將最近遇到的一個業務場景進行抽象,希望能有高手指點。(可以通過存盤程序實作,這里求教非回圈的實作方式)排序規則如下:
對于發生時間相同的幾組事件,與這個時間前一時間屬于相同方的事件,排在前面。
一組簡單的事例:
時間 隊
A A
B B
B A
C A
C B
排序的結果應該為:
時間 隊
A A
B A
B B
C B
C A
uj5u.com熱心網友回復:
沒 oracle 環境, 用 sqlserver 做了一個, 不過思路一樣, 你參照著改一下就好。USE tempdb
GO
IF OBJECT_ID('t') IS NOT NULL DROP TABLE t
GO
CREATE TABLE t(
tt VARCHAR(10),
seq VARCHAR(10)
)
GO
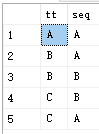
INSERT INTO t VALUES ('A','A')
INSERT INTO t VALUES ('B','B')
INSERT INTO t VALUES ('B','A')
INSERT INTO t VALUES ('C','A')
INSERT INTO t VALUES ('C','B')
---------- 以上為測驗表及測驗資料 ----------------
;WITH cte AS (
SELECT ROW_NUMBER() OVER (ORDER BY tt) AS rid,tt FROM t GROUP BY tt
),cte2 AS (
SELECT a.*,b.tt AS upTT FROM cte AS a LEFT JOIN cte AS b ON a.rid=b.rid+1
)
SELECT *
FROM t
ORDER BY
tt
,CASE WHEN EXISTS(
SELECT 1 FROM cte2 WHERE cte2.tt=t.tt AND cte2.upTT=t.seq
) THEN 0 ELSE 1 END,seq
uj5u.com熱心網友回復:
沒說清楚啊,如果資料是
時間 隊
A D
A B
A C
B A
B C
B D
該如何排序?
uj5u.com熱心網友回復:
隊那一列只有兩種可能,我抽象出了最原始的情況。抱歉哈uj5u.com熱心網友回復:
看了一上思路,是在CTE陳述句中進行關聯查詢,怎么沒想到呢。謝謝啦,馬上嘗試一下,有訊息了告訴您。謝謝謝謝uj5u.com熱心網友回復:
您好,可能我在具體抽象中表述的不太準確了。我看您在最后排序時,tt列與seq列進行了關聯。而實際中,tt列是一系列的復雜情況,比如具體的時間(我實際的業務需求是就是解決同時發生的事件排序問題),沒有這類簡單的對應關系。您看是否可以解決?uj5u.com熱心網友回復:
麻煩貼一下完整可行的測驗資料腳本吧, 可以保證按你的腳本資料做出來, 你正式的就可以用的uj5u.com熱心網友回復:
好的,我截取了三分鐘以內的資料。主要是解決對同時發生的事件進行排序的問題,對同時的事件,與前一組事件距離近的在前;距離相同的,與前一組事件的最后一個事件屬于同一隊的在前。難點在于后一組排序會依賴于前一組的排序結果,比如對0分10秒、0分12秒的結果。(對于同一時間有三個時間的,需要結合距離之類的計算,我覺得思路一致,)現只麻煩您看一下,能否解決時間相同的,與前一組事件最后一個屬于同一隊的,排在前面這個難點吧。麻煩了
CREATE TABLE table_order (
"team_id" varchar(255) COLLATE "default",
"minute" varchar(255) COLLATE "default",
"second" varchar(255) COLLATE "default",
"x" varchar(255) COLLATE "default",
"y" varchar(255) COLLATE "default",
"end_x" varchar(255) COLLATE "default",
"end_y" varchar(255) COLLATE "default"
)WITH (OIDS=FALSE);
INSERT INTO table_order VALUES ('26', '0', '1', '52.605', '34.68', '55.755', '33.116');
INSERT INTO table_order VALUES ('26', '0', '10', '41.58', '52.496', NULL, NULL);
INSERT INTO table_order VALUES ('26', '0', '15', '24.465', '43.112', NULL, NULL);
INSERT INTO table_order VALUES ('26', '0', '16', '24.465', '43.112', '26.46', '18.02');
INSERT INTO table_order VALUES ('26', '0', '19', '28.77', '17.136', '44.52', '5.576');
INSERT INTO table_order VALUES ('26', '0', '2', '55.755', '33.116', '48.51', '37.06');
INSERT INTO table_order VALUES ('26', '0', '21', '44.415', '5.644', '48.3', '16.796');
INSERT INTO table_order VALUES ('26', '0', '22', '48.3', '16.796', NULL, NULL);
INSERT INTO table_order VALUES ('26', '0', '29', '49.35', '40.936', NULL, NULL);
INSERT INTO table_order VALUES ('26', '0', '3', '48.51', '37.06', '33.81', '57.392');
INSERT INTO table_order VALUES ('26', '0', '4', '33.81', '57.392', '23.73', '41.548');
INSERT INTO table_order VALUES ('26', '0', '5', '23.73', '41.548', '33.6', '41.548');
INSERT INTO table_order VALUES ('26', '0', '53', '47.04', '16.184', NULL, NULL);
INSERT INTO table_order VALUES ('26', '0', '54', '45.045', '19.244', '73.92', '17.816');
INSERT INTO table_order VALUES ('26', '0', '58', '62.37', '16.116', '76.125', '9.724');
INSERT INTO table_order VALUES ('26', '0', '6', '33.81', '42.024', '23.31', '44.88');
INSERT INTO table_order VALUES ('26', '0', '9', '23.94', '46.308', '42.735', '50.184');
INSERT INTO table_order VALUES ('26', '1', '11', '80.22', '0', '76.44', '3.196');
INSERT INTO table_order VALUES ('26', '1', '13', '76.44', '3.196', '79.905', '1.564');
INSERT INTO table_order VALUES ('26', '1', '14', '79.905', '1.564', '69.93', '1.972');
INSERT INTO table_order VALUES ('26', '1', '16', '69.93', '1.972', '56.91', '4.76');
INSERT INTO table_order VALUES ('26', '1', '19', '56.28', '11.832', '46.83', '33.184');
INSERT INTO table_order VALUES ('26', '1', '2', '82.635', '13.668', '82.845', '15.3');
INSERT INTO table_order VALUES ('26', '1', '22', '55.755', '41.004', '63.315', '43.452');
INSERT INTO table_order VALUES ('26', '1', '26', '64.575', '48.756', NULL, NULL);
INSERT INTO table_order VALUES ('26', '1', '52', '70.035', '39.984', '94.5', '35.496');
INSERT INTO table_order VALUES ('26', '1', '58', '87.465', '65.688', NULL, NULL);
INSERT INTO table_order VALUES ('26', '2', '13', '76.23', '50.796', '74.445', '37.264');
INSERT INTO table_order VALUES ('26', '2', '16', '73.71', '35.292', '73.395', '18.632');
INSERT INTO table_order VALUES ('26', '2', '18', '73.29', '17.816', '78.54', '1.904');
INSERT INTO table_order VALUES ('26', '2', '22', '79.59', '4.828', '79.59', '6.596');
INSERT INTO table_order VALUES ('26', '2', '27', '81.48', '0', '92.4', '3.604');
INSERT INTO table_order VALUES ('26', '2', '28', '92.4', '3.604', '85.575', '0');
INSERT INTO table_order VALUES ('26', '2', '3', '87.255', '68', '79.065', '63.376');
INSERT INTO table_order VALUES ('26', '2', '4', '79.065', '63.376', '85.365', '65.416');
INSERT INTO table_order VALUES ('26', '2', '45', '69.825', '32.776', NULL, NULL);
INSERT INTO table_order VALUES ('26', '2', '47', '74.235', '31.348', '77.28', '29.92');
INSERT INTO table_order VALUES ('26', '2', '51', '74.655', '18.36', '68.565', '25.568');
INSERT INTO table_order VALUES ('26', '2', '53', '68.565', '25.568', '80.01', '25.16');
INSERT INTO table_order VALUES ('26', '2', '54', '80.01', '25.16', '78.855', '29.104');
INSERT INTO table_order VALUES ('26', '2', '55', '78.96', '29.308', '79.8', '24.48');
INSERT INTO table_order VALUES ('26', '2', '56', '79.485', '27.676', '75.81', '19.244');
INSERT INTO table_order VALUES ('26', '2', '58', '75.81', '19.04', '101.535', '12.376');
INSERT INTO table_order VALUES ('26', '2', '7', '83.16', '59.84', '77.595', '52.496');
INSERT INTO table_order VALUES ('26', '2', '9', '77.595', '52.564', '84.525', '63.58');
INSERT INTO table_order VALUES ('26', '3', '14', '85.365', '0', '85.995', '9.384');
INSERT INTO table_order VALUES ('26', '3', '19', '91.035', '15.708', '90.3', '30.736');
INSERT INTO table_order VALUES ('26', '3', '2', '101.43', '12.376', '90.825', '28.016');
INSERT INTO table_order VALUES ('26', '3', '23', '74.865', '46.308', '70.875', '37.876');
INSERT INTO table_order VALUES ('26', '3', '25', '70.875', '39.168', '98.385', '56.576');
INSERT INTO table_order VALUES ('26', '3', '30', '99.75', '49.368', NULL, NULL);
INSERT INTO table_order VALUES ('26', '3', '44', '40.95', '68', '51.765', '66.028');
INSERT INTO table_order VALUES ('26', '3', '45', '51.765', '66.028', '38.01', '63.444');
INSERT INTO table_order VALUES ('26', '3', '46', '38.01', '63.444', NULL, NULL);
INSERT INTO table_order VALUES ('26', '3', '47', '50.505', '55.624', '69.3', '48.348');
INSERT INTO table_order VALUES ('26', '3', '49', '56.805', '45.56', '62.055', '68');
INSERT INTO table_order VALUES ('26', '3', '7', '85.785', '6.46', NULL, NULL);
INSERT INTO table_order VALUES ('96', '0', '10', '41.58', '52.496', NULL, NULL);
INSERT INTO table_order VALUES ('96', '0', '12', '32.76', '53.788', '27.72', '51.204');
INSERT INTO table_order VALUES ('96', '0', '12', '32.76', '53.788', NULL, NULL);
INSERT INTO table_order VALUES ('96', '0', '14', '27.93', '50.864', NULL, NULL);
INSERT INTO table_order VALUES ('96', '0', '22', '49.14', '18.36', NULL, NULL);
INSERT INTO table_order VALUES ('96', '0', '23', '45.15', '19.788', NULL, NULL);
INSERT INTO table_order VALUES ('96', '0', '24', '45.045', '22.508', '46.2', '29.648');
INSERT INTO table_order VALUES ('96', '0', '25', '46.2', '29.648', '49.245', '27.676');
INSERT INTO table_order VALUES ('96', '0', '26', '49.35', '27.88', '47.145', '37.672');
INSERT INTO table_order VALUES ('96', '0', '29', '49.35', '40.936', NULL, NULL);
INSERT INTO table_order VALUES ('96', '0', '38', '50.19', '40.392', '57.855', '23.528');
INSERT INTO table_order VALUES ('96', '0', '40', '58.065', '23.528', '62.37', '8.976');
INSERT INTO table_order VALUES ('96', '0', '43', '64.785', '14.28', '99.96', '17.204');
INSERT INTO table_order VALUES ('96', '0', '49', '97.65', '13.056', '49.035', '13.192');
INSERT INTO table_order VALUES ('96', '0', '53', '47.04', '16.184', NULL, NULL);
INSERT INTO table_order VALUES ('96', '0', '56', '78.54', '15.232', '68.775', '11.764');
INSERT INTO table_order VALUES ('96', '0', '58', '68.775', '11.764', '63.945', '13.056');
INSERT INTO table_order VALUES ('96', '1', '26', '64.575', '48.756', NULL, NULL);
INSERT INTO table_order VALUES ('96', '1', '3', '85.05', '15.028', NULL, NULL);
INSERT INTO table_order VALUES ('96', '1', '53', '95.025', '41.344', NULL, NULL);
INSERT INTO table_order VALUES ('96', '1', '57', '90.93', '52.768', NULL, NULL);
INSERT INTO table_order VALUES ('96', '1', '58', '87.465', '65.688', NULL, NULL);
INSERT INTO table_order VALUES ('96', '2', '22', '78.225', '8.296', NULL, NULL);
INSERT INTO table_order VALUES ('96', '2', '40', '83.16', '0', '66.99', '12.172');
INSERT INTO table_order VALUES ('96', '2', '41', '66.99', '12.172', '75.285', '2.38');
INSERT INTO table_order VALUES ('96', '2', '42', '74.76', '2.38', '69.3', '28.084');
INSERT INTO table_order VALUES ('96', '2', '48', '79.695', '26.588', NULL, NULL);
INSERT INTO table_order VALUES ('96', '2', '52', '80.22', '16.796', NULL, NULL);
INSERT INTO table_order VALUES ('96', '2', '55', '80.955', '21.012', NULL, NULL);
INSERT INTO table_order VALUES ('96', '3', '20', '89.145', '35.224', NULL, NULL);
INSERT INTO table_order VALUES ('96', '3', '3', '89.985', '30.124', NULL, NULL);
INSERT INTO table_order VALUES ('96', '3', '30', '97.125', '49.776', NULL, NULL);
INSERT INTO table_order VALUES ('96', '3', '30', '99.75', '49.368', NULL, NULL);
INSERT INTO table_order VALUES ('96', '3', '32', '91.56', '51.748', '67.2', '68');
INSERT INTO table_order VALUES ('96', '3', '46', '41.055', '63.512', NULL, NULL);
INSERT INTO table_order VALUES ('96', '3', '47', '61.11', '51.408', NULL, NULL);
INSERT INTO table_order VALUES ('96', '3', '8', '84', '11.968', NULL, NULL);
uj5u.com熱心網友回復:
實際資料看著好亂,我就直接拿開始的例子寫了。with tab1 as (
select 'A' a, 'A' b from dual union all
select 'B' a, 'B' b from dual union all
select 'B' a, 'A' b from dual union all
select 'C' a, 'A' b from dual union all
select 'C' a, 'B' b from dual
)
, tab2 as (
select a, b, dense_rank() over(order by a) dr from tab1)
select a, b
from tab2
order by a, decode(b, first_value(a) over(order by dr range between 1 preceding and 0 following), 1, 2), b
;
oracle中能直接用分析函式解決的還是不要自連接比較好,效率一般會快很多
uj5u.com熱心網友回復:
理解了下您的思路,還是通過取當前組的前一行值來實作。那我這個需求的難點在于,如果上一組的排序結果發生變動了,會對下一組排序結果產生影響。比如,如果第一組的值,隊對應的變為B,則相應的,下面的排序都需要跟著變動。而我理解,分析函式,其分析的依據,應該還是變化前的表格吧uj5u.com熱心網友回復:
看不懂你想要干什么。
“組”是怎么劃分的,與前一組的“距離”是什么,“事件”是什么,“組”內的“事件”是什么規則排序,第一組組內是什么規則排序,“同一隊”指的又是什么。x y end_x end_y都是什么東西。
挑出或者手寫出不超過10條可以涵蓋所有特征的資料,包括“同一時間有三個時間的”,尤其是可以讓人一眼看出你所說的“難點”的資料,并給出預期結果。
uj5u.com熱心網友回復:
我近一步簡化問題吧:按tour_id、second列升序排列,對tour_id、second相同的,根據該記錄對應的team_id與上一組(即與該記錄tour_id,second上一條記錄)相同的排在前面。示例資料如下所示:
tour_id team_id second
1 26 9
1 96 10
1 26 10
1 26 12
1 96 12
1 26 19
1 96 22
1 26 22
2 26 9
2 16 10
2 26 10
2 26 12
2 16 12
2 26 19
2 16 22
2 26 22
************************************
想要的結果:
tour_id team_id second
1 26 9
1 26 10
1 96 10
1 96 12
1 26 12
1 26 19
1 26 22
1 96 22
2 26 9
2 26 10
2 16 10
2 16 12
2 26 12
2 26 19
2 26 22
2 16 22
uj5u.com熱心網友回復:
with tab1 as (
select 1 tour_id, 26 team_id, 9 sec from dual union all
select 1 , 96 , 10 from dual union all
select 1 , 26 , 10 from dual union all
select 1 , 26 , 12 from dual union all
select 1 , 96 , 12 from dual union all
select 1 , 26 , 19 from dual union all
select 1 , 96 , 22 from dual union all
select 2 , 26 , 9 from dual union all
select 2 , 10 , 10 from dual
)
select *
from tab1 t1
model
dimension by(
dense_rank() over(order by t1.tour_id, sec) dr,
row_number() over(partition by t1.tour_id, sec order by team_id desc) rn)
measures(-1 ord, tour_id, team_id, sec)
rules automatic order(
ord[dr, rn] order by dr, rn = decode(team_id[cv(), cv()], team_id[cv() - 1, 1], 1, 2)
)
order by dr, ord, rn
;
uj5u.com熱心網友回復:
謝謝您的回復,看您用了些非標準SQL的內容,我好好消化一下。不管能不能理解吧,感謝您的回復uj5u.com熱心網友回復:
又仔細看了一下,有點bug,應該這么寫
with tab1 as (
select 1 tour_id, 13 team_id, 9 sec from dual union all
select 1 , 26 , 9 from dual union all
select 1 , 96 , 10 from dual union all
select 1 , 26 , 10 from dual union all
select 1 , 26 , 12 from dual union all
select 1 , 96 , 12 from dual union all
select 1 , 13 , 19 from dual union all
select 1 , 26 , 19 from dual union all
--select 1 , 96 , 20 from dual union all
select 1 , 133 , 22 from dual union all
select 1 , 96 , 22 from dual union all
select 2 , 26 , 9 from dual union all
select 2 , 10 , 10 from dual
)
select *
from tab1 t1
model
dimension by(
dense_rank() over(order by t1.tour_id, sec) dr,
row_number() over(partition by t1.tour_id, sec order by team_id ) rn)
measures(-1 ord, tour_id, team_id, sec)
rules automatic order(
--ord[dr, rn] order by dr, rn = decode(team_id[cv(), cv()], team_id[cv() - 1, 1], 1, 2)
ord[dr, rn] order by dr, rn =
case when team_id[cv(), cv()] = max(decode(ord, 1, -99999999, team_id))[cv() - 1, rn]
then 1 else 2 end
)
order by dr, ord, rn
;
這種真遞回的需求要是能用標準sql的select陳述句寫出來,請一定要@我。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/62137.html
標籤:高級技術
上一篇:實體已創建。DIM-00019:創建服務時出錯 O/S-Error:(OS1053)服務沒有及時回應啟動或控制請求