開心一刻

樓主:心都讓你嚇出來了!
獅王:淡定,打個小噴嚏而已
前情回顧
神奇的 SQL 之 聯表細節 → MySQL JOIN 的執行程序(一)中,我們講到了 3 種聯表演算法:SNL、BNL 和 INL,了解了資料的查詢方式是 one by one,聯表方式也是 one by one ;并談到了 ON 和 WHERE,對下圖中所說的提出了質疑

認為 ON 和 WHERE 的生效時機有待商榷;此時樓主開始了欠大家的賬
神奇的 SQL 之 聯表細節 → MySQL JOIN 的執行程序(二)中對聯表演算法進行了補充,詳細介紹了 MRR 和 BKA,但還是未介紹 ON 和 WHERE,樓主依舊欠著大家的賬,內心涌滿了愧疚
終于在今天,樓主痛定思痛,決定將這筆賬還上;此刻樓主的內心獨白是這樣的

此時各位看官的內心肯定嘀咕著:你特么欠賬欠的這么義憤填膺 ? 不過我好喜歡

咳咳,閑話不多說,進入我們今天的正題
SQL 執行順序
SQL 的執行順序相信大家多少有所了解,上網一搜也很快就能找到答案

除了 WITH 用的比較少之外,其他都比較常用,相信大家對上面的執行順序也沒有什么疑問;我們重點關注下 JOIN、ON 和 WHERE

那么 WHERE 是不是一定是在 ON 之后生效了 ? 我們帶著這個疑問往下看
ON 和 WHERE 的常規區別
on 針對的關聯條件,是表與表之間通過哪些列、以什么條件進行關聯,而 where 針對的是過濾條件;兩者從概念上來講是不同的
另外 on 一定是與 join 一并使用的,join 會添加外部行,并將外部行中被驅動表的欄位填充 null ,而 where 進行過濾的時候,只有邏輯判斷為 true 的記錄才會保留,邏輯值為 false 和 unknown 的記錄都會過濾掉(更多詳情:神奇的 SQL 之溫柔的陷阱 → 三值邏輯 與 NULL !);兩者得到的結果會有所不同
上面說的可能有些抽象,我們結合具體示例來看;MySQL 版本 5.7.21 ,準備表和初始資料


create table tbl_a (a int primary key, b int, c int, d int, e varchar(50)); insert into tbl_a values (4,3,1,1,'a'); insert into tbl_a values (1,1,1,2,'d'); insert into tbl_a values (8,8,7,8,'h'); insert into tbl_a values (2,2,1,2,'g'); insert into tbl_a values (5,2,2,5,'e'); insert into tbl_a values (3,3,2,1,'c'); insert into tbl_a values (7,4,0,5,'b'); insert into tbl_a values (6,5,2,4,'f'); create table tbl_b like tbl_a; insert into tbl_b SELECT * from tbl_a; insert into tbl_a values (9,9,9,9,'9'); insert into tbl_b values (10,10,10,10,'10');View Code
我們先來看看 left join(right join類似)
SELECT * FROM tbl_a a LEFT JOIN tbl_b b ON a.a = b.a AND a.b = b.b; /*query_on*/ SELECT * FROM tbl_a a LEFT JOIN tbl_b b ON a.a = b.a WHERE a.b = b.b; /*query_where*/
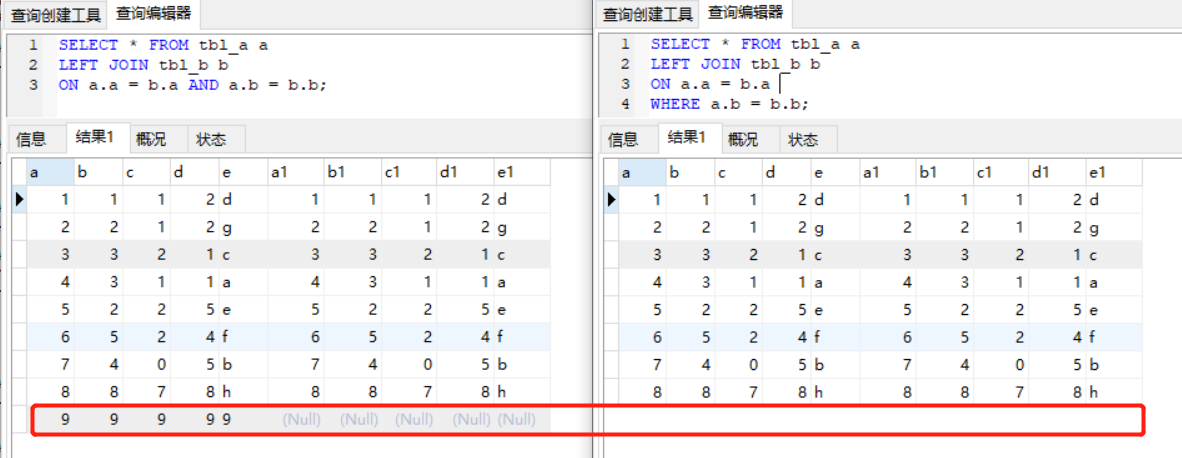
我們可以看到:
陳述句 query_on 回傳了 tbl_a 中的全部記錄,tbl_b 無對應記錄的欄位值填成 NULL,這是因為 join 會添加外部行,將 tbl_a 有而 tbl_b 中沒有的記錄添加到結果集
陳述句 query_where 回傳的是 8 行,因為最后的一行,在表 tbl_b 中沒有匹配的欄位,所以 where 后的 b.b 的值是 NULL,而 a.b 的值是 9,那么 where 9 = NULL 的結果是 unknown 而不是 true,因此這條記錄不能作為結果集的一部分
我們再來看看 inner join
SELECT * FROM tbl_a a INNER JOIN tbl_b b ON a.a = b.a AND a.b = b.b; /*query_on*/ SELECT * FROM tbl_a a INNER JOIN tbl_b b ON a.a = b.a WHERE a.b = b.b; /*query_where*/
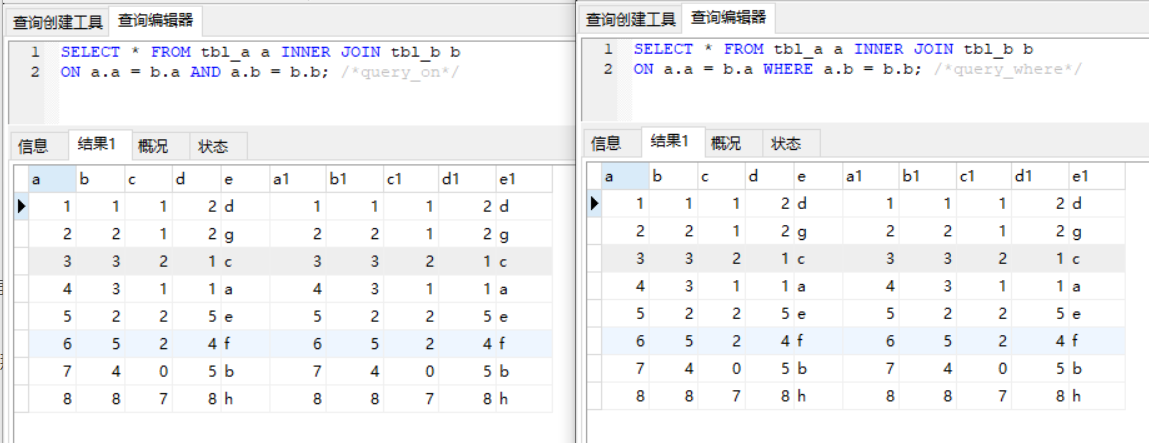
我們可以看到,執行結果是一樣的,inner join 查詢的就是驅動表與被驅動表同時存在的記錄,所以過濾條件不管放在 ON 里,還是放在 WHERE 里,執行結果是一樣的
ON 和 WHERE 的生效時機
ON 后的關聯條件與 WHERE 后的過濾條件,這兩者的執行順序是否如 SQL 執行順序圖中說的那樣,ON 一定先與 WHERE ?
問題先放著,我們以 left join 為例,來看看 4 個案例,也許從中能找到我們想要的答案
1、左表與右表都沒二級索引
剛好上面的 tbl_a 和 tbl_b 滿足條件,我們來看看 SQL 的執行計劃
EXPLAIN SELECT * FROM tbl_a a LEFT JOIN tbl_b b ON a.b = b.b AND a.c = b.c WHERE a.b >= 2 AND a.b < 10 AND a.c > 0 AND a.d != 1 AND a.e != 'a'View Code
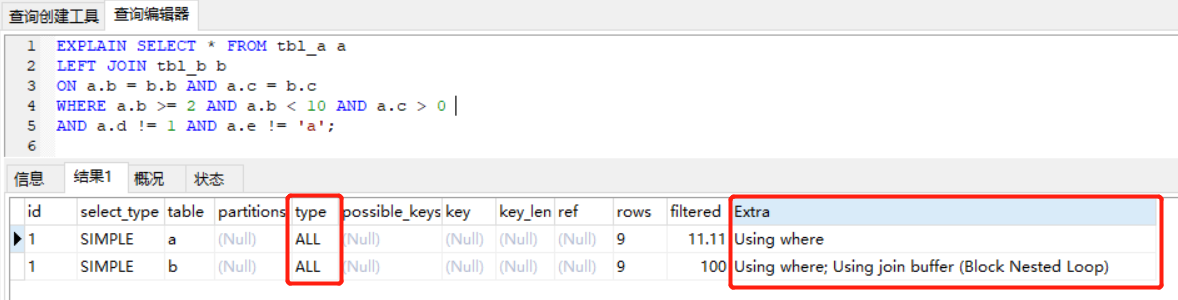
驅動表是 tbl_a,這個相信大家沒問題,我們重點看下 type 和 Extra
type:上面的 ALL 表示全表掃描 a 表,下面的 ALL 表示全表關聯,a 表中每一條滿足條件的記錄都會與 b 表中全部 9 條記錄逐條進行關聯
Extra:Using where 表示要進行 WHERE 條件過濾,Using join buffer (Block Nested Loop) 表示用到了 BNL
這條 SQL 的執行流程應該是這樣的:

此時大家看出什么了沒 ? ON 后的關聯條件是在 WHERE 后的過濾條件之前生效的嗎 ?
這個案例不太常見,因為表沒有二級索引,我們接著往下看看有二級索引的情況
2、左表有二級索引,右表無二級索引
我們在 tbl_a 建一個組合索引 create index idx_bcd on tbl_a(b, c, d); ,然后往 tbl_a 和 tbl_b 中各插入 10W 條記錄,我們再來看執行計劃
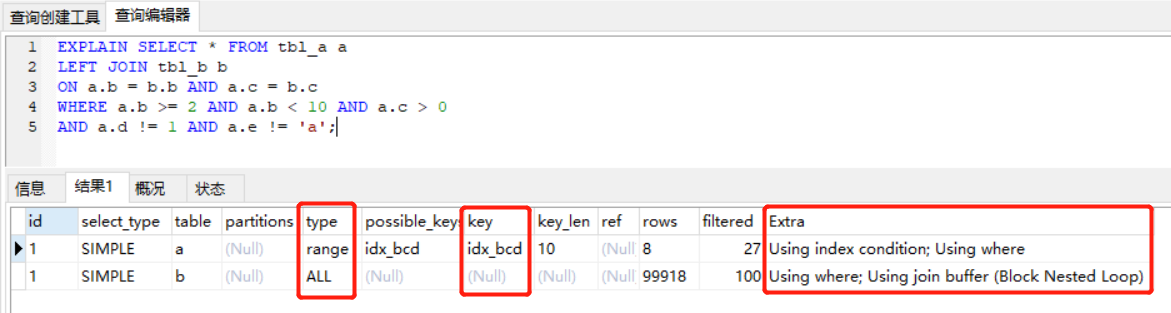
上圖中紅框標記的欄位重點關注下,不知道欄位含義的小伙伴,可以去翻翻我之前關于 explain的博客
那么此時 SQL 的執行流程應該是這樣的:

就步驟 1 與 示例 1 中的步驟 1 不同,其余 2 步是一樣的
此時 WHERE 后的過濾條件的生效時機也是早于 ON 后的關聯條件的
3、左表無二級索引,右表有二級索引
將 tbl_b 作為左表,tbl_a 作為右表,我們來看效果
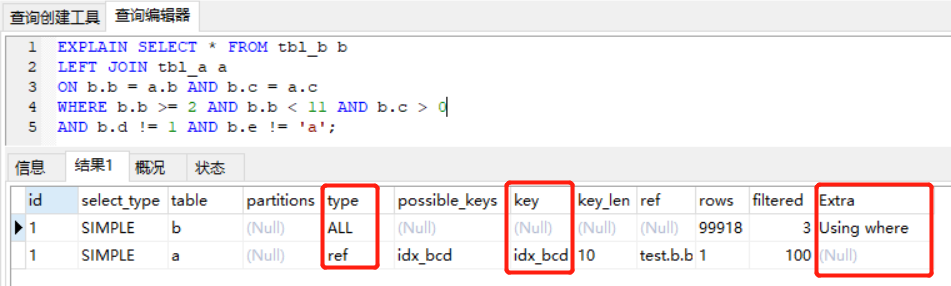
此時 SQL 的執行流程應該是這樣的:

此時 ON 后的關聯條件的生效時機是早于 WHERE 后的過濾條件的
4、左表與右表都有二級索引
我們在 tbl_b 表上建一個組合索引 create index idx_bcd on tbl_b(b, c, d); 我們來看看 SQL 的執行計劃
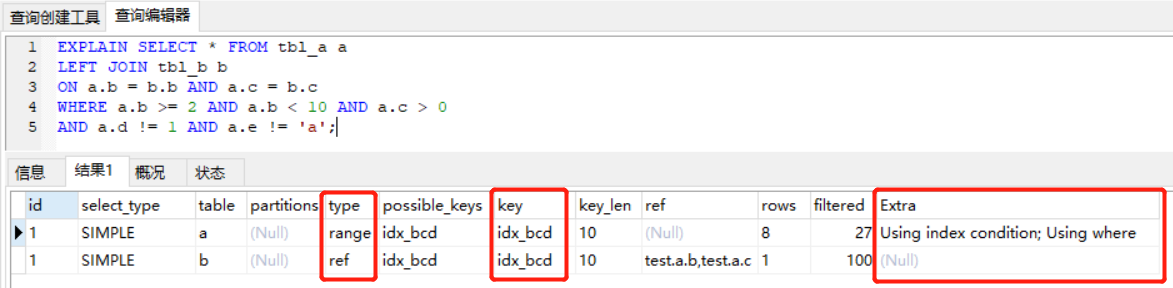
此時 SQL 的執行流程應該是這樣的:

先是 WHERE 中的 Index Filter 條件生效,然后是 ON 后的關聯條件生效,最后是 WHERE 中的 Table Filter 生效,關聯條件的生效時間穿插在過濾條件的生效時間中
自此,關于 ON 和 WHERE 的生效時機,你清楚了嗎 ?
總結
1、關聯博客
如果沒有讀樓主的前幾篇博客,那么有些概念可能不理解,樓主把相關聯的博客都列一下
神奇的 SQL 之溫柔的陷阱 → 三值邏輯 與 NULL !
神奇的 SQL 之 MySQL 執行計劃 → EXPLAIN,讓我們了解 SQL 的執行程序!
神奇的 SQL 之 聯表細節 → MySQL JOIN 的執行程序(一)
神奇的 SQL 之 聯表細節 → MySQL JOIN 的執行程序(二)
神奇的 SQL 之 WHERE 條件的提取與應用
神奇的 SQL 之 ICP → 索引條件下推
對相關概念不了解的可以去對應的博客查閱
2、ON 和 WHERE
兩者好區分,也容易混淆,他們在概念上就做了明確區分,但是又可以做概念之外的事,所以用著用著就開始混淆了
樓主推薦:嚴格按他們的概念來處理,ON 后跟關聯條件,其他的都放到 WHERE 后做過濾條件;盡量保證 SQL 語意清晰
至于他兩的生效時機,需要結合表結構,以及具體的 SQL 來分析,而不是 ON 一定先于 WHERE
參考
What is the meaning of filtered in MySQL explain?
MySQL的server層和存盤引擎層是如何互動的
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/70559.html
標籤:MySQL