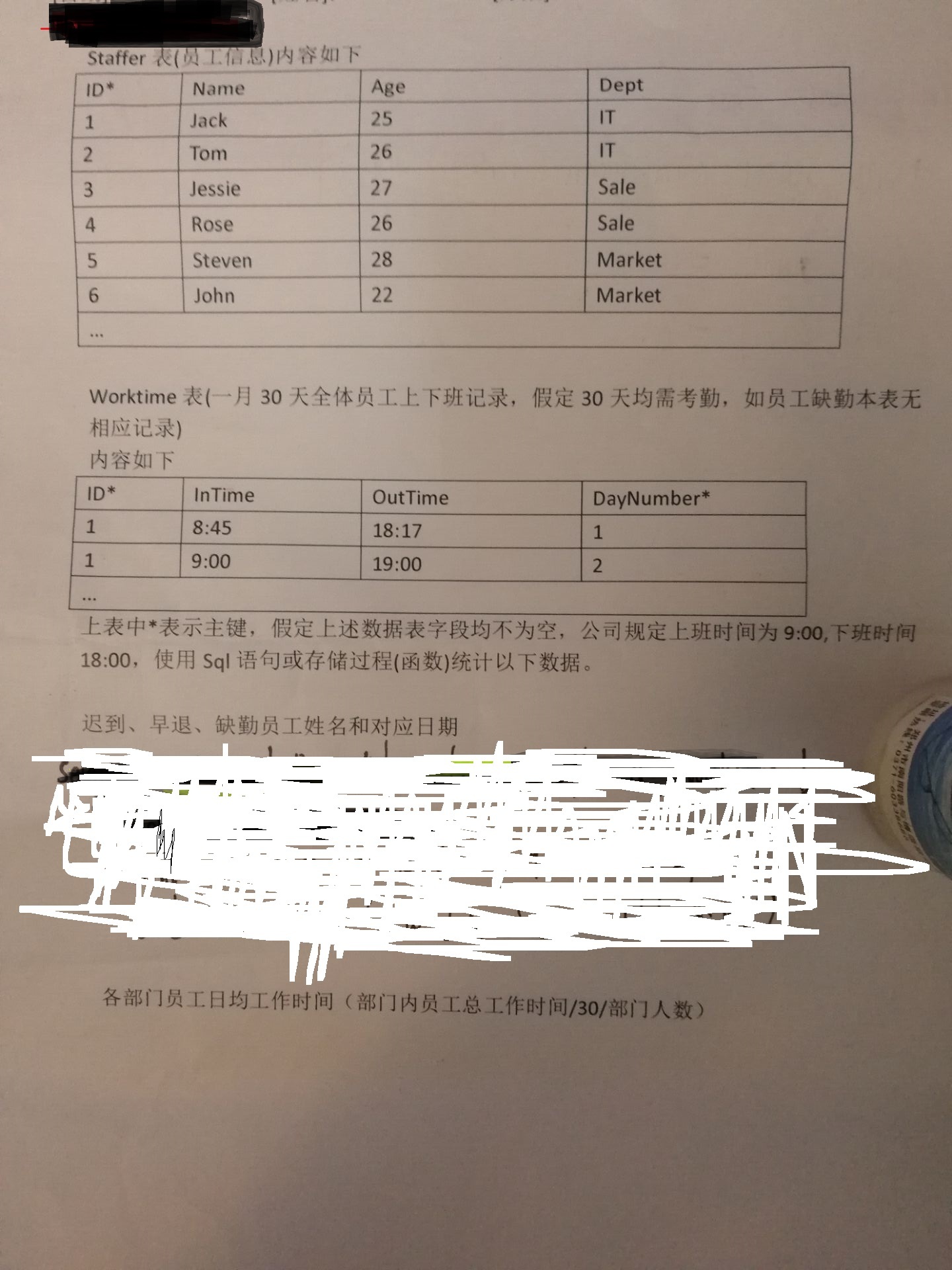
請各位幫我看一下題目 用SQL 或者 存過 寫出來 謝謝了 尤其是第二個題目
uj5u.com熱心網友回復:
你自己先造些資料出來uj5u.com熱心網友回復:
作業自己做
uj5u.com熱心網友回復:


uj5u.com熱心網友回復:
SQL實作如下:
--創建員工基本資訊表
create table Staffer as
select 1 id, 'Jack' name, 25 age, 'IT' dept from dual union all
select 2 id, 'Tom' name, 26 age, 'IT' dept from dual union all
select 3 id, 'Jessie' name, 27 age, 'Sale' dept from dual union all
select 4 id, 'Rose' name, 26 age, 'Sale' dept from dual union all
select 5 id, 'Steven' name, 28 age, 'Market' dept from dual union all
select 6 id, 'John' name, 22 age, 'Market' dept from dual
--創建考勤表
create table Worktime as
select 1 id, '8:45' intime, '18:17' outtime, 1 daynumber from dual union all
select 1 id, '9:00' intime, '19:00' outtime, 2 daynumber from dual
--題1:遲到、早退、缺勤員工姓名和日期,用union all關聯查詢
--1.查詢遲到和早退的員工姓名和日期
select a.name,b.daynumber
from Staffer a,Worktime b
where a.id = b.id
and ((case when a.intime > '9:00' then 1 else 0 end)+(case when a.outtime < '18:00' then 1 else 0 end))>0
union all
--2.查詢缺勤的員工姓名和日期
select t1.name,t1.daynumber
from(select a.id, a.name,b.daynumber
from Staffer a,(select 1+rownum-1 daynumber from dual connect by rownum <= 30) b
) t1
left join (select distinct id,daynumber from Worktime) t2 on t2.id = t1.id
where t2.id is null;
--題2:各部門員工日均作業時間:
select a.dept,round(sum(b.hours)/30/count(*),2) avg_work
from Staffer a
left join(select id, round(to_date(outtime,'yyyymmdd hh24:mi:ss') - to_date(intime,'yyyymmdd hh24:mi:ss') ,2) hours
from(select id,to_char(trunc(sysdate),'yyyymmdd')||' '||intime as intime,to_char(trunc(sysdate),'yyyymmdd')||' '||outtime as outtime
from Worktime
)
group by a.dept;
uj5u.com熱心網友回復:
4樓 我問一下 我在資料庫上運行第二題 發現 一個少有括號 我給了括號后 報缺少關鍵字 我看了一會 沒有找到缺少什么 能幫我 看看嗎 謝謝了uj5u.com熱心網友回復:
而且 這個b.hours 中的b 并沒有定義uj5u.com熱心網友回復:
你試試這個:
select a.dept,round(sum(b.hours)/30/count(*),2) avg_work
from Staffer a
left join(select id, round(to_date(outtime,'yyyymmdd hh24:mi:ss') - to_date(intime,'yyyymmdd hh24:mi:ss') ,2) hours
from(select id,to_char(trunc(sysdate),'yyyymmdd')||' '||intime as intime,to_char(trunc(sysdate),'yyyymmdd')||' '||outtime as outtime
from Worktime
)b
on a.id = b.id
group by a.dept;
uj5u.com熱心網友回復:
-- Create table
create table T_STAFFER
(
id INTEGER,
name VARCHAR2(50),
age INTEGER,
dept VARCHAR2(20)
);
-- Create table
create table T_WORKTIME
(
id INTEGER,
intime VARCHAR2(20),
outtime VARCHAR2(20),
daynumber INTEGER
);
prompt Importing table t_staffer...
set feedback off
set define off
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7369, 'SMITH', 29, '20');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7499, 'ALLEN', 26, '30');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7521, 'WARD', 25, '30');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7566, 'JONES', 25, '20');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7654, 'MARTIN', 34, '30');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7698, 'BLAKE', 33, '30');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7782, 'CLARK', 38, '10');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7788, 'SCOTT', 32, '20');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7839, 'KING', 29, '10');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7844, 'TURNER', 21, '30');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7876, 'ADAMS', 38, '20');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7900, 'JAMES', 21, '30');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7902, 'FORD', 36, '20');
insert into t_staffer (ID, NAME, AGE, DEPT)
values (7934, 'MILLER', 33, '10');
prompt Done.
insert into t_worktime
select id,
lpad(trunc(dbms_random.value(8, 10)), 2, '0') || ':' ||
lpad(trunc(dbms_random.value(0, 59)), 2, '0') intime,
lpad(trunc(dbms_random.value(17, 21)), 2, '0') || ':' ||
lpad(trunc(dbms_random.value(0, 59)), 2, '0') outtime,
daynum
from t_staffer, (select level daynum from dual connect by level <= 30)
order by id, daynum;
commit;
-- 隨機洗掉幾條資料, 制造缺勤
delete t_worktime
where rowid in (select rid
from (select rowid rid,
daynumber,
trunc(dbms_random.value(1, 50)) random
from t_worktime t)
where random = daynumber);
commit;
-- 先看看每個員工這個月的出勤情況
select id, count(*) cnt from t_worktime group by id order by cnt;
-- 第一題的答案
-- 這種實作方式有一點不好的, 當員工數量比較多的時候, 例如 富士康500W員工, 這里就會有性能問題,
-- 因為這里使用笛卡爾積列舉出每個員工出勤30天的資料
with v_staff_days as
(select /* 列舉出每個員工30天的考勤 */
s.id, daynumber, s.dept
from (select level daynumber from dual connect by level <= 30) days
cross join (select id, dept from t_staffer) s)
--select * from v_staff_days order by id, daynumber
select t1.id,
t1.daynumber,
t1.dept,
t2.intime,
t2.outtime,
(case
when t2.id is null then
'缺勤'
when t2.intime > '09:00' and t2.outtime < '18:00' then
'遲到、早退'
when t2.intime > '09:00' then
'遲到'
when t2.outtime < '18:00' then
'早退'
end) reason
from v_staff_days t1
left join t_worktime t2
on (t1.id = t2.id and t1.daynumber = t2.daynumber)
where ((t2.id is null) --缺勤
or (t2.intime > '09:00') --遲到
or (t2.outtime < '18:00') --早退
)
-- and t1.id = 7900 -- 可加上這個過濾條件看看缺勤天數是否對的上
order by t1.id, t1.daynumber;
----------------------------------------用存盤程序來實作的話, 效率會高很多----------------------------------------
with v_base as
(select t.*,
lead(daynumber, 1, daynumber) over(partition by t.id order by t.daynumber) next_daynumber,
(case
when t.intime > '09:00' and t.outtime < '18:00' then
3
when t.intime > '09:00' then
1
when t.outtime < '18:00' then
2
else
0
end) status
from t_worktime t)
select a.*,
(case
when next_daynumber - daynumber > 1 then
1
else
0
end) lost_range_mark
from v_base a;
詳見 存盤程序實作思路.png
-- 搞一個表來存盤例外考勤的資料
create table t_incorrect_log(
staffid int, -- 員工id
daynumber int, -- 考勤日期
status int, -- 是否遲到、早退 狀態
time1 int, --遲到時間(單位:分鐘)
time2 int, --早退時間(單位:分鐘)
lost int -- 是否缺勤 1 是 0 否
);
create procedure proc_analysis_incorrect_kq as
type tbl_type is table of t_incorrect_log%rowtype index by pls_integer;
tbl tbl_type; -- 用來存放考勤例外記錄
i pls_integer; -- 計數的
v_final_date_prefix varchar2(20) := to_char(sysdate, 'yyyyMMdd');
v_final_intime date := to_date(v_final_date_prefix || ' 09:00',
'yyyyMMdd hh24:mi');
v_final_outtime date := to_date(v_final_date_prefix || ' 18:00',
'yyyyMMdd hh24:mi');
begin
-- 這里最好是分為兩個for回圈進行處理, 分別對 主SQL再添加過濾條件 status <> 0 表示遲到的 lost_range_mark <> 0 表示缺勤的
-- 這里我偷懶就只寫一個了
for r in (with v_base as
(select t.*,
lead(daynumber, 1, daynumber) over(partition by t.id order by t.daynumber) next_daynumber,
(case
when t.intime > '09:00' and t.outtime < '18:00' then
3
when t.intime > '09:00' then
1
when t.outtime < '18:00' then
2
else
0
end) status
from t_worktime t)
select a.*,
(case
when next_daynumber - daynumber > 1 then
1
else
0
end) lost_range_mark
from v_base a) loop
-- 判斷遲到
if r.status <> 0 then
i := tbl.count + 1; --要+1
tbl(i).staffid := r.id;
tbl(i).daynumber := r.daynumber;
tbl(i).status := r.status;
tbl(i).time1 := (to_date(v_final_date_prefix || ' ' || r.intime,
'yyyyMMdd hh24:mi') - v_final_intime) * 24 * 60; --遲到時間(單位:分鐘)
tbl(i).time2 := (v_final_outtime -
to_date(v_final_date_prefix || ' ' || r.outtime,
'yyyyMMdd hh24:mi')) * 24 * 60; --早退時間(單位:分鐘)
if r.status = 2 then
-- 只早退的不要記錄遲到時間,否則會變成負數
tbl(i).time1 := null;
elsif r.status = 1 then
-- 只遲到的不記錄早退時間,否則會變成負數
tbl(i).time2 := null;
end if;
tbl(i).lost := 0;
end if;
-- 判斷缺勤
if r.lost_range_mark = 1 then
-- 找出缺勤的日期
for j in r.daynumber + 1 .. r.next_daynumber - 1 loop
dbms_output.put_line(r.daynumber || '~' || r.next_daynumber ||
' ---> ' || j);
i := tbl.count + 1; --要+1
tbl(i).staffid := r.id;
tbl(i).daynumber := j; -- 缺勤日
tbl(i).status := null;
tbl(i).time1 := null; --遲到時間(單位:分鐘)
tbl(i).time2 := null; --早退時間(單位:分鐘)
tbl(i).lost := 1;
end loop;
end if;
-- 批量插入
if i >= 50000 then
forall x in 1 .. tbl.count
insert into t_incorrect_log
(staffid, daynumber, status, time1, time2, lost)
values
(tbl(x).staffid,
tbl(x).daynumber,
tbl(x).status,
tbl(x).time1,
tbl(x).time2,
tbl(x).lost);
commit;
tbl.delete(); -- 一定要清空tbl
end if;
end loop;
-- 最后一批資料可能沒有達到50000條, 別漏了操作
forall x in 1 .. tbl.count
insert into t_incorrect_log
(staffid, daynumber, status, time1, time2, lost)
values
(tbl(x).staffid,
tbl(x).daynumber,
tbl(x).status,
tbl(x).time1,
tbl(x).time2,
tbl(x).lost);
commit;
end;
/
select * from t_incorrect_log;
truncate table t_incorrect_log; -- 每次測驗都先刪掉記錄表的資料
-- 現在可在 t_incorrect_log 進行更多的分析了, 如看誰是遲到3巨頭。。是否超出每個月限定的遲到次數、遲到時間等等。。。
-- 校驗是否正確:
-- 運行完存盤程序后, 查看 t_incorrect_log 表的資料量, 看和第一條SQL查詢出來的資料量是否一致。
-- 也可單獨看某個員工的出勤,來和 t_incorrect_log 表的資料進行比對
-- 第二題的答案:每個員工每個月作業總時長
select b.dept, sum(a.day_worktime) / count(distinct a.id) staff_cnt / 30
from (select x.id,
(to_date(x.outtime, 'hh24:mi') - to_date(x.intime, 'hh24:mi')) * 24 day_worktime
from t_worktime x) a
inner join t_staffer b
on (a.id = b.id)
group by b.dept;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/74969.html
標籤:開發
上一篇:商品圖片顯示 SQL陳述句