導讀
-
現代大部分的登錄系統都支持郵箱、手機號碼登錄兩種方式,那么如何在郵箱或者手機號碼這個字串上建立索引才能保證性能最佳呢?
-
今天這篇文章就來探討一下在Mysql中如何給一個字串加索引才能達到性能最佳,
- 本文首發于作者的微信公眾號【碼猿技術專欄】,原創不易,喜歡的朋友支持一下,謝謝!!!
-
陳某將會從什么是前綴索引、前綴索引和普通索引的比較、如何建麗最佳性能的前綴索引、前綴索引對覆寫索引的影響這幾段來講,
前綴索引
-
顧名思義,對于列值較長,比如
BLOB、TEXT、VARCHAR,就 "必須" 使用前綴索引,即將值的前一部分作為索引,因為索引的存盤也是需要空間的,同樣索引太長維護起來也比較困難, -
比如我們給
User表中的郵箱添加前綴索引,如下:
alter table user add index index1(email(7));
-
上述陳述句將email的前7個字符作為索引,
前綴索引和普通索引比較
-
我們分別將
email的全部作為索引和前7個字符作為索引來看看在性能上有什么差異,建立索引的陳述句如下:
alter table user add index index1(email);
?
alter table user add index index2(email(7));
-
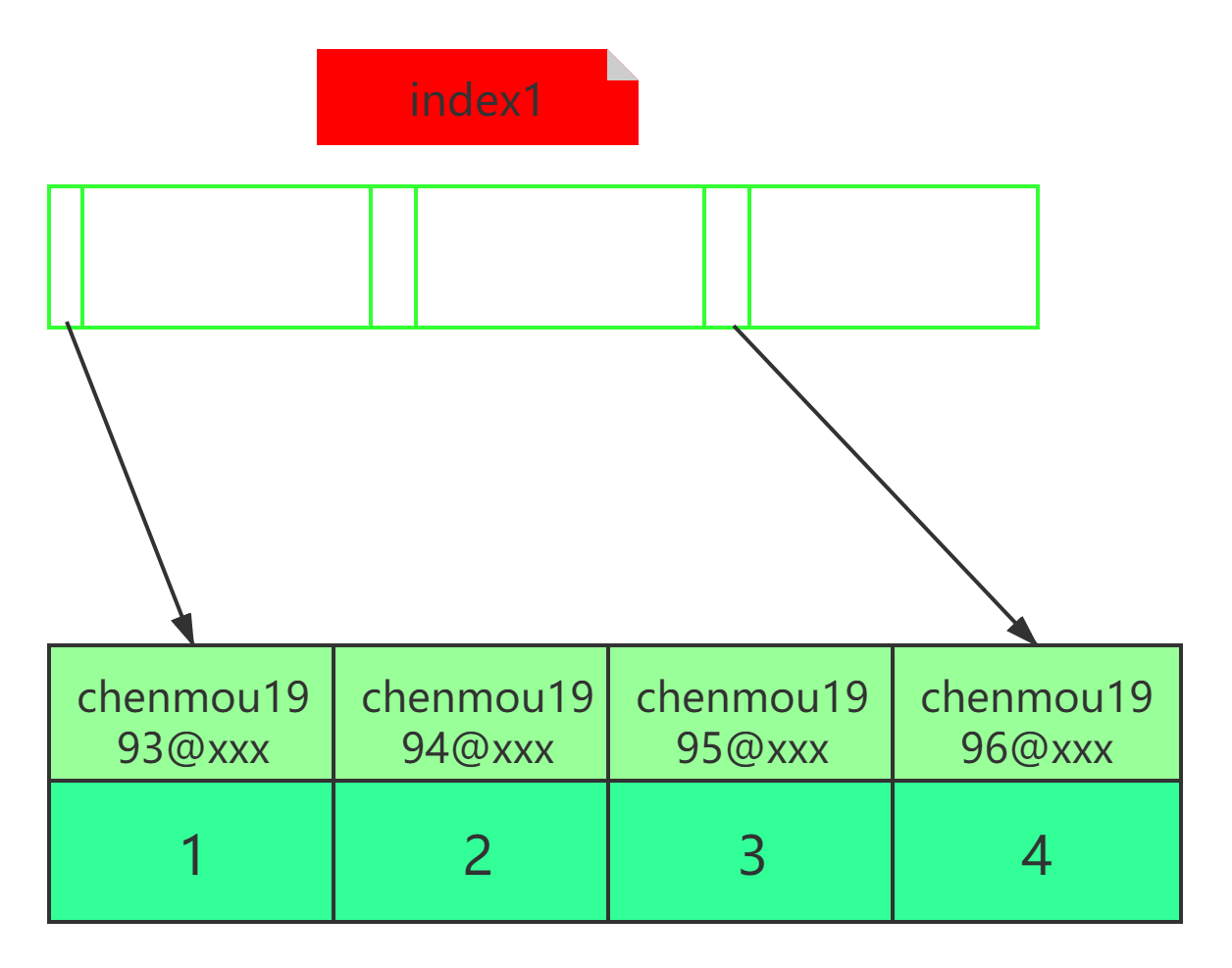
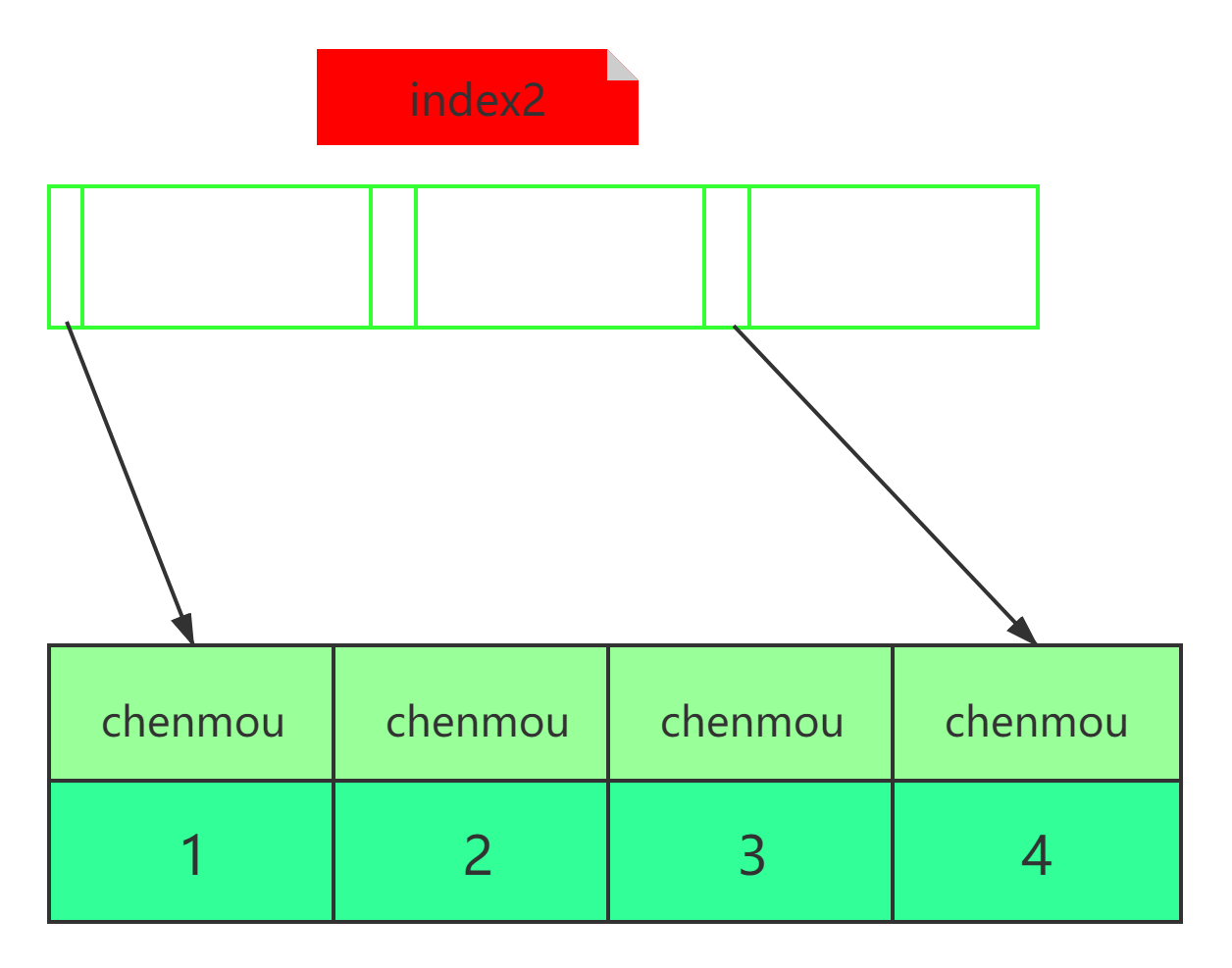
假設有
user表中有這樣幾條資料(id,name,email):(1,"陳某","chenmou1993@xxx")、(2,"張某","chenmou1994@xxx")、(3,"李某","chenmou1995@xxx")、(4,"王某","chenmou1996@xxx"), -
對應于index1和index2的索引樹如下兩張圖:
-
如果執行下面的查詢陳述句,Mysql如何利用索引來查詢呢?
select * from user where email="chenmou1995@xxx";
【1】普通索引的執行程序
-
從index1索引樹找到滿足索引值是
chenmou1995@xxx的這條記錄,取得id=2的值; -
到主鍵上查到主鍵值是
id=2的行,判斷email的值是正確的,將這行記錄加入結果集; -
取
index1索引樹上剛剛查到的位置的下一條記錄,發現已經不滿足email=chenmou1995@xxx的條件了,回圈結束,
這個程序中,只需要回主鍵索引取一次資料,所以系統認為只掃描了一行,
【2】前綴索引的執行程序
-
從index2索引樹找到滿足索引值是
chenmou的記錄,找到的第一個是id=1; -
到主鍵上查到主鍵值是id=1的行,判斷出email的值不是
chenmou1995@xxx,這行記錄丟棄; -
取index2上剛剛查到的位置的下一條記錄,發現仍然是
chenmou,取出id=2,再到ID索引上取整行然后判斷,這次值對了,將這行記錄加入結果集; -
重復上一步,直到在idxe2上取到的值不是
chenmou時,回圈結束,
在這個程序中,要回主鍵索引取4次資料,也就是掃描了4行,
-
通過以上查詢的對比,很容易就可以發現,使用前綴索引后,可能會導致查詢陳述句讀資料的次數變多,
-
但是對于這個查詢陳述句來說,如果建立的前綴索引的長度為13呢?那么滿足
chenmou1995的記錄只有一個,這樣就可以直接定位到id=2,此時不但空間縮小了,掃描的行數也減少了, -
于是結論就來了:使用前綴索引,只要定義好長度,就可以做到既節省空間,又不用額外增加太多的查詢成本,
-
那么如何建立正確的前綴索引才能達到最佳的性能呢?接著往下看................
如何建立最佳性能的前綴索引
-
通過上述的比較,可以得出一個結論,建立前綴索引的區分度越高越好,意味著重復的鍵值越少,
-
那么如何統計區分度,其實很簡單,只需要判斷資料庫中重復的次數即可,sql如下:
select
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from user;
-
但是如果對于使用前綴區分度不太好的情況,比如,我們國家的身份證號,一共18位,其中前6位是地址碼,所以同一個縣的人的身份證號前6位一般會是相同的, 這時候如果對身份證號做長度為6的前綴索引的話,這個索引的區分度就非常低了,
-
按照我們前面說的方法,可能你需要創建長度為12以上的前綴索引,才能夠滿足區分度要求,
-
但是,索引選取的越長,占用的磁盤空間就越大,相同的資料頁能放下的索引值就越少,搜索的效率也就會越低,
-
那么,如果我們能夠確定業務需求里面只有按照身份證進行等值查詢的需求,還有沒有別的處理方法呢?這種方法,既可以占用更小的空間,也能達到相同的查詢效率,現在簡單的介紹一種解決此種問題的方式,當然方法肯定不止一種,如下:
倒序存盤
如果你存盤身份證號的時候把它倒過來存,每次查詢的時候,你可以這么寫:
select field_list from t where id_card = reverse('輸入的身份證號');
由于身份證號的最后6位沒有地址碼這樣的重復邏輯,所以最后這6位很可能就提供了足夠的區分度,當然了,實踐中你不要忘記使用count(distinct)方法去做個驗證,
前綴索引對覆寫索引的影響
-
前綴索引會導致覆寫索引失效,查詢陳述句如下:
select id,name from user where email="chenmou1995@xxx";
-
由于使用了前綴索引,因此必須會回表驗證查詢到的時候正確,此處使用了覆寫索引也是無效的,
-
也就是說,使用前綴索引就用不上覆寫索引對查詢性能的優化了,這也是你在選擇是否使用前綴索引時需要考慮的一個因素,
總結
-
如何給字串加索引是一個需要考量的問題,陳某在這里給出如下的建議:
-
如果字串長度很短,建議直接用全部作為索引,
-
使用前綴索引注意分析區分度,區分度越高越好,
-
使用前綴索引需要考慮覆寫索引失效的問題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/61062.html
標籤:MySQL
上一篇:varchar int 查詢 到底什么情況下走索引?
下一篇:MySQL事務介紹