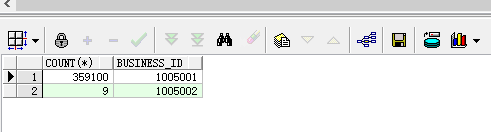
select count(*),business_id from tb_smp_sms_history_201409 t where latn_id=919 and business_id in(1005001,1005002,1005003) group by business_id
uj5u.com熱心網友回復:
business_id in(1005001,1005002,1005003) 這個只是個條件通過這個找到需要匯總的記錄,之后就和這個條件沒有關系了
表中資料 不存在 1005003的記錄,group的時候自然不會出現在結果中
uj5u.com熱心網友回復:
這樣啊 那怎么把這條空記錄 這樣顯示出來0 1005003
uj5u.com熱心網友回復:
我把count(*)改成nvl(count(*),0)這樣還是沒第3條記錄uj5u.com熱心網友回復:
-- 這個必使用外連接的方式,機器可不知道你要顯示條件中那三個數值。
with mt as (
select 1005001 c from dual
union all
select 1005002 from dual
union all
select 1005003 from dual
)
select mt.c , count(*)
from mt left join tb_smp_sms_history_201409 t on business_id = mt.c
where latn_id=919
group by mt.c
uj5u.com熱心網友回復:
union all ...........uj5u.com熱心網友回復:
有沒有類似的編碼表:business_id用business_id的編碼表和你的查詢陳述句左連接:
select a.business_id,nvl(b.b1,0) 合計
from 標碼表 a left join
(select count(*) b1,business_id from tb_smp_sms_history_201409 t where latn_id=919 and business_id in(1005001,1005002,1005003) group by business_id ) b
on a.business_id=b.business_id
group by a.business_id
;
uj5u.com熱心網友回復:
這有矛盾吧 ,既然是group 和count 只有 有記錄的才會進行groupby 所以,count(*) 最少為1 啊,怎么可能會有0的記錄
uj5u.com熱心網友回復:
樓上說的不錯,既然要group by那么沒有的在分組的時候就不會被統計了。
uj5u.com熱心網友回復:
6樓說法正確uj5u.com熱心網友回復:
設計表的時候 應該是有business_id 這個欄位的主表吧,先 select主表 然后 leap join tb_smp_sms_history_201409 group by business_iduj5u.com熱心網友回復:
何必糾結,復制出來 execl加上1005003 為 0 。
uj5u.com熱心網友回復:
你的(latn_id=919 and business_id=1005003)=false吧非要顯示的話
select a.business_id, nvi(b.cnt,0) as cnt
from (select business_id
from tb_smp_sms_history_201409 t
where business_id in (1005001, 1005002, 1005003)) a,
(select count(*) as cnt, business_id
from tb_smp_sms_history_201409 t
where latn_id = 919
and business_id in (1005001, 1005002, 1005003)
group by business_id) b
where a.business_id = b.business_id
不過其實從統計角度看,這個不存在的值根本就沒意義
uj5u.com熱心網友回復:
樓上說的很對,
uj5u.com熱心網友回復:
上面說的 union all 的方法不錯。下面這樣把 union all 放面,或者我們把默認的 0 與 count() /group 的結果 union all一起再 sum 一次。
select sum(cnt) as cnt, business_id
from (
select 0 as cnt, 1005001 as business_id from dual
union all
select 0 as cnt, 1005002 as business_id from dual
union all
select 0 as cnt, 1005003 as business_id from dual
union all
select 1 as cnt,business_id
from tb_smp_sms_history_201409 t
where latn_id=919 and business_id in(1005001,1005002,1005003)
) a
group by business_id
uj5u.com熱心網友回復:
其實這個問題后面是對 SQL 陳述句的執行次序的理解:一條普通的 select 陳述句,
首先是從 from 部分開始執行的,
然后是可選的 join 部分
然后是 where 部分
最早執行的肯定是 SQL 中的 "選擇運算”,
select 后面的是最后執行,它是投影運算。
選擇運算沒有命中的記錄,不會被投影運算處理的。
因此在 where 條件沒有命中的記錄,不會被 group by 處理,自然也就沒有 0 這個占位子家伙了。
uj5u.com熱心網友回復:
SELECTt.business_id,
IFNULL(t.num, 0)
FROM
(
(SELECT DISTINCT
business_id
FROM
tb_smp_sms_history_201409
WHERE business_id IN (1005001, 1005002, 1005003)) a
LEFT JOIN
(SELECT
COUNT(*) AS num,
business_id
FROM
tb_smp_sms_history_201409 t
WHERE latn_id = 919
AND business_id IN (1005001, 1005002, 1005003)
GROUP BY business_id) b
ON a.business_id = b.business_id
) t
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/65070.html
標籤:基礎和管理