對于資料庫,優化查詢的方法
1.使用索引
使用索引時,應盡量避免全表掃描,首先應考慮在 where 及 order by ,group by 涉及的列上建立索引,
2.優化SQL陳述句
1)分析查詢陳述句:通過對查詢陳述句的分析,可以了解查詢陳述句執行情況,找出查詢陳述句執行的瓶頸,從而優化查詢陳述句,
通過explain(查詢優化神器)用來查看SQL陳述句的執行結果,可以幫助選擇更好的索引和優化查詢陳述句,寫出更好的優化陳述句,
例如:explain select * from news;
2)任何地方都不要使用select * from t ,用具體的欄位串列代替“*”,不要回傳用不到的任何欄位,
3)不在索引列做運算或者使用函式,
4)查詢盡可能使用 limit 減少回傳的行數,減少資料傳輸時間和帶寬浪費,
3.優化資料庫物件
1)優化表的資料型別
使用 procedure analyse()函式對表進行分析,該函式可以對表中列的資料型別提出優化建議,表資料型別第一個原則是:使用能正確地表示和存盤資料的最短型別,這樣可以減少對磁盤空間、記憶體、CPU快取的使用,
使用方法:select * from 表名 procedure analyse();
2)對表進行拆分
通過拆分表可以提高表的訪問效率,有兩種拆分方法:
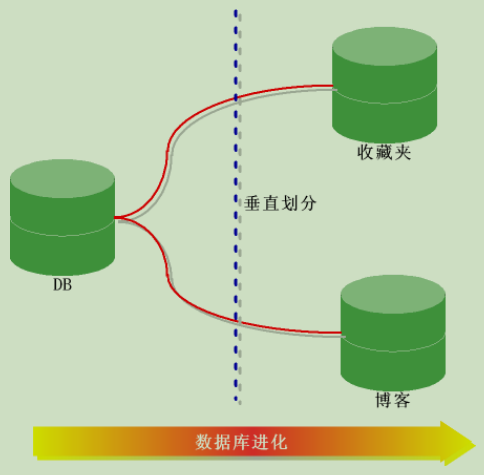
a.垂直拆分(按照功能模塊)
將表按照功能模塊、關系密切程度劃分出來,部署到不同的庫上,例如:我們會建立定義資料庫workDB、商品資料庫payDB、用戶資料庫userDB等,分別用于存盤專案資料定義表、商品定義表、用戶資料表等,
把主鍵和一些列放在一個表中,然后把主鍵和另外的列放在零一個表中,如果一個表中某些列常用,而另外一個些不常用,則可以采用垂直拆分,
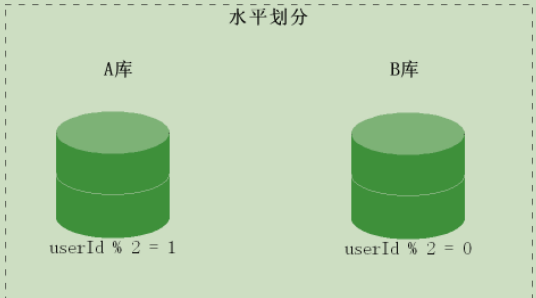
b.水平拆分(按照規則劃分存盤)
當一個表中的資料量過大時,我們可以把該表的資料按照某種規則進行劃分,例如userID散列,然后存盤到多個結構相同的表和不同的庫中,
根據一列或者多列資料的值吧資料行放到兩個獨立的表中,
3)使用中間表來提高查詢速度
創建中間表,表結構和源表結構完全相同,轉移要統計的資料到中間表,然后在中間表上進行統計,得出想要的結果,
4.硬體優化
1)CPU優化
選擇多核和主頻高的CPU,
2)記憶體的優化
使用更大的記憶體,將盡量多的記憶體分配給MySQL做快取,
3)磁盤I/O的優化
a.使用磁盤陣列
RAID 0沒有資料冗余,沒有資料校驗的磁盤陳列,實作RAID 0至少需要兩塊以上的硬碟,它將兩塊以上的硬碟合并成一塊,資料連續地分割在每塊盤上,
RAID 1是將一個兩塊硬碟所構成RAID硬碟陣列,其容量僅等于一塊硬碟的容量,因為另一塊只是當作資料“鏡像”,
使用RAID-0+1磁盤陣列,RAID 0+1是RAID 0和RAID 1的組合形式,它在提供與RAID 1一樣的資料安全保障的同時,也提供了與RAID 1近似的存盤性能,
b.調整磁盤調度演算法
選擇合適的磁盤調度演算法,可以減少磁盤的尋道時間,
5.MySQL自身的優化
對MySQL自身的優化主要是對其組態檔my.cnf中的各項引數進行優化調整,如指定MySQL查詢緩沖區的大小,指定MySQL允許的最大連接行程數等,
6.應用優化
1)使用資料庫連接池
2)實用查詢快取
它的作用是存盤 select 查詢的文本及其相應結果,如果隨后收到一個相同的查詢,服務器會從查詢快取中直接得到查詢結果,查詢快取適用的物件是更新不頻繁的表,當表中資料更改后,查詢快取中的相關條目就會被清空,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/66591.html
標籤:MySQL