第一個就是使用優化查詢的方法,這個在前期的內容中有具體說明,這里不再做說明,
第二、這里簡要說明一個以下幾個方法:
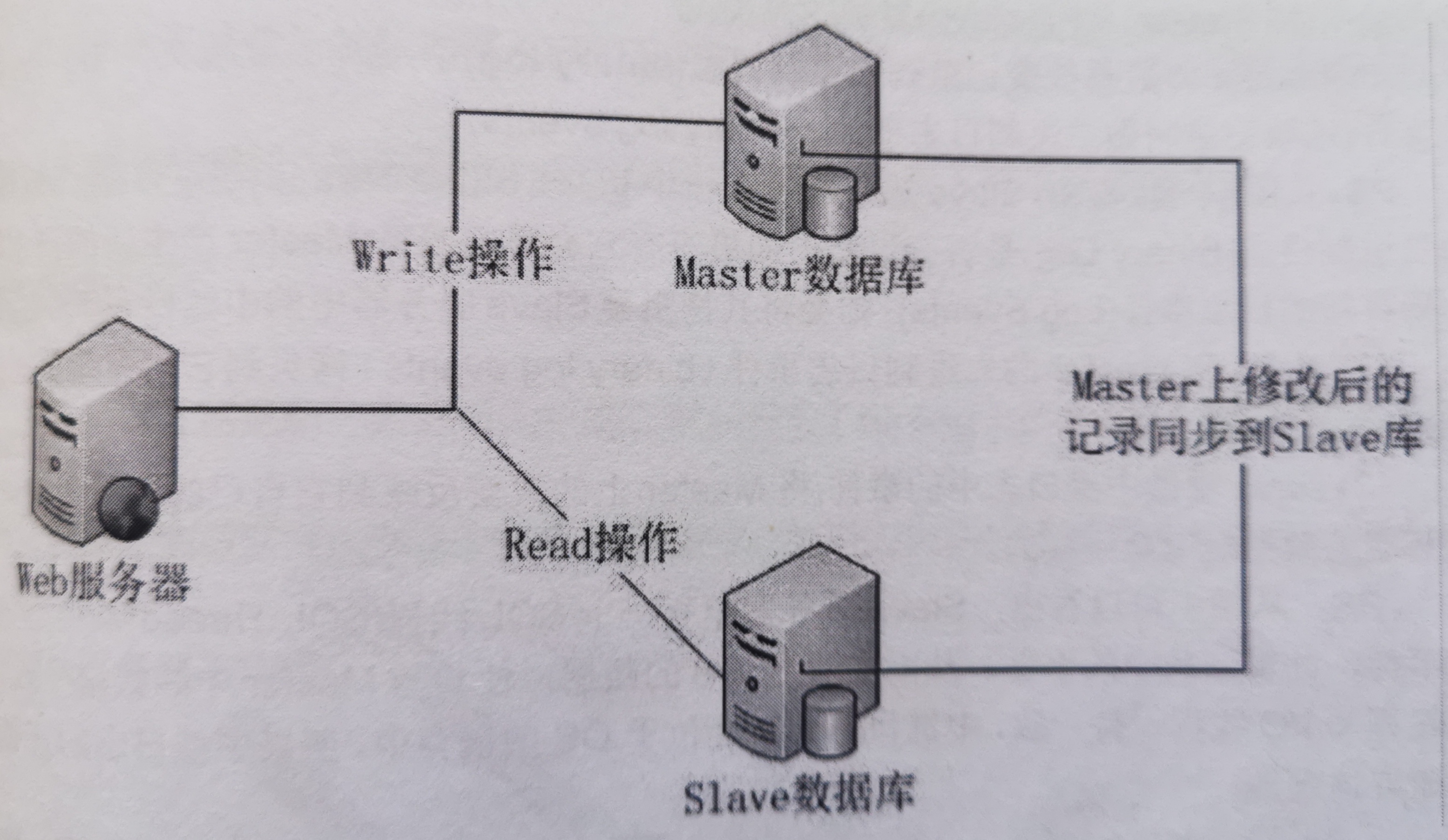
主從復制、讀寫分離、負載均衡
目前,大部分的主流關系型資料庫都提供了主從復制的功能,通過配置兩臺(或多臺)資料庫的主從關系,可以將一臺資料庫服務器的資料更新同步到另一臺服務器上,網站可以利用資料庫的這一功能,實作資料庫的讀寫分離,從而改善資料庫的負載壓力,一個系統的讀操作遠遠多于其寫操作,因此寫操作發向master,讀操作發向slaves進行操作(簡單的輪循演算法來決定使用哪個slave),
利用資料庫的讀寫分離,web服務器在寫資料的時候,訪問著資料庫(Master),主資料庫通過主從復制機制將資料更新同步到從資料庫(Slave),這樣web服務器讀資料的時候,就可以通過從資料庫獲得資料,這一方案使得在大量讀操作的web應用可以輕松地讀取資料,而主資料庫也只會承受少量的寫入操作,還可以實作資料熱備份,可謂是一舉兩得的方案,
1.復制的基本原則
MySQL復制是異步的且串行化的;
每個Slave只有一個Master;
每個Slave只有一個唯一的服務器ID;
每個Master可以有多個Slave;
2.一主一從常見配置:
MySQL版本一致且后臺以服務運行;
主從都配置在[mysqld]結點下,都是小寫,主機修改my.ini組態檔,從機修改my.cnf組態檔,因修改過組態檔,請主機+從機都重啟后臺MySQL服務;
主機從機都關閉防火墻;
在Windows主機上建立賬戶并授權slave;
在Linux從機上配置需要復制的主機;
主機新建庫,新建表,insert記錄,從機復制;
通過stop slave 停止從機復制;
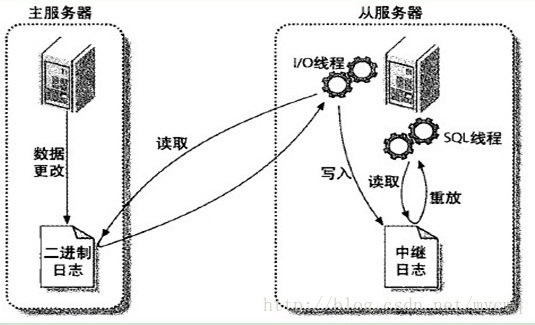
主從復制的原理:
影響MySQL-A資料庫的操作,在資料庫執行后,都會寫入本地的日志系統A中,假設,實時的將變化了的日志系統中的資料庫事件操作,通過網路發給MySQL-B,MySQL-B收到后,寫入本地日志系統B,然后一條條地將資料庫事件在資料庫中完成,那么MySQL-A的變化,MySQL-B也會變化,這樣就是所謂的MySQL的復制,
在上面的模型中,MySQL-A就是主服務器,即master,MySQL-B就是從服務器,即slave,
日志系統A,其實它是MySQL的日志型別的二進制日志,也就是專門用來保存修改資料庫的所有動作,即bin log,【注意MySQL會在執行陳述句之后,釋放鎖之前,寫入二進制日志,確保事務安全,】
日志系統B,并不是二進制日志,由于它是從MySQL-A的二進制日志復制過來的,并不是自己的資料庫變化產生的,有點接力的感覺,稱為中繼日志,即relay log,
可以發現,通過上面的機制,可以保證MySQL-A和MySQL-B的資料庫資料一致,但是時間上肯定有延遲,即MySQL-B的資料是滯后的,
簡化版:
MySQL主(稱master)從(稱slave)復制的原理:
1.master將資料改變記錄到二進制日志(binary log)中,也即是組態檔log-bin指定的檔案(這些記錄叫做二進制日志事件,binary log events)
PS:從圖中可以看出,Slave服務器中有一個I/O執行緒(I/O Thread)在不停地監聽Master的二進制日志(binary log)是否有更新:如果沒有,它會睡眠等待Master產生新的日志事件;如果有新的日志事件(log events),則會將其拷貝至Slave服務器中的中繼日志(relay log),
2.slave將master的二進制日志事件(binary log events)拷貝到它的中繼日志(relay log),
3.slave重做中繼日志中的事件,將Master上的改變反映到它自己的資料庫中,所以兩端的資料是完全一樣的,
PS:從圖中可以看出,Slave服務器有一個SQL執行緒(SQL Thread)從中繼日志讀取事件,并重做其中的事件,從而更新Slave的資料,使其與Master中的資料一致,只要該執行緒與I/O執行緒保持一致,中繼日志通常會位于OS的快取中,所以中繼日志的開銷很小,
主從復制的幾種方式:
1.同步復制
主服務器在將更新的資料寫入它的二進制日志(binlog)檔案中后,必須等待驗證所有的從服務器的更新資料是否已經復制到其中,之后才可以自由處理其他進入的事務處理請求,
2.異步復制
主服務器在將更新的資料寫入它的二進制日志(binlog)檔案中后,無需等待驗證更新資料是否復制到從服務器中,就可以自由處理其他進入的事務處理請求,
3.半異步復制
主服務器在將更新的資料寫入它的二進制日志(binlog)檔案中后,只需等待驗證其中一臺從服務器的更新資料是否已經復制到其中,就可以自由處理其他進入的事務處理請求,其他的從服務器不用管,
資料庫分表、磁區、分庫
分表見上期描述,
磁區就是把一張表的資料分成多個區塊,這些區塊可以在一個磁盤上,也可以在不同的磁盤上,磁區后,表面上還是一張表,但資料散列在多個位置,這樣一來,多塊硬碟同時處理不同請求,從而提高磁盤IO讀寫性能,實作比較簡單,包括水平磁區和垂直磁區,
分庫是根據業務不同把相關的表且分到不同的資料庫中,比如web、bbs、blog等庫,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/66600.html
標籤:MySQL
上一篇:The SourceSet 'instrumentTest' is not recognized by the Android Gradle Plugin. P