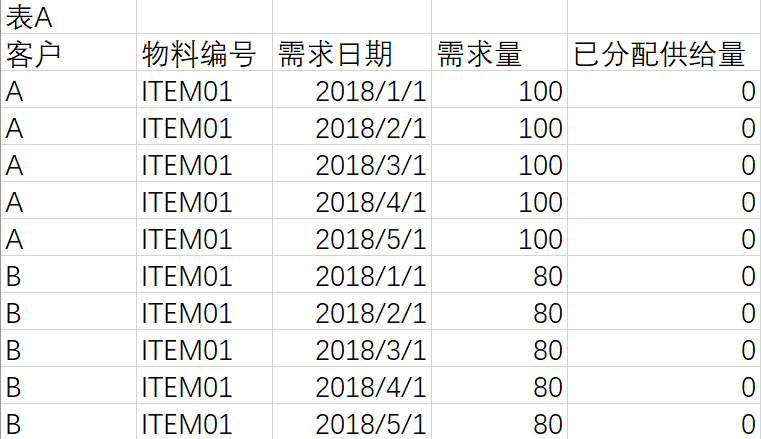
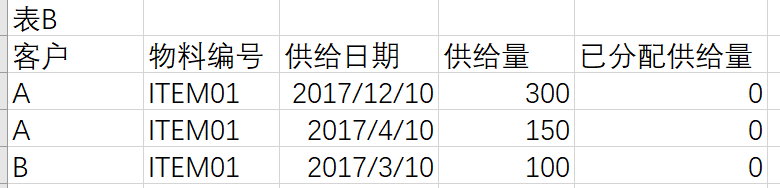
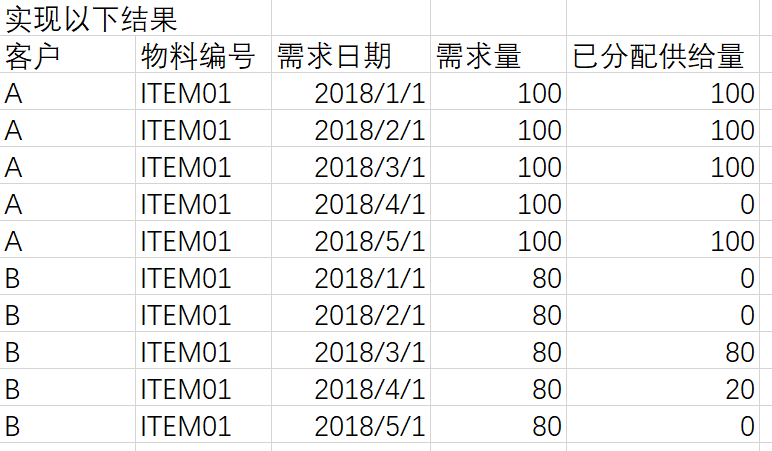
需要通過存盤程序實作將表B的供給量分配給表A中同客戶同物料編號的資料中,需要供給日期小于需求日期的資料才能分配,最終希望實作如下結果:
uj5u.com熱心網友回復:
創建表結構,并插入資料:
CREATE TABLE "表A"
("客戶" CHAR(1),
"物料編號" VARCHAR2(10),
"需求日期" DATE,
"需求量" number,
"已分配供給量" number);
CREATE TABLE "表B"
("客戶" CHAR(1),
"物料編號" VARCHAR2(10),
"供給日期" DATE,
"供給量" number,
"已分配供給量" number);
INSERT INTO "表A" VALUES('A','ITEM01', DATE'2018-01-01',100,0);
INSERT INTO "表A" VALUES('A','ITEM01', DATE'2018-02-01',100,0);
INSERT INTO "表A" VALUES('A','ITEM01', DATE'2018-03-01',100,0);
INSERT INTO "表A" VALUES('A','ITEM01', DATE'2018-04-01',100,0);
INSERT INTO "表A" VALUES('A','ITEM01', DATE'2018-05-01',100,0);
INSERT INTO "表A" VALUES('B','ITEM01', DATE'2018-01-01',80,0);
INSERT INTO "表A" VALUES('B','ITEM01', DATE'2018-02-01',80,0);
INSERT INTO "表A" VALUES('B','ITEM01', DATE'2018-03-01',80,0);
INSERT INTO "表A" VALUES('B','ITEM01', DATE'2018-04-01',80,0);
INSERT INTO "表A" VALUES('B','ITEM01', DATE'2018-05-01',80,0);
INSERT INTO "表B" VALUES('A','ITEM01', DATE'2017-12-10',300,0);
INSERT INTO "表B" VALUES('A','ITEM01', DATE'2018-04-10',150,0);
INSERT INTO "表B" VALUES('B','ITEM01', DATE'2018-03-10',100,0);
COMMIT;
CREATE TABLE "結果"
("客戶" CHAR(1),
"物料編號" VARCHAR2(10),
"需求日期" DATE,
"需求量" number,
"已分配供給量" number);
存盤程序代碼
CREATE OR REPLACE PROCEDURE p1 AS
v_supply NUMBER;
v_keep NUMBER;
BEGIN
v_supply := 0;
FOR r1 IN (SELECT a.*, row_number() over(PARTITION BY "客戶", "物料編號" ORDER BY "供給日期") seqno
FROM "表B" a
ORDER BY "客戶", "物料編號", "供給日期") LOOP
IF r1.seqno = 1 THEN
v_supply := r1.供給量;
ELSE
v_supply := v_supply + r1.供給量;
END IF;
FOR r2 IN (SELECT *
FROM "表A"
WHERE "客戶" = r1."客戶"
AND "物料編號" = r1."物料編號"
ORDER BY "需求日期") LOOP
IF r2. "需求日期" >= r1."供給日期" THEN
v_keep := least(v_supply, r2."需求量");
v_supply := v_supply - v_keep;
ELSE
v_keep := 0;
END IF;
dbms_output.put_line(r1."客戶" || ',' || r1."供給日期" || ',' || r2.需求日期 || ',' || v_keep || ',' ||
v_supply);
MERGE INTO "結果" a
USING (SELECT r2."客戶" "客戶", r2."物料編號" "物料編號", r2."需求日期" "需求日期", r2."需求量" "需求量",
v_supply "已分配供給量"
FROM dual) b
ON (a."客戶" = b."客戶" AND a."物料編號" = b."物料編號" AND a."需求日期" = b."需求日期")
WHEN MATCHED THEN
UPDATE SET "已分配供給量" = "已分配供給量" + v_keep
WHEN NOT MATCHED THEN
INSERT
("客戶", "物料編號", "需求日期", "需求量", "已分配供給量")
VALUES
(b."客戶", b."物料編號", b."需求日期", b."需求量", v_keep);
END LOOP;
END LOOP;
COMMIT;
END;
執行存盤程序:
BEGIN
p1;
END;
--查詢結果
SELECT * FROM "結果";
uj5u.com熱心網友回復:
此前也試過用回圈和游標的寫法,但是由于需求表的資料量比較大,回圈的效率比較慢,是否有其他更高效的寫法呢?
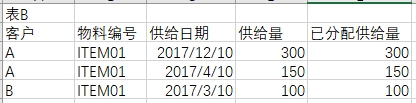
另外,問題描述有遺漏,其實最終結果就是更新A 表中的已分配供給量,B表中的已分配供給量也是同時需要更新的,B表最終結果如下:
uj5u.com熱心網友回復:
可以不用存盤程序,只用SQL陳述句with ba1 as (select 'A' kh,'ITEM01' wl,to_date('20180101','yyyymmdd') xqrq,100 xql,0 yfp from dual union all
select 'A' kh,'ITEM01' wl,to_date('20180201','yyyymmdd') xqrq,100 xql,0 yfp from dual union all
select 'A' kh,'ITEM01' wl,to_date('20180301','yyyymmdd') xqrq,100 xql,0 yfp from dual union all
select 'A' kh,'ITEM01' wl,to_date('20180401','yyyymmdd') xqrq,100 xql,0 yfp from dual union all
select 'A' kh,'ITEM01' wl,to_date('20180501','yyyymmdd') xqrq,100 xql,0 yfp from dual union all
select 'B' kh,'ITEM01' wl,to_date('20180101','yyyymmdd') xqrq,80 xql,0 yfp from dual union all
select 'B' kh,'ITEM01' wl,to_date('20180201','yyyymmdd') xqrq,80 xql,0 yfp from dual union all
select 'B' kh,'ITEM01' wl,to_date('20180301','yyyymmdd') xqrq,80 xql,0 yfp from dual union all
select 'B' kh,'ITEM01' wl,to_date('20180401','yyyymmdd') xqrq,80 xql,0 yfp from dual union all
select 'B' kh,'ITEM01' wl,to_date('20180501','yyyymmdd') xqrq,80 xql,0 yfp from dual),
bb1 as (select 'A' kh,'ITEM01' wl,to_date('20171210','yyyymmdd') ggrq,300 xql,0 yfp from dual union all
select 'A' kh,'ITEM01' wl,to_date('20180410','yyyymmdd') ggrq,150 xql,0 yfp from dual union all
select 'B' kh,'ITEM01' wl,to_date('20180310','yyyymmdd') ggrq,100 xql,0 yfp from dual),
ba as (select row_number() over (partition by kh,wl order by xqrq) xh,ba1.* from ba1),
bb as (select row_number() over (partition by kh,wl order by ggrq) xh,bb1.* from bb1),
aa as (select ba.*,(select sum(xql) from bb where bb.kh=ba.kh and bb.wl=ba.wl and bb.ggrq<ba.xqrq) kgg from ba)
select * from aa
model
dimension by (kh,wl,xh)
measures(xql,kgg,0 kfp,0 yl,yfp)
rules
(kfp[kh,wl,xh]=nvl(kgg[cv(),cv(),cv()],0)-nvl(kgg[cv(),cv(),cv()-1],0),yl[kh,wl,xh]=greatest(nvl(yl[cv(),cv(),cv()-1],0)+nvl(kfp[cv(),cv(),cv()],0)-nvl(xql[cv(),cv(),cv()],0),0),
yfp[kh,wl,xh]=case when kfp[cv(),cv(),cv()]>0 then least(xql[cv(),cv(),cv()],kfp[cv(),cv(),cv()]) else least(xql[cv(),cv(),cv()],yl[cv(),cv(),cv()-1]) end);
uj5u.com熱心網友回復:
按最新描述完成的代碼,功能沒有問題,至于性能,我是按資料量比較少的供給表B做外層回圈,并關聯需求表A,如果表A的關聯欄位都有索引(客戶+物料編號),性能應該能夠滿足:CREATE OR REPLACE PROCEDURE p1 AS
v_supply NUMBER;
v_keep NUMBER;
BEGIN
v_supply := 0;
FOR r1 IN (SELECT a.*, row_number() over(PARTITION BY "客戶", "物料編號" ORDER BY "供給日期") seqno
FROM "表B" a
ORDER BY "客戶", "物料編號", "供給日期") LOOP
IF r1.seqno = 1 THEN
v_supply := r1.供給量;
ELSE
v_supply := v_supply + r1.供給量;
END IF;
FOR r2 IN (SELECT *
FROM "表A"
WHERE "客戶" = r1."客戶"
AND "物料編號" = r1."物料編號"
ORDER BY "需求日期") LOOP
IF r2. "需求日期" >= r1."供給日期" THEN
v_keep := least(v_supply, r2."需求量");
v_supply := v_supply - v_keep;
ELSE
v_keep := 0;
END IF;
dbms_output.put_line(r1."客戶" || ',' || r1."供給日期" || ',' || r2.需求日期 || ',' || v_keep || ',' ||
v_supply);
UPDATE "表A" a
SET a."已分配供給量" = a."已分配供給量" + v_keep
WHERE a."客戶" = r2."客戶"
AND a."物料編號" = r2."物料編號"
AND a."需求日期" = r2."需求日期";
UPDATE "表B" b
SET b."已分配供給量" = b."已分配供給量" + v_keep
WHERE b."客戶" = r1."客戶"
AND b."物料編號" = r1."物料編號"
AND b."供給日期" = r1."供給日期";
END LOOP;
END LOOP;
COMMIT;
END;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/73364.html
標籤:開發
上一篇:請問大神們,這兩sql陳述句有什么區別啊,加括號和不加括號,輸出結果差別好大,求指教
下一篇:求教一個sql陳述句