redis是一個key-value存盤系統,和Memcached類似,它支持存盤的value型別相對更多,包括string(字串)、list(鏈表)、set(集合)、zset(sorted set --有序集合)和hash(哈希型別),這些資料型別都支持push/pop、add/remove及取交集并集和差集及更豐富的操作,而且這些操作都是原子性的,在此基礎上,redis支持各種不同方式的排序,與memcached一樣,為了保證效率,資料都是快取在記憶體中,區別的是redis會周期性的把更新的資料寫入磁盤或者把修改操作寫入追加的記錄檔案,并且在此基礎上實作了master-slave(主從)同步,
一、Redis安裝和基本使用
wget http://download.redis.io/releases/redis-3.0.6.tar.gz
tar xzf redis-3.0.6.tar.gz
cd redis-3.0.6
make
啟動服務端
src/redis-server
啟動客戶端
src/redis-cli
redis> set foo bar
OK
redis> get foo
"bar"
二、Redis的特性
使用Redis有哪些好處?
(1) 速度快,因為資料存在記憶體中,類似于HashMap,HashMap的優勢就是查找和操作的時間復雜度都是O(1)
(2) 支持豐富資料型別,支持string,list,set,sorted set,hash
(3) 支持事務,操作都是原子性,所謂的原子性就是對資料的更改要么全部執行,要么全部不執行
(4) 豐富的特性:可用于快取,訊息,按key設定過期時間,過期后將會自動洗掉
redis相比memcached有哪些優勢?
(1) memcached所有的值均是簡單的字串,redis作為其替代者,支持更為豐富的資料型別
(2) redis的速度比memcached快很多
(3) redis可以持久化其資料
redis常見性能問題和解決方案
(1) Master最好不要做任何持久化作業,如RDB記憶體快照和AOF日志檔案
(2) 如果資料比較重要,某個Slave開啟AOF備份資料,策略設定為每秒同步一次
(3) 為了主從復制的速度和連接的穩定性,Master和Slave最好在同一個局域網內
(4) 盡量避免在壓力很大的主庫上增加從庫
(5) 主從復制不要用圖狀結構,用單向鏈表結構更為穩定,即:Master <- Slave1 <- Slave2 <- Slave3...
這樣的結構方便解決單點故障問題,實作Slave對Master的替換,如果Master掛了,可以立刻啟用Slave1做Master,其他不變,
MySQL里有2000w資料,redis中只存20w的資料,如何保證redis中的資料都是熱點資料
相關知識:redis 記憶體資料集大小上升到一定大小的時候,就會施行資料淘汰策略,redis 提供 6種資料淘汰策略:
voltile-lru:從已設定過期時間的資料集(server.db[i].expires)中挑選最近最少使用的資料淘汰
volatile-ttl:從已設定過期時間的資料集(server.db[i].expires)中挑選將要過期的資料淘汰
volatile-random:從已設定過期時間的資料集(server.db[i].expires)中任意選擇資料淘汰
allkeys-lru:從資料集(server.db[i].dict)中挑選最近最少使用的資料淘汰
allkeys-random:從資料集(server.db[i].dict)中任意選擇資料淘汰
no-enviction(驅逐):禁止驅逐資料
Memcache與Redis的區別都有哪些?
1)、存盤方式
Memecache把資料全部存在記憶體之中,斷電后會掛掉,資料不能超過記憶體大小,
Redis有部份存在硬碟上,這樣能保證資料的持久性,
2)、資料支持型別
Memcache對資料型別支持相對簡單,
Redis有復雜的資料型別,
3),value大小
redis最大可以達到1GB,而memcache只有1MB
Redis 常見的性能問題都有哪些?如何解決?
1).Master寫記憶體快照,save命令調度rdbSave函式,會阻塞主執行緒的作業,當快照比較大時對性能影響是非常大的,會間斷性暫停服務,所以Master最好不要寫記憶體快照,
2).Master AOF持久化,如果不重寫AOF檔案,這個持久化方式對性能的影響是最小的,但是AOF檔案會不斷增大,AOF檔案過大會影響Master重啟的恢復速度,Master最好不要做任何持久化作業,包括記憶體快照和AOF日志檔案,特別是不要啟用記憶體快照做持久化,如果資料比較關鍵,某個Slave開啟AOF備份資料,策略為每秒同步一次,
3).Master呼叫BGREWRITEAOF重寫AOF檔案,AOF在重寫的時候會占大量的CPU和記憶體資源,導致服務load過高,出現短暫服務暫停現象,
4). Redis主從復制的性能問題,為了主從復制的速度和連接的穩定性,Slave和Master最好在同一個局域網內
redis 最適合的場景
Redis最適合所有資料in-momory的場景,雖然Redis也提供持久化功能,但實際更多的是一個disk-backed的功能,跟傳統意義上的持久化有比較大的差別,那么可能大家就會有疑問,似乎Redis更像一個加強版的Memcached,那么何時使用Memcached,何時使用Redis呢?
如果簡單地比較Redis與Memcached的區別,大多數都會得到以下觀點:
1 、Redis不僅僅支持簡單的k/v型別的資料,同時還提供list,set,zset,hash等資料結構的存盤,
2 、Redis支持資料的備份,即master-slave模式的資料備份,
3 、Redis支持資料的持久化,可以將記憶體中的資料保持在磁盤中,重啟的時候可以再次加載進行使用,
(1)、會話快取(Session Cache)
最常用的一種使用Redis的情景是會話快取(session cache),用Redis快取會話比其他存盤(如Memcached)的優勢在于:Redis提供持久化,當維護一個不是嚴格要求一致性的快取時,如果用戶的購物車資訊全部丟失,大部分人都會不高興的,現在,他們還會這樣嗎?
幸運的是,隨著 Redis 這些年的改進,很容易找到怎么恰當的使用Redis來快取會話的檔案,甚至廣為人知的商業平臺Magento也提供Redis的插件,
(2)、全頁快取(FPC)
除基本的會話token之外,Redis還提供很簡便的FPC平臺,回到一致性問題,即使重啟了Redis實體,因為有磁盤的持久化,用戶也不會看到頁面加載速度的下降,這是一個極大改進,類似PHP本地FPC,
再次以Magento為例,Magento提供一個插件來使用Redis作為全頁快取后端,
此外,對WordPress的用戶來說,Pantheon有一個非常好的插件 wp-redis,這個插件能幫助你以最快速度加載你曾瀏覽過的頁面,
(3)、佇列
Reids在記憶體存盤引擎領域的一大優點是提供 list 和 set 操作,這使得Redis能作為一個很好的訊息佇列平臺來使用,Redis作為佇列使用的操作,就類似于本地程式語言(如Python)對 list 的 push/pop 操作,
如果你快速的在Google中搜索“Redis queues”,你馬上就能找到大量的開源專案,這些專案的目的就是利用Redis創建非常好的后端工具,以滿足各種佇列需求,例如,Celery有一個后臺就是使用Redis作為broker,你可以從這里去查看,
(4),排行榜/計數器
Redis在記憶體中對數字進行遞增或遞減的操作實作的非常好,集合(Set)和有序集合(Sorted Set)也使得我們在執行這些操作的時候變的非常簡單,Redis只是正好提供了這兩種資料結構,所以,我們要從排序集合中獲取到排名最靠前的10個用戶–我們稱之為“user_scores”,我們只需要像下面一樣執行即可:
當然,這是假定你是根據你用戶的分數做遞增的排序,如果你想回傳用戶及用戶的分數,你需要這樣執行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一個很好的例子,用Ruby實作的,它的排行榜就是使用Redis來存盤資料的,你可以在這里看到,
(5)、發布/訂閱
最后(但肯定不是最不重要的)是Redis的發布/訂閱功能,發布/訂閱的使用場景確實非常多,我已看見人們在社交網路連接中使用,還可作為基于發布/訂閱的腳本觸發器,甚至用Redis的發布/訂閱功能來建立聊天系統!(不,這是真的,你可以去核實),
Redis提供的所有特性中,我感覺這個是喜歡的人最少的一個,雖然它為用戶提供如果此多功能,
三、Python操作redis
sudo pip install redis
or
sudo easy_install redis
or
原始碼安裝
API使用
redis-py 的API的使用可以分類為:
- 連接方式
- 連接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 發布訂閱
操作模式
redis-py提供兩個類Redis和StrictRedis用于實作Redis的命令,StrictRedis用于實作大部分官方的命令,并使用官方的語法和命令,Redis是StrictRedis的子類,用于向后兼容舊版本的redis-py,
import redis
r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print(r.get('foo'))
連接池
redis-py使用connection pool來管理對一個redis server的所有連接,避免每次建立、釋放連接的開銷,默認,每個Redis實體都會維護一個自己的連接池,可以直接建立一個連接池,然后作為引數Redis,這樣就可以實作多個Redis實體共享一個連接池,
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
操作
1、String操作
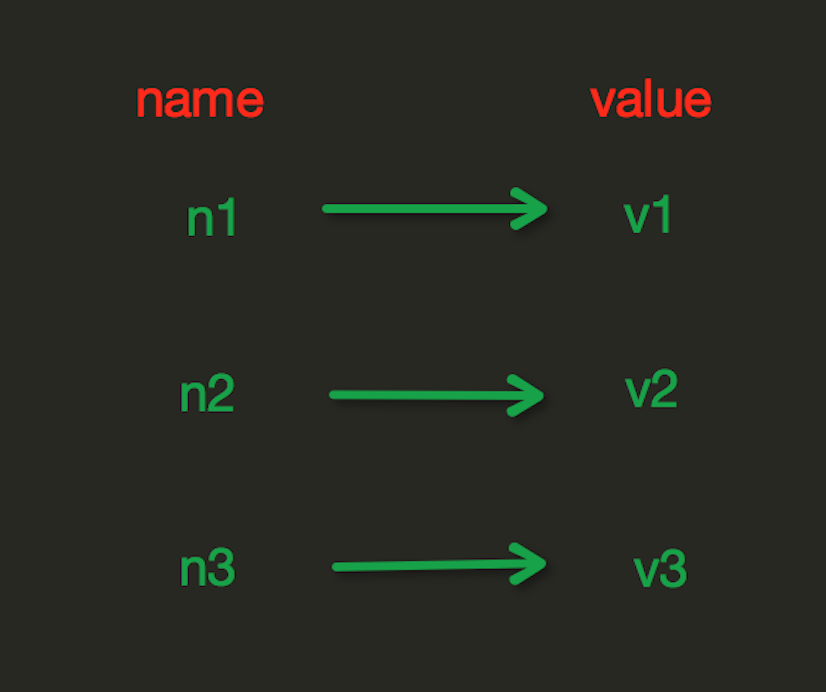
String操作,redis中的String在在記憶體中按照一個name對應一個value來存盤,如圖:
set(name, value, ex=None, px=None, nx=False, xx=False)
set(name, value, ex=None, px=None, nx=False, xx=False)
# 在Redis中設定值,默認,不存在則創建,存在則修改
引數:
ex,過期時間(秒)
px,過期時間(毫秒)
nx,如果設定為True,則只有name不存在時,當前set操作才執行
xx,如果設定為True,則只有name存在時,崗前set操作才執行
setnx(name, value)
# 設定值,只有name不存在時,執行設定操作(添加)
setex(name, value, time)
# 設定值
# 引數:
# time,過期時間(數字秒 或 timedelta物件)
psetex(name, time_ms, value)
# 設定值
# 引數:
# time_ms,過期時間(數字毫秒 或 timedelta物件)
mset(*args, **kwargs)
批量設定值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
get(name)
獲取值
mget(keys, *args)
批量獲取
如:
mget('ylr', 'wupeiqi')
或
r.mget(['ylr', 'wupeiqi'])
getset(name, value)
設定新值并獲取原來的值
getrange(key, start, end)
# 獲取子序列(根據位元組獲取,非字符)
# 引數:
# name,Redis 的 name
# start,起始位置(位元組)
# end,結束位置(位元組)
# 如: "大帥逼" ,0-3表示 "大"
setrange(name, offset, value)
# 修改字串內容,從指定字串索引開始向后替換(新值太長時,則向后添加)
# 引數:
# offset,字串的索引,位元組(一個漢字三個位元組)
# value,要設定的值
setbit(name, offset, value)
# 對name對應值的二進制表示的位進行操作
# 引數:
# name,redis的name
# offset,位的索引(將值變換成二進制后再進行索引)
# value,值只能是 1 或 0
# 注:如果在Redis中有一個對應: n1 = "foo",
那么字串foo的二進制表示為:01100110 01101111 01101111
所以,如果執行 setbit('n1', 7, 1),則就會將第7位設定為1,
那么最終二進制則變成 01100111 01101111 01101111,即:"goo"
# 擴展,轉換二進制表示:
# source = "武沛齊"
source = "foo"
for i in source:
num = ord(i)
print bin(num).replace('b','')
特別的,如果source是漢字 "大帥比"怎么辦?
答:對于utf-8,每一個漢字占 3 個位元組,那么 "大帥比" 則有 9個位元組
對于漢字,for回圈時候會按照 位元組 迭代,那么在迭代時,將每一個位元組轉換 十進制數,然后再將十進制數轉換成二進制
11100110 10101101 10100110 11100110 10110010 10011011 11101001 10111101 10010000
-------------------------- ----------------------------- -----------------------------
大 帥 比
getbit(name, offset)
# 獲取name對應的值的二進制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None)
# 獲取name對應的值的二進制表示中 1 的個數
# 引數:
# key,Redis的name
# start,位起始位置
# end,位結束位置
bitop(operation, dest, *keys)
# 獲取多個值,并將值做位運算,將最后的結果保存至新的name對應的值
# 引數:
# operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(異或)
# dest, 新的Redis的name
# *keys,要查找的Redis的name
# 如:
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
# 獲取Redis中n1,n2,n3對應的值,然后講所有的值做位運算(求并集),然后將結果保存 new_name 對應的值中
strlen(name)
# 回傳name對應值的位元組長度(一個漢字3個位元組)
incr(self, name, amount=1)
# 自增 name對應的值,當name不存在時,則創建name=amount,否則,則自增,
# 引數:
# name,Redis的name
# amount,自增數(必須是整數)
# 注:同incrby
incrbyfloat(self, name, amount=1.0)
# 自增 name對應的值,當name不存在時,則創建name=amount,否則,則自增,
# 引數:
# name,Redis的name
# amount,自增數(浮點型)
decr(self, name, amount=1)
# 自減 name對應的值,當name不存在時,則創建name=amount,否則,則自減,
# 引數:
# name,Redis的name
# amount,自減數(整數)
append(key, value)
# 在redis name對應的值后面追加內容
# 引數:
key, redis的name
value, 要追加的字串
2、Hash操作
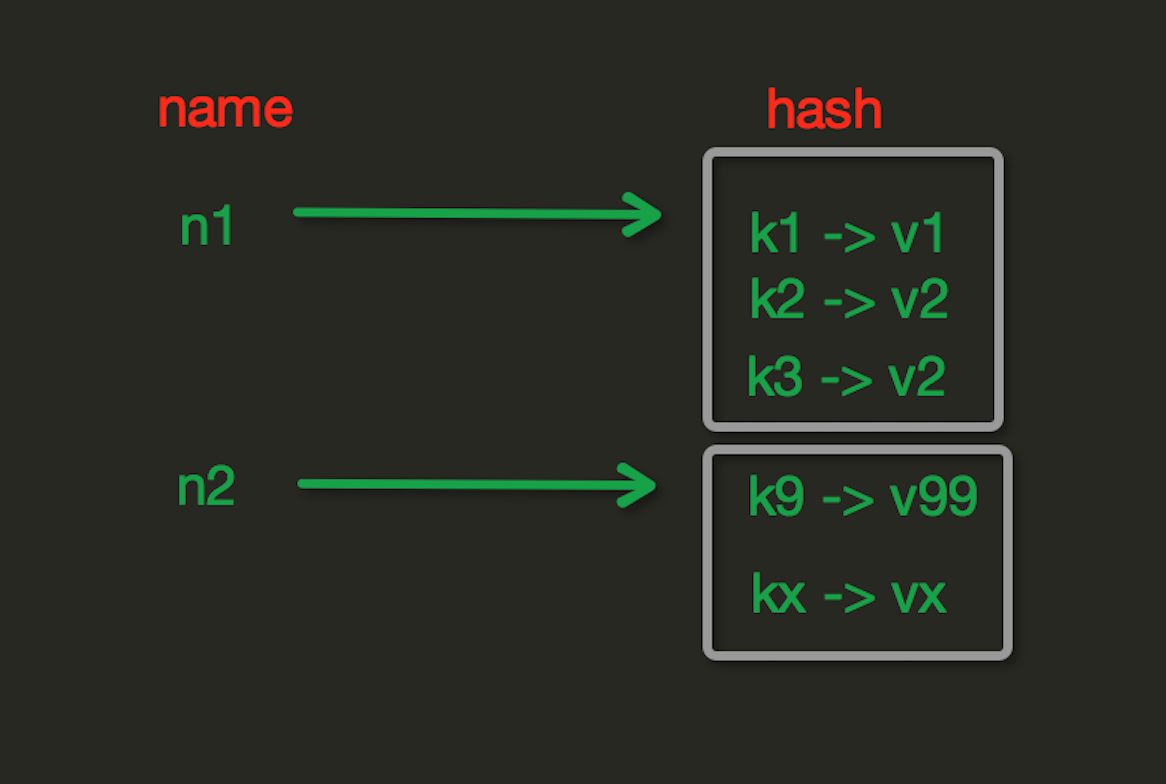
Hash操作,redis中Hash在記憶體中的存盤格式如下圖:
hset(name, key, value)
# name對應的hash中設定一個鍵值對(不存在,則創建;否則,修改)
# 引數:
# name,redis的name
# key,name對應的hash中的key
# value,name對應的hash中的value
# 注:
# hsetnx(name, key, value),當name對應的hash中不存在當前key時則創建(相當于添加)
hmset(name, mapping)
# 在name對應的hash中批量設定鍵值對
# 引數:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
# 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name對應的hash中獲取根據key獲取value
hmget(name, keys, *args)
# 在name對應的hash中獲取多個key的值
# 引數:
# name,reids對應的name
# keys,要獲取key集合,如:['k1', 'k2', 'k3']
# *args,要獲取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name)
# 獲取name對應hash的所有鍵值
hlen(name)
# 獲取name對應的hash中鍵值對的個數
hkeys(name)
# 獲取name對應的hash中所有的key的值
hvals(name)
# 獲取name對應的hash中所有的value的值
hexists(name, key)
# 檢查name對應的hash是否存在當前傳入的key
hdel(name,*keys)
# 將name對應的hash中指定key的鍵值對洗掉
hincrby(name, key, amount=1)
# 自增name對應的hash中的指定key的值,不存在則創建key=amount
# 引數:
# name,redis中的name
# key, hash對應的key
# amount,自增數(整數)
hincrbyfloat(name, key, amount=1.0)
# 自增name對應的hash中的指定key的值,不存在則創建key=amount
# 引數:
# name,redis中的name
# key, hash對應的key
# amount,自增數(浮點數)
# 自增name對應的hash中的指定key的值,不存在則創建key=amount
hscan(name, cursor=0, match=None, count=None)
# 增量式迭代獲取,對于資料大的資料非常有用,hscan可以實作分片的獲取資料,并非一次性將資料全部獲取完,從而放置記憶體被撐爆
# 引數:
# name,redis的name
# cursor,游標(基于游標分批取獲取資料)
# match,匹配指定key,默認None 表示所有的key
# count,每次分片最少獲取個數,默認None表示采用Redis的默認分片個數
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到回傳值cursor的值為0時,表示資料已經通過分片獲取完畢
hscan_iter(name, match=None, count=None)
# 利用yield封裝hscan創建生成器,實作分批去redis中獲取資料
# 引數:
# match,匹配指定key,默認None 表示所有的key
# count,每次分片最少獲取個數,默認None表示采用Redis的默認分片個數
# 如:
# for item in r.hscan_iter('xx'):
# print item
3、List操作
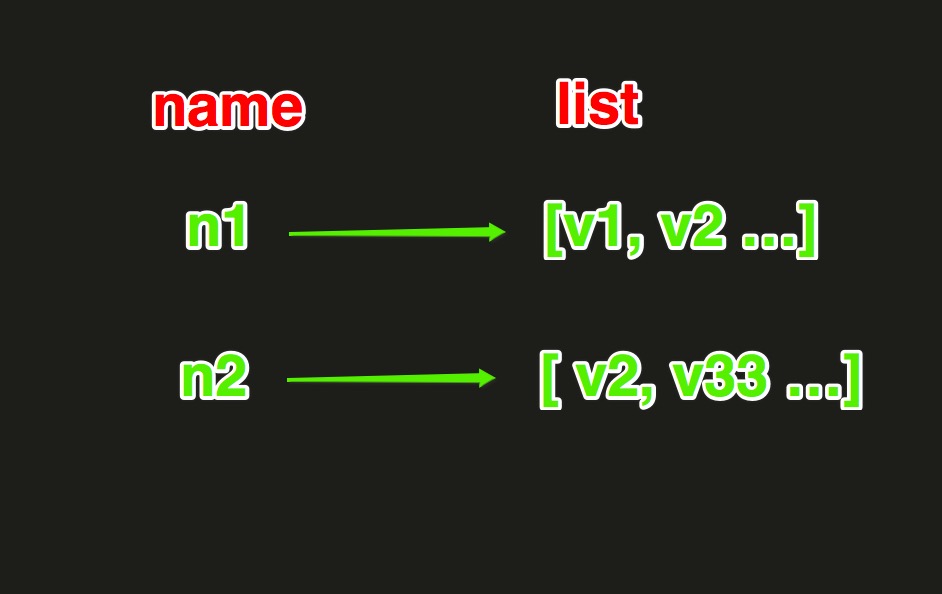
List操作,redis中的List在在記憶體中按照一個name對應一個List來存盤,如圖:
lpush(name,values)
# 在name對應的list中添加元素,每個新的元素都添加到串列的最左邊
# 如:
# r.lpush('oo', 11,22,33)
# 保存順序為: 33,22,11
# 擴展:
# rpush(name, values) 表示從右向左操作
lpushx(name,value)
# 在name對應的list中添加元素,只有name已經存在時,值添加到串列的最左邊
# 更多:
# rpushx(name, value) 表示從右向左操作
llen(name)
# name對應的list元素的個數
linsert(name, where, refvalue, value))
# 在name對應的串列的某一個值前或后插入一個新值
# 引數:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,標桿值,即:在它前后插入資料
# value,要插入的資料
r.lset(name, index, value)
# 對name對應的list中的某一個索引位置重新賦值
# 引數:
# name,redis的name
# index,list的索引位置
# value,要設定的值
r.lrem(name, value, num)
# 在name對應的list中洗掉指定的值
# 引數:
# name,redis的name
# value,要洗掉的值
# num, num=0,洗掉串列中所有的指定值;
# num=2,從前到后,洗掉2個;
# num=-2,從后向前,洗掉2個
lpop(name)
# 在name對應的串列的左側獲取第一個元素并在串列中移除,回傳值則是第一個元素
# 更多:
# rpop(name) 表示從右向左操作
lindex(name, index)
在name對應的串列中根據索引獲取串列元素
lrange(name, start, end)
# 在name對應的串列分片獲取資料
# 引數:
# name,redis的name
# start,索引的起始位置
# end,索引結束位置
ltrim(name, start, end)
# 在name對應的串列中移除沒有在start-end索引之間的值
# 引數:
# name,redis的name
# start,索引的起始位置
# end,索引結束位置
rpoplpush(src, dst)
# 從一個串列取出最右邊的元素,同時將其添加至另一個串列的最左邊
# 引數:
# src,要取資料的串列的name
# dst,要添加資料的串列的name
blpop(keys, timeout)
# 將多個串列排列,按照從左到右去pop對應串列的元素
# 引數:
# keys,redis的name的集合
# timeout,超時時間,當元素所有串列的元素獲取完之后,阻塞等待串列內有資料的時間(秒), 0 表示永遠阻塞
# 更多:
# r.brpop(keys, timeout),從右向左獲取資料
brpoplpush(src, dst, timeout=0)
# 從一個串列的右側移除一個元素并將其添加到另一個串列的左側
# 引數:
# src,取出并要移除元素的串列對應的name
# dst,要插入元素的串列對應的name
# timeout,當src對應的串列中沒有資料時,阻塞等待其有資料的超時時間(秒),0 表示永遠阻塞
4、Set操作
Set操作,Set集合就是不允許重復的串列
sadd(name,values)
# name對應的集合中添加元素
scard(name)
獲取name對應的集合中元素個數
sdiff(keys, *args)
# 在第一個name對應的集合中且不在其他name對應的集合的元素集合
sdiffstore(dest, keys, *args)
# 獲取第一個name對應的集合中且不在其他name對應的集合,再將其新加入到dest對應的集合中
sinter(keys, *args)
# 獲取多一個name對應集合的并集
sinterstore(dest, keys, *args)
# 獲取多一個name對應集合的并集,再講其加入到dest對應的集合中
sismember(name, value)
# 檢查value是否是name對應的集合的成員
smembers(name)
# 獲取name對應的集合的所有成員
smove(src, dst, value)
# 將某個成員從一個集合中移動到另外一個集合
spop(name)
# 從集合的右側(尾部)移除一個成員,并將其回傳
srandmember(name, numbers)
# 從name對應的集合中隨機獲取 numbers 個元素
srem(name, values)
# 在name對應的集合中洗掉某些值
sunion(keys, *args)
# 獲取多一個name對應的集合的并集
sunionstore(dest,keys, *args)
# 獲取多一個name對應的集合的并集,并將結果保存到dest對應的集合中
sscan(name, cursor=0, match=None, count=None)
sscan_iter(name, match=None, count=None)
# 同字串的操作,用于增量迭代分批獲取元素,避免記憶體消耗太大
5、有序集合
有序集合,在集合的基礎上,為每元素排序;元素的排序需要根據另外一個值來進行比較,所以,對于有序集合,每一個元素有兩個值,即:值和分數,分數專門用來做排序,
zadd(name, *args, **kwargs)
# 在name對應的有序集合中添加元素
# 如:
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
zcard(name)
# 獲取name對應的有序集合元素的數量
zcount(name, min, max)
# 獲取name對應的有序集合中分數 在 [min,max] 之間的個數
zincrby(name, value, amount)
# 自增name對應的有序集合的 name 對應的分數
r.zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范圍獲取name對應的有序集合的元素
# 引數:
# name,redis的name
# start,有序集合索引起始位置(非分數)
# end,有序集合索引結束位置(非分數)
# desc,排序規則,默認按照分數從小到大排序
# withscores,是否獲取元素的分數,默認只獲取元素的值
# score_cast_func,對分數進行資料轉換的函式
# 更多:
# 從大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float)
# 按照分數范圍獲取name對應的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 從大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name, value)
# 獲取某個值在 name對應的有序集合中的排行(從 0 開始)
# 更多:
# zrevrank(name, value),從大到小排序
zrangebylex(name, min, max, start=None, num=None)
# 當有序集合的所有成員都具有相同的分值時,有序集合的元素會根據成員的 值 (lexicographical ordering)來進行排序,而這個命令則可以回傳給定的有序集合鍵 key 中, 元素的值介于 min 和 max 之間的成員
# 對集合中的每個成員進行逐個位元組的對比(byte-by-byte compare), 并按照從低到高的順序, 回傳排序后的集合成員, 如果兩個字串有一部分內容是相同的話, 那么命令會認為較長的字串比較短的字串要大
# 引數:
# name,redis的name
# min,左區間(值), + 表示正無限; - 表示負無限; ( 表示開區間; [ 則表示閉區間
# min,右區間(值)
# start,對結果進行分片處理,索引位置
# num,對結果進行分片處理,索引后面的num個元素
# 如:
# ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga
# r.zrangebylex('myzset', "-", "[ca") 結果為:['aa', 'ba', 'ca']
# 更多:
# 從大到小排序
# zrevrangebylex(name, max, min, start=None, num=None)
zrem(name, values)
# 洗掉name對應的有序集合中值是values的成員
# 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name, min, max)
# 根據排行范圍洗掉
zremrangebyscore(name, min, max)
# 根據分數范圍洗掉
zremrangebylex(name, min, max)
# 根據值回傳洗掉
zscore(name, value)
# 獲取name對應有序集合中 value 對應的分數
zinterstore(dest, keys, aggregate=None)
# 獲取兩個有序集合的交集,如果遇到相同值不同分數,則按照aggregate進行操作
# aggregate的值為: SUM MIN MAX
zunionstore(dest, keys, aggregate=None)
# 獲取兩個有序集合的并集,如果遇到相同值不同分數,則按照aggregate進行操作
# aggregate的值為: SUM MIN MAX
zscan(name, cursor=0, match=None, count=None, score_cast_func=float)
zscan_iter(name, match=None, count=None,score_cast_func=float)
# 同字串相似,相較于字串新增score_cast_func,用來對分數進行操作
5、自定義增量迭代
# 由于redis類別庫中沒有提供對串列元素的增量迭代,如果想要回圈name對應的串列的所有元素,那么就需要:
# 1、獲取name對應的所有串列
# 2、回圈串列
# 但是,如果串列非常大,那么就有可能在第一步時就將程式的內容撐爆,所有有必要自定義一個增量迭代的功能:
def list_iter(name):
"""
自定義redis串列增量迭代
:param name: redis中的name,即:迭代name對應的串列
:return: yield 回傳 串列元素
"""
list_count = r.llen(name)
for index in xrange(list_count):
yield r.lindex(name, index)
# 使用
for item in list_iter('pp'):
print item
6、其他常用操作
delete(*names)
# 根據洗掉redis中的任意資料型別
exists(name)
# 檢測redis的name是否存在
keys(pattern='*')
# 根據模型獲取redis的name
# 更多:
# KEYS * 匹配資料庫中所有 key ,
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等,
# KEYS h*llo 匹配 hllo 和 heeeeello 等,
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 為某個redis的某個name設定超時時間
rename(src, dst)
# 對redis的name重命名為
move(name, db))
# 將redis的某個值移動到指定的db下
randomkey()
# 隨機獲取一個redis的name(不洗掉)
type(name)
# 獲取name對應值的型別
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字串操作,用于增量迭代獲取key
管道
redis-py默認在執行每次請求都會創建(連接池申請連接)和斷開(歸還連接池)一次連接操作,如果想要在一次請求中指定多個命令,則可以使用pipline實作一次請求指定多個命令,并且默認情況下一次pipline 是原子性操作,
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.multi()
pipe.set('name', 'alex')
pipe.set('role', 'sb')
pipe.execute()
# 實作計數器
import redis
conn = redis.Redis(host='192.168.1.41',port=6379)
conn.set('count',1000)
with conn.pipeline() as pipe:
# 先監視,自己的值沒有被修改過
conn.watch('count')
# 事務開始
pipe.multi()
old_count = conn.get('count')
count = int(old_count)
if count > 0: # 有庫存
pipe.set('count', count - 1)
# 執行,把所有命令一次性推送過去
pipe.execute()
發布訂閱

發布者:服務器
訂閱者:Dashboad和資料處理
Demo如下:
# RedisHelper
import redis
class RedisHelper:
def __init__(self):
self.__conn = redis.Redis(host='10.211.55.4')
self.chan_sub = 'fm104.5'
self.chan_pub = 'fm104.5'
def public(self, msg):
self.__conn.publish(self.chan_pub, msg)
return True
def subscribe(self):
pub = self.__conn.pubsub()
pub.subscribe(self.chan_sub)
pub.parse_response()
return pub
RedisHelper
訂閱者:
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()
while True:
msg= redis_sub.parse_response()
print(msg)
發布者:
from monitor.RedisHelper import RedisHelper
obj = RedisHelper()
obj.public('hello')
sentinel
redis重的sentinel主要用于在redis主從復制中,如果master顧上,則自動將slave替換成master
from redis.sentinel import Sentinel
# 連接哨兵服務器(主機名也可以用域名)
sentinel = Sentinel([('10.211.55.20', 26379),
('10.211.55.20', 26380),
],
socket_timeout=0.5)
# # 獲取主服務器地址
# master = sentinel.discover_master('mymaster')
# print(master)
#
# # # 獲取從服務器地址
# slave = sentinel.discover_slaves('mymaster')
# print(slave)
#
#
# # # 獲取主服務器進行寫入
# master = sentinel.master_for('mymaster')
# master.set('foo', 'bar')
# # # # 獲取從服務器進行讀取(默認是round-roubin)
# slave = sentinel.slave_for('mymaster', password='redis_auth_pass')
# r_ret = slave.get('foo')
# print(r_ret)
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/7341.html
標籤:其它