定義
向前傳播
? 通常,當我們使用神經網路時,我們輸入某個向量x,然后網路產生一個輸出y,這個輸入向量通過每一層隱含層,直到輸出層,這個方向的流動叫做正向傳播,
? 在訓練階段,輸入最后可以計算出一個代價標量J(θ),
反向傳播演算法
? 然后,代價通過反向演算法回傳到網路中,調整權重并計算梯度,未完待續……
分析
? 可能是你們在學校里做過用代數的方法來分析反向傳播,對于普通函式,這很簡單,但當決議法很困難時,我們通常嘗試數值微分,
數值微分
? 由于代數操作很困難,在數值方法中,我們通常使用計算量大的方法,因此經常需要用到計算機,一般有兩種方法,一種是利用近鄰點,另一種是利用曲線擬合,
隨機梯度下降法
? 負責“學習”的演算法,它使用了由反向傳播演算法產生的梯度,
反向傳播演算法
? 然后,反向傳播演算法回傳到網路中,調整權重來計算梯度,一般來說,反向傳播演算法不僅僅適用于多層感知器,它是一個通用的數值微分演算法,可以用來找到任何函式的導數,只要給定函式是可微的,
? 該演算法最重要的特點之一是,它使用了一個相對簡單和廉價的程式來計算微分,提高效率,
如何計算一個代價函式的梯度
? 給定一個函式f,我們想要找到梯度:
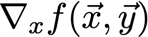
? x是一組我們需要它的導數的變數,y是額外的變數,我們不需要它的導數,
? 為了使網路繼續學習,我們想要找到代價函式的梯度,
損失函式
? 這個函式通常應用于一個資料點,尋找預測點和實際點之間的距離,大多數情況下,這是距離的平方損失,
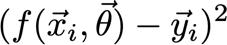
代價函式
? 這個函式是所有損失函式的組合,它不總是一個和,但有時是平均值或加權平均值,例如:
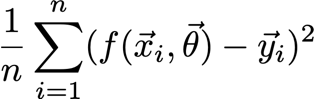
如何計算一個代價函式的梯度
? 給定一個函式f,我們想要找到梯度:
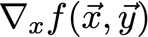
? x是一組我們需要它的導數的變數,y是額外的變數,我們不需要它的導數,
? 為了網路的學習,我們想要找到代價函式的梯度,
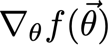
微積分鏈式法則
? 假設x是實數,f和g都是實數到實數的映射函式,此外,
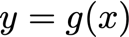
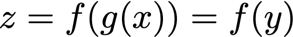
? 根據鏈式法則,
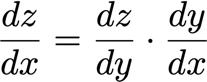
多變數鏈式法則
? 已知x和y是不同維數的向量,

? g和f也是從一個維度映射到另一個維度的函式,

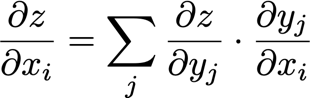
? 或者說,
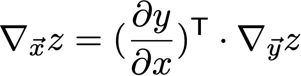
? ?y /?x是g的n×m雅可比矩陣,
梯度
? 而導數或微分是沿一個軸的變化率,梯度是一個函式沿多個軸的斜率矢量,
雅可比矩陣
? 有時我們需要找出輸入和輸出都是向量的函式的所有偏導數,包含所有這些偏導數的矩陣就是雅可比矩陣,
? 有函式
? 雅可比矩陣J為:
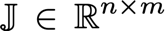
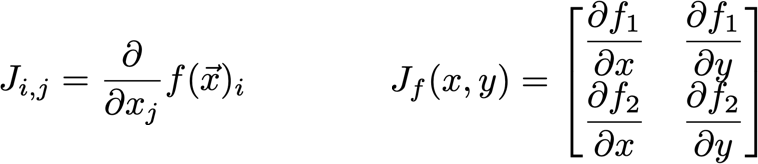
張量的鏈式法則
? 我們大部分時間都在處理高維資料,例如影像和視頻,所以我們需要將鏈式法則擴展到張量,
? 想象一個三維張量,
? z值對這個張量的梯度是,
? 對于這個張量, i?? 指數給出一個向量,
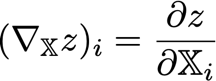
? 所以考慮到這一點,

? 張量的鏈式法則是,
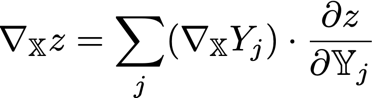
概念
計算圖
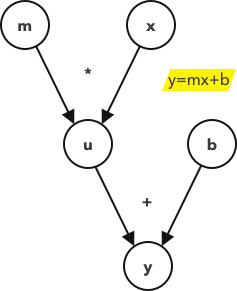
? 這是一個關于直線方程的計算圖的例子,開始節點是你將在方程中看到的,為了計算圖的方便,總是需要為中間節點定義額外的變數,在這個例子中是節點u,節點“u”等價于“mx”,
? 我們引入這個概念來說明復雜的計算流程的支撐演算法,
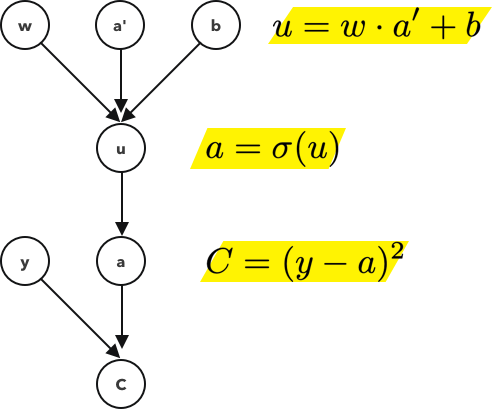
? 還記得之前,當我們把損失函式定義為差的平方,這就是我們在計算圖的最后一層使用的,其中y是實際值a是預測值,

? 請注意,我們的損失值嚴重依賴于最后的激活值,而最后的激活值又依賴于前一個激活值,再依賴于前一個激活值,以此類推,
? 在神經網路的前程序序中,我們最終得到一個預測值a,在訓練階段,我們有一個額外的資訊,這就是網路應該得到的實際結果,y,我們的損失函式就是這些值之間的距離,當我們想要最小化這個距離時,我們首先要更新最后一層的權重,但這最后一層依賴于它的前一層,因此我們更新它們,所以從這個意義上說,我們是在向后傳遞神經網路并更新每一層,
敏感性改變
? 當x的一個小變化導致函式f的一個大變化時,我們說函式對x非常敏感如果x的一個小變化導致f的一個小變化,我們說它不是很敏感,
? 例如,一種藥物的有效性可用f來衡量,而x是所使用的劑量,靈敏度表示為:
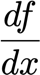
? 為了進一步擴展,我們假設現在的函式是多變數的,
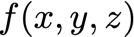
? 函式f可以對每個輸入有不同的敏感度,舉個例子,也許僅僅進行數量分析是不夠的,所以我們把藥物分解成3種活性成分,然后考慮每種成分的劑量,
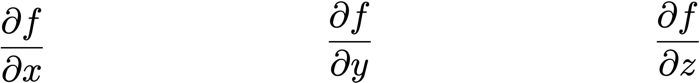
? 最后一點擴展,如果其中一個輸入值,比如x也依賴于它自己的輸入,我們可以用鏈式法則來找出敏感性,同樣的例子,也許x被分解成它在身體里的組成部分,所以我們也要考慮這個,
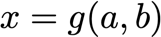
? 我們考慮x的組成,以及它的成分如何影響藥物的整體效果,

? 在這里,我們測量的是整個藥物的效果對藥物中這個小成分的敏感度,
一個簡單的模型
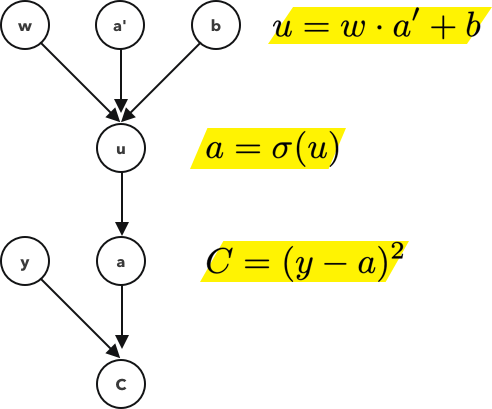
? 這個計算圖考慮了節點a和它前面的節點a '之間的連接,

? 用鏈式法則,
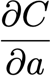
? 它測量了a對u的微小變化有多敏感,然后我們繼續前面的3次計算,
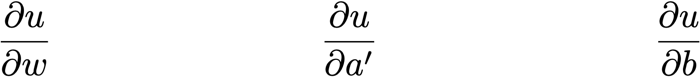
? 測量u對以下每一項的微小變化的敏感度:
-
權重,w
-
之前的激活值,a ’
-
偏質,b
? 把這些放在一起,
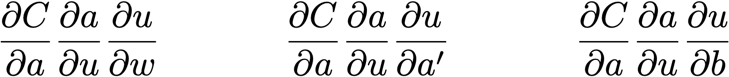
簡單模型的復雜性
? 如果在前面的例子中,我們有兩個節點和它們之間的一個鏈接,在這個例子中,我們有3個節點和2個鏈接,

? 因為鏈式法則的鏈式長度是沒有限制的,我們可以對任意數量的層繼續這樣做,對于這一層,注意計算圖是這樣的,
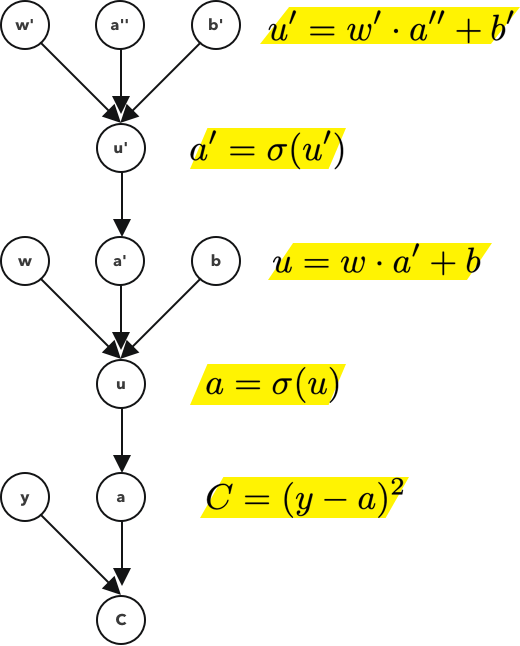
? 請注意,需要用附加的刻度對每個節點進行注釋,這些刻度不是衍生物,它們只是表示u和u '是不同的、唯一的值或物件
復雜模型的復雜性
? 到目前為止的例子都是線性的,鏈表式的神經網路,把它擴展到現實的網路是這樣的,
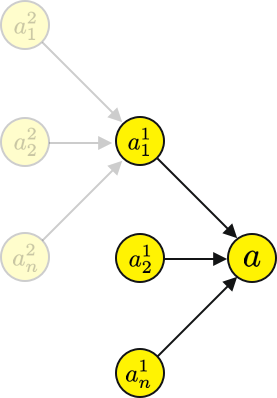
? 我們需要給網路添加一些額外的符號,
? 讓我們通過 a1?計算一下計算圖 a2?,
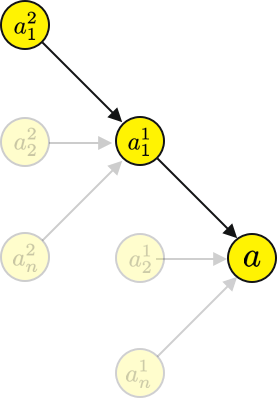
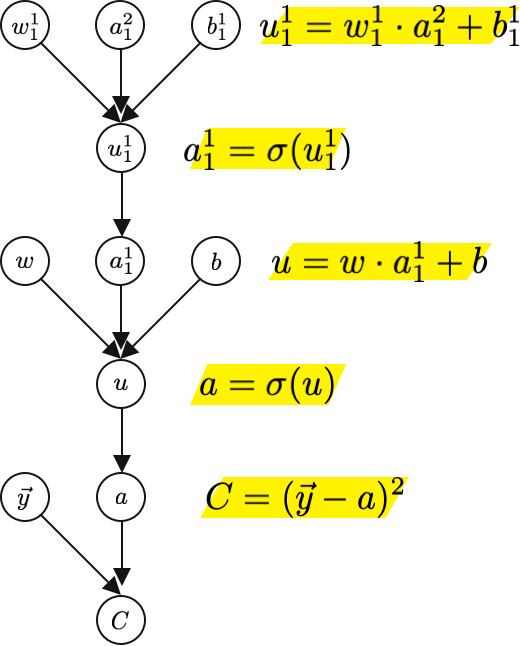
? 實際上你會發現兩個計算圖有一個很大的共同點,特別是到a1?,這意味著,如果一個計算已經被計算過,那么它可以在下一次和下下次被重用,依此類推,雖然這增加了記憶體的占用,但它顯著減少了計算時間,而且對于大型神經網路來說,這是必要的,
? 如果我們用鏈式法則,得到的公式幾乎是一樣的,只是增加了索引,
復雜模型的進一步復雜化
? 你會發現一個a2? 會有幾個路徑輸出層節點,,
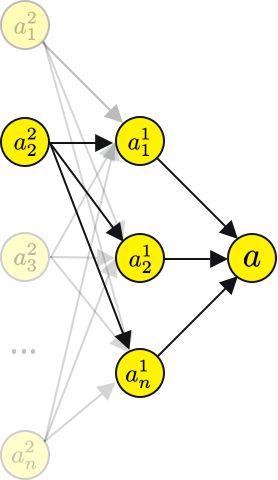
? 所以我們需要對前一層求和,我們從所有前面的節點和它們的梯度的總和中得到的這個值有更新它的指令,以便我們最小化損失,
最小化成本函式
? 如果你還記得定義6和7,特別是定義7,你會記得成本函式在概念上是預測產出和實際產出之差的平均值或加權平均值,
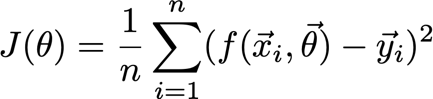
? 如果我們使用線性回歸或邏輯回歸的梯度下降演算法來最小化代價函式,
? 對于神經網路,我們使用反向傳播演算法,我想現在已經很清楚為什么我們不能對神經網路使用單一方程了,神經網路并不是我們可以很好地求導數的連續函式,相反,它們近似一個函式的離散節點,因此需要一個遞回演算法來找到它的導數或梯度,這需要考慮到所有的節點,
? 完整的成本函式是這樣的:
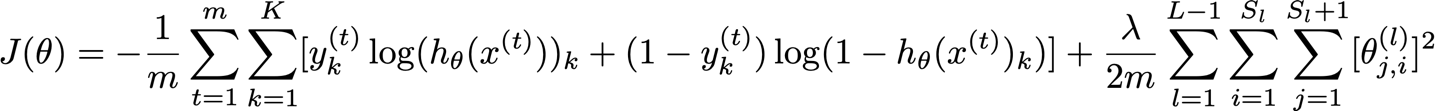
? 從概念上講
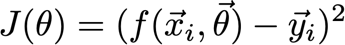
符號對符號導數
? 到目前為止,您已經了解了如何得到神經網路中節點梯度的代數運算式,通過鏈式法則在張量上的應用和計算圖的概念,
? 代數運算式或計算圖不處理具體問題,而只是給我們的理論背景,以驗證我們正在正確地計算它們,它們幫助指導我們的編碼,
? 在下一個概念中,我們將討論符號對數值導數的影響,
符號-數值導數
? 這里我們開始脫離理論,進入實踐領域,
演算法
基本設定+計算節點的梯度
? 首先我們要做一些設定,包括神經網路的順序以及與網路相關的節點的計算圖,我們把它們排列好,
? 每個節點u^{(n)} 都與一個操作f^{(i)}相關聯,使得:
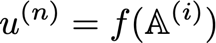
? 在𝔸^ {(i)}是所有節點的集合,u^ {(n)}的父節點,
? 首先我們需要計算所有的輸入節點,為此我們需要將所有的訓練資料以x向量的形式輸入:
for i = 1, ...., n_i
u_i = get_u(x_i)
? 注意,n_i為輸入節點數,其中輸入節點為:
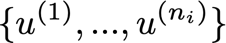
? 如果這些是輸入節點,則節點:
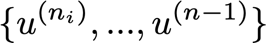
? 是輸入節點之后最后一個節點之前的節點u^{(n)},
for i = n_i+1, ..., n
A_i = { u_j = get_j(Pa(u_i)) }
u_i = fi(A_i)
? 你會注意到,這和我們鏈式法則計算圖的概念上的方向是相反的,這是因為這部分詳細說明了正向傳播,
? 我們稱這個圖為:
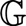
? 利用這個圖,我們可以構造另一個圖:
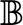
? G中的每個節點計算正向圖節點u^i,而B中的每個節點使用鏈式法則計算梯度,
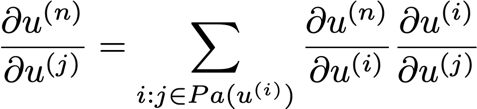
? 如果你考慮神經網路中的所有節點和連接它們的邊,你就能想到反向傳播所需的計算量隨著邊的數量線性增加,因為每條邊都代表了一條鏈規則的計算,它將一些節點連接到它的一個父節點,
附加約束+簡單的反向傳播
? 如前所述,該演算法的計算復雜度與網路的邊數呈線性關系,但這是假設求每條邊的偏導數需要一個常數時間,
? 在這里,我們的目標是建立一個具體反向傳播演算法,
Run forward propagation
? 這將獲得處于隨機的或非有用狀態的網路的激活值,
Initialize grad_table
? 在這個資料結構中,我們將存盤所有我們計算的梯度,
To get an individual entry, we use grad_table(u_i)
? 這將存盤計算值:
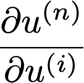
grad_table[u_n] = 1
? 這將最后一個節點設定為1,
for j = n-1 to 1
grad_table[u_j] = \\sum grad_table[u_i] du_i/du_j
? 理論上是這樣的:
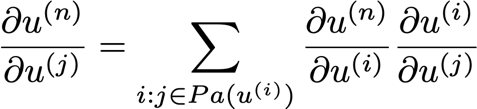
return grad_table
? 反向傳播演算法只訪問每個節點一次來計算偏置,這避免了不必要的重新計算子運算式的步驟,請記住,這是以更多記憶體占用為代價的,
作者:Tojo Batsuuri
deephub翻譯組:孟翔杰
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/68797.html
標籤:其他