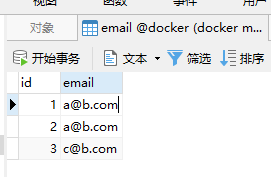
這個是資料
需求是找表中所有重復的電子郵箱
我寫了兩個SQL
SELECT
r.email
FROM
(SELECT
e.email,
count(e.email) as num
FROM
email e
GROUP BY
e.email) r
where
r.num > 1
SELECT
e.email
FROM
email e
GROUP BY
e.email
HAVING
count( e.email ) > 1
比較兩個陳述句的執行效率,發現嵌套查詢使用時間會小于實用Having查詢
問題:為什么嵌套查詢使用時間會小于實用Having查詢
uj5u.com熱心網友回復:
這個要看具體的資料內容和表結構。通常,不主張用HAVING,還可以用加索引的方式提速。
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/66863.html
標籤:MySQL