零、環境準備
mysql版本:8.0.20
除錯IDE:Visual Studio Code
一、問題引入
看如下一條sql陳述句:
# table T (id int, name varchar(20))
delete from T where id = 10;MySQL在執行的程序中,是如何加鎖呢?
再看下面這條陳述句:
select * from T where id = 5;那這條陳述句呢?其實這其中包含太多知識點了,要回答這兩個問題,首先需要了解一些知識,
二、相關知識回顧
2.1 多版本并發控制
在MySQL默認存盤引擎InnoDB中,實作的是基于多版本的并發控制協議——MVCC(Multi-Version Concurrency Control)(注:與MVVC相對的,是基于鎖的并發控制,Lock-Based Concurrency Control),
其中MVCC最大的好處是:讀不加鎖,讀寫不沖突,在讀多寫少的OLTP應用中,讀寫不沖突是非常重要的,極大的提高了系統的并發性能,在現階段,幾乎所有的RDBMS,都支持MVCC,其實,MVCC就一句話總結:同一份資料臨時保存多個版本的一種方式,進而實作并發控制,
2.2 當前讀和快照讀
在MVCC并發控制中,讀操作可以分為兩類:快照讀與當前讀,
- 快照讀(簡單的select操作):讀取的是記錄中的可見版本(可能是歷史版本),不用加鎖,這你就知道第二個問題的答案了吧,
- 當前讀(特殊的select操作、insert、delete和update):讀取的是記錄中最新版本,并且當前讀回傳的記錄都會加上鎖,這樣保證了了其他事務不會再并發修改這條記錄,
2.3 聚集索引
也叫做聚簇索引,在InnoDB中,資料的組織方式就是聚簇索引:完整的記錄,儲存在主鍵索引中,通過主鍵索引,就可以獲取記錄中所有的列,
2.4 最左前綴原則
也就是最左優先,這條原則針對的是組合索引和前綴索引,理解:
1、在MySQL中,進行條件過濾時,是按照向右匹配直到遇到范圍查詢(>,<,between,like)就停止匹配,比如說a = 1 and b = 2 and c > 3 and d = 4 如果建立(a, b, c, d)順序的索引,d是用不到索引的,如果建立(a, b, d, c)索引就都會用上,其中a,b,d的順序可以任意調整,
2、= 和 in 可以亂序,比如 a = 1 and b = 2 and c = 3 建立(a, b, c)索引可以任意順序,MySQL的查詢優化器會優化索引可以識別的形式,
2.5 兩階段鎖
傳統的RDMS加鎖的一個原則,就是2PL(Two-Phase Locking,二階段鎖),也就是說鎖操作分為兩個階段:加鎖階段和解鎖階段,并且保證加鎖階段和解鎖階段不想交,也就是說在一個事務中,不管有多少條增刪改,都是在加鎖階段加鎖,在 commit 后,進入解鎖階段,才會全部解鎖,
2.6 隔離級別
MySQL/InnoDB中,定義了四種隔離級別:
- Read Uncommitted:可以讀取未提交記錄,此隔離級別不會使用,
- Read Committed(RC):針對當前讀,RC隔離級別保證了對讀取到的記錄加鎖(記錄鎖),存在幻讀現象,
- Repeatable Read(RR):針對當前讀,RR隔離級別保證對讀取到的記錄加鎖(記錄鎖),同時保證對讀取的范圍加鎖,新的滿足查詢條件的記錄不能夠插入(間隙鎖),不存在幻讀現象,
- Serializable:從MVCC并發控制退化為基于鎖的并發控制,不區別快照讀和當前讀,所有的讀操作都是當前讀,讀加讀鎖(S鎖),寫加寫鎖(X鎖),在該隔離級別下,讀寫沖突,因此并發性能急劇下降,在MySQL/InnoDB中不建議使用,
2.7 Gap鎖和Next-Key鎖
在InnoDB中完整行鎖包含三部分:
- 記錄鎖(Record Lock):記錄鎖鎖定索引中的一條記錄,
- 間隙鎖(Gap Lock):間隙鎖要么鎖住索引記錄中間的值,要么鎖住第一個索引記錄前面的值或最后一個索引記錄后面的值,
- Next-Key Lock:Next-Key鎖時索引記錄上的記錄鎖和在記錄之前的間隙鎖的組合,
三、案例分析程序
SQL1: select * from t1 where id = 10;(不加鎖,因為MySQL是使用多版本并發控制的,讀不加鎖,)
SQL2: delete from t1 where id = 10;(需根據多種情況進行分析)
假設t1表上有索引,執行計劃一定會選擇使用索引進行過濾 (索引掃描),根據以下組合,來進行分析,
- 組合一:id列是主鍵,RC隔離級別
- 組合二:id列是二級唯一索引,RC隔離級別
- 組合三:id列是二級非唯一索引,RC隔離級別
- 組合四:id列上沒有索引,RC隔離級別
- 組合五:id列是主鍵,RR隔離級別
- 組合六:id列是二級唯一索引,RR隔離級別
- 組合七:id列是二級非唯一索引,RR隔離級別
- 組合八:id列上沒有索引,RR隔離級別
- 組合九:Serializable隔離級別
注:在前面八種組合下,也就是RC,RR隔離級別下,SQL1:select操作均不加鎖,采用的是快照讀,因此在下面的討論中就忽略了,主要討論SQL2:delete操作的加鎖,
組合一: id主鍵 + RC
id是主鍵,Read Committed隔離級別,給定SQL:delete from t1 where id = 10; 只需要將主鍵上,id = 10的記錄加上X鎖即可,如下圖所示:
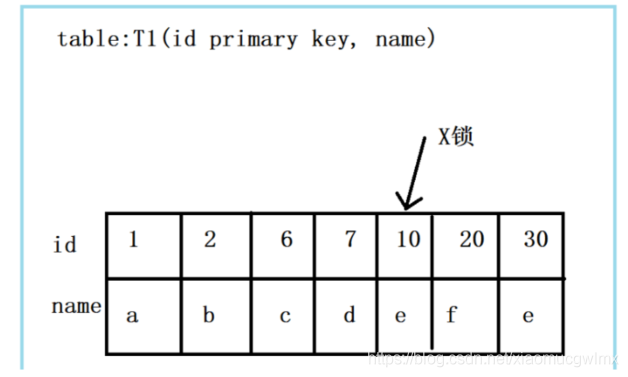
結論:id是主鍵時,此SQL只需要在id=10這條記錄上加X鎖即可,
示例:
#準備資料
mysql> create table t1 (id int,name varchar(10));
mysql> alter table t1 add primary key (id);
mysql> insert into t1 values(1,'a'),(4,'c'),(7,'b'),(10,'a'),(20,'d'),(30,'b');
mysql> select * from t1;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 4 | c |
| 7 | b |
| 10 | a |
| 20 | d |
| 30 | b |
+----+------+
6 rows in set (0.00 sec)
會話1
mysql> select @@tx_isolation;
+----------------+
| @@tx_isolation |
+----------------+
| READ-COMMITTED |
+----------------+
1 row in set, 1 warning (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t1 where id=10;
Query OK, 1 row affected (0.00 sec)
會話2
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t1;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 4 | c |
| 7 | b |
| 10 | a |
| 20 | d |
| 30 | b |
+----+------+
6 rows in set (0.00 sec)
mysql> update t1 set name='a1' where id=10;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update t1 set name='a1' where id=11;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 0 Changed: 0 Warnings: 0
mysql> update t1 set name='a1' where id=7;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
從示例中可以看到會話1執行的delete操作,只對id=10加了X鎖,
組合二:id唯一索引 + RC
id不是主鍵,而是一個Unique的二級索引鍵值,那么在RC隔離級別下,delete from t1 where id = 10; 需要加什么鎖呢?見下圖:
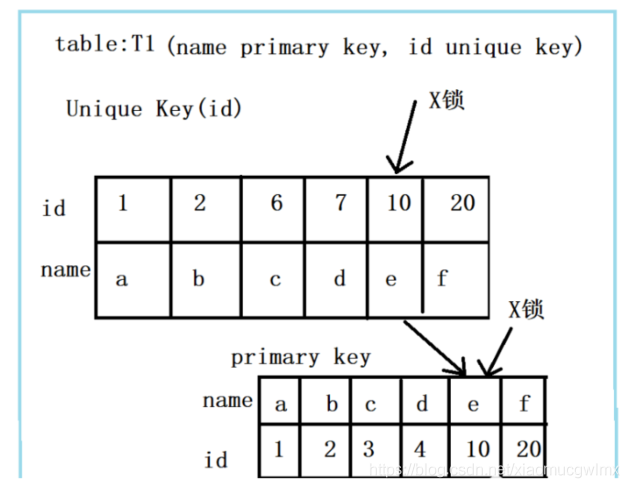
此組合中,id是unique索引,而主鍵是name列,此時,加鎖的情況由于組合一有所不同,由于id是unique索引,因此delete陳述句會選擇走id列的索引進行where條件的過濾,在找到id=10的記錄后,首先會將unique索引上的id=10索引記錄加上X鎖,同時,會根據讀取到的name列,回主鍵索引(聚簇索引),然后將聚簇索引上的name = ‘d’ 對應的主鍵索引項加X鎖,
為什么聚簇索引上的記錄也要加鎖?試想一下,如果并發的一個SQL,是通過主鍵索引來更新:update t1 set id = 100 where name = 'd';此時,如果delete陳述句沒有將主鍵索引上的記錄加鎖,那么并發的update就會感知不到delete陳述句的存在,違背了同一記錄上的更新/洗掉需要串行執行的約束,
示例:
準備資料
mysql> create table t1 (id int,name varchar(10));
Query OK, 0 rows affected (0.06 sec)
mysql> ALTER TABLE test.t1 ADD UNIQUE INDEX idx_id (id);
Query OK, 0 rows affected (0.07 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> ALTER TABLE test.t1 ADD PRIMARY KEY (name);
Query OK, 0 rows affected (0.11 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> insert into t1 values(1,'f'),(2,'zz'),(3,'b'),(5,'a'),(6,'c'),(10,'d');
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
會話1
mysql> begin;
Query OK, 0 rows affected (0.01 sec)
mysql> delete from t1 where id=10;
Query OK, 1 row affected (0.00 sec)
會話2
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t1;
+------+------+
| id | name |
+------+------+
| 1 | f |
| 2 | zz |
| 3 | b |
| 5 | a |
| 6 | c |
| 10 | d |
+------+------+
6 rows in set (0.00 sec)
mysql> update t1 set id =100 where name='d';
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update t1 set id =100 where name='c';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update t1 set id =101 where name='a';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0結論:若id列是unique列,其上有unique索引,那么SQL需要加兩個X鎖,一個對應于id unique索引上的id = 10的記錄,另一把鎖對應于聚簇索引上的[name=’d’,id=10]的記錄,
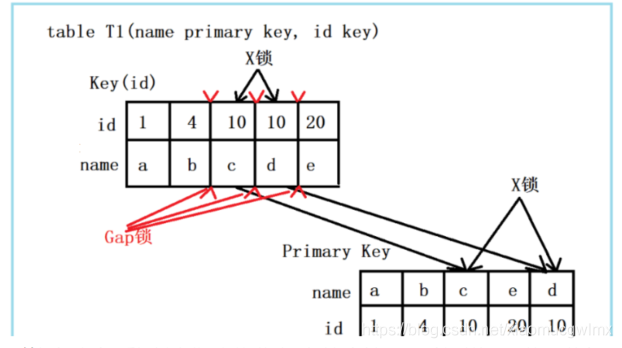
組合三:id非唯一索引 + RC
id列是一個普通索引,假設delete from t1 where id = 10; 陳述句,仍舊選擇id列上的索引進行過濾where條件,那么此時會持有哪些鎖?同樣見下圖:
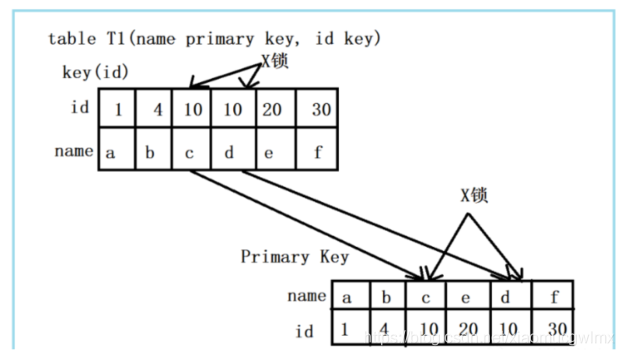
由上圖可以看出,首先,id列索引上,滿足id = 10查詢的記錄,均加上X鎖,同時,這些記錄對應的主鍵索引上的記錄也加上X鎖,與組合二的唯一區別,組合二最多只有一個滿足條件的記錄,而在組合三中會將所有滿足條件的記錄全部加上鎖,
結論:若id列上有非唯一索引,那么對應的所有滿足SQL查詢條件的記錄,都會加上鎖,同時,這些記錄在主鍵索引上也會加上鎖,
示例:
準備資料
mysql> create table t1 (id int,name varchar(10));
mysql> ALTER TABLE test.t1 ADD PRIMARY KEY (name);
mysql> alter table t1 add index idx_id (id);
mysql> insert into t1 values(2,'zz'),(6,'c'),(10,'b'),(10,'d'),(11,'f'),(15,'a');
會話1
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t1 where id=10;
Query OK, 2 rows affected (0.00 sec)
會話2
mysql> select * from t1;
+------+------+
| id | name |
+------+------+
| 2 | zz |
| 6 | c |
| 10 | b |
| 10 | d |
| 11 | f |
| 15 | a |
+------+------+
6 rows in set (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update t1 set id=11 where name='b';
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update t1 set id=11 where name='d';
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update t1 set id=11 where name='f';
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0
mysql> update t1 set id=11 where name='c';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
組合四:id無索引+RC
相對于前面的組合,該組合相對特殊,因為id列上無索引,所以在 where id = 10 這個查詢條件下,沒法通過索引來過濾,因此只能全表掃描做過濾,對于該組合,MySQL又會進行怎樣的加鎖呢?看下圖:
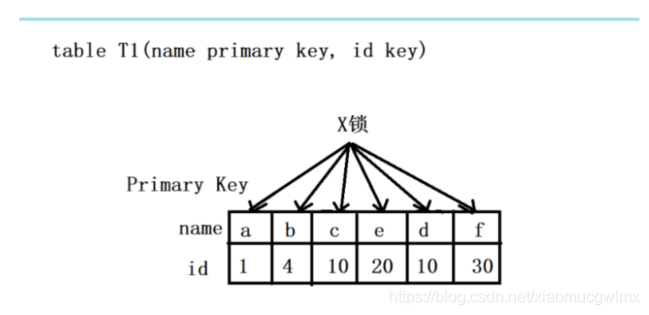
由于id列上無索引,因此只能走聚簇索引,進行全表掃描,由圖可以看出滿足條件的記錄只有兩條,但是,聚簇索引上的記錄都會加上X鎖,但在實際操作中,MySQL進行了改進,在進行過濾條件時,發現不滿足條件后,會呼叫 unlock_row 方法,把不滿足條件的記錄放鎖(違背了2PL原則),這樣做,保證了最后滿足條件的記錄加上鎖,但是每條記錄的加鎖操作是不能省略的,
結論:若id列上沒有索引,MySQL會走聚簇索引進行全表掃描過濾,由于是在MySQl Server層面進行的,因此每條記錄無論是否滿足條件,都會加上X鎖,但是,為了效率考慮,MySQL在這方面進行了改進,在掃描程序中,若記錄不滿足過濾條件,會進行解鎖操作,同時優化違背了2PL原則,
示例:
準備資料
mysql> create table t1 (id int,name varchar(10));
mysql> ALTER TABLE test.t1 ADD PRIMARY KEY (name);
mysql> insert into t1 values(5,'a'),(3,'b'),(10,'d'),(2,'f'),(10,'g'),(9,'zz');
會話1
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t1 where id=10;
Query OK, 2 rows affected (0.00 sec)
會話2
mysql> select * from t1;
+------+------+
| id | name |
+------+------+
| 5 | a |
| 3 | b |
| 10 | d |
| 2 | f |
| 10 | g |
| 9 | zz |
+------+------+
6 rows in set (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update t1 set id=6 where name='a';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update t1 set id=6 where name='b';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update t1 set id=6 where name='d';
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update t1 set id=6 where name='f';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update t1 set id=6 where name='g';
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update t1 set id=6 where name='zz';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update t1 set id=6 where name='zzf';
Query OK, 0 rows affected (0.00 sec)
Rows matched: 0 Changed: 0 Warnings: 0
實驗結果與推倒的結論不一致,
實驗結果看出只鎖住了id=10的兩行,
組合五:id主鍵+RR
id列是主鍵列,Repeatable Read隔離級別,針對delete from t1 where id = 10; 這條SQL,加鎖與組合一:”id主鍵 + RC“一致,
結論:id是主鍵是,此SQL陳述句只需要在id = 10這條記錄上加上X鎖即可,
示例:
mysql> create table t1 (id int,name varchar(10));
mysql> alter table t1 add primary key (id);
mysql> insert into t1 values(1,'a'),(4,'c'),(7,'b'),(10,'a'),(20,'d'),(30,'b');
mysql> select * from t1;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 4 | c |
| 7 | b |
| 10 | a |
| 20 | d |
| 30 | b |
+----+------+
6 rows in set (0.00 sec)
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
會話1
mysql> begin;
Query OK, 0 rows affected (0.01 sec)
mysql> delete from t1 where id=10;
Query OK, 1 row affected (0.00 sec)
會話2
mysql> select * from t1;
+----+------+
| id | name |
+----+------+
| 1 | a |
| 4 | c |
| 7 | b |
| 10 | a |
| 20 | d |
| 30 | b |
+----+------+
6 rows in set (0.00 sec)
mysql> update t1 set name='a1' where id=10;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update t1 set name='a1' where id=11;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 0 Changed: 0 Warnings: 0
mysql> update t1 set name='a1' where id=7;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
組合六:id唯一索引+RR
id唯一索引 + RR的加鎖與id唯一索引,RC一致,兩個X鎖,id唯一索引滿足條件的記錄上一個,對應的聚簇索引上的記錄一個,
示例:
準備資料
mysql> create table t1 (id int,name varchar(10));
mysql> ALTER TABLE test.t1 ADD UNIQUE INDEX idx_id (id);
mysql> ALTER TABLE test.t1 ADD PRIMARY KEY (name);
mysql> insert into t1 values(1,'f'),(2,'zz'),(3,'b'),(5,'a'),(6,'c'),(10,'d');
會話1
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t1 where id=10;
Query OK, 1 row affected (0.01 sec)
會話2
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t1;
+------+------+
| id | name |
+------+------+
| 1 | f |
| 2 | zz |
| 3 | b |
| 5 | a |
| 6 | c |
| 10 | d |
+------+------+
6 rows in set (0.00 sec)
mysql> update t1 set id =100 where name='d';
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> update t1 set id =100 where name='c';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> update t1 set id =101 where name='a';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
組合七:id不唯一索引+RR
在組合一到組合四中,隔離級別是Read Committed下,會出現幻讀情況,但是在該組合Repeatable Read級別下,不會出現幻讀情況,這是怎么回事呢?而MySQL又是如何給上述陳述句加鎖呢?看下圖:
該組合和組合三看起來很相似,但差別很大,在該組合中加入了一個間隙鎖(Gap鎖),這個Gap鎖就是相對于RC級別下,RR級別下不會出現幻讀情況的關鍵,實質上,Gap鎖不是針對于記錄本身的,而是記錄之間的Gap,所謂幻讀,就是同一事務下,連續進行多次當前讀,且讀取一個范圍內的記錄(包括直接查詢所有記錄結果或者做聚合統計),發現結果不一致(標準檔案一般指記錄增多, 記錄的減少應該也算是幻讀),
那么該如何解決這個問題呢?如何保證多次當前讀回傳一致的記錄,那么就需要在多個當前讀之間,其他事務不會插入新的滿足條件的記錄并提交,為了實作該結果,Gap鎖就應運而生,
如圖所示,有些位置可以插入新的滿足條件的記錄,考慮到B+樹的有序性,滿足條件的記錄一定是具有連續性的,因此會在 [4, b], [10, c], [10, d], [20, e] 之間加上Gap鎖,
Insert操作時,如insert(10, aa),首先定位到 [4, b], [10, c]間,然后插入在插入之前,會檢查該Gap是否加鎖了,如果被鎖上了,則Insert不能加入記錄,因此通過第一次當前讀,會把滿足條件的記錄加上X鎖,還會加上三把Gap鎖,將可能插入滿足條件記錄的3個Gap鎖上,保證后續的Insert不能插入新的滿足 id = 10 的記錄,也就解決了幻讀問題,
而在組合五,組合六中,同樣是RR級別,但是不用加上Gap鎖,在組合五中id是主鍵,組合六中id是Unique鍵,都能保證唯一性,一個等值查詢,最多只能回傳一條滿足條件的記錄,而且新的相同取值的記錄是無法插入的,
結論:在RR隔離級別下,id列上有非唯一索引,對于上述的SQL陳述句;首先,通過id索引定位到第一條滿足條件的記錄,給記錄加上X鎖,并且給Gap加上Gap鎖,然后在主鍵聚簇索引上滿足相同條件的記錄加上X鎖,然后回傳;之后讀取下一條記錄重復進行,直至第一條出現不滿足條件的記錄,此時,不需要給記錄加上X鎖,但是需要給Gap加上Gap鎖,最后回傳結果,
示例:
準備資料
mysql> create table t1 (id int,name varchar(10));
mysql> ALTER TABLE test.t1 ADD PRIMARY KEY (name);
mysql> alter table t1 add index idx_id (id);
mysql> insert into t1 values(1,'a'),(4,'b'),(10,'c'),(20,'e'),(10,'d');
會話1
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t1 where id=10;
Query OK, 2 rows affected (0.00 sec)
會話2
mysql> select * from t1;
+------+------+
| id | name |
+------+------+
| 1 | a |
| 4 | b |
| 10 | c |
| 10 | d |
| 20 | e |
+------+------+
5 rows in set (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into t1 values(6,'aa');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t1 values(6,'bb');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t1 values(6,'cc');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into t1 values(7,'cc');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into t1 values(8,'cc');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into t1 values(9,'cc');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into t1 values(10,'cc');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into t1 values(11,'cc');
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> insert into t1 values(11,'ff');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t1 values(11,'g');
Query OK, 1 row affected (0.00 sec)
組合八:id無索引+RR
該組合中,id列上無索引,只能進行全表掃描,那么該如何加鎖,看下圖:
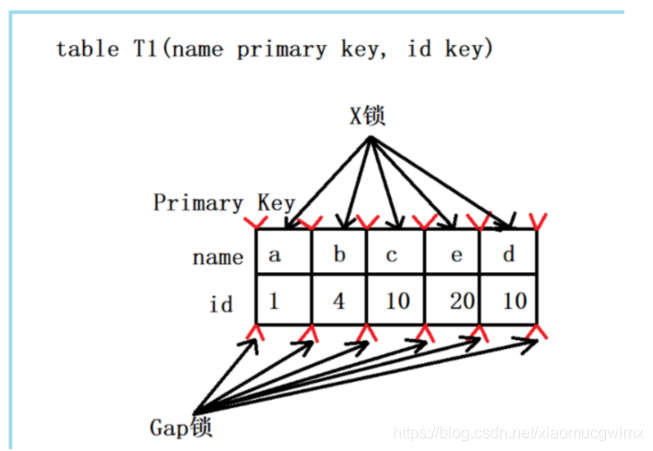
如圖,可以看出這是一個很恐怖的事情,全表每條記錄要加X鎖,每個Gap加上Gap鎖,如果表上存在大量資料時,又是什么情景呢?這種情況下,這個表,除了不加鎖的快照讀,其他任何加鎖的并發SQL,均不能執行,不能更新,洗掉,插入,這樣,全表鎖死,
當然,和組合四一樣,MySQL進行了優化,就是semi-consistent read,semi-consistent read開啟的情況下,對于不滿足條件的記錄,MySQL會提前放鎖,同時Gap鎖也會釋放,而semi-consistent read是如何觸發:要么在Read Committed隔離級別下;要么在Repeatable Read隔離級別下,設定了 innodb_locks_unsafe_for_binlog 引數,
示例:
準備資料
mysql> create database cgwtest;
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
//mysql> insert into t1 values(5,'a'),(3,'b'),(10,'d'),(2,'f'),(10,'g'),(9,'zz');
mysql> insert into t values(1,1),(5,5),(10,10);
會話1
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> delete from t where d=5;
Query OK, 1 rows affected (0.00 sec)
會話2
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from t;
+----+------+
| id | d |
+----+------+
| 1 | 1 |
| 5 | 5 |
| 10 | 10 |
+----+------+
3 rows in set (0.00 sec)
mysql> insert into t values(2,2);
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
(注:以下流程和原始碼是主流程和重點關注的點!)
1,delete原始碼實作程序:
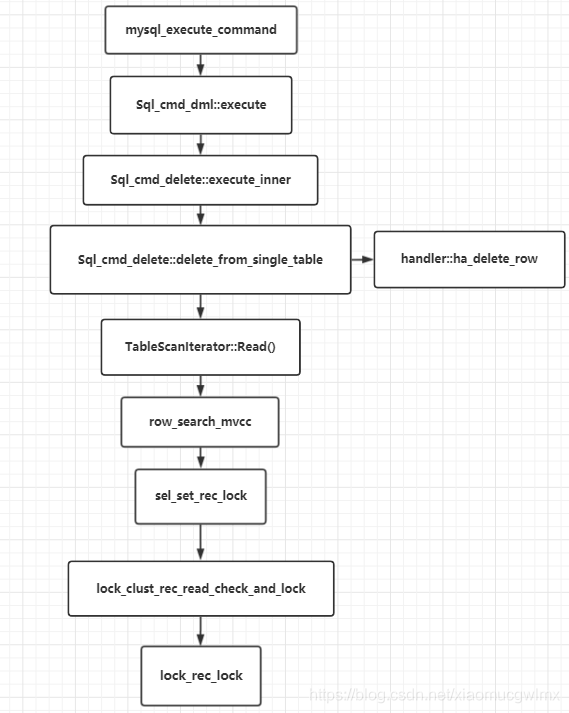
/* Basic lock modes */
enum lock_mode {
LOCK_IS = 0, /* intention shared */
LOCK_IX, /* intention exclusive */
LOCK_S, /* shared */
LOCK_X, /* exclusive */
LOCK_AUTO_INC, /* locks the auto-inc counter of a table
in an exclusive mode */
LOCK_NONE, /* this is used elsewhere to note consistent read */
LOCK_NUM = LOCK_NONE, /* number of lock modes */
LOCK_NONE_UNSET = 255
};
ut_ad(gap_mode == LOCK_ORDINARY || gap_mode == LOCK_GAP ||
gap_mode == LOCK_REC_NOT_GAP);
#define ut_ad(EXPR) ut_a(EXPR)
/** Debug statement. Does nothing unless UNIV_DEBUG is defined. */除錯斷言核心方法:
/** Sets a lock on a record.
mostly due to we cannot reposition a record in R-Tree (with the
nature of splitting)
@param[in] pcur cursor
@param[in] rec record
@param[in] index index
@param[in] offsets rec_get_offsets(rec, index)
@param[in] sel_mode select mode: SELECT_ORDINARY,
SELECT_SKIP_LOKCED, or SELECT_NO_WAIT
@param[in] mode lock mode
@param[in] type LOCK_ORDINARY, LOCK_GAP, or LOC_REC_NOT_GAP
@param[in] thr query thread
@param[in] mtr mtr
@return DB_SUCCESS, DB_SUCCESS_LOCKED_REC, or error code */
UNIV_INLINE
dberr_t sel_set_rec_lock(btr_pcur_t *pcur, const rec_t *rec,
dict_index_t *index, const ulint *offsets,
select_mode sel_mode, ulint mode, ulint type,
que_thr_t *thr, mtr_t *mtr) {
trx_t *trx;
dberr_t err = DB_SUCCESS;
const buf_block_t *block;
block = btr_pcur_get_block(pcur);
trx = thr_get_trx(thr);
trx_mutex_enter(trx);
ut_ad(trx_can_be_handled_by_current_thread(trx));
bool too_many_locks = (UT_LIST_GET_LEN(trx->lock.trx_locks) > 10000);
trx_mutex_exit(trx);
if (too_many_locks) {
if (buf_LRU_buf_pool_running_out()) {
return (DB_LOCK_TABLE_FULL);
}
}
if (index->is_clustered()) {
err = lock_clust_rec_read_check_and_lock(
lock_duration_t::REGULAR, block, rec, index, offsets, sel_mode,
static_cast<lock_mode>(mode), type, thr);
} else {
if (dict_index_is_spatial(index)) {
if (type == LOCK_GAP || type == LOCK_ORDINARY) {
ut_ad(0);
ib::error(ER_IB_MSG_1026) << "Incorrectly request GAP lock "
"on RTree";
return (DB_SUCCESS);
}
err = sel_set_rtr_rec_lock(pcur, rec, index, offsets, sel_mode, mode,
type, thr, mtr);
} else {
err = lock_sec_rec_read_check_and_lock(
lock_duration_t::REGULAR, block, rec, index, offsets, sel_mode,
static_cast<lock_mode>(mode), type, thr);
}
}
return (err);
}dberr_t lock_clust_rec_read_check_and_lock(
const lock_duration_t duration, const buf_block_t *block, const rec_t *rec,
dict_index_t *index, const ulint *offsets, const select_mode sel_mode,
const lock_mode mode, const ulint gap_mode, que_thr_t *thr) {
dberr_t err;
ulint heap_no;
ut_ad(rec_offs_validate(rec, index, offsets));
if (srv_read_only_mode || index->table->is_temporary()) {
return (DB_SUCCESS);
}
heap_no = page_rec_get_heap_no(rec);
if (heap_no != PAGE_HEAP_NO_SUPREMUM) {
lock_rec_convert_impl_to_expl(block, rec, index, offsets);//隱示鎖轉顯示鎖
}
DEBUG_SYNC_C("after_lock_clust_rec_read_check_and_lock_impl_to_expl");
lock_mutex_enter();//系統鎖
if (duration == lock_duration_t::AT_LEAST_STATEMENT) {
lock_protect_locks_till_statement_end(thr);
}
ut_ad(mode != LOCK_X ||
lock_table_has(thr_get_trx(thr), index->table, LOCK_IX));
ut_ad(mode != LOCK_S ||
lock_table_has(thr_get_trx(thr), index->table, LOCK_IS));
err = lock_rec_lock(false, sel_mode, mode | gap_mode, block, heap_no, index,
thr);
MONITOR_INC(MONITOR_NUM_RECLOCK_REQ);
lock_mutex_exit();
ut_ad(lock_rec_queue_validate(false, block, rec, index, offsets));
DEBUG_SYNC_C("after_lock_clust_rec_read_check_and_lock");
ut_ad(err == DB_SUCCESS || err == DB_SUCCESS_LOCKED_REC ||
err == DB_LOCK_WAIT || err == DB_DEADLOCK || err == DB_SKIP_LOCKED ||
err == DB_LOCK_NOWAIT);
return (err);
}/** Tries to lock the specified record in the mode requested. If not immediately
possible, enqueues a waiting lock request. This is a low-level function
which does NOT look at implicit locks! Checks lock compatibility within
explicit locks. This function sets a normal next-key lock, or in the case
of a page supremum record, a gap type lock.
@param[in] impl if true, no lock is set if no wait is
necessary: we assume that the caller will
set an implicit lock
@param[in] sel_mode select mode: SELECT_ORDINARY,
SELECT_SKIP_LOCKED, or SELECT_NO_WAIT
@param[in] mode lock mode: LOCK_X or LOCK_S possibly ORed to
either LOCK_GAP or LOCK_REC_NOT_GAP
@param[in] block buffer block containing the record
@param[in] heap_no heap number of record
@param[in] index index of record
@param[in,out] thr query thread
@return DB_SUCCESS, DB_SUCCESS_LOCKED_REC, DB_LOCK_WAIT, DB_DEADLOCK,
DB_SKIP_LOCKED, or DB_LOCK_NOWAIT */
static dberr_t lock_rec_lock(bool impl, select_mode sel_mode, ulint mode,
const buf_block_t *block, ulint heap_no,
dict_index_t *index, que_thr_t *thr) {
ut_ad(lock_mutex_own());
ut_ad(!srv_read_only_mode);
/* Implicit locks are equivalent to LOCK_X|LOCK_REC_NOT_GAP, so we can omit
creation of explicit lock only if the requested mode was LOCK_REC_NOT_GAP */
ut_ad(!impl || ((mode & LOCK_REC_NOT_GAP) == LOCK_REC_NOT_GAP));
/* We try a simplified and faster subroutine for the most
common cases */
switch (lock_rec_lock_fast(impl, mode, block, heap_no, index, thr)) {
case LOCK_REC_SUCCESS
return (DB_SUCCESS);
case LOCK_REC_SUCCESS_CREATED:
return (DB_SUCCESS_LOCKED_REC);
case LOCK_REC_FAIL:
return (
lock_rec_lock_slow(impl, sel_mode, mode, block, heap_no, index, thr));
default:
ut_error;
}
}
delete陳述句呼叫堆疊:
lock_rec_lock(bool impl, select_mode sel_mode, ulint mode, const buf_block_t * block, ulint heap_no, dict_index_t * index, que_thr_t * thr) (\root\mysql-8.0.20\storage\innobase\lock\lock0lock.cc:1667)
lock_clust_rec_read_check_and_lock(const lock_duration_t duration, const buf_block_t * block, const rec_t * rec, dict_index_t * index, const ulint * offsets, const select_mode sel_mode, const lock_mode mode, const ulint gap_mode, que_thr_t * thr) (\root\mysql-8.0.20\storage\innobase\lock\lock0lock.cc:5701)
sel_set_rec_lock(btr_pcur_t * pcur, const rec_t * rec, dict_index_t * index, const ulint * offsets, select_mode sel_mode, ulint mode, ulint type, que_thr_t * thr, mtr_t * mtr) (\root\mysql-8.0.20\storage\innobase\row\row0sel.cc:1184)
row_search_mvcc(unsigned char * buf, page_cur_mode_t mode, row_prebuilt_t * prebuilt, ulint match_mode, const ulint direction) (\root\mysql-8.0.20\storage\innobase\row\row0sel.cc:5214)
ha_innobase::general_fetch(ha_innobase * const this, uchar * buf, uint direction, uint match_mode) (\root\mysql-8.0.20\storage\innobase\handler\ha_innodb.cc:9949)
ha_innobase::rnd_next(ha_innobase * const this, uchar * buf) (\root\mysql-8.0.20\storage\innobase\handler\ha_innodb.cc:10226)
handler::ha_rnd_next(handler * const this, uchar * buf) (\root\mysql-8.0.20\sql\handler.cc:2966)
TableScanIterator::Read(TableScanIterator * const this) (\root\mysql-8.0.20\sql\records.cc:423)
Sql_cmd_delete::delete_from_single_table(Sql_cmd_delete * const this, THD * thd) (\root\mysql-8.0.20\sql\sql_delete.cc:503)
Sql_cmd_delete::execute_inner(Sql_cmd_delete * const this, THD * thd) (\root\mysql-8.0.20\sql\sql_delete.cc:823)
Sql_cmd_dml::execute(Sql_cmd_dml * const this, THD * thd) (\root\mysql-8.0.20\sql\sql_select.cc:725)
mysql_execute_command(THD * thd, bool first_level) (\root\mysql-8.0.20\sql\sql_parse.cc:3471)
mysql_parse(THD * thd, Parser_state * parser_state) (\root\mysql-8.0.20\sql\sql_parse.cc:5306)
dispatch_command(THD * thd, const COM_DATA * com_data, enum_server_command command) (\root\mysql-8.0.20\sql\sql_parse.cc:1776)
do_command(THD * thd) (\root\mysql-8.0.20\sql\sql_parse.cc:1274)
handle_connection(void * arg) (\root\mysql-8.0.20\sql\conn_handler\connection_handler_per_thread.cc:302)
pfs_spawn_thread(void * arg) (\root\mysql-8.0.20\storage\perfschema\pfs.cc:2854)
libpthread.so.0!start_thread (未知源:0)
libc.so.6!clone (未知源:0)執行洗掉:
row_upd_clust_step(upd_node_t * node, que_thr_t * const thr) (\root\mysql-8.0.20\storage\innobase\row\row0upd.cc:2982)
row_upd(upd_node_t * node, que_thr_t * thr) (\root\mysql-8.0.20\storage\innobase\row\row0upd.cc:3175)
row_upd_step(que_thr_t * thr) (\root\mysql-8.0.20\storage\innobase\row\row0upd.cc:3306)
row_update_for_mysql_using_upd_graph(const unsigned char * mysql_rec, row_prebuilt_t * prebuilt) (\root\mysql-8.0.20\storage\innobase\row\row0mysql.cc:2347)
row_update_for_mysql(const unsigned char * mysql_rec, row_prebuilt_t * prebuilt) (\root\mysql-8.0.20\storage\innobase\row\row0mysql.cc:2443)
ha_innobase::delete_row(ha_innobase * const this, const uchar * record) (\root\mysql-8.0.20\storage\innobase\handler\ha_innodb.cc:9374)
handler::ha_delete_row(handler * const this, const uchar * buf) (\root\mysql-8.0.20\sql\handler.cc:7894)
Sql_cmd_delete::delete_from_single_table(Sql_cmd_delete * const this, THD * thd) (\root\mysql-8.0.20\sql\sql_delete.cc:528)
Sql_cmd_delete::execute_inner(Sql_cmd_delete * const this, THD * thd) (\root\mysql-8.0.20\sql\sql_delete.cc:823)
Sql_cmd_dml::execute(Sql_cmd_dml * const this, THD * thd) (\root\mysql-8.0.20\sql\sql_select.cc:725)
mysql_execute_command(THD * thd, bool first_level) (\root\mysql-8.0.20\sql\sql_parse.cc:3471)
mysql_parse(THD * thd, Parser_state * parser_state) (\root\mysql-8.0.20\sql\sql_parse.cc:5306)
dispatch_command(THD * thd, const COM_DATA * com_data, enum_server_command command) (\root\mysql-8.0.20\sql\sql_parse.cc:1776)
do_command(THD * thd) (\root\mysql-8.0.20\sql\sql_parse.cc:1274)
handle_connection(void * arg) (\root\mysql-8.0.20\sql\conn_handler\connection_handler_per_thread.cc:302)
pfs_spawn_thread(void * arg) (\root\mysql-8.0.20\storage\perfschema\pfs.cc:2854)
libpthread.so.0!start_thread (未知源:0)
libc.so.6!clone (未知源:0)
2,insert原始碼實作程序:
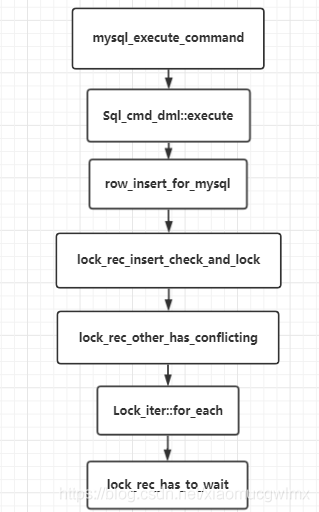
核心方法:
/** Checks if some other transaction has a conflicting explicit lock request
in the queue, so that we have to wait.
@return lock or NULL */
static const lock_t *lock_rec_other_has_conflicting(
ulint mode, /*!< in: LOCK_S or LOCK_X,
possibly ORed to LOCK_GAP or
LOC_REC_NOT_GAP,
LOCK_INSERT_INTENTION */
const buf_block_t *block, /*!< in: buffer block containing
the record */
ulint heap_no, /*!< in: heap number of the record */
const trx_t *trx) /*!< in: our transaction */
{
ut_ad(lock_mutex_own());
ut_ad(!(mode & ~(ulint)(LOCK_MODE_MASK | LOCK_GAP | LOCK_REC_NOT_GAP |
LOCK_INSERT_INTENTION)));
ut_ad(!(mode & LOCK_PREDICATE));
ut_ad(!(mode & LOCK_PRDT_PAGE));
RecID rec_id{block, heap_no};
const bool is_supremum = rec_id.is_supremum();
return (Lock_iter::for_each(rec_id, [=](const lock_t *lock) {
return (!(lock_rec_has_to_wait(trx, mode, lock, is_supremum)));
}));
}
/** Iterate over all the locks on a specific row
@param[in] rec_id Iterate over locks on this row
@param[in] f Function to call for each entry
@param[in] hash_table The hash table to iterate over
@return lock where the callback returned false */
template <typename F>
static const lock_t *for_each(const RecID &rec_id, F &&f,
hash_table_t *hash_table = lock_sys->rec_hash) {
ut_ad(lock_mutex_own());
auto list = hash_get_nth_cell(hash_table,
hash_calc_hash(rec_id.m_fold, hash_table));
for (auto lock = first(list, rec_id); lock != nullptr;
lock = advance(rec_id, lock)) {
ut_ad(lock->is_record_lock());
if (!std::forward<F>(f)(lock)) {
return (lock);
}
}
return (nullptr);
}
};/** Checks if a lock request for a new lock has to wait for request lock2.
@return true if new lock has to wait for lock2 to be removed */
UNIV_INLINE
bool lock_rec_has_to_wait(
const trx_t *trx, /*!< in: trx of new lock */
ulint type_mode, /*!< in: precise mode of the new lock
to set: LOCK_S or LOCK_X, possibly
ORed to LOCK_GAP or LOCK_REC_NOT_GAP,
LOCK_INSERT_INTENTION */
const lock_t *lock2, /*!< in: another record lock; NOTE that
it is assumed that this has a lock bit
set on the same record as in the new
lock we are setting */
bool lock_is_on_supremum)
/*!< in: true if we are setting the
lock on the 'supremum' record of an
index page: we know then that the lock
request is really for a 'gap' type lock */
{
ut_ad(trx && lock2);
ut_ad(lock_get_type_low(lock2) == LOCK_REC);
const bool is_hp = trx_is_high_priority(trx);
if (trx != lock2->trx &&
!lock_mode_compatible(static_cast<lock_mode>(LOCK_MODE_MASK & type_mode),
lock_get_mode(lock2))) {
/* If our trx is High Priority and the existing lock is WAITING and not
high priority, then we can ignore it. */
if (is_hp && lock2->is_waiting() && !trx_is_high_priority(lock2->trx)) {
return (false);
}
/* We have somewhat complex rules when gap type record locks
cause waits */
if ((lock_is_on_supremum || (type_mode & LOCK_GAP)) &&
!(type_mode & LOCK_INSERT_INTENTION)) {
/* Gap type locks without LOCK_INSERT_INTENTION flag
do not need to wait for anything. This is because
different users can have conflicting lock types
on gaps. */
return (false);
}
if (!(type_mode & LOCK_INSERT_INTENTION) && lock_rec_get_gap(lock2)) {
/* Record lock (LOCK_ORDINARY or LOCK_REC_NOT_GAP
does not need to wait for a gap type lock */
return (false);
}
if ((type_mode & LOCK_GAP) && lock_rec_get_rec_not_gap(lock2)) {
/* Lock on gap does not need to wait for
a LOCK_REC_NOT_GAP type lock */
return (false);
}
if (lock_rec_get_insert_intention(lock2)) {
/* No lock request needs to wait for an insert
intention lock to be removed. This is ok since our
rules allow conflicting locks on gaps. This eliminates
a spurious deadlock caused by a next-key lock waiting
for an insert intention lock; when the insert
intention lock was granted, the insert deadlocked on
the waiting next-key lock.
Also, insert intention locks do not disturb each
other. */
return (false);
}
return (true);
}
return (false);
}
呼叫堆疊
lock_rec_other_has_conflicting(ulint mode, const buf_block_t * block, ulint heap_no, const trx_t * trx) (\root\mysql-8.0.20\storage\innobase\lock\lock0lock.cc:805)
lock_rec_insert_check_and_lock(ulint flags, const rec_t * rec, buf_block_t * block, dict_index_t * index, que_thr_t * thr, mtr_t * mtr, ulint * inherit) (\root\mysql-8.0.20\storage\innobase\lock\lock0lock.cc:5291)
btr_cur_ins_lock_and_undo(ulint flags, btr_cur_t * cursor, dtuple_t * entry, que_thr_t * thr, mtr_t * mtr, ulint * inherit) (\root\mysql-8.0.20\storage\innobase\btr\btr0cur.cc:2621)
btr_cur_optimistic_insert(ulint flags, btr_cur_t * cursor, ulint ** offsets, mem_heap_t ** heap, dtuple_t * entry, rec_t ** rec, big_rec_t ** big_rec, que_thr_t * thr, mtr_t * mtr) (\root\mysql-8.0.20\storage\innobase\btr\btr0cur.cc:2841)
row_ins_clust_index_entry_low(uint32_t flags, ulint mode, dict_index_t * index, ulint n_uniq, dtuple_t * entry, que_thr_t * thr, bool dup_chk_only) (\root\mysql-8.0.20\storage\innobase\row\row0ins.cc:2515)
row_ins_clust_index_entry(dict_index_t * index, dtuple_t * entry, que_thr_t * thr, bool dup_chk_only) (\root\mysql-8.0.20\storage\innobase\row\row0ins.cc:3095)
row_ins_index_entry(dict_index_t * index, dtuple_t * entry, uint32_t & multi_val_pos, que_thr_t * thr) (\root\mysql-8.0.20\storage\innobase\row\row0ins.cc:3286)
row_ins_index_entry_step(ins_node_t * node, que_thr_t * thr) (\root\mysql-8.0.20\storage\innobase\row\row0ins.cc:3424)
row_ins(ins_node_t * node, que_thr_t * thr) (\root\mysql-8.0.20\storage\innobase\row\row0ins.cc:3542)
row_ins_step(que_thr_t * thr) (\root\mysql-8.0.20\storage\innobase\row\row0ins.cc:3666)
row_insert_for_mysql_using_ins_graph(const unsigned char * mysql_rec, row_prebuilt_t * prebuilt) (\root\mysql-8.0.20\storage\innobase\row\row0mysql.cc:1585)
row_insert_for_mysql(const unsigned char * mysql_rec, row_prebuilt_t * prebuilt) (\root\mysql-8.0.20\storage\innobase\row\row0mysql.cc:1715)
ha_innobase::write_row(ha_innobase * const this, uchar * record) (\root\mysql-8.0.20\storage\innobase\handler\ha_innodb.cc:8530)
handler::ha_write_row(handler * const this, uchar * buf) (\root\mysql-8.0.20\sql\handler.cc:7837)
write_record(THD * thd, TABLE * table, COPY_INFO * info, COPY_INFO * update) (\root\mysql-8.0.20\sql\sql_insert.cc:2111)
Sql_cmd_insert_values::execute_inner(Sql_cmd_insert_values * const this, THD * thd) (\root\mysql-8.0.20\sql\sql_insert.cc:621)
Sql_cmd_dml::execute(Sql_cmd_dml * const this, THD * thd) (\root\mysql-8.0.20\sql\sql_select.cc:725)
mysql_execute_command(THD * thd, bool first_level) (\root\mysql-8.0.20\sql\sql_parse.cc:3471)
mysql_parse(THD * thd, Parser_state * parser_state) (\root\mysql-8.0.20\sql\sql_parse.cc:5306)
dispatch_command(THD * thd, const COM_DATA * com_data, enum_server_command command) (\root\mysql-8.0.20\sql\sql_parse.cc:1776)
結論:在Repeatable Read隔離級別下,如果進行全表掃描的當前讀,那么會鎖上表上的所有記錄,并且所有的Gap加上Gap鎖,杜絕所有的 delete/update/insert 操作,當然在MySQL中,可以觸發 semi-consistent read來緩解鎖開銷與并發影響,但是semi-consistent read本身也會帶來其他的問題,不建議使用,
組合九:Serializable
在最后組合中,對于上訴的洗掉SQL陳述句,加鎖程序和組合八一致,但是,對于查詢陳述句(比如select * from T1 where id = 10)來說,在RC,RR隔離級別下,都是快照讀,不加鎖,在Serializable隔離級別下,無論是查詢陳述句也會加鎖,也就是說快照讀不存在了,MVCC降級為Lock-Based CC,
結論:在MySQL/InnoDB中,所謂的讀不加鎖,并不適用于所有的情況,而是和隔離級別有關,在Serializable隔離級別下,所有的操作都會加鎖,
四、其它:
1. 資料庫事務ACID特性
資料庫事務的4個特性:
原子性(Atomic): 事務中的多個操作,不可分割,要么都成功,要么都失敗; All or Nothing.
一致性(Consistency): 事務操作之后, 資料庫所處的狀態和業務規則是一致的; 比如a,b賬戶相互轉賬之后,總金額不變;
隔離性(Isolation): 多個事務之間就像是串行執行一樣,不相互影響;
持久性(Durability): 事務提交后被持久化到永久存盤.
2. 隔離性
其中 隔離性 分為了四種:
READ UNCOMMITTED:可以讀取未提交的資料,未提交的資料稱為臟資料,所以又稱臟讀,此時:幻讀,不可重復讀和臟讀均允許;
READ COMMITTED:只能讀取已經提交的資料;此時:允許幻讀和不可重復讀,但不允許臟讀,所以RC隔離級別要求解決臟讀;
REPEATABLE READ:同一個事務中多次執行同一個select,讀取到的資料沒有發生改變;此時:允許幻讀,但不允許不可重復讀和臟讀,所以RR隔離級別要求解決不可重復讀;
SERIALIZABLE: 幻讀,不可重復讀和臟讀都不允許,所以serializable要求解決幻讀;
3. 幾個概念
臟讀:可以讀取未提交的資料,RC 要求解決臟讀;
不可重復讀:同一個事務中多次執行同一個select, 讀取到的資料發生了改變(被其它事務update并且提交);
可重復讀:同一個事務中多次執行同一個select, 讀取到的資料沒有發生改變(一般使用MVCC實作);RR各級級別要求達到可重復讀的標準;
幻讀:同一個事務中多次執行同一個select, 讀取到的資料行發生改變,也就是行數減少或者增加了(被其它事務delete/insert并且提交),SERIALIZABLE要求解決幻讀問題;
這里一定要區分 不可重復讀 和 幻讀:
不可重復讀的重點是修改:
同樣的條件的select, 你讀取過的資料, 再次讀取出來發現值不一樣了
幻讀的重點在于新增或者洗掉:
同樣的條件的select, 第1次和第2次讀出來的記錄數不一樣
從結果上來看, 兩者都是為多次讀取的結果不一致,但如果你從實作的角度來看, 它們的區別就比較大:
對于前者, 在RC下只需要鎖住滿足條件的記錄,就可以避免被其它事務修改,也就是 select for update, select in share mode; RR隔離下使用MVCC實作可重復讀;
對于后者, 要鎖住滿足條件的記錄及所有這些記錄之間的gap,也就是需要 gap lock,
而ANSI SQL標準沒有從隔離程度進行定義,而是定義了事務的隔離級別,同時定義了不同事務隔離級別解決的三大并發問題:
| Isolation Level | Dirty Read | Unrepeatable Read | Phantom Read |
| Read UNCOMMITTED | YES | YES | YES |
| READ COMMITTED | NO | YES | YES |
| READ REPEATABLE | NO | NO | YES |
| SERIALIZABLE | NO | NO | NO |
4. 資料庫的默認隔離級別
除了MySQL默認采用RR隔離級別之外,其它幾大資料庫都是采用RC隔離級別,
但是他們的實作也是極其不一樣的,Oracle僅僅實作了RC 和 SERIALIZABLE隔離級別,默認采用RC隔離級別,解決了臟讀,但是允許不可重復讀和幻讀,其SERIALIZABLE則解決了臟讀、不可重復讀、幻讀,
MySQL的實作:MySQL默認采用RR隔離級別,SQL標準是要求RR解決不可重復讀的問題,但是因為MySQL采用了gap lock,所以實際上MySQL的RR隔離級別也解決了幻讀的問題,那么MySQL的SERIALIZABLE是怎么回事呢?其實MySQL的SERIALIZABLE采用了經典的實作方式,對讀和寫都加鎖,
5. MySQL 中RC和RR隔離級別的區別
MySQL資料庫中默認隔離級別為RR,但是實際情況是使用RC 和 RR隔離級別的都不少,好像淘寶、網易都是使用的 RC 隔離級別,那么在MySQL中 RC 和 RR有什么區別呢?我們該如何選擇呢?為什么MySQL將RR作為默認的隔離級別呢?
5.1 RC 與 RR 在鎖方面的區別
1> 顯然 RR 支持 gap lock(next-key lock),而RC則沒有gap lock,因為MySQL的RR需要gap lock來解決幻讀問題,而RC隔離級別則是允許存在不可重復讀和幻讀的,所以RC的并發一般要好于RR;
2> RC 隔離級別,通過 where 條件過濾之后,不符合條件的記錄上的行鎖,會釋放掉(雖然這里破壞了“兩階段加鎖原則”);但是RR隔離級別,即使不符合where條件的記錄,也不會是否行鎖和gap lock;所以從鎖方面來看,RC的并發應該要好于RR;另外 insert into t select ... from s where 陳述句在s表上的鎖也是不一樣的,
2563 2048 + 512 + 3
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/61347.html
標籤:其他
上一篇:資料庫系統及原理 筆記