Zookeeper 的集群角色
集群中的 server 分為三種角色:leader, follower, observer,
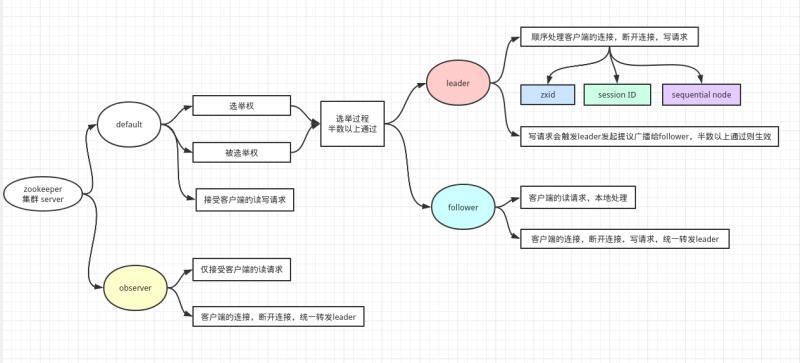
- 其中
observer是配置zoo.cfg明確定義的,角色leader在一個zookeeper集群中有且只能有一個,是通過內部的選舉機制臨時產生的, leader是集群中最重要的角色,負責回應集群的所有對Zookeeper資料狀態變更的請求,它會將每個狀態更新請求進行順序管理,以便保證整個集群內部訊息處理的 FIFO,遵循了順序一致性(Sequential Consistency),leader內部維護 session ,來自客戶端的連接和斷開連接,都會被統一follower或observer轉發給leader處理,leader內部維護單調遞增的 Zxid(ZooKeeper Transaction Id),針對客戶端連接,斷開連接,節點的寫操作都會分配一個全域唯一的Zxid,同時這些操作是原子性的,并且是嚴格順序性的,遵循ZAB原子廣播一致性協議完成事務(transaction)操作,如果客戶端的所有寫操作,都會被follower統一轉發給leader處理,
follower具有選舉權,負責提供給客戶端讀寫服務,需要回應leader的提議observer沒有選舉權,主要提供給客戶端讀服務,不提供寫服務,也不需要回應leader的提議,也不需要日志檔案,因為沒有寫服務,沒有持久化的需要,
Server狀態
LOOKING,競選狀態,FOLLOWING,隨從狀態,同步leader狀態,參與投票決策提案,OBSERVING,觀察狀態,同步leader狀態,不參與投票決策提案,LEADING,領導者狀態,發起正常訊息的提案,
Zookeeper 的存盤
zookeeper中的znode資料都是在記憶體中優先維護和提供讀服務,當事務被提交以及最終提交都會持久化到磁盤的日志檔案中,
Zookeeper 的內部網路拓撲
Zookeeper 在內部網路中如何實作兩兩連接的?
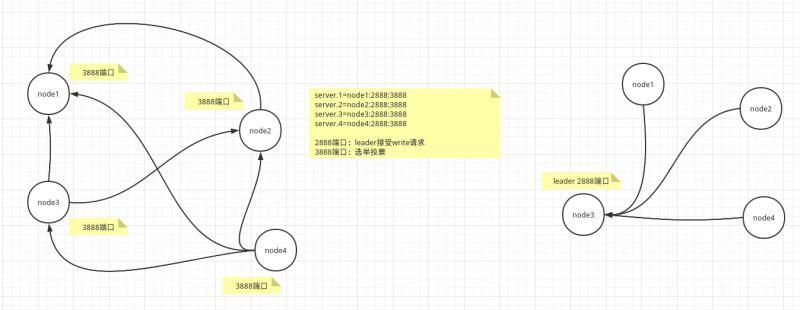
這里暫且使用 10.0.2.30,10.0.2.31,10.0.2.32,10.0.2.33 替代 node1,node2,node3,node4,并依次啟動 zookeeper,
zoo.cfg組態檔
server.1=10.0.2.30:2888:3888
server.2=10.0.2.31:2888:3888
server.3=10.0.2.32:2888:3888
server.4=10.0.2.33:2888:3888
依次使用 netstat 查看網路連接情況
- node1
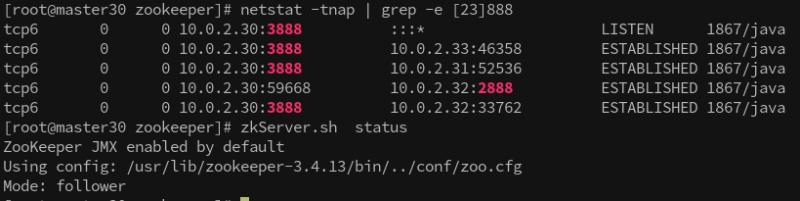
可以看出來 node1作為服務節點,由 node2,node3,node4 通過 3888埠建立連接進來,
node1 作為客戶端連接 node3 (目前node3是leader) 的2888埠,
- node2
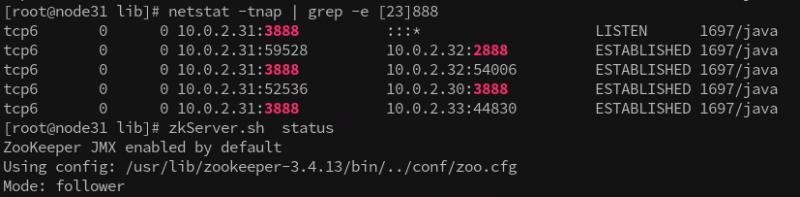
可以看出來 node2作為服務節點,由 node3,node4 通過 3888埠建立連接進來,
但是 node2 作為客戶端連接node1的3888埠,
node2 作為客戶端連接 node3 (目前node3是leader) 的2888埠,
- node3
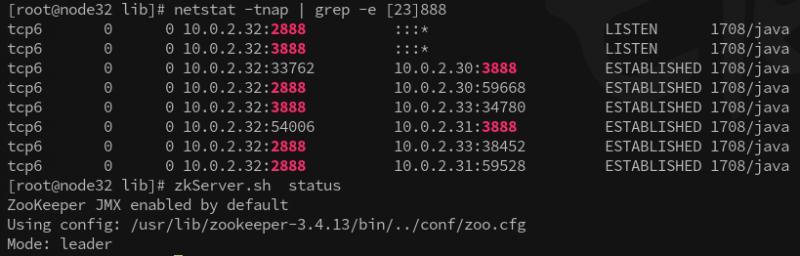
可以看出來 node3作為服務節點,由 node4 通過 3888埠建立連接進來,
但是 node3 作為客戶端連接node1,node2 的3888埠,
node3 作為leader節點,由 node1,node2 ,node4 通過 3888埠建立連接進來,
至于為什么 node3能當選 leader 呢?可以在下面的 選舉程序中 得到進一步詳細的闡述,
- node4
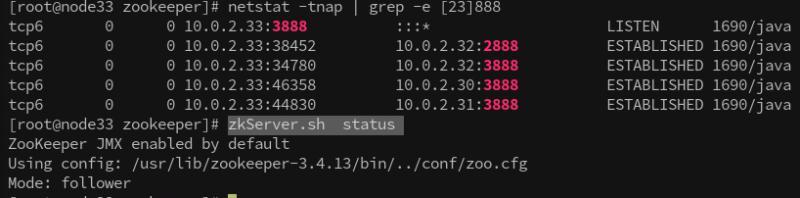
可以看出來 node4 作為客戶端連接node1,node2 ,node3 的3888埠,
node4 作為客戶端連接 node3 (目前node3是leader) 的2888埠,
- 結論
Zookeeper 在內部網路中如圖所示,依據zoo.cfg的配置后續的server都逐個連接前面的server的3888埠,這樣就形成了兩兩連接的拓撲,同時也不冗余,
而當leader當選時,會開放2888埠,其他follower連接其2888埠,
ZAB(原子廣播,Zookeeper Atomic Broadcast)
https://zookeeper.apache.org/doc/current/zookeeperInternals.html
ZAB(Zookeeper Atomic Broadcast)原子廣播是 Paxos分布式一致性協議演算法(http://zh.wikipedia.org/zh-cn/Paxos) 的一個簡化版本,
首先有以下概念,我們需要了解:
- 資料包(
Packet):通過 FIFO Channel 發送的位元組陣列, - 提案(
Proposal):協議的單位,通過與ZooKeeper中的法定server交換資料包來達成協議,大多數提案都包含訊息,但是NEW_LEADER Proposal提案是不包含訊息, - 訊息(
Message):要自動廣播到所有ZooKeeper服務器的位元組陣列,訊息被包含在一個提案(Proposal)中,并且只有在提案(Proposal)被通過后訊息才會最終交付delivered(提交到事務日志和更新記憶體的統一視圖), - 法定人員 (
Quorum):有 Zookeeper集群中非observer角色的所有服務器節點組成,具有投票通過提案(Proposal)的權力,
在 Zookeeper 中提供以下的保證資料的嚴格順序:
- 傳遞可靠性:如果一個訊息被一個server最終交付
delivered,那么這個訊息最終也被其他所有的server最終交付delivered,這里指最終一致性, - 順序全域性:如果一個訊息a先于b被一個server最終交付
delivered,那么訊息a也是先于b被其他所有的server最終交付delivered, - 順序傳遞性:如果訊息a先于b被發送到server,訊息b先于c被發送到server,那么訊息a也是先于c被server接收的,
如上所述,ZooKeeper保證訊息的總順序,也保證建議的總順序,
ZooKeeper使用ZooKeeper transaction id (zxid) ,這是一個全域的唯一的ID,提出提案(Proposal)時,所有提案都將附上zxid,進而保證全域的順序性,
-
leader將提案(Proposal)將發送到所有ZooKeeper服務器, -
在法定人員(
Quorum)收到后,會確認(acknowledge)回復這個提案(Proposal)給leader,
其中確認acknowledge提案(Proposal)表示服務器已將提案(Proposal)持久化到日志中,
稍微注意一下:法定人員(Quorum)收到提案(Proposal),只存在確認(acknowledge),或者因為網路等原因超時回應,不存在反對(reject),
-
只要一但滿足半數以上(大于所有法定人員的一半)確認
acknowledge后,leader就會進入正式提交(Commit), -
如果提案(
Proposal)中包含一條訊息,則在提交時將最終交付delivered該訊息,
ZooKeeper訊息傳遞包括兩個階段:
- leader選舉(
Leader activation):在此階段,leader被選舉出來,集群開始變為對外可用狀態,并準備開始提出提案(Proposal), - 活動訊息傳遞(
Active messaging):在此階段,leader開始接受訊息(Message),并發起提案(Proposal),協調和決策以提交(Commit)提案(Proposal),
leader選舉
leader產生的條件:
- 具有最新的 Zxid,如果 存在多個server都有最新的Zxid,在投票程序中選取建立網路連接中 myid最大的,
leader和其連接的follower的個數必須滿足半數以上(大于所有法定人員的一半),

當集群中任意具有選舉權的server發現leader掛了:
- 該 server 會觸發
NEW_LEADER Proposal提案,給自己投票,并通過 ZAB 廣播給所有連接的 server, - 接受到
NEW_LEADER Proposal提案的server,如果有被選舉權,則會觸發它的投票行為:- 先比較zxid,最新的勝出,如果zxid相同,再比較myid,最大的勝出,
- 最后將勝出的內容,通過 ZAB 廣播給所有連接的 server,
- 最終滿足
leader條件的server,將被選出,同時follower也被廣播獲得Proposal的提交,
以上中的 網路拓撲 為什么 node3能當選 leader 呢?
- node1 啟動時,給自己投票,因為其他server尚沒啟動,因為 node1 依然在
LOOKING競選狀態, - node2 啟動完,給自己投票,同時與 node1 交換了Zxid和myid,node2 勝出,但因為沒有達到半數以上法定人員,所以node1,node2 依然處于
LOOKING競選狀態, - node3 啟動完,給自己投票,同時與 node1 ,node2 交換了Zxid和myid,node3 勝出,也達到半數以上法定人員(3 > 4/2),因此 node3 被選舉為
leader, - node4 啟動完,給自己投票,同時與 node1 ,node2 ,node3交換了Zxid和myid,node3的Zxid最新,因此 node4 追隨 node3,
活動訊息傳遞
訊息的傳遞一般指寫請求,
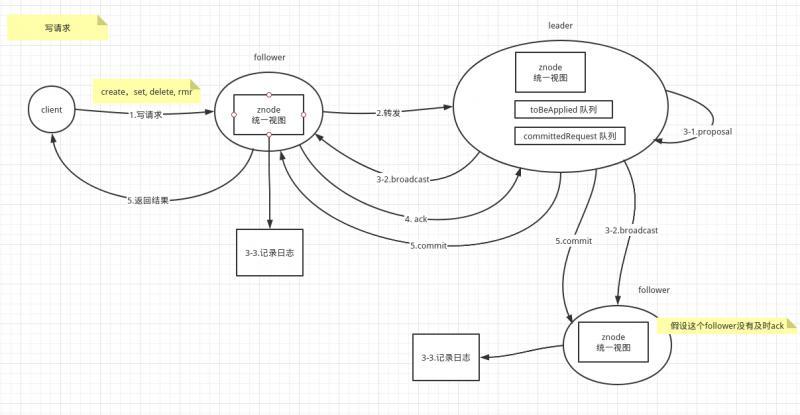
- 當
follower接收到 客戶端的 寫請求后,會轉發給leader順序處理, leader收到寫請求,會檢查資料問題,如無問題,創建一個新的提案proposal加入toBeAppliedFIFO 佇列,內容是寫請求的訊息,并附上全域的ZXid,leader每次toBeAppliedFIFO 佇列頭部取到一個提案proposal,通過 ZAB 廣播給所有的follower,處于 pending 等待回復,follower收到提案proposal后,記錄提案proposal持久化到磁盤的日志檔案中,然后確認(acknowledge)回復這個提案(Proposal)給leader,leader處于 pending 等待回復,一旦收到follower加上自己的確認(acknowledge)超過半數法定人員(Quorum),就會觸發Commit階段,發送commit請求給所有的follower,發送info請求所有的observer,
同時,leader將提案proposal放入 committedRequest 佇列,并從toBeAppliedFIFO 佇列移出該 提案proposal,follower收到Commit后,會更新自己的記憶體資料,統一資料視圖,observer收到info后,會更新自己的記憶體資料,統一資料視圖,
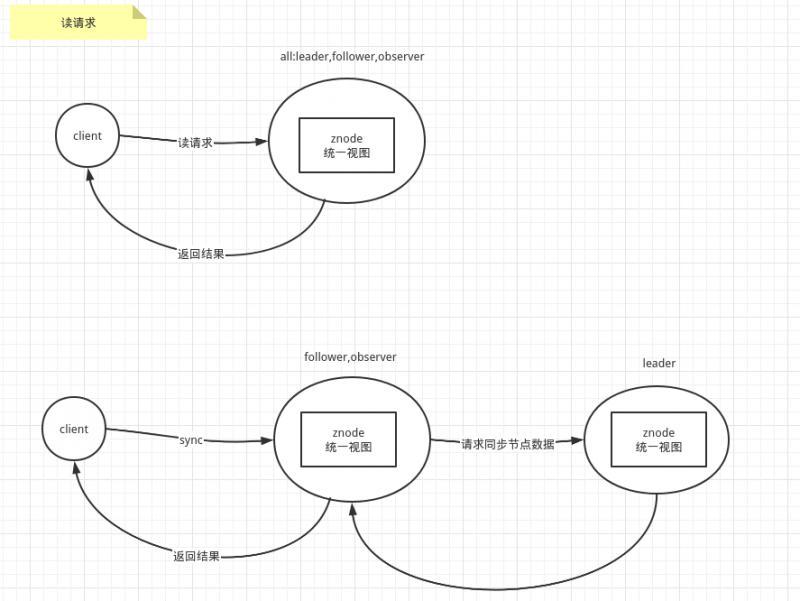
針對客戶端的讀請求,則不需要轉發給leader處理,
當然如果是客戶端的sync命令,則會觸發客戶端連接的follower或observer向leader請求同步資料狀態,
@SvenAugustus(https://www.flysium.xyz/)
更多請關注微信公眾號【編程不離宗】,專注于分享服務器開發與編程相關的技術干貨:

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/6031.html
標籤:大數據
上一篇:Zookeeper 資料結構詳解
下一篇:pandas用法總結