導讀
-
相信讀者看過很多MYSQL索引優化的文章,其中有很多優化的方法,比如最佳左前綴,覆寫索引等方法,但是你真正理解為什么要使用最佳左前綴,為什么使用覆寫索引會提升查詢的效率嗎?
-
本篇文章將從MYSQL內部結構上講一下為什么覆寫索引能夠提升效率,
InnoDB索引模型
-
在InnoDB中,表都是根據主鍵順序以索引的形式存放的,這種存盤方式的表稱為索引組織表,又因為前面我們提到的,InnoDB使用了B+樹索引模型,所以資料都是存盤在B+樹中的,
-
每一個索引在InnoDB里面對應一棵B+樹,
主鍵索引和非主鍵索引的區別
-
主鍵索引又叫聚簇索引 ,非主鍵索引又叫普通索引,那么這兩種索引有什么區別呢?
-
主鍵索引的葉子節點存放的是整行資料,非主鍵索引的葉子節點存放的是主鍵的值,
-
假設有一張User表(id,age,name,address),其中有id和age兩個欄位,其中id是主鍵,age是普通索引,有幾行資料u1-u5的(id,age)的值是(100,1)、(200,2)、(300,3)、(500,5)和(600,6) ,此時的兩棵樹的示例如下:
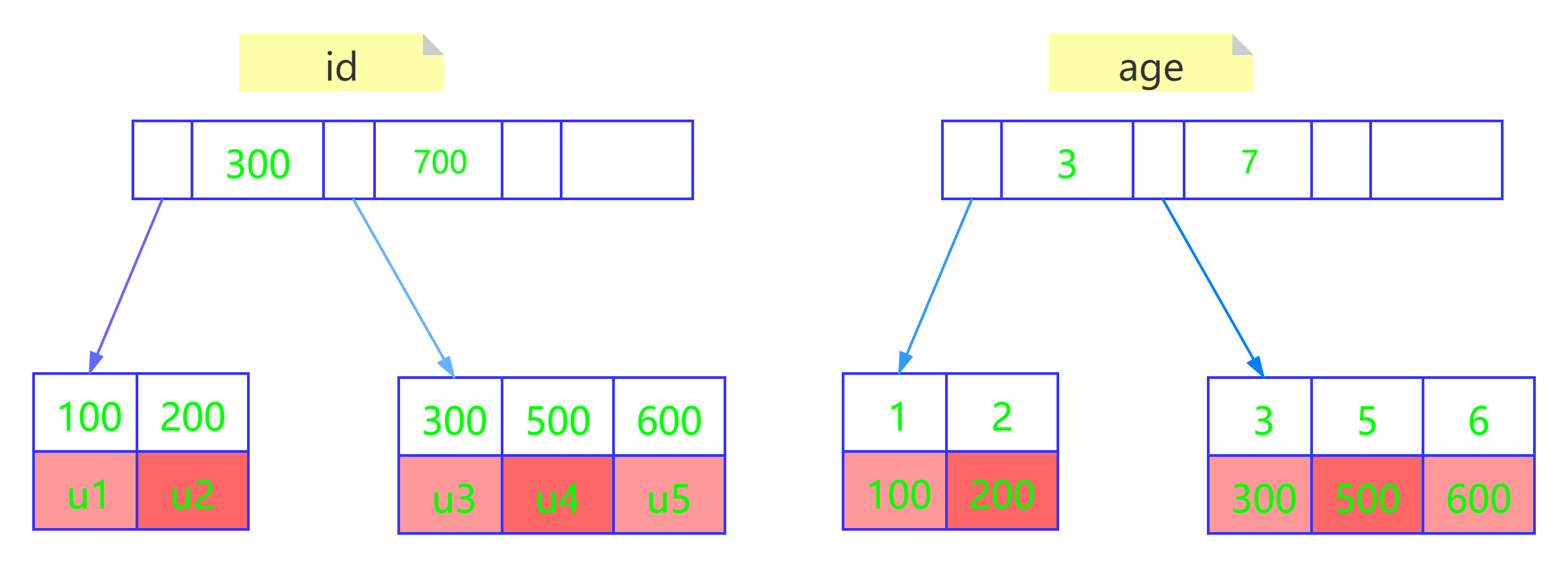
-
從上圖可以看出來,基于主鍵索引的樹的葉子節點存放的是整行User資料,基于普通索引age的葉子節點存放的是id(主鍵)的值,
什么是回表?
-
假設有一條查詢陳述句如下:
select * from user where age=3;
-
上面這條sql陳述句執行的程序如下:
1、根據age這個普通索引在age索引樹上搜索,得到主鍵id的值為300,
2、因為age索引樹并沒有存盤User的全部資料,因此需要根據在age索引樹上查詢到的主鍵id的值300再到id索引樹搜索一次,查詢到了u3,
3、回傳結果,
-
上述執行的程序中,從age索引樹再到id索引樹的查詢的程序叫做回表(回到主鍵索引樹搜索的程序),
-
也就是說通過非主鍵索引的查詢需要多掃描一棵索引樹,因此需要盡量使用主鍵索引查詢,
為什么使用覆寫索引?
-
有了上述提及到的幾個概念,便能很清楚的理解為什么覆寫索引能夠提升查詢效率了,因為少了一次回表的程序,
-
假設我們使用覆寫索引查詢,陳述句如下:
select id from user where age=3;
-
這條陳述句執行程序很簡單,直接在age索引樹中就能查詢到id的值,不用再去id索引樹中查找其他的資料,避免了回表,
總結
-
覆寫索引的使用能夠減少樹的搜索次數,避免了回表,顯著提升了查詢性能,因此覆寫索引是一個常用的性能優化手段,
-
留給讀者一個問題:身份證是一個人的唯一識別憑證,如果有根據身份證號查詢市民資訊的需求,我們只要在身份證號欄位上建立索引就夠了,而再建立一個(身份證號、姓名)的聯合索引,是不是浪費空間?
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/64466.html
標籤:MySQL
上一篇:簡單SQL陳述句
下一篇:Java系列——基礎編程題