開心一刻

樓主:來,我們先排練一遍
小伙伴們:好
嘿、哈、嚯
樓主:非常好,就是這個節奏,我們開始吧
樓主:啊、啊、啊,疼 ! 你們是不是故意的 ?
回表與覆寫索引
正式講 ICP 之前了,我們先將相關的概念捋一捋,知道的就當回顧,不知道的就當了解了,這有助于對 ICP 的理解
建個示例表 tbl_index
CREATE TABLE tbl_index (
c1 INT,
c2 INT,
c3 CHAR(1),
PRIMARY KEY(c1),
KEY idx_c2 (c2)
);
覆寫索引
如果 where 條件的列和 select 的列都在一個索引中,通過這個索引就可以完成查詢,這就叫就叫覆寫索引;當然,覆寫索引基本針對的是組合索引(InnoDB 的聚簇索引有點特殊,具體可以看下面的圖)
針對上面的 tbl_index, select c2 from tbl_index where c2 = 4; 是覆寫索引查詢,但是這條 SQL 沒有意義,如果我們在 tbl_index 表上增加索引 index idx_c2_c3 (c2,c3) ,那么 select c3 from tbl_index where c2 = 4; 走覆寫索引查詢還是很有意義的,那問題又來了,覆寫索引的意義何在 ? 我們往下看
回表
通過某個索引無法直接完成 SQL 查詢(where 條件的列和 select 的列不全部存在于任何一個索引中),那么此時需要獲取完整的資料記錄來完成此次查詢,從索引項記錄到獲取對應的完整資料記錄的程序就叫回表;概念可能說的有些抽象,我們結合 MySQL 來看看具體什么是回表
InnoDB 的回表
InnoDB 的索引結構有些特殊,非聚簇索引(二級索引)回表到聚簇索引的程序類似如下
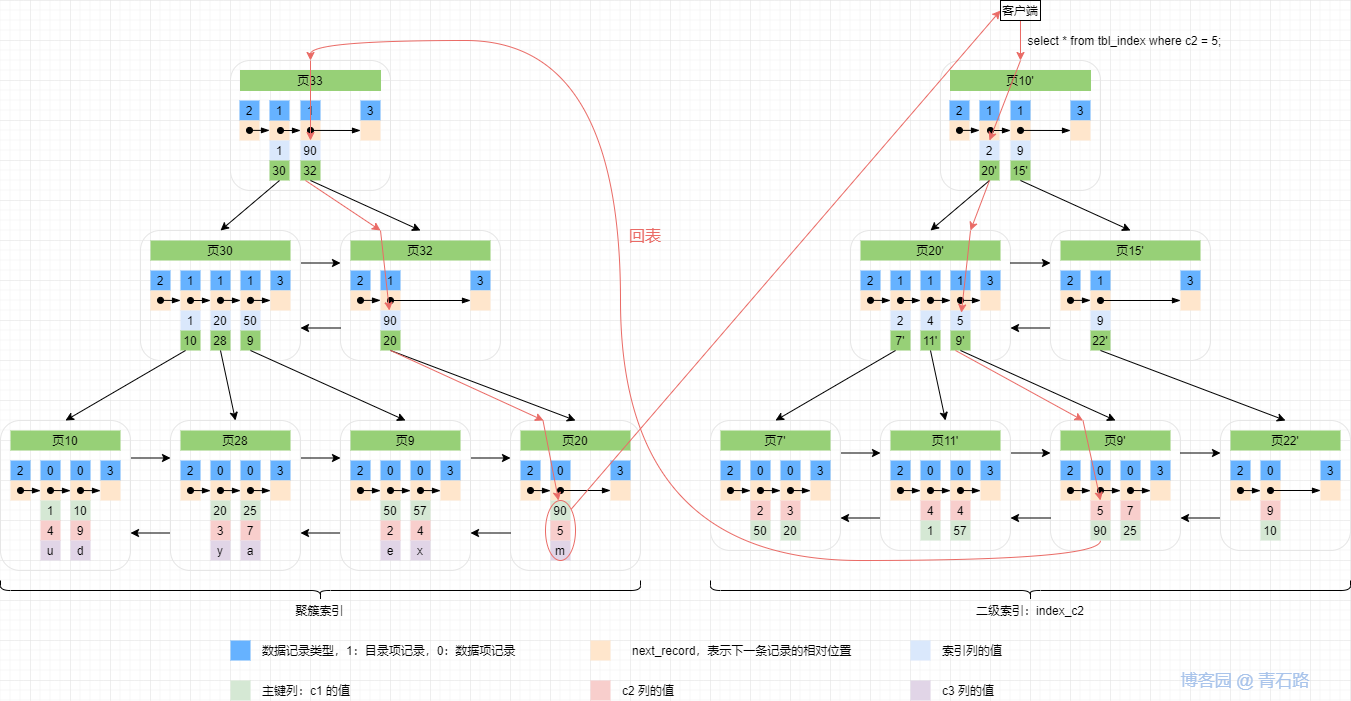
InnoDB的聚簇索引即資料,索引和資料是存在一起的;那么直接走聚簇索引查詢的 SQL 是不存在回表一說的,比如 select * from tbl_index where c1 = 10; ,只有從二級索引出發,并且二級索引獨自完成不了查詢的時候才會回表到聚簇索引完成查詢
MyISAM 的回表
有這樣一種說法: MyISAM 中的索引都是二級索引 ,其實說的是聚簇索引和二級索引的結構基本一致,只是聚簇索引有個唯一性約束
MyISAM 聚簇索引和二級索引,以及它們的回表程序類似如下
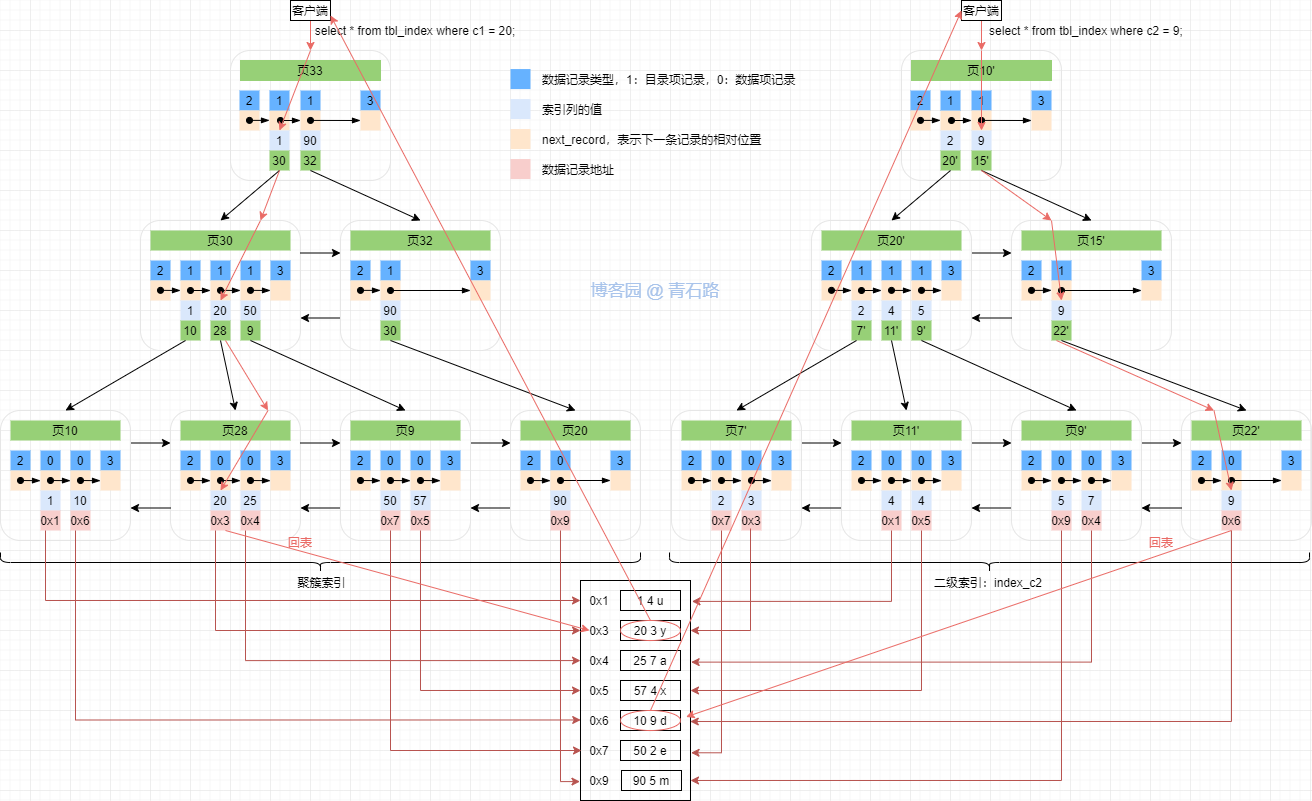
MyISAM 的回表程序指的是根據葉子節點中的資料記錄的地址來獲取完整記錄的程序,無論是聚簇索引還是二級索引都可能存在回表的程序;MyISAM 的回表與 InnoDB 還是有差別的
無論是 InnoDB 的回表還是 MyISAM 的回表,很有可能會造成額外的磁盤 IO,這會嚴重影響查詢效率,覆寫索引的目的就是盡量能夠一次完成 SQL 查詢,避免有回表程序,從而提高效率
如何確認 MySQL 是進行了覆寫索引查詢,還是進行了回表查詢 ?
看 MySQL 的執行計劃,如果 Extra 中只有 using index 則說明使用了覆寫索引查詢,如果 Extra 中出現了 using index condition 或 using index & using where 則說明進行了回表查詢
ICP
Index Condition Pushdown,MySQL 5.6 中引入的一種優化策略
那么究竟是將什么從哪 Push Down 到哪,優化了什么?要弄清楚這 4 個問題,我們需要先弄清楚 where 條件的提取與應用,具體可查看:神奇的 SQL 之 WHERE 條件的提取與應用
where 條件會被提取成 3 部分: Index Key,Index Filter,Table Filter ,在 MySQL 5.6 之前,并不區分 Index Filter 與 Table Filter,統統將 Index First Key 與 Index Last Key 范圍內的索引記錄,回表讀取完整記錄,然后回傳給 MySQL Server 層進行過濾,而在 MySQL 5.6 之后,Index Filter 與 Table Filter 分離,Index Filter 下降到引擎層(InnoDB和MyISAM)的索引層面進行過濾,減少了回表與回傳 MySQL Server 層的記錄互動開銷,提高了 SQL 的執行效率
ICP 優化程序
假設我們有表: tbl_icp


create table tbl_icp (a int primary key, b int, c int, d int, e varchar(50)); create index idx_bcd on tbl_icp(b, c, d); insert into tbl_icp values (4,3,1,1,'a'); insert into tbl_icp values (1,1,1,2,'d'); insert into tbl_icp values (8,8,7,8,'h'); insert into tbl_icp values (2,2,1,2,'g'); insert into tbl_icp values (5,2,2,5,'e'); insert into tbl_icp values (3,3,2,1,'c'); insert into tbl_icp values (7,4,0,5,'b'); insert into tbl_icp values (6,5,2,4,'f');View Code
若沒有使用 ICP,則 SQL 查詢類似如下
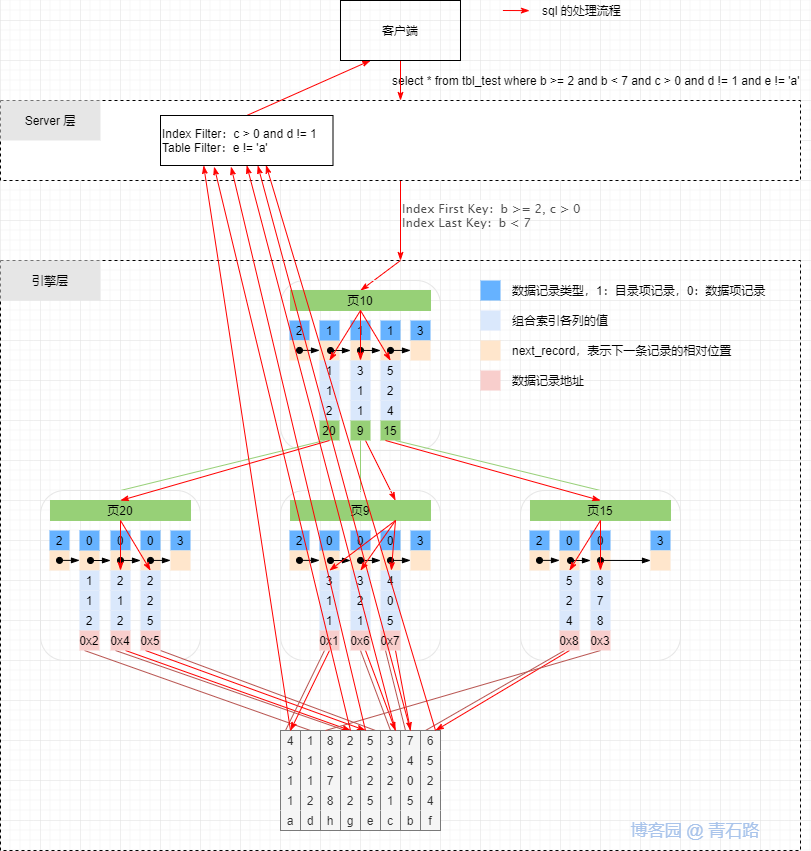
沒有使用 ICP 時,引擎層會將滿足 Index Key 范圍限制的所有資料記錄(示例中一共 6 條)逐潭訓傳給 Server 層,然后由 server 層應用 Index Filter 和 Table Filter (MySQL 5.6 之前不區分 Index Filter 和 Table Filter),最后將滿足條件的資料回傳給客戶端;
若使用 ICP,則 SQL 查詢類似如下
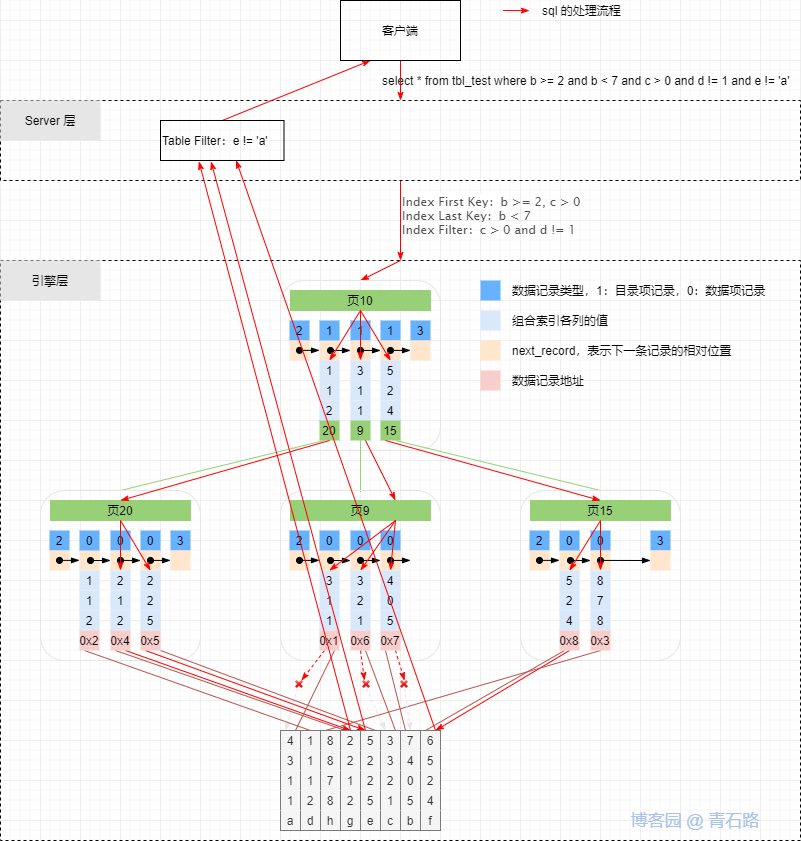
使用了 ICP,Server 層會將 Index Filter 下推到引擎層,引擎層在對 Index First Key 與 Index Last Key 范圍內的索引項逐條進行過濾的時候,會應用上 Index Filter,對不滿足 Index Filter 條件的索引項直接過濾掉,無需回表操作,也無需回傳給 Server 層,從而提供執行效率;上圖中的索引項: 3 1 1 、 3 2 1 不滿足 Index Filter 中的 d != 1 , 4 0 5 不滿足 c > 0 ,所以這 3 個索引項無需進行回表操作,也不需要回傳給 Server 層
相信到這里,大家對 ICP 的 4 個問題應該就比較清楚了
ICP 的適用條件
雖說 ICP 能提高 SQL 執行效率,但也不是任何情況下都適用的,它只適用于某些情況
1、當 SQL 需要全表訪問時,ICP 的優化策略可用于 range, ref, eq_ref, ref_or_null 型別的資料訪問方式
2、只適用于 InnoDB 和 MyISAM 兩種存盤引擎
3、在 InnoDB 中,ICP 只適用于二級索引
ICP 的目的就是為了減少回表導致的磁盤 I/O,而 InnoDB 的聚簇索引的葉子節點存放的就是完整的資料記錄,只要索引資料被讀到記憶體了,那么索引項對應的完整資料記錄也就讀到記憶體了,那么通過索引項獲取資料記錄的程序就在記憶體中進行了,無需進行磁盤 I/O;也就說聚簇索引上應用 ICP,不會減少磁盤 I/O,也就沒有使用的意義了
4、不支持覆寫索引
其實和第 3 點一樣,因為覆寫索引無需回表,ICP 也就沒意義了
5、不支持子查詢條件的下推
6、不支持存盤程序條件、觸發器條件的下推
至于 ICP 的優化效果,取決于在存盤引擎內通過 ICP 篩選掉的資料的比例,過濾掉的資料比例大,那就性能提升大,反之則性能提升小
總結
1、索引覆寫與回表
這兩個往往是一起來考慮的,因為覆寫索引的目的就是減少因回表產生的磁盤 I/O,從而提高執行效率
在實際應用中,我們往往也需要考慮盡可能用覆寫索引來完成我們的 SQL 查詢
2、ICP的四個問題
將什么從哪 Push Down 到哪,優化了什么
將 Index Filter 從 Server 層 Push Down 到了引擎層,減少了因回表產生的磁盤 I/O,也減少了與 Server 層的互動,提高了 SQL 執行效率
3、疑問點
為什么這么明顯的優化策略到 MySQL 5.6 才引入,個人感覺很容易就能考慮到呀,MySQL 的開發者們是腫么肥事 ?

可能是樓主在巨人的肩膀上,站著說話不腰疼吧......
參考
Index Condition Pushdown Optimization
Index Condition Pushdown
MySQL的索引
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/74700.html
標籤:MySQL