和MIN
查詢最高工資和最低工資:
SELECT MAX(salary), MIN(salary) FROM employee;
9. 分組查詢
什么是分組查詢
將查詢結果按照1個或多個欄位進行分組,欄位值相同的為一組
分組使用
SELECT gender from employee GROUP BY gender;
根據gender欄位來分組,gender欄位的全部值只有兩個('男'和'女'),所以分為了兩組 當group by單獨使用時,只顯示出每組的第一條記錄 所以group by單獨使用時的實際意義不大
- group by + group_concat()
group_concat(欄位名)可以作為一個輸出欄位來使用
表示分組之后,根據分組結果,使用group_concat()來放置每一組的某欄位的值的集合
SELECT gender,GROUP_CONCAT(name) from employee GROUP BY gender;
- group by + 聚合函式
通過group_concat()的啟發,我們既然可以統計出每個分組的某欄位的值的集合,那么我們也可以通過集合函式來對這個"值的集合"做一些操作
查詢每個部門的部門名稱和每個部門的工資和
SELECT department,SUM(salary) FROM employee GROUP BY department;
查詢每個部門的部門名稱以及每個部門的人數
SELECT department,COUNT(*) FROM employee GROUP BY department;
查詢每個部門的部門名稱以及每個部門工資大于1500的人數
SELECT department,COUNT(salary) FROM employee WHERE salary > 1500 GROUP BY department;
- group by + having
用來分組查詢后指定一些條件來輸出查詢結果
having作用和where一樣,但having只能用于group by
查詢工資總和大于9000的部門名稱以及工資和
SELECT department,GROUP_CONCAT(salary) FROM employee GROUP BY department;
SELECT department,SUM(salary) FROM employee GROUP BY department;
總和大于9000
SELECT department,SUM(salary) FROM employee GROUP BY department HAVING SUM(salary)>9000;
- having與where的區別
having是在分組后對資料進行過濾.
where是在分組前對資料進行過濾
having后面可以使用分組函式(統計函式)
where后面不可以使用分組函式
WHERE是對分組前記錄的條件,如果某行記錄沒有滿足WHERE子句的條件,那么這行記錄不會參加分組;而HAVING是對分組后資料的約束,
查詢工資大于2000的,工資總和大于6000的部門名稱以及工資和
- 查詢工資大于2000的
SELECT * FROM employee WHERE salary >2000;
- 各部門工資
SELECT department, GROUP_CONCAT(salary) FROM employee WHERE salary >2000 GROUP BY department;
- 各部門工資總和
SELECT department, SUM(salary) FROM employee WHERE salary >2000 GROUP BY department;
- 各部門工資總和大于6000
SELECT department, SUM(salary) FROM employee WHERE salary >2000 GROUP BY department HAVING SUM(salary)>6000;
- 各部門工資總和大于6000降序排列
SELECT department, SUM(salary) FROM employee
WHERE salary >2000
GROUP BY department
HAVING SUM(salary)>6000
ORDER BY SUM(salary) DESC;
10. LIMIT
從哪一行開始查,總共要查幾行
Limit 引數1,引數2
- 引數1:從哪一行開始查
- 引數2:一共要查幾行
角標是從0開始
格式:
select * from 表名 limit 0,3;
11. 書寫順序
- 書寫順序
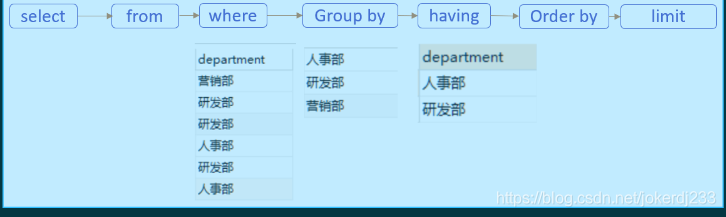
- 執行順序

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/58174.html
標籤:MySQL
上一篇:從零開始學資料庫mysql--MySql資料庫介紹與安裝
下一篇:MySQL密碼加密與解密