資料庫的完整性
什么是資料的完整性
保證用戶輸入的資料保存到資料庫中是正確的,
如何添加資料完整性
在創建表時給表中添加約束
完整性分類
- 物體完整性
- 域完整性
- 參照完整性
物體完整性
- 什么是物體完整性
表中的一行(一條記錄)代表一個物體(entity)
- 物體完整性的作用
標識每一行資料不重復,行級約束
- 約束型別
- 主鍵約束(primary key)
- 唯一約束(unique)
- 自動增長列(auto_increment)
- 主鍵約束
特點:
- 每個表中要有一個主鍵
- 資料唯一,且不能為null
添加主鍵約束的方式
CREATE TABLE 表名(欄位名1 資料型別 primary key,欄位2 資料型別);
CREATE TABLE 表名(欄位1 資料型別, 欄位2 資料型別,primary key(要設定主鍵的欄位));
CREATE TABLE 表名(欄位1 資料型別, 欄位2 資料型別,primary key(主鍵1,主鍵2));
聯合主鍵: 兩個欄位資料同時相同時,才違反聯合主鍵約束,
1.先創建表
2.再去修改表,添加主鍵
ALTER TABLE student ADD CONSTRAINT PRIMARY KEY (id);
- 唯一約束:
特點:
- 指定列的資料不能重復
- 可以為空值
CREATE TABLE 表名(欄位名1 資料型別 欄位2 資料型別 UNIQUE);
- 自動增長列
特點:
- 指定列的資料自動增長
- 即使資料洗掉,還是從洗掉的序號繼續往下
CREATE TABLE 表名(欄位名1 資料型別 PRIMARY KEY AUTO_INCREMENT ,欄位2 資料型別 UNIQUE);
域完整性
限制此單元格的資料正確,不對照此列的其它單元格比較
域代表當前單元格
域完整性約束:
-
資料型別 :
數值型別、日期型別、字串型別 -
非空約束(not null)
CREATE TABLE 表名(欄位名1 資料型別 PRIMARY KEY AUTO_INCREMENT ,欄位2 資料型別 UNIQUE not null); -
默認值約束(default)
CREATE TABLE 表名(欄位名1 資料型別 PRIMARY KEY AUTO_INCREMENT ,欄位2 資料型別 UNIQUE not null default '男');
? 插入的時候,values當中的值直接給default
參照完整性
-
什么是參照完整性
是指表與表之間的一種對應關系
通常情況下可以通過設定兩表之間的主鍵、外鍵關系,或者撰寫兩表的觸發器來實作,
有對應參照完整性的兩張表格,在對他們進行資料插入、更新、洗掉的程序中,系統都會將被修改表格與另一張對應表格進行對照,從而阻止一些不正確的資料的操作,
資料庫的主鍵和外鍵型別一定要一致;
兩個表必須得要是InnoDB型別
設定參照完整性后 ,外鍵當中的內值,必須得是主鍵當中的內容 -
一個表設定當中的欄位設定為主鍵,設定主鍵的為主表
CREATE TABLE student(sid int PRIMARY key,name varchar(50) not null,sex varchar(10) default '男'); -
創建表時,設定外鍵,設定外鍵的為子表
CREATE TABLE score( sid INT, score DOUBLE, CONSTRAINT fk_stu_score_sid FOREIGN KEY(sid) REFERENCES student(id));?
表之間關系
- 一對一
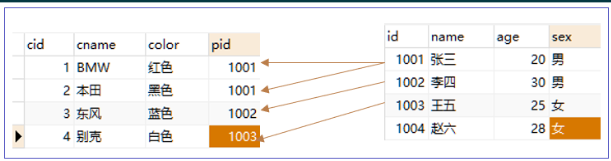
一夫一妻 - 一對多關系
一個人可以擁有多輛汽車,要求查詢某個人擁有的所有車輛,
創建Person表

創建Car表
- 多對多關系
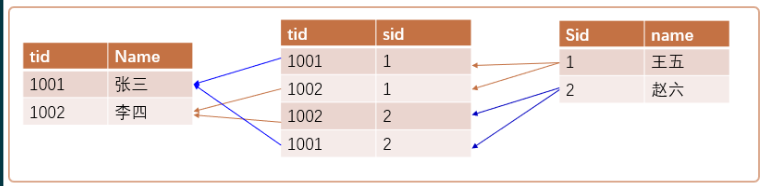
- 學生選課,一個學生可以選修多門課程,每門課程可供多個學生選擇,
- 一個學生可以有多個老師,而一個老師也可以有多個學生
創建老師表

創建學生表

創建學生與老師關系表

關系圖
添加外鍵


多表操作
合并結果集
- 什么是合并結果集
合并結果集就是把兩個select陳述句的查詢結果合并到一起
- 合并結果集的兩種方式
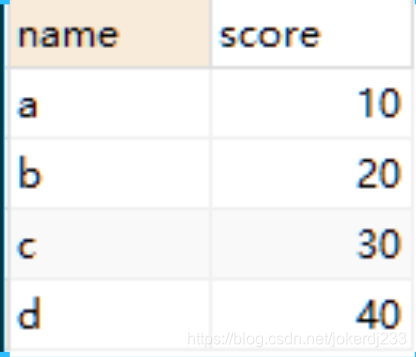
- UNION
合并時去除重復記錄- UNION ALL
合并時不去除重復記錄
格式:
UNION:
SELECT * FROM 表1 UNION SELECT * FROM 表2;
SELECT * FROM 表1 UNION ALL SELECT * FROM 表2;
創建表:

UNION:

UNION ALL:

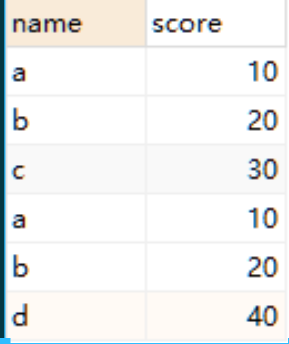
注意事項:被合并的兩個結果:列數、列型別必須相同,
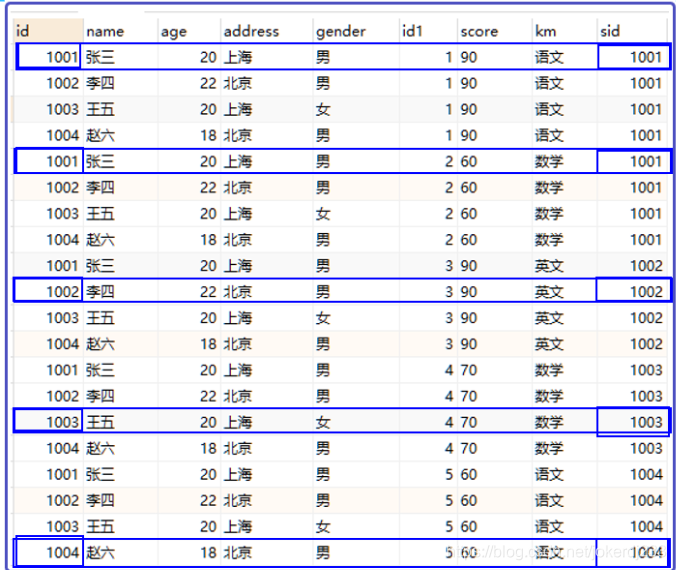
多表聯查:
- 什么是連接查詢
也可以叫跨表查詢,需要關聯多個表進行查詢
- 什么是笛卡爾集
假設集合A={a,b},集合B={0,1,2},
則兩個集合的笛卡爾積為{(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)},
可以擴展到多個集合的情況
同時查詢兩個表,出現的就是笛卡爾集結果
- 查詢時給表起別名

- 多表聯查,如何保證資料正確
逐行判斷,相等的留下,不相等的全不要
連接查詢
1. 內連接
內連接
圖示:
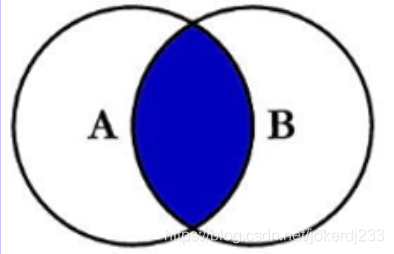
作用:查詢兩張表的共有部分
陳述句:
Select <select_list> from tableA A Inner join tableB B on A.Key = B.Key
示例:
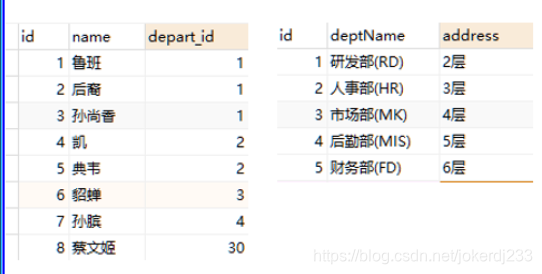
SELECT * from employee e INNER JOIN department d on e.depart_id = d.id;
多表連接:
建表:
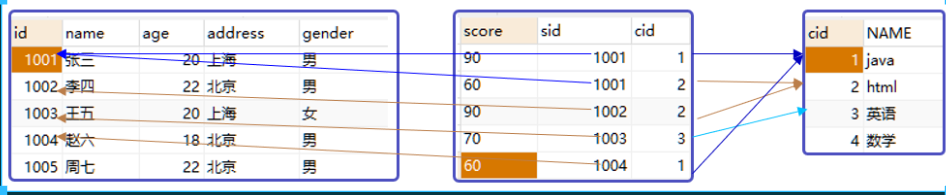
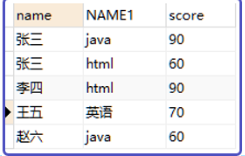
使用99連接法:

使用行內查詢

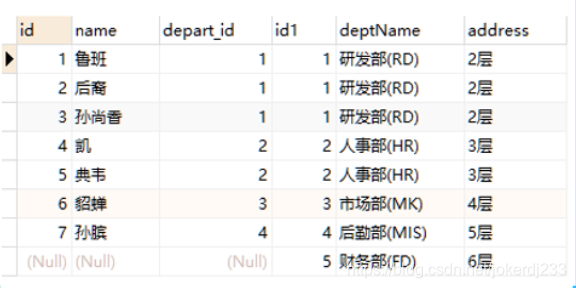
2. 左連接
圖示
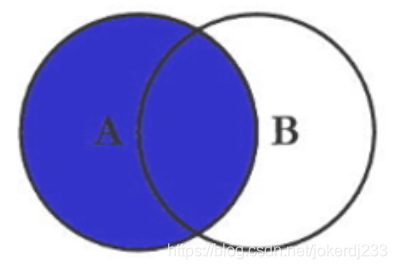
作用: 把左邊表的內容全部查出,右邊表只查出滿足條件的記錄
陳述句:
Select <select_list> from tableA A Left Join tableB B on A.Key = B.Key
示例
SELECT * from employee e LEFT JOIN department d on e.depart_id = d.id;
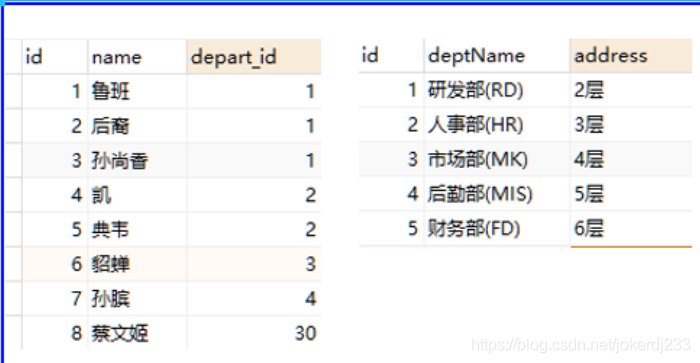
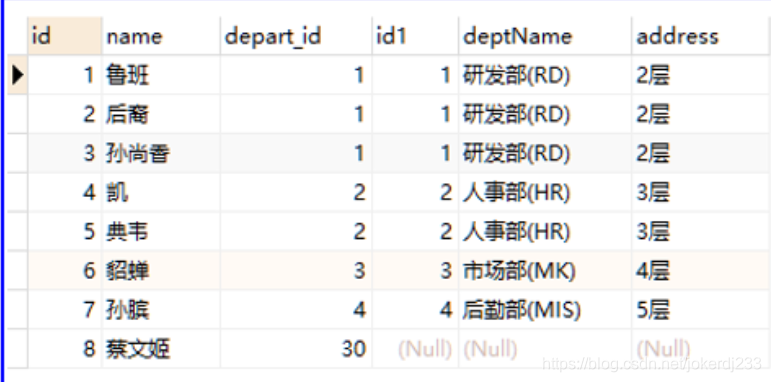
3. 右連接
圖示:
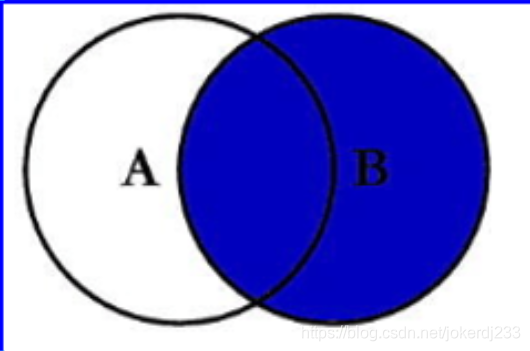
作用
把右邊表的內容全部查出,左邊表只查出滿足條件的記錄
陳述句
Select <select_list> from tableA A Right Join tableB B on A.Key = B.Key
示例
SELECT * from employee e RIGHT JOIN department d on e.depart_id = d.id;
子查詢
什么是子查詢
一個select陳述句中包含另一個完整的select陳述句, 或兩個以上SELECT,那么就是子查詢陳述句了,
子查詢出現的位置
- where后,把select查詢出的結果當作另一個select的條件值
- from后,把查詢出的結果當作一個新表;
示例表

使用
查詢與項羽同一個部門人員工
- 先查出項羽所在的部門編號

- 再根據編號查同一部門的員工

把第1條查出來的結果當第2天陳述句的條件
查詢工資高于程咬金的員工
- 查出程咬金的工資

- 再去根據查出的結果查詢出大于該值的記錄員工名稱

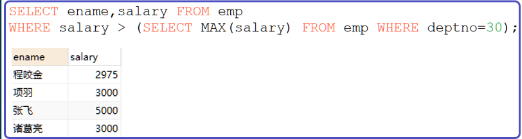
工資高于30號部門所有人的員工資訊
- 先查出30號部門工資最高的那個人

- 再到整個表中查詢大于30號部門工資最高的那個人
查詢作業和工資與妲己完全相同的員工資訊
- 先查出妲已的作業和工資

- 根據查詢結果當作條件再去查詢作業和工資相同的員工
由于是兩個條件,使用 IN進行判斷

有2個以上直接下屬的員工資訊
-
對所有的上級編號進行分組

-
找出大于2個的,大于2個說明有兩個下屬

-
把上條的結果當作員工編號時行查詢

查詢員工編號為7788的員工名稱、員工工資、部門名稱、部門地址

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/58190.html
標籤:MySQL
上一篇:MySQL 索引、視圖
下一篇:MySQL 存盤程序