目錄
- 什么是ElasticSearch
- 核心能力
- ES的搜索核心
- 搜索引擎選擇
- 搜索的處理
- 補充:
- 小節總結:
- 基本學習環境搭建
- 如何操作ElasticSearch
- 下載、安裝和運行(Based Windows)
- 如何操作ES
- 基于postman操作
- 補充:
- 小節總結
- 需要了解的概念
- 分布式模型相關
- 資料存盤相關
- 小節總結
- Hello ElasticSearch
- 寫->讀
- 寫->搜索
- 小節總結
發表日期:2019年9月18日
什么是ElasticSearch
ElasticSearch是一個集資料存盤、資料搜索和資料分析為一體的系統,它是分布式的,所以能利用分布式來提高其處理能力,具有高可用性和高伸縮性,如果你需要一個能夠提供高性能的搜索服務的系統,那么它或許是一個好的選擇,
- 資料存盤:是指它能夠以JSON格式來存盤資料,如果你不在意資料的搜索,你甚至可以像類似使用mongodb那樣來單純把它作為一個資料存盤系統使用,
- 資料搜索:是指它能夠對JSON格式的資料進行全文檢索等搜索,
- 資料分析:是指它能夠利用一些演算法來對JSON檔案資料進行分析,比如得出某個月的商品銷售增長量,
核心能力
ElasticSearch是一個搜索系統,搜索就是從資料集合中搜索出我們想要的資料,例如從大量的商品資料中搜索出我們想要的某類商品,
現在提一個需求,例如我有一個“文章”的表,我想搜索文章表中欄位content中包含有'java'的資料,
如果你不使用ES,那么從開發角度來說,平常我們都是使用關系型資料庫系統來存盤資料,然后使用類似select name,age,address from student where name like '%李%'的陳述句通過模糊匹配來搜索符合指定條件的資料的,(對應到上面的需求應該是select name,author,content from article where content like '%java%')但其實上面這種基于模糊匹配的搜索方式的效率是比較低的,因為資料庫系統的搜索通常是逐一掃描的,也就是從頭到尾的來嘗試匹配,某個欄位的資料越多,可能需要嘗試匹配的次數就會越多(試想一下從4000字的文章中從上到下只為找到一個字),這種查找就好像最低級的遍歷查找(當然并不是真的就是傻傻的遍歷了,各個資料庫系統都會采用各種演算法來優化),
而ElasticSearch由于其內部建立了每個詞的索引表,當搜索某個詞時,可以根據這個詞從索引表中找到匹配的記錄,所以效率比較高(就好像記錄了某個詞的坐標,有了坐標,就能根據坐標非常快地找到那個詞),
(這里舉個類似的栗子:相信大家都用過字典,那么普通的資料庫搜索就好像從第一頁到最后一頁找一個詞,而ElasticSearch根據這個詞的部首結構從“部首-字的對應表”中直接查找到那個字的頁數,這個效率直接就是天差地別了!)另外,資料庫的搜索是根據指定詞直接查找的,它是很笨的!它不能查找到某些意義上“類似”的結果,比如我搜索“mother”,但如果某個記錄中包含“mom”這個詞,那這條記錄也應該被展示出來,而資料庫的普通搜索做不到,
而這個操作ElasticSearch就可以做到,由于它內部有分詞器,在建立索引的程序中,分詞器可以把資料中的某些詞都認為是指定的某一個詞(比如把mother,mom通通都使用mom作為索引詞),再用這個詞來建立索引,然后在進行搜索的時候,將輸入的詞也進行同樣的轉化,再根據這個詞從索引表中查找到符合的記錄結果,這樣就可以把那些意義相近的結果也搜索出來,所以說,ElasticSearch解決了普通全文搜索的搜索效率低下和搜索不智能的問題,
ES的搜索核心
介紹兩個搜索方法:順序掃描查找、全文搜索
上面有說到資料庫的搜索和ElasticSearch的搜索,
常見的關系型資料庫的針對某個欄位中的資料的搜索是順序掃描查找,從頭到尾去嘗試匹配,也就是所謂的遍歷查找,當然演算法可能沒有那么低級,(現在一些資料庫系統也在嘗試優化全文搜索功能,)而ElasticSearch的搜索是全文搜索,而什么是全文搜索?
全文搜索可以根據一定方式把非結構化的資料對應到一種結構化的標識,從而可以通過標識來檢索到指定的非結構化的資料記錄,
這句話可能有點難以理解,舉個例子理解,比如有一大堆食物你需要去認識,食物本身可以被認作是非結構化的資料,因為他們都是獨特的,但如果我們利用他們的顏色來劃分的話就可以初步地將他們進行結構化劃分,這個就是一種簡單的將資料結構化的手段,在ElasticSearch中,這個把非結構化的資料對應到一種結構化的標識的方式就是倒排索引,下面介紹倒排索引來理解這個概念,在ElasticSearch中,處理這些非結構化的資料的方式就是建立倒排索引(Inverted Index),
什么是倒排索引呢?
倒排索引把資料進行了拆分(比如某個欄位的資料為hello world,那么就會被拆分成hello和world),我們使用這些拆分的詞來作為索引詞來建立索引表,在以hello為索引詞的記錄中,有對hello world的指向,world也是如此,
當然,這里的拆分并不是真實的拆分,原始的資料依然存盤在elasticsearch中,我們另外創建了一個索引檔案來存盤,下面是一個使用倒排索引搜索的示例
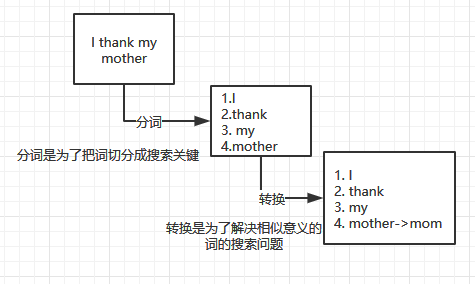
1.首先,假設我們有一個欄位的資料是"I thank my mother",當我們把這個資料存盤到ElasticSearch中,ElasticSearch內部使用分詞器進行處理資料,分詞器用于將非結構化資料中的詞進行拆分和轉換,于是把"I thank my mother"拆解成了"I"、"thank"、"my"、"mother",
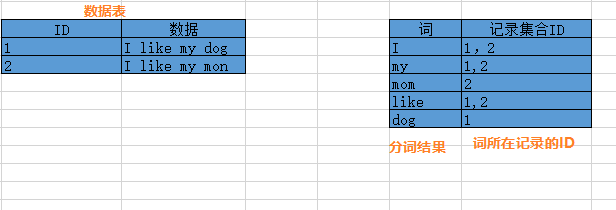
2.當把資料拆分出來后(拆分成的資料單位我們稱為“詞”),就會把這些詞建立索引,ElasticSearch內部有一個索引表,用于建立詞與資料的對應,結構類似如下(真實格式還會有詞的頻率、資料長度等資訊),索引表存盤了詞和詞所在記錄的ID集合,所以可以通過某個詞來快速搜索出相關的記錄,比如搜索"I",那么會回傳1和2,然后可以快速根據ID來獲取對應的資料,【請注意,下圖只是方便理解,并不是真實的格式】
3.然后我們搜索的時候,分詞器也先把我們輸入的內容處理(為了與索引表的詞統一),然后再從索引表中查找,回傳對應的資料記錄集合,
例如我輸入mother,mother會先轉成mom,然后從索引表中找到mom,回傳包含mom的記錄的ID,然后根據ID獲取對應資料,也就是“I like my mom”
搜索引擎選擇
Lucene也是一種搜索引擎,為什么不直接使用Lucene?
ElasticSearch實際上底層使用的就是Lucene,雖然Lucene也有很多功能,但Lucene的使用難度較大(也正是使用難度高所以ElasticSearch才對Lucene進行封裝),而且ElasticSearc的高級功能也很強大,ES支持了多樣的資料分析,除了基本的功能,集群能力也是一個問題,Lucene一開始沒有考慮集群,所以對于存盤在不同服務器上的大量資料的互動比較麻煩,而ElasticeSearch一開始就是集群思想的,資料存盤以一個ElasticSearch節點為單位,多個節點的資料可以交流,
由于底層是Lucene,所以,對于一些elasticsearch底層的東西,有時候你完全可以參照Lucene,比如索引詞檔案的存盤等,為什么不是Solr?
Solr也是一個知名的搜索引擎,它與ElasticSearch各有好處,Solr適用于一些非實時搜索系統(新增的資料不要求馬上查出來的),而ElasticSearch適用于一些實時搜索要求較高的系統(電商平臺等要求新商品馬上可查的系統),因為Solr在建立索引時,搜索效率下降,實時索引搜索效率不高,而ElasticSearch建立索引的速度較快,ElasticSearch有一個非常顯著的特性"NRT":NRT全稱Near Real Time,近實時,意思是你插入的資料幾乎可以“馬上”就可以被搜索出來,這也是為什么它能使用在實時更新要求高的場景的原因,
搜索的處理
上面提了詞的拆分,這里提一些關于底層的搜索處理的內容,介紹一下ElasticSearch另一個協助搜索的關鍵組件--分詞器,ElasticSearch的全文搜索離不開分詞器的幫助,
分詞器通常由分解器tokenizer和詞元過濾器token filter組成,
分詞器對資料的分詞處理:為了提高索引的效率,ElasticSearch會資料進行處理,處理方式主要有字符過濾、詞轉換、詞拆分
字符過濾:過濾一些特殊字符,例如&、||、html標簽,因為這些詞通常搜索意義不大,詞轉換:把一些意義相同的詞統一轉成一個詞,(同詞義轉換)比如mom,mother統一轉成mom;(大小寫轉換)he,He統一歸為He;還處理一些詞意義不大的詞(停用詞清除),比如英文的“the”,“to”,這些詞使用頻率很高,但沒有具體意義,
詞拆分:進行資料的拆分,拆分成詞,比如把
good morning,mom拆分成good,morining,mom,另外,詞拆分并不完全是按照資料的最小單位分解的,某一些分詞器會把一些詞進行組合,因為一些詞的組合起來才有索引的意義,比如中文的一些詞通常要組合起來才有意義,比如“大”和“家”要組成“大家”才有比較具體的意義,這是為了確保索引詞的最小單位是有意義的(比如英文mom的最小單位是m,o,m,內部的分詞器要能夠區分出mom整個是有意義的才可以確保是采用mom作為索引,而不是采用m和o,也正是因為這個問題,所以英文分詞器不能用于中文分詞器),【分詞器有很多個,默認的分詞器是不能適當對中文資料分詞的,它只能把一個個資料按最小的單位拆分,因為英文分詞器不能分清楚怎么把詞拆分才有意義,由于配置分詞器是一個較為靠后的知識點,所以前期將以英文資料為測驗資料,】分詞檔案的存盤:
分詞檔案一般包括三種檔案:詞典檔案,頻率檔案,位置檔案,
詞典檔案保存了關鍵詞(索引詞),還保留了指向頻率檔案和位置檔案的指標,
頻率檔案記錄了詞出現的頻率,
位置檔案記錄了這些詞出現在哪些資料中,
補充:
- 資料庫不是被替代,而是被補充,有時候會將資料同時存盤到資料庫和ElasticSearch中,在單個查看的時候可以從資料庫中查詢,在搜索的時候從ElasticSearch中查詢;也有的專案由于資料比較簡單完全使用elasticsearch來存盤資料,
- ElasticSearch是分布式的,但我們是不需要對其集群進行部署的,它自動進行了集群部署和節點發現等功能,我們只需進行很少的配置就能管理集群,在比較靠后的內容才會講到如何深入管理集群,
小節總結:
- 1.本小節簡單講述了ElasticSearch是什么
- 2.傳統搜索的不足
- 3.使用ElasticSearch搜索的好處
- 4.全文搜索和倒排索引
- 5.與其他搜索引擎的比較
- 6.ElasticSearch對于索引詞的處理(這個內容是提前講的內容,是為了幫助了解倒排索引如何建立索引)
基本學習環境搭建
如何操作ElasticSearch
首先要說的是,ElasticSearch是一款軟體,有點類似MySQL,我們要操作它的時候,也要給它發送它能識別的命令,而ElasticSearch是面向restful(不知道restful的自查吧)的,所以我們發送的命令是有點類似發送http請求的,
mysql是3306埠,而elasticsearch支持9200和9300埠操作,其中9200面向http,9300面向tcp,9200能夠使用普通的http請求來操作elasticsearch,9300需要連接elasticsearch之后再執行命令,
- 對于9200,因為面向http,所以我們可以使用postman發http請求來操作elasticsearch,
- 對于9300,因為面向tcp,我們通常使用一些elasticsearch管理工具(如kibana)進行連接elasticsearch之后再執行命令,(類似navicat之于mysql)
下載、安裝和運行(Based Windows)
我們首先來搭建好學習環境,主要是ElasticSearch和Kibana,【請注意,Elasticsearch依賴Java環境】 【Kibana是可選的,下面會介紹一下基于postman的對ElasticSearch操作,】,Kibana是一款對ElasticSearch進行管理的軟體,我們可以在Kibana上執行ElasticSearch的命令,
下載:
- ElasticSearch下載:ElasticSearch下載【這里以6.2的為例】
- Kibana下載:Kibana下載 【兩個下載都是同一個位置,這里下載以6.2的為例】【Kibana的版本盡量與ElasticSearch的一致,有些版本會連接錯誤】
安裝:
- 兩個軟體都是不需要安裝的,下載后,直接解壓即可,
運行:
- 對于ElasticSearch,可以直接在
elasticsearch-6.2.0\bin中運行elasticsearch.bat,當提示“started”時,表示運行成功, - 對于Kibana,可以直接在
kibana-6.2.0-windows-x86_64\bin中運行kibana.bat,當提示“Server running at http://localhost:5601”時,表示運行成功,【要先運行ElasticSearch再運行Kibana,因為它要與ElasticSearch進行連接】
如何操作ES
ElasticSearch默認的TCP服務埠是9300,Kibana的服務埠是5601,當我們啟動了Kibana之后,它會默認幫我們連接上9300,所以我們可以從http://localhost:5601中進入Kibana的管理界面來管理ElasticSearch,
如果你是第一次使用,那么ElasticSearch會自動創建一個名為elasticsearch的集群,Kibana會在這個節點中初始化一個index
我們在Kibana的DevTools中執行一些命令來看一下ElasticSearch,【從http://localhost:5601中進入】
在輸入命令GET /_cat/health?v后,點擊該行右側的執行按鈕,【GET /_cat/health?v是查看集群的健康狀態的命令】

然后就可以在右側的結果視窗中查看命令執行結果,

【你現在大概都是看不懂命令的意義和結果的意義的了,不過你應該知道哪里輸入命令和哪里看執行結果了】
基于postman操作
postman是一個用來發請求的軟體,可以使用restful風格的請求來操作elasticsearch,
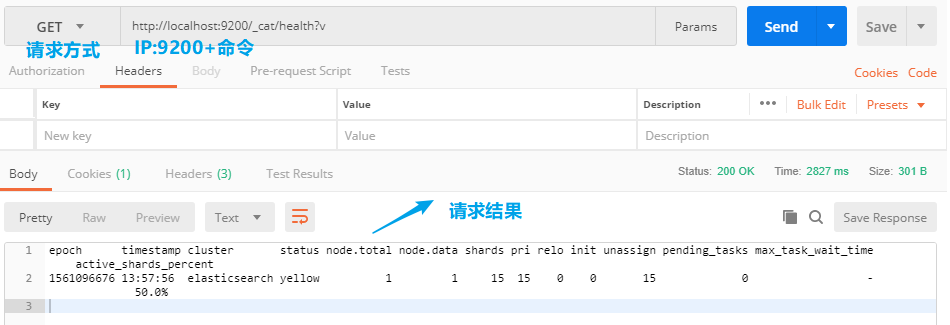
比如上面的查看集群的命令:GET /_cat/health?v
轉成基于restful的是:http://localhost:9200/_cat/health?v即IP:9200+命令,其中9200是用于接收restful請求的es監聽埠,
補充:
上面的第一次使用并沒有涉及到具體的知識,只是讓你熟悉一下如何使用Kibana來操作ElasticSearch,下面講到具體知識點才會具體使用,
小節總結
- 1.講了ES如何提供服務:9200,9300
- 2.講了如何下載、安裝、運行ElasticSearch和Kibana
- 3.講述了如何在Kibana中操作ElasticSearch
- 4.講述了如何在postman中操作ElasticSearch
需要了解的概念
分布式模型相關
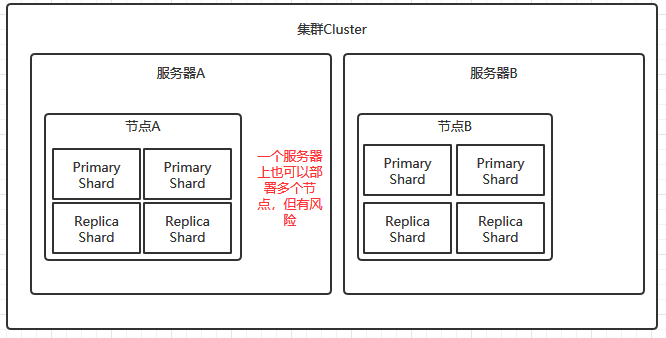
- 集群Cluster:所謂集群,就是多個服務節點的集合,集群意味著這些節點是能夠相互交流的,不然無法進行資料互動,集群的默認名稱是"elasticsearch",多個提供服務的節點會根據集群名來自動加入集群,
- 節點Node:節點是集群的一部分,是集群的最小單元,是可以提供服務的節點,
- 分片shard:分片位于節點上,分片是elasticsearch資料存盤的單元,elasticsearch中的資料會存盤在分片中,分片可以存盤在任意一個節點上,分片分為主分片Primary Shard和副本分片Replica Shard,
- 主分片Primary Shard:當存盤一個檔案document的時候,會先存盤到主分片中,然后再復制到其他的副本分片Replica Shard中,
- 副本分片Replica Shard:副本分片是主分片的復制(備份),默認情況下,主分片有一個副本分片,主分片不能修改,但副本分片可以后續再增加,
- 為了保證資料的不丟失,通常來說Replica Shard不能與其對應的Primary Shard處于同一個節點中,【因為萬一這個節點損壞了,那么存盤在這個節點上的原資料(primary shard)和備份資料(replica shard)就全部丟失了】
- 當主分片掛掉的時候,會選擇一個副本分片作為主分片,
- 查詢可以在主分片或副本分片上進行查詢,這樣可以提供查詢效率,【但資料的修改只發生在主分片上,】
- 一個Primary Shard可以有多個Replica Shard,默認創建是1個,
資料存盤相關
資料存盤在shard中,shard中的資料是以檔案document為單位的,document存盤在index和type劃分的邏輯空間中,document以json為格式,每一個key-value中key可以稱為域Field,
- 索引Index:索引是存盤具有相同結構的document的集合,意義上有點類似關系型資料庫中的資料庫,用于存盤一系列資料,比如可以說“商品”索引,一般都是個大類,小邏輯劃分由Type處理,
- 型別Type:型別是索引的邏輯磁區,意義有點類似關系型資料庫中的資料表,用來劃分索引下不同子型別的資料,比如商品(索引)可以有電子產品(型別),藥品(型別),在同一個分類下的資料一般都具有同種特征,用來定義資料的欄位的數量一般也是相同的,每一個document都有一個type和一個id,在存盤檔案的時候需要指定索引、型別和ID,
- 檔案Document:類似于關系型資料庫中的記錄,是ElasticSearch的資料存盤的基本單位,格式與JSON相同,例如:
{
"book_id": 1,
"book_name": "Java Core ",
"book_desc": "A good book, you know!",
"category_id": "1",
"category_name": "Computer"
}
- 域Field:類似于關系型資料庫中的欄位,
- elasticsearch是面向restful的,下面是restful請求與elasticsearch操作的對應:
| 請求方法 | 對應操作 | 說明 |
|---|---|---|
| GET | 讀取 | 獲取資料 |
| POST | 新增 | 新增資料 |
| PUT | 修改 | 修改資料或增加資料 |
| DELETE | 洗掉 | 洗掉資料 |
- 索參考來存盤資料,分片也是用來存盤資料,它們是怎么對應的?一個索引存盤在多個分片上,默認情況下,一個索引有五個主分片,五個副本分片,主分片的數量一旦定下來就不能再修改,但副本分片的數量還可以修改,
小節總結
- 講了一下ElasticSearch的集群概念,節點是集群的基礎服務單位,節點可以提供資料讀寫服務,資料按分片來存盤,主分片是主要資料,可以讀取和修改資料,副本分片不支持修改資料,
- 主分片和副本分片的互斥性(為了保證資料不同時丟失)
- elasticsearch的資料的邏輯存盤結構(索引->型別->檔案),索引是資料的大分類,型別是資料的小分類,
- 檔案的格式
- 索引與分片的關系,一個索引存盤在多個分片上
Hello ElasticSearch
前面提了一下index,type,document,說了ElasticSearch的邏輯存盤空間,
下面以兩個實體:“寫document->讀document”和“寫document->搜索document“來初步演示一下如何存盤資料和獲取資料,
寫->讀
如果我們要向ElasticSearch中寫入一份資料(document),命令的語法應該如下:
PUT /index名稱/type名稱/document的ID
{
document的資料
}
上面的語法的意思就是向一個index的一個type中插入一個document,document用id作為標識,后面我們取document的資料也將以這個id為依據,其中index,type是可以不需要我們預創建的,在我們還不會如何創建index和type的時候,你可以先隨便打個名字(如果ElasticSearch檢測到我們輸入的index和type是不存在的,那么它就會以默認的規則幫我們創建出來),
請在kibana的devtool中執行以下命令來存盤一份document:
PUT /douban/book/1
{
"book_id":1,
"book_name":"A Clockwork Orange",
"author":"Anthony Burgess",
"summary":"Fully restored edition of Anthony Burgess' original text of A Clockwork Orange, with a glossary of the teen slang 'Nadsat', explanatory notes, pages from the original typescript, interviews, articles and reviews Edited by Andrew Biswell With a Foreword by Martin Amis 'It is a horrorshow story ...' Fifteen-year-old Alex likes lashings of ultraviolence. He and his gang of friends rob, kill and rape their way through a nightmarish future, until the State puts a stop to his riotous excesses. But what will his re-education mean? A dystopian horror, a black comedy, an exploration of choice, A Clockwork Orange is also a work of exuberant invention which created a new language for its characters. This critical edition restores the text of the novel as Anthony Burgess originally wrote it, and includes a glossary of the teen slang 'Nadsat', explanatory notes, pages from the original typescript, interviews, articles and reviews, shedding light on the enduring fascination of the novel's 'sweet and juicy criminality'. Anthony Burgess was born in Manchester in 1917 and educated at Xaverian College and Manchester University. He spent six years in the British Army before becoming a schoolmaster and colonial education officer in Malaya and Brunei. After the success of his Malayan Trilogy, he became a full-time writer in 1959. His books have been published all over the world, and they include The Complete Enderby, Nothing Like the Sun, Napoleon Symphony, Tremor of Intent, Earthly Powers and A Dead Man in Deptford. Anthony Burgess died in London in 1993. Andrew Biswell is the Professor of Modern Literature at Manchester Metropolitan University and the Director of the International Anthony Burgess Foundation. His publications include a biography, The Real Life of Anthony Burgess, which won the Portico Prize in 2006. He is currently editing the letters and short stories of Anthony Burgess.",
"press":"Penguin Classic",
"publication_date":"2000-02-22"
}
如果要獲取ES中存盤的document,命令的語法應該如下:
GET /index名/type名/id
一樣的,請在kibana中執行下述命令來獲取我們上面存盤的document:
GET /douban/book/1
回傳結果:【回傳index名稱,type名稱,id,原始檔案等資料】

很明顯地,我們獲取到了我們剛剛存盤進去的資料,
寫->搜索
一樣的,我們寫多一份資料進ES中:
PUT /douban/book/2
{
"book_id":2,
"book_name":"Kubernetes in Action",
"author":"Marko Luksa",
"summary":"Kubernetes in Action teaches you to use Kubernetes to deploy container-based distributed applications. You'll start with an overview of Docker and Kubernetes before building your first Kubernetes cluster. You'll gradually expand your initial application, adding features and deepening your knowledge of Kubernetes architecture and operation. As you navigate this comprehensive guide, you'll explore high-value topics like monitoring, tuning, and scaling.Kubernetes is Greek for \"helmsman,\" your guide through unknown waters. The Kubernetes container orchestration system safely manages the structure and flow of a distributed application, organizing containers and services for maximum efficiency. Kubernetes serves as an operating system for your clusters, eliminating the need to factor the underlying network and server infrastructure into your designs.",
"press":"Manning Publications",
"publish_date":"2017-08-31"
}
下面將演示搜索的功能,搜索的其中一種語法是:
GET /index名/type名/_search
{
"query":{
"match":{
"欄位Field名稱":"用于搜索的關鍵字"
}
}
}
那么,根據我們之前存盤的資料,如果我們要查詢summary欄位有Orange的資料的話,命令如下:
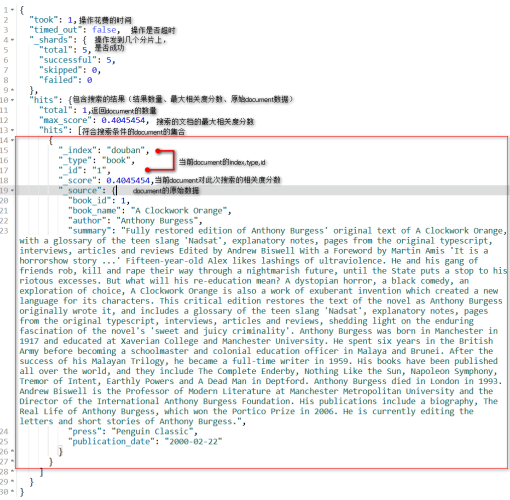
GET /douban/book/_search
{
"query": {
"match": {
"summary":"Orange"
}
}
}
回傳的結果:
小節總結
- 這小節涉及到了資料的插入,讀取,搜索,但僅僅是一個Hello ElasticSearch的例子,所以沒有講到插入資料應該有的前置知識,理論上,你只需要記得這個流程即可,后面會補充這個流程中沒有提到的內容,
--To Be Continue
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/7350.html
標籤:其它