前言
- 昨天有讀者朋友留言,想要陳某寫一篇防止快取穿透的文章,今天特意寫了一篇,

- 文章目錄如下:
-
什么是快取穿透?
- 快取穿透其實是指從快取中沒有查到資料,而不得不從后端系統(比如資料庫)中查詢的情況,
- 快取畢竟是在記憶體中,不可能所有的資料都存盤在 Redis 中,因此少量的快取穿透是不可避免的,也是系統能夠承受的,但是一旦在瞬間發生大量的快取穿透,資料庫的壓力會瞬間增大,后果可想而知,
- 在開發中使用快取的方案如下圖,在查詢資料庫之前會先查詢 Redis:

- 快取穿透的整個程序分為如下幾個步驟:
- 應用查詢快取,快取不命中
- DB 層查詢不命中,不將空結果快取
- 回傳空結果
- 下一個請求繼續重復1,2,3步,
解決方案
- 萬事萬物都是相生相克,既然出現了快取穿透,就一定有避免的方案,
- 下面介紹兩種快取的方案,分別是
快取空值、布隆過濾器,
快取空值
- 回顧快取穿透的定義知道,大量空值沒有快取導致重復的訪問 DB 層,由此解決方案也是很明顯了,直接將回傳的空值也快取即可,此時的執行步驟如下圖:
-
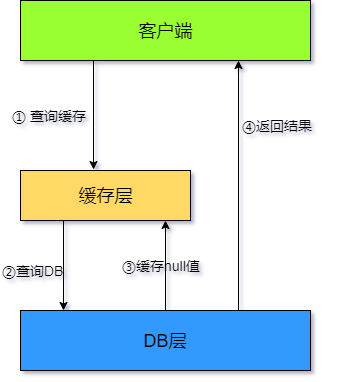
- 如上圖所示,如果快取不命中,查詢 DB 層之后,直接將空值快取在 Redis 中,偽代碼如下:
Object nullValue = https://www.cnblogs.com/Chenjiabing/p/new Object();
try {
Object valueFromDB = getFromDB(uid); //從資料庫中查詢資料
if (valueFromDB == null) {
cache.set(uid, nullValue, 10); //如果從資料庫中查詢到空值,就把空值寫入快取,設定較短的超時時間
} else {
cache.set(uid, valueFromDB, 1000);
}
} catch(Exception e) {
// 出現例外也要寫入快取
cache.set(uid, nullValue, 10);
}
- 通過偽代碼可以很清楚的了解了快取空值的流程,但是需要注意以下問題:
- 快取一定要設定過期時間:因為空值并不是準確的業務資料,并且會占用快取空間,所以要給空值加上一個過期時間,使得能夠在短期之內被淘汰,但是隨之而來的一個問題就是在一定的時間視窗內快取的資料和實際資料不一致,比如設定 10 秒鐘過期時間,但是在這 10 秒之內業務又寫入了資料,那么回傳就不應該為空值了,所以還要考慮資料一致的問題,解決方法很簡單,利用訊息系統或者主動更新的方式清除掉快取中的資料即可,
布隆過濾器
- 1970 年布隆提出了一種布隆過濾器的演算法,用來判斷一個元素是否在一個集合中,這種演算法由一個二進制陣列和一個 Hash 演算法組成,
- 解決快取穿透的大致思想:在訪問快取層和存盤層之前,可以通過定時任務或者系統任務來初始化布隆過濾器,將存在的 key 用布隆過濾器提前保存起來,做第一層的攔截,例如:一個推薦系統有 4 億個用戶 id, 每個小時演算法工程師會根據每個用戶之前歷史行為計算出推薦資料放到存盤層中, 但是最新的用戶由于沒有歷史行為, 就會發生快取穿透的行為, 為此可以將所有推薦資料的用戶做成布隆過濾器, 如果布隆過濾器認為該用戶 id 不存在, 那么就不會訪問存盤層, 在一定程度保護了存盤層,此時的結構如下圖:
-
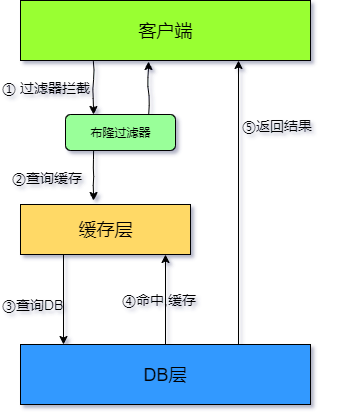
- 當然布隆過濾器的假陽性的存在導致了誤判率,但是我們可以盡量的降低誤判率,一個解決方案就是:使用多個 Hash 演算法為元素計算出多個 Hash 值,只有所有 Hash 值對應的陣列中的值都為 1 時,才會認為這個元素在集合中,
- 這種方法適用于
資料命中不高、資料相對固定、實時性低(通常是資料 集較大)的應用場景,代碼維護較為復雜,但是快取空間占用少,為什么呢?因為布隆過濾器不支持洗掉元素,一旦資料變化,并不能及時的更新布隆過濾器,
兩種方案對比
- 兩種方案各有優缺點,具體使用哪種方案還是要根據業務場景和系統體量來定,具體的區別如下表:
| 方案 | 適用場景 | 維護成本 |
|---|---|---|
| 快取物件 | 1. 資料命中不高 2. 資料頻繁變化,實時性高 | 代碼維護點單、需要過多的快取空間,資料一致性需要自己實作 |
| 布隆過濾器 | 1. 資料命中不高 2.資料相對固定,實時性低 | 代碼維護復雜、快取空間占用少 |
總結
- 至此,如何解決快取穿透的問題已經介紹完了,覺得寫得不錯的,有所識訓的朋友,點點在看,分享關注一波,

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/6067.html
標籤:NoSQL
上一篇:Redis 鏈表實作
下一篇:Mongodb的備份與恢復