? 
? 在《什么的是用戶畫像》一文中,我們已經知道用戶畫像對于企業的巨大意義,當然也有著非常大實時難度,那么在用戶畫像的系統架構中都有哪些難度和重點要考慮的問題呢?
挑戰
大資料
隨著互聯網的崛起和智能手機的興起,以及物聯網帶來的各種可穿戴設備,我們能獲取的每一個用戶的資料量是非常巨大的,而用戶量本身更是巨大的,我們面臨的是TB級,PB級的資料,所以我們必須要一套可以支撐大資料量的高可用性,高擴展性的系統架構來支撐用戶畫像分析的實作,毫無疑問,大資料時代的到來讓這一切都成為可能,近年來,以Hadoop為代表的大資料技術如雨后春筍般迅速發展,每隔一段時間都會有一項新的技術誕生,不斷驅動的業務向前,這讓我們對于用戶畫像的簡單統計,復雜分析,機器學習都成為可能,所以整體用戶畫像體系必須建立在大資料架構之上,

?
實時性
在Hadoop崛起初期,大部分的計算都是通過批處理完成的,也就是T+1的處理模式,要等一天才能知道前一天的結果,但是在用戶畫像領域,我們越來越需要實時性的考慮,我們需要在第一時間就得到各種維度的結果,在實時計算的初期只有Storm一家獨大,而Storm對于時間視窗,水印,觸發器都沒有很好的支持,而且保證資料一致性時將付出非常大的性能代價,但Kafka和Flink等實時流式計算框架的出現改變了這一切,資料的一致性,事件時間視窗,水印,觸發器都成為很容易的實作,而實時的OLAP框架Druid更是讓互動式實時查詢成為可能,這這些高性能的實時框架成為支撐我們建立實時用戶畫像的最有力支持,
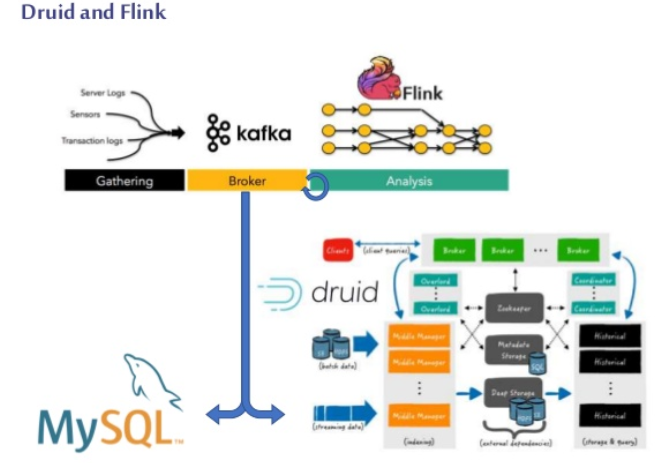
資料倉庫
資料倉庫的概念由來已久,在我們得到海量的資料以后,如何將資料變成我們想要的樣子,這都需要ETL,也就是對資料進行抽取(extract)、轉換(transform)、加載(load)的程序,將資料轉換成想要的樣子儲存在目標端,毫無疑問,Hive是作為離線數倉的不二選擇,而hive使用的新引擎tez也有著非常好的查詢性能,而最近新版本的Flink也支持了hive性能非常不錯,但是在實時用戶畫像架構中,Hive是作為一個按天的歸檔倉庫的存在,作為歷史資料形成的最終存盤所在,也提供了歷史資料查詢的能力,而Druid作為性能良好的實時數倉,將共同提供資料倉庫的查詢與分析支撐,Druid與Flink配合共同提供實時的處理結果,實時計算不再是只作為實時資料接入的部分,而真正的挑起大梁,
所以,兩者的區別僅在于資料的處理程序,實時流式處理是對一個個流的反復處理,形成一個又一個流表,而數倉的其他概念基本一致,
數倉的基本概念如下:
DB 是現有的資料來源(也稱各個系統的元資料),可以為mysql、SQLserver、檔案日志等,為資料倉庫提供資料來源的一般存在于現有的業務系統之中,
ETL的是 Extract-Transform-Load 的縮寫,用來描述將資料從來源遷移到目標的幾個程序:
- Extract,資料抽取,也就是把資料從資料源讀出來,
- Transform,資料轉換,把原始資料轉換成期望的格式和維度,如果用在資料倉庫的場景下,Transform也包含資料清洗,清洗掉噪音資料,
- Load 資料加載,把處理后的資料加載到目標處,比如資料倉庫,
ODS(Operational Data Store) 操作性資料,是作為資料庫到資料倉庫的一種過渡,ODS的資料結構一般與資料來源保持一致,便于減少ETL的作業復雜性,而且ODS的資料周期一般比較短,ODS的資料最終流入DW
DW (Data Warehouse)資料倉庫,是資料的歸宿,這里保持這所有的從ODS到來的資料,并長期保存,而且這些資料不會被修改,
DM(Data Mart) 資料集市,為了特定的應用目的或應用范圍,而從資料倉庫中獨立出來的一部分資料,也可稱為部門資料或主題資料,面向應用,
當然最終提供的服務不僅僅是可視化的展示,還有實時資料的提供,最終形成用戶畫像的實時服務,形成產品化,
在整個資料的處理程序中我們還需要自動化的調度任務,免去我們重復的作業,實作系統的自動化運行,Airflow就是一款非常不錯的調度工具,相比于老牌的Azkaban 和 Oozie,基于Python的作業流DAG,確保它可以很容易地進行維護,版本化和測驗,
至此我們所面臨的問題都有了非常好的解決方案,下面我們設計出我們系統的整體架構,并分析我們需要掌握的技術與所需要的做的主要作業,
#系統架構
? 依據上面的分析與我們要實作的功能,我們將依賴Hive和Druid建立我們的資料倉庫,使用Kafka進行資料的接入,使用Flink作為我們的流處理引擎,對于標簽的元資料管理我們還是依賴Mysql作為把標簽的管理,并使用Airflow作為我們的調度任務框架,并最終將結果輸出到Mysql和Hbase中,對于標簽的前端管理,可視化等功能依賴Springboot+Vue.js搭建的前后端分離系統進行展示,而Hive和Druid的可視化查詢功能,我們也就使用強大的Superset整合進我們的系統中,最終系統的架構圖設計如下:
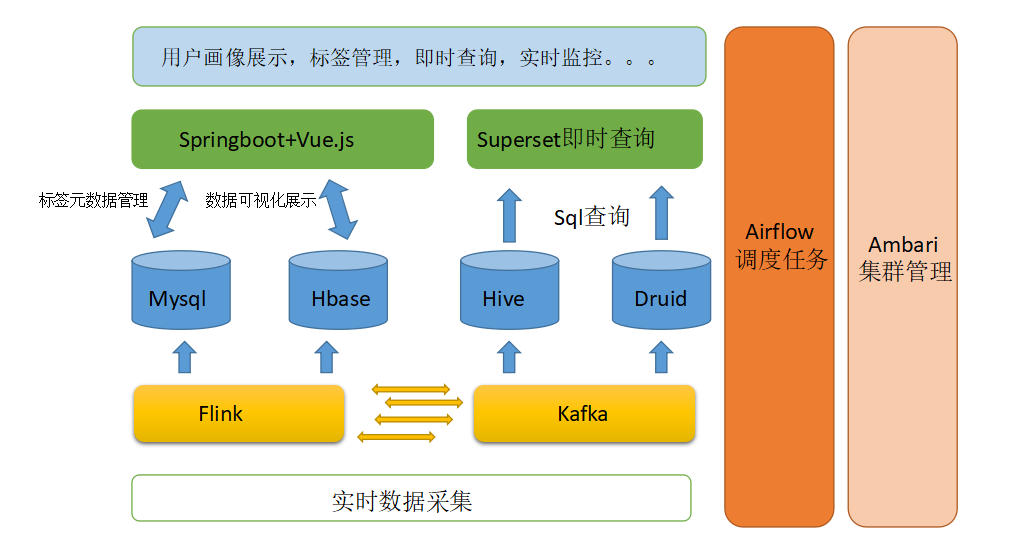
相對于傳統的技術架構,實時技術架構將極大的依賴于Flink的實時計算能力,當然大部分的聚合運算我們還是可以通過Sql搞定,但是復雜的機器學習運算需要依賴編碼實作,而標簽的存盤細節還是放在Mysql中,Hive與Druid共同建立起資料倉庫,相對于原來的技術架構,只是將計算引擎由Spark換成了Flink,當然可以選擇Spark的structured streaming同樣可以完成我們的需求,兩者的取舍還是依照具體情況來做分析,
傳統架構如下:
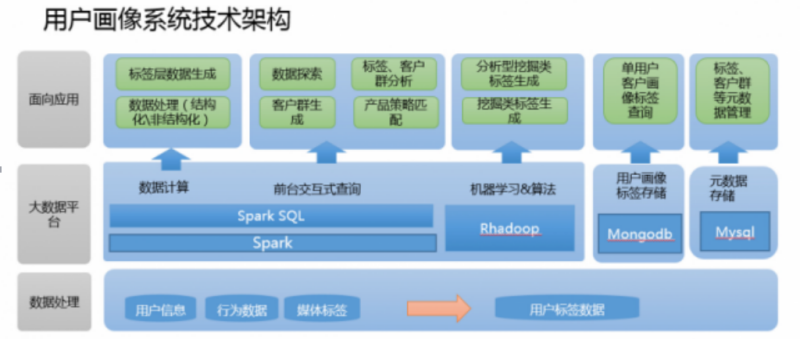
這樣我們就形成,資料存盤,計算,服務,管控的強有力的支撐,我們是否可以開始搭建大資料集群了呢?其實還不著急,在開工之前,需求的明確是無比重要的,針對不同的業務,電商,風控,還是其他行業都有著不同的需求,對于用戶畫像的要求也不同,那么該如何明確這些需求呢,最重要的就是定義好用戶畫像的標簽體系,這是涉及技術人員,產品,運營等崗位共同討論的結果,也是用戶畫像的核心所在,下一篇,我們將討論用戶畫像的標簽體系,未完待續~
參考文獻
《用戶畫像:方法論與工程化解決方案》
更多實時資料分析相關博文與科技資訊,歡迎關注 “實時流式計算” 獲取用戶畫像相關資料 請關注 “實時流式計算” 回復 “用戶畫像”

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/6033.html
標籤:大數據
上一篇:pandas用法總結
下一篇:【趙強老師】Kafka的體系架構